

关于SLAM基础知识详解
描述
01Slam概述
SLAM是Simultaneous localization and mapping缩写,意为“同步定位与建图”。
SLAM的典型应用领域:
机器人定位导航领域-地图建模, VR/AR方面-辅助增强视觉效果, 无人机领域-地图建模, 无人驾驶领域-视觉里程计。
SLAM框架:
传感器数据:主要用于采集实际环境中的各类型原始数据。包括激光扫描数据、视频图像数据、点云数据等。
视觉里程计:主要用于不同时刻间移动目标相对位置的估算。包括特征匹配、直接配准等算法的应用。
后端:主要用于优化视觉里程计带来的累计误差。包括滤波器、图优化等算法应用。
建图:用于三维地图构建。
回环检测:主要用于空间累积误差消除
其工作流程大致为:
传感器读取数据后,视觉里程计估计两个时刻的相对运动(Ego-motion),后端处理视觉里程计估计结果的累积误差,建图则根据前端与后端得到的运动轨迹来建立地图,回环检测考虑了同一场景不同时刻的图像,提供了空间上约束来消除累积误差。
基于传感器的SLAM分类
基于激光雷达的激光SLAM(Lidar SLAM)和基于视觉的VSLAM(Visual SLAM)。
1.激光SLAM
激光SLAM采用2D或3D激光雷达(也叫单线或多线激光雷达),2D激光雷达一般用于室内机器人上(如扫地机器人),而3D激光雷达一般使用于无人驾驶领域。激光雷达的出现和普及使得测量更快更准,信息更丰富。激光雷达采集到的物体信息呈现出一系列分散的、具有准确角度和距离信息的点,被称为点云。通常,激光SLAM系统通过对不同时刻两片点云的匹配与比对,计算激光雷达相对运动的距离和姿态的改变,也就完成了对机器人自身的定位。
激光雷达测距比较准确,误差模型简单,在强光直射以外的环境中运行稳定,点云的处理也比较容易。同时,点云信息本身包含直接的几何关系,使得机器人的路径规划和导航变得直观。激光SLAM理论研究也相对成熟,落地产品更丰富。
2.视觉SLAM
眼睛是人类获取外界信息的主要来源。视觉SLAM也具有类似特点,它可以从环境中获取海量的、富于冗余的纹理信息,拥有超强的场景辨识能力。早期的视觉SLAM基于滤波理论,其非线性的误差模型和巨大的计算量成为了它实用落地的障碍。近年来,随着具有稀疏性的非线性优化理论(Bundle Adjustment)以及相机技术、计算性能的进步,实时运行的视觉SLAM已经不再是梦想。
视觉SLAM的优点是它所利用的丰富纹理信息。例如两块尺寸相同内容却不同的广告牌,基于点云的激光SLAM算法无法区别他们,而视觉则可以轻易分辨。这带来了重定位、场景分类上无可比拟的巨大优势。同时,视觉信息可以较为容易的被用来跟踪和预测场景中的动态目标,如行人、车辆等,对于在复杂动态场景中的应用这是至关重要的。
融合激光+视觉
激光SLAM和视觉SLAM各擅胜场,单独使用都有其局限性,而融合使用则可能具有巨大的取长补短的潜力。例如,视觉在纹理丰富的动态环境中稳定工作,并能为激光SLAM提供非常准确的点云匹配,而激光雷达提供的精确方向和距离信息在正确匹配的点云上会发挥更大的威力。而在光照严重不足或纹理缺失的环境中,激光SLAM的定位工作使得视觉可以借助不多的信息进行场景记录。
SLAM与SFM的区别与联系
SFM即Structure From Motion
传统三维重建,这是一门计算机视觉学科的分支, 特点是把数据采集回来,然后离线处理。常见应用就是重建某建筑物的3d地图。
区别:
SFM是vision方向的叫法,而SLAM是robotics方向的叫法。
SLAM所谓的Mapping, SFM叫structure;SLAM所谓的Location, SFM方向叫camera pose。
从出发点考虑,SFM主要是要完成3D reconstuction,而SLAM主要是要完成localization
从方法论的角度上考虑, SFM不要求prediction的,real-time是不要求的。但是对于SLAM而言prediction是必须的,SLAM的终极目标是real-time navigation。
SLAM要求实时,数据是线性有序的,无法一次获得所有图像,部分SLAM算法会丢失过去的部分信息;基于图像的SFM不要求实时,数据是无序的,可以一次输入所有图像,利用所有信息。
SLAM是个动态问题,会涉及到滤波,运动学相关的知识,而SFM主要涉及的还是图像处理的知识。
联系:
基本理论是一致的,都是多视角几何;
传统方法都需要做特征值提取与匹配;
都需要优化投影误差;
回环检测和SfM的全局注册方法是同一件事情。
02代表性的SLAM算法
•VINS-Mono MONO SLAM https://github.com/HKUST-Aerial-Robotics/VINS-Mono
•ORB-SLAM2 RGBD SLAM https://github.com/raulmur/ORB_SLAM2
•LOAM Laser SLAM https://github.com/laboshinl/loam_velodyne
•MaskFusion Semantic SLAM https://github.com/martinruenz/maskfusion
•BundleFusion Dense 3D Reconstruction https://github.com/niessner/BundleFusion
一、VINS-Mono
论文解读
近年来的发展趋势为用低成本惯性测量单元(IMU)辅助单目视觉系统。
单目视觉-惯性系统(VINS)的主要优点是具有可观测的度量尺度,以及翻滚角(roll)和俯仰角(pitch)。这让需要有尺度的状态估计的导航任务成为可能。
IMU测量值的积分可以显著提高运动跟踪性能,弥补光照变化、缺少纹理的区域或运动模糊的视觉轨迹损失的差距。
原文的解决方案的核心是一个鲁棒的基于紧耦合的滑动窗非线性优化的单目视觉惯性里程计(VIO)。
1、一个鲁棒的初始化过程,它能够从未知的初始状态引导系统。
2、一个紧耦合、基于优化的单目视觉惯性里程计,具有相机-IMU外部校准和IMU偏置估计。
3、在线回环检测与紧耦合重定位。
4、四自由度全局位姿图优化。
5、用于无人机导航、大规模定位和移动AR应用的实时性能演示。
6、完全集成于ros的pc版本以及可在iphone 6或更高版本上运行的IOS版本的开源代码。
源码解析
Visual-Inertial融合定位算法。
VINS-Mono主要包含两个节点: 前端节点feature_tracker_node和后端节点estimator_node。
前端节点处理Measurement Preprocessing中的Feature Detection and Tracking, 其他几个部分(IMU preintegration, initialization, LocalBA, Loop closure)都是在estimator_node中处理。
二、ORB-SLAM2
论文解读
ORB-SLAM2是基于单目,双目和RGB-D相机的一套完整的SLAM方案。在实时和标准的CPU的前提下能够进行重新定位和回环检测,以及地图的重用。在实验当中,我们关心的是在大场景中建立可用的地图和长期的定位。与此前的SLAM方案进行对比,在大多数的情况下,ORB-SLAM2展现出一样好的精确程度。
视觉SLAM仅仅通过一个单目相机就能够完成。单目相机也是最便宜也是最小巧的传感器设备。然而深度信息无法从单目相机中观测到,地图的尺度和预测轨迹是未知的。此外,由于不能从第一帧当中进行三角测量化,单目视觉SLAM系统的启动往往需要多个视角或者滤波技术才能产生一个初始化的地图。最后,单目SLAM可能会造成尺度漂移,以及在探索的过程中执行纯旋转的时候可能会失败。通过使用一个双目或者RGB-D相机将会解决这些问题,并且能够成为一种更加有效的视觉SLAM的解决方案。
在这篇文章当中,在单目ORB-SLAM[1]的基础上提出ORB-SLAM2,有以下贡献:
这是首个基于单目,双目和RGB-D相机的开源SLAM方案,这个方案包括,回环检测,地图重用和重定位。
我们的RGB-D结果说明,光速法平差优化(BA)比ICP或者光度和深度误差最小方法的更加精确。
通过匹配远处和近处的双目匹配的点和单目观测,我们的双目的结果比直接使用双目系统更加精确。
针对无法建图的情况,提出了一个轻量级的定位模式 ,能够更加有效的重用地图。
系统框架展示:
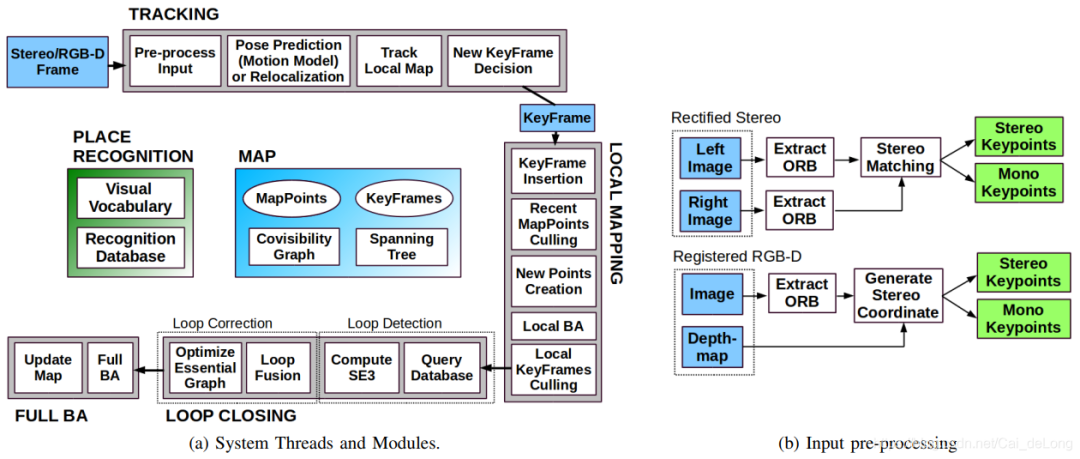
三、LOAM
论文解读
《LOAM:Lidar Odometry and Mapping in Realtime》
LOAM是激光雷达slam中鼎鼎有名的,一套基于线面特征的前端框架。
使用一个三维空间中运动的两轴激光雷达来构建实时激光里程计。
提出可以同时获得低漂移和低复杂度计算,并且不需要高精度的测距和惯性测量。
核心思想是分割同时定位和建图的复杂问题,寻求通过两个算法同时优化大量变量。:
一个是执行高频率的里程计但是低精度的运动估计,另一个算法在一个数量级低的频率执行匹配和注册点云信息。将这两个算法结合就获得高精度、实时性的激光里程计。
使用以6自由度运动的2轴雷达的距离测量值。
难点:不同时间接收到的距离测量值以及运动估计的误差会导致点云的误匹配。
以高频率但低保真度执行测距法以估计激光雷达的速度+以较低的数量级频率运行,以进行点云的精确匹配和配准
结果表明,该方法可以在最先进的离线批处理方法水平上实现准确性。
主要贡献: 是把同时定位与建图(SLAM)技术分为两部分,一个是高频率(10HZ)低精度的里程计odometry过程,另一个是低频率(1HZ)高精度的建图mapping过程,二者结合可实现低漂移、低计算量、高精度的SLAM。
Lidar Odometry:分为特征点提取Feature Point Extraction和特征点关联 Finding Feature Point Correspondence两部分。
特征点提取:在激光雷达每一次sweep中,根据曲率对点进行排序,作为评价特征点局部表面光滑性的标准。曲率最大的为边缘点,曲率最小的为平面点,每个局部提取2个边缘点和4个平面点。
特征点关联:使用scan-to-scan方式,分为边缘点匹配和平面点匹配两部分。计算点到直线的距离和点到平面的距离。
姿态解算:根据匹配的特征点云估计接收端位姿。
Lidar Mapping:低频率建图,前面获得相邻帧的姿态变换,接下来要和全局地图进行匹配,将其加入到全局地图中。
源码解析
LOAM源码主要由四个节点构成,分别完成特征点提取,高频低精度odom, 低频高精度odom, 双频odom融合的功能,每个节点以rosnode的形式存在, 也就是说是独立的进程,进程间通过rostopic传递点云, odom等数据。实际上, 四个节点的执行顺序完全是串行的,很容易改成单进程的版本。
四、MaskFusion
-与Mask-RCNN的关联(有使用到)。
多个运动目标进行实时识别、跟踪和重构。
一个实时的、对象感知的、语义的和动态的RGB-D SLAM系统, 超越传统的输出静态场景的纯几何地图的系统。
尽管取得了这些进步,SLAM方法及其在增强现实中的应用在两个领域中仍处于非常初级的阶段。
大多数SLAM方法依赖于这样一种假设,即环境大多是静态的,移动的对象最多只能被检测为异常值并被忽略。可以处理任意动态和非刚性的场景仍然是一个开放的挑战。
大多数SLAM系统提供的输出是一个纯粹的环境几何图。近期才出现添加语义信息的工作,并且识别主要是限于少数已知的对象实例的三维模型可提前得知,或每个3 D地图点划分成一组固定的语义类别没有区分对象实例。
贡献:
识别、检测、跟踪和重构多个运动的刚性对象,同时可以精确地分割每个实例并为其分配一个语义标签。
联合的输出:
(i)Mask- RCNN,这是一个强大的基于图像的实例级分割算法,可以预测80个对象类的对象类别标签;
(ii)一种基于几何的分割算法,这将根据深度和表面法线线索生成一个对象边缘映射,以增加目标掩码中对象边界的准确性。
该系统利用语义场景理解来映射和跟踪多个目标。在从二维图像数据中提取语义标签的同时,系统为每个对象实例和背景分别建立了独立的三维模型。
它在识别、重构和跟踪三个主要问题上存在局限性。
在识别方面,MaskFusion只能识别经过MaskRCNN训练的类中的对象(目前MS-COCO数据集的80个类),不考虑对象标签分类错误。虽然MaskFusion可以处理一些非刚性物体的存在,例如人类,但是通过将它们从地图上移除,跟踪和重构仅限于刚性物体。在没有三维模型的情况下,跟踪几何信息较少的小目标会产生误差。
五、BundleFusion
BundleFusion_ Real-time Globally Consistent 3D Reconstruction 3D实时重建。
实时、高质量、大规模场景的3D扫描是混合现实和机器人应用的关键。
然而,可扩展性带来了姿态估计漂移的挑战,在累积模型中引入了严重的错误。
这种方法通常需要数小时的离线处理才能全局地纠正模型错误。
最近的在线方法显示了引人注目的结果,但存在以下问题:
(1)需要几分钟的时间来进行在线纠正,阻止了真正的实时使用;
(2)帧对帧(或帧对模型)位姿估计过于脆弱,导致跟踪失败较多;
(3)只支持非结构化的基于点的表示,这限制了扫描的质量和适用性。
我们系统地解决这些问题与一个新颖的,实时的,端到端重建框架。
其核心是一种鲁棒位姿估计策略,通过考虑RGB-D输入的完整历史,用一种有效的分层方法对全局相机位姿集的每帧进行优化。
我们消除了对时间跟踪的严重依赖,并不断地对全局优化的帧进行定位。提出了一个可并行优化框架,该框架采用基于稀疏特征和密集的几何与光度匹配的对应。
我们的方法实时估计全局优化(即束调整BA)姿态,支持从总体跟踪失败中恢复(即重定位)的鲁棒跟踪,并在一个单一框架内实时重新估计3D模型以确保全局一致性。
我们的方法在质量上优于最先进的在线系统,但以前所未有的速度和扫描完整性。提出的框架导致了一个全面的针对大型室内环境的在线扫描解决方案,易用并且能得到高质量的结果。
编辑:lyn
-
无功补偿原理基础知识详解2023-08-11 2122
-
关于MOS管的基础知识2023-05-23 2565
-
关于mos管的基础知识2023-01-29 6351
-
介绍关于编程的基础知识2021-07-27 2062
-
机器视觉基础知识详解模板2021-05-28 1252
-
【转】变压器基础知识_制作流程_详解2018-08-05 4508
-
FreeRTOS基础知识详解pdf下载2018-03-29 1599
-
MEMS传感器概念、分类等基础知识详解2016-12-06 10602
-
嵌入式系统基础知识2016-03-03 909
-
关于protel的一些基础知识2012-05-31 3459
-
红外基础知识2011-11-02 1060
-
安防技术基础知识名词详解大全2008-12-29 1155
-
电子元器件基础知识详解2007-10-08 2194
全部0条评论

快来发表一下你的评论吧 !
