

解读一下DeBERTa在BERT上有哪些改造
描述
DeBERTa刷新了GLUE的榜首,本文解读一下DeBERTa在BERT上有哪些改造
DeBERTa对BERT的改造主要在三点
分散注意力机制
为了更充分利用相对位置信息,输入的input embedding不再加入pos embedding, 而是input在经过transformer编码后,在encoder段与“decoder”端 通过相对位置计算分散注意力
增强解码器(有点迷)
为了解决预训练和微调时,因为任务的不同而预训练和微调阶段的gap,加入了一个增强decoder端,这个decoder并非transformer的decoder端(需要decoder端有输入那种),只是直观上起到了一个decoder作用
解码器前接入了绝对位置embedding,避免只有相对位置而丢失了绝对位置embedding
其实本质就是在原始BERT的倒数第二层transformer中间层插入了一个分散注意力计算
训练trick
训练时加入了一些数据扰动
mask策略中不替换词,变为替换成词的pos embedding
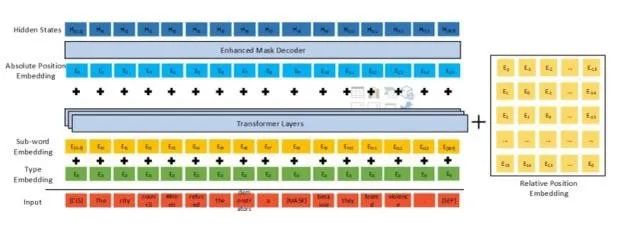
分散注意力机制
motivation
BERT加入位置信息的方法是在输入embedding中加入postion embedding, pos embedding与char embedding和segment embedding混在一起,这种早期就合并了位置信息在计算self-attention时,表达能力受限,维护信息非常被弱化了
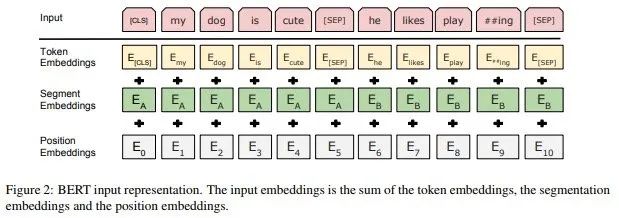
BERT embedding
本文的motivation就是将pos信息拆分出来,单独编码后去content 和自己求attention,增加计算 “位置-内容” 和 “内容-位置” 注意力的分散Disentangled Attention
Disentangled Attention计算方法
分散注意力机制首先在input中分离相对位置embedding,在原始char embedding+segment embedding经过编码成后,与相对位置计算attention,
即是内容编码,是相对的位置编码, attention的计算中,融合了位置-位置,内容-内容,位置-内容,内容-位置
相对位置的计算
限制了相对距离,相距大于一个阈值时距离就无效了,此时距离设定为一个常数,距离在有效范围内时,用参数用控制
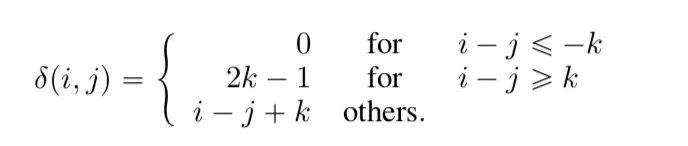
增强型解码器
强行叫做解码器
用 EMD( enhanced mask decoder) 来代替原 BERT 的 SoftMax 层预测遮盖的 Token。因为我们在精调时一般会在 BERT 的输出后接一个特定任务的 Decoder,但是在预训练时却并没有这个 Decoder;所以本文在预训练时用一个两层的 Transformer decoder 和一个 SoftMax 作为 Decoder。其实就是给后层的Transformer encoder换了个名字,千万别以为是用到了Transformer 的 Decoder端
绝对位置embedding
在decoder前有一个骚操作是在这里加入了一层绝对位置embedding来弥补一下只有相对位置的损失,比如“超市旁新开了一个商场”,当mask的词是“超市”,“商场”,时,只有相对位置时没法区分这两个词的信息,因此decoder中加入一层
一些训练tricks
将BERT的训练策略中,mask有10%的情况是不做任何替换,这种情况attention偏向自己会非常明显,DeBeta将不做替换改成了换位该位置词绝对位置的pos embedding, 实验中明显能看到这种情况下的attention对自身依赖减弱
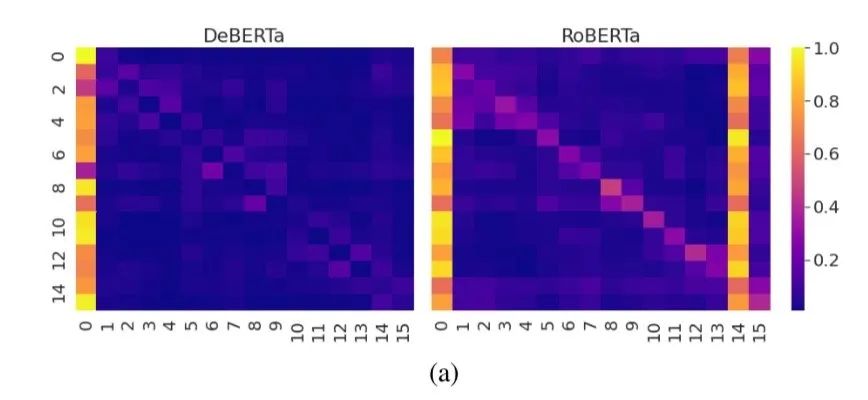
在训练下游任务时,给训练集做了一点扰动来增强模型的鲁棒性
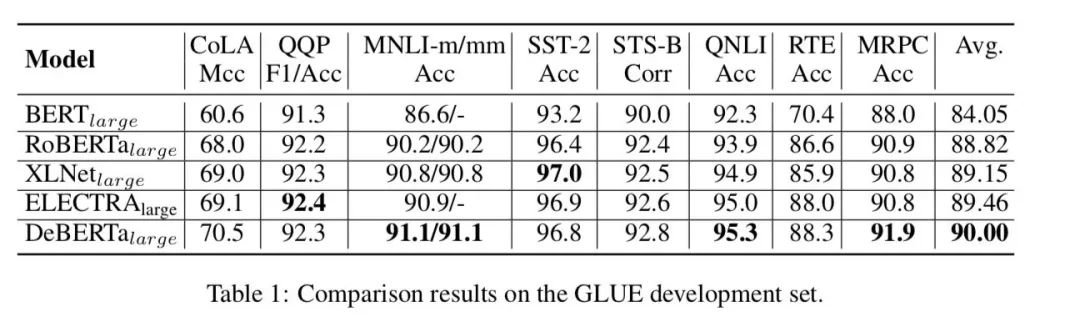
效果
DeBERTa large目前是GLUE的榜首,在大部分任务上整体效果相比还是有一丢丢提升
责任编辑:lq
-
MP5屏幕碎了,能不能改造一下2011-08-06 4276
-
【OK210试用体验】 我的开发板学习日记一LINUX下程序解读LED2015-09-29 3123
-
谁手上有ADC2011资料,分享一下2016-01-17 5442
-
BERT原理详解2019-07-02 1428
-
请帮助解读一下这个声控模块的电路原理图?2021-05-17 1864
-
BERT模型的PyTorch实现2018-11-13 14724
-
专家解读GPT 2.0 VS BERT!GPT 2.0到底做了什么2019-02-18 10824
-
电磁炉加热一下就停一下什么原因及解决办法2020-03-18 289899
-
电磁炉加热一下就停一下什么原因2021-06-04 42372
-
一篇BERT用于推荐系统的文章2020-11-03 4044
-
如何优雅地使用bert处理长文本2020-12-26 9778
-
微软DeBERTa登顶SuperGLUE排行榜2021-02-05 2257
-
NLP入门之Bert的前世今生2023-02-22 1699
-
一个电路感受一下MOS管和三极管在功能上有什么区别?2023-11-13 1833
-
支付宝发布新一代AI视觉搜索“探一下”2024-12-31 1354
全部0条评论

快来发表一下你的评论吧 !
