

国产框架超越 PyTorch 和 TensorFlow?
描述
在深度学习领域,PyTorch、TensorFlow 等主流框架,毫无疑问占据绝大部分市场份额,就连百度这样级别的公司,也是花费了大量人力物力,堪堪将 PaddlePaddle 推入主流。
在这样资源主导、肉食者谋的竞争环境下 ,一家国产深度学习框架的创业公司 OneFlow 出现了。
它以处理大规模模型见长,甚至今年将全部源码和实验对比数据,在 GitHub 进行了开源。
质疑不可避免的出现了:OneFlow 这种擅长解决大模型训练的新架构有必要吗?深度学习框架的效率有那么重要吗?创业公司有可能在竞争中脱颖而出么?
我们借着 CosCon 20' 开源年会的机会,采访了一流科技 CEO 袁进辉,了解到了他和一流科技的工程师们,1300 多个日日夜夜、数十万行代码背后的故事。
光环再多,创业也得一步一个脚印
2016 年 11 月,袁进辉在清华附近的一栋写字楼里,写下了 OneFlow 的第一版设计理念。此时的袁进辉刚刚从工作了近 4 年的微软亚洲研究院(MSRA)离职。
「MSRA 前员工」并不是袁进辉身上唯一的 tag,2003 年从西安电子科技大学本科毕业后,他被保送到清华大学计算机系继续直博学习,师从中国科学院院士、中国 AI 学科奠基人之一张钹教授。
2008 年袁进辉从清华大学毕业后,先后加入网易、360 搜索。他开发的鹰眼系统,被中国国家队作为日常训练辅助系统。除此之外,他在 MSRA 工作期间,专注于大规模机器学习平台,还研发出了当时世界上最快的主题模型训练算法和系统 LightLDA,被应用于微软在线广告系统。
LightLDA 于 2014 年面世,仅仅两年之后,独具慧眼的袁进辉就又萌生了一个大胆地猜想:随着业务需求和场景的丰富,能高效处理大模型训练的分布式深度学习框架,必然成为继 Hadoop、Spark 之后,数据智能时代基础设施的核心。
但是当时主流的深度学习框架都是由 Google、Amazon、Facebook 等大厂牵头开发的,即使是国内情况也类似。这由于开发深度学习框架不光需要雄厚的研发成本,更重要的是能耐得住寂寞,做好打持久战的准备,因此尚没有初创企业敢在该领域试水。
已有的深度学习框架都已经打的如火如荼了,一家初创企业,又搞出来一个新框架,会有用户买单吗?行动派袁进辉不但敢想,他还敢干。
敲下 OneFlow 第一行代码的时候,他还没想清楚详细地实现策略,更谈不上完善的业务逻辑。他的想法很简单,又很复杂,要做一款「开发者爱用」的产品。
一群天才+21 个月,OneFlow 初版上线
2017 年 1 月,袁进辉成立一流科技,召集了 30 多位工程师,开启了 OneFlow 的正式「团战」。尽管大家对困难已经做了充分预估,但是随着开发的逐渐深入,涌现的重重困难还是出乎的团队的意料。
深度学习框架的技术非常复杂,况且 OneFlow 采用了一个全新的技术架构,没有先例可以参考,光是把技术设想跑通,就花了快两年时间。
2018 年秋天,一流科技的发展进入了最艰难的阶段。产品研发迟迟不能定型,一些员工的耐心跟信心消耗殆尽,加上公司下轮融资一波三折,团队的士气和信心面临极大挑战。
在创业圈有个「18 个月魔咒」的说法,意思是一年半没看到希望,没有正反馈,创业团队的心态就会发生变化,失去耐心。袁进辉意识到,不能再等了,必须要尽早在真实场景去使用 OneFlow,让大家看到 OneFlow 的创新的确是有价值的, 从而形成正反馈。
2018 年 9 月,在经历了长达 1 年 9 个月的研发后,袁进辉和团队推出了 OneFlow 闭源版。当时 OneFlow 还没有开源,也存在大大小小的问题,但产品正式发布了,总算是给团队成员吃了个定心丸。
专注大规模训练,效率秒杀同类框架
2018 年 11 月,幸运之神降临到一流科技。Google 推出了最强自然语言模型 BERT,开启了 NLP 新时代。这验证了袁进辉的预测,擅长处理大规模训练的新架构,是必须且必要的。
很快,一流科技的工程师就基于 OneFlow 支持了 BERT-Large 的分布式训练,这也是当时唯一一个支持分布式 BERT-Large 训练的框架,性能和处理速度远超已有的开源框架。
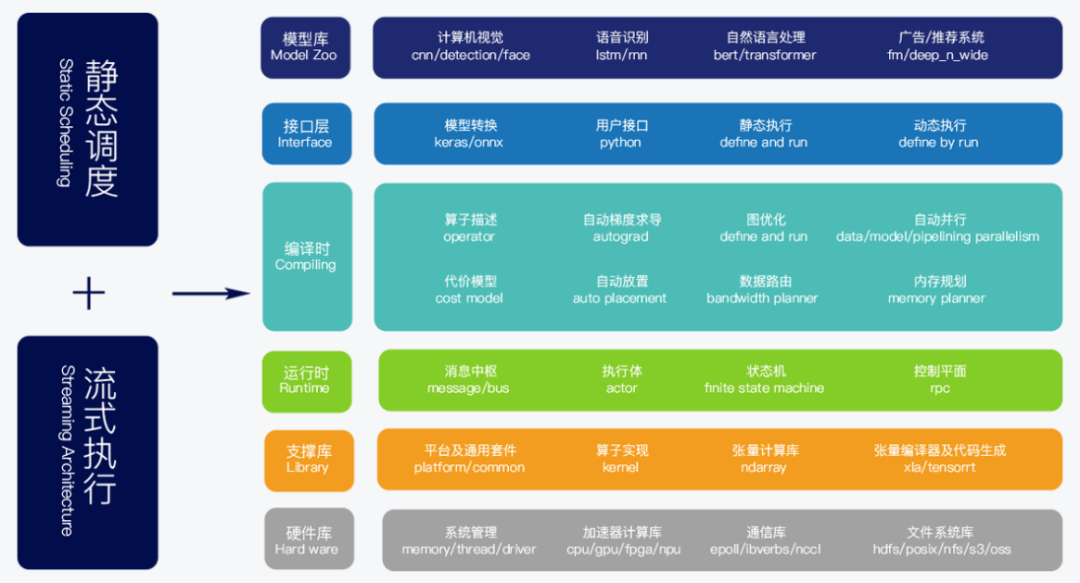
OneFlow 异构分布式流式系统架构图
OneFlow 「一战成名」,这也为一流科技积累第一批头部互联网企业用户提供了契机。令人倍感意外的是,当时的袁进辉因为「仍对产品不满意」,所以选择了一条格外低调的路。
从 2018 年 9 月闭源版本发布,到 2020 年 7 月正式开源,袁进辉又用了 22 个月来打磨 OneFlow。他和团队一边持续优化经典模型,一边解决原来没预计到的问题,在袁进辉看来,哪怕是产品文档没做好,他都不会轻易把 OneFlow 推到台面上。
2020 年 7 月 31 日,OneFlow 正式在 GitHub 开源。这个以训练大规模模型著称的开源框架,第二次站到聚光灯下,完美诠释了四个字--效率为王。
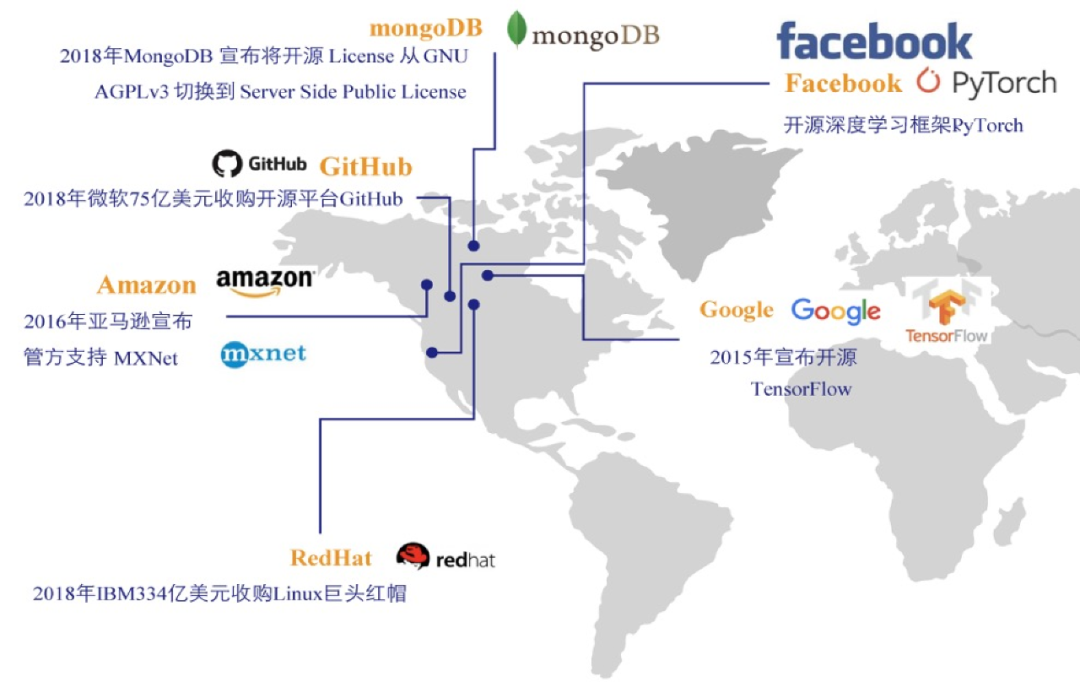
深度学习框架版图几乎由美国企业主导
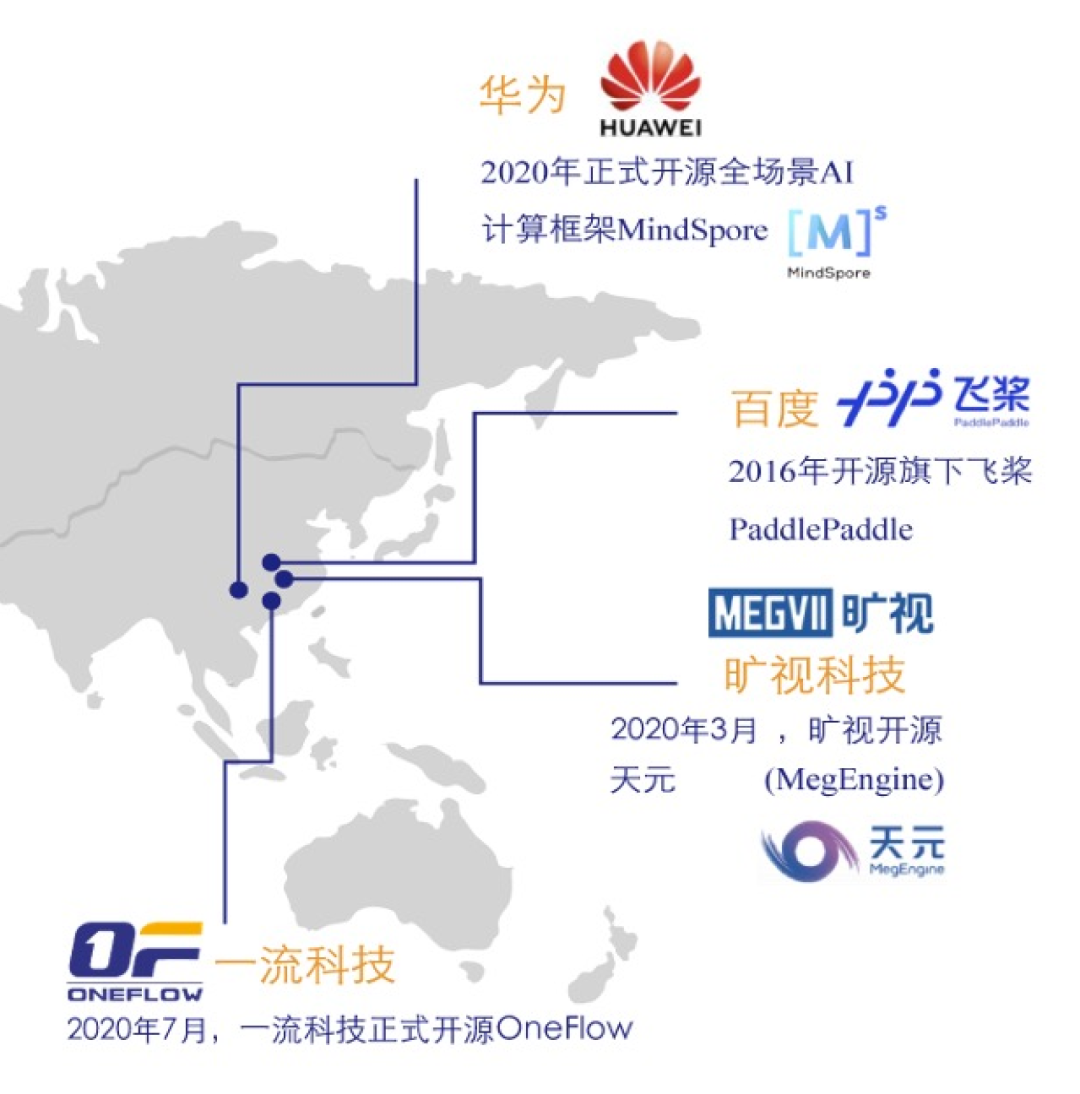
国内开源的深度学习框架版图中
只有 OneFlow 是由初创企业研发并开源
训练速度更快、GPU 利用率更高、多机加速比更高、运维成本更低、用户上手难度更低,五个强大优势让 OneFlow 能快速适应各个场景,并进行快速延展。袁进辉和团队对 OneFlow 的性能追求和优化,达到了极致。
近期,OneFlow 发布了 v0.2.0 版本,更新的性能优化多达 17 个,使得 CNN 和 BERT 的自动混合精度训练速度大幅提升。
开发团队还建立了一个名为 DLPerf 的开源项目,将实验环境、实验数据、可复现算法完全开源,测评了在相同的物理环境上(4台 V100 16G x8的机器),OneFlow 和其他几个主流框架在 ResNet50-v1.5 和 BERT-base 模型上的吞吐率及加速比。
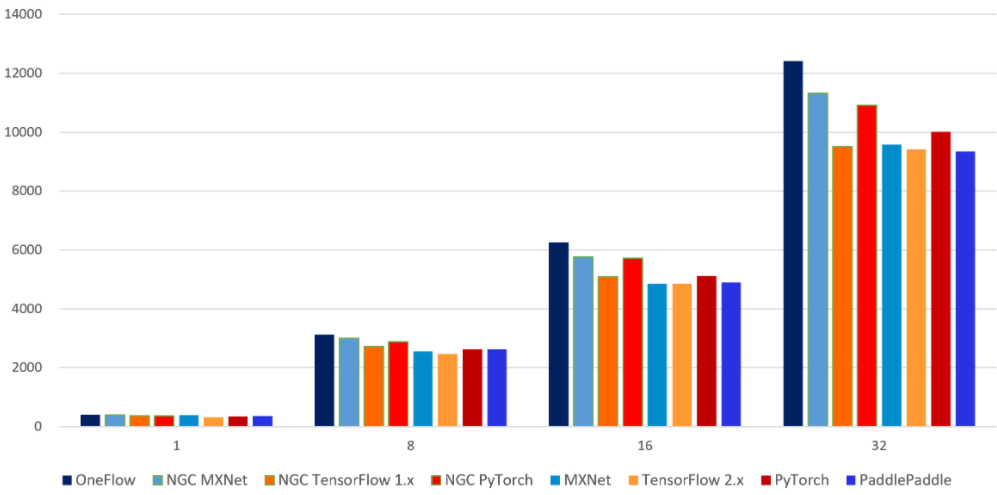
7 个框架在 ResNet50-v1.5 模型上的吞吐率对比
结果证明 OneFlow 在单机单卡、多机多卡下的吞吐率都明显领先其他框架,成为在主流旗舰显卡(V100 16G)上训练 ResNet50-v1.5 和 BERT-base 模型最快的框架,OneFlow ResNet50-v1.5 AMP 单卡比 NVIDIA 深度优化过的 PyTorch 快 80%, 比 TensorFlow 2.3 快 35%。
直面质疑,做赛道的「少数派」
事实上,OneFlow 从诞生至今,受到的质疑并不在少数,「上车晚且生存空间狭小」是最主流的声音,对此袁进辉表现出了超乎寻常的坦然。
在他看来,深度学习框架本就是一个新生事物,技术和产业都在中早期,不存在上车早晚的问题。在技术收敛之前,性能高、易用性强、符合用户使用价值的产品,就会受到用户的青睐。
至于生存空间小一说,更是子虚乌有。开源让小公司和大公司的产品有机会公平竞技,优秀的新生框架挑战权威的框架,正是开源精神的内核之一。
质疑声并没有阻碍 OneFlow 的发展,相反,袁进辉和团队加快了 OneFlow 的升级和完善进程,更新优化性能、梳理开发者文档、收集社区反馈……这些努力和坚持,为 OneFlow 吸引了更多用户,其中不乏最初的「怀疑论者」。
在 COSCon'20 中国开源年会上,袁进辉做了题为《深度学习训练系统演进》的分享,向所有开发者介绍了 OneFlow 下一步的开发规划,除了坚持效率为王、继续性能优化外,开发团队还在努力降低用户的学习成本和迁移成本。目前 PyTorch 用户迁移到 OneFlow 的成本已经相当低了,因为二者的用户接口几乎一样,已训练好的模型转换成 OneFlow 的成本也足够低。
客观讲,OneFlow 在完备性和易用性上,与 TensorFlow 和 PyTorch 相比还有差距。但是,OneFlow 的特色是效率高、扩展性好以及分布式特别容易使用,非常适合大规模人脸识别、大规模广告推荐系统、以及类似 GPT-3 这种模型参数巨大的模型训练场景。
采访的最后袁进辉老师也毫不掩饰对人才的渴望,他表示 OneFlow 正在招聘机器学习工程师以及深度学习工程师,非常欢迎有识之士加入这个朝气勃勃、渴望胜利的团队。
编辑:jq
-
tensorflow和pytorch哪个好2024-07-05 2135
-
TensorFlow与PyTorch深度学习框架的比较与选择2024-07-02 2965
-
PyTorch与TensorFlow的优点和缺点2023-10-30 2214
-
深度学习框架pytorch介绍2023-08-17 3040
-
深度学习框架PyTorch和TensorFlow如何选择2023-02-02 1636
-
TensorFlow和PyTorch的实际应用比较2023-01-14 3983
-
TensorFlow的衰落与PyTorch的崛起2022-11-04 2690
-
在Ubuntu 18.04 for Arm上运行的TensorFlow和PyTorch的Docker映像2022-10-14 3294
-
如何安装TensorFlow2 Pytorch?2022-03-07 1353
-
TensorFlow、PyTorch,“后浪”OneFlow 有没有机会2021-07-27 1764
-
PyTorch1.8和Tensorflow2.5该如何选择?2021-07-09 2481
-
机器学习框架Tensorflow 2.0的这些新设计你了解多少2018-11-17 3884
-
什么是张量,如何在PyTorch中操作张量?2018-10-12 17255
-
深度学习框架排名:TensorFlow第一,PyTorch第二2018-04-02 12217
全部0条评论

快来发表一下你的评论吧 !
