

浅谈GPU: 衡量计算效能的正确姿势(1)
描述
琢磨了好几天,也不知道公众号第一篇正式文章应该怎么写。现在很后悔在朋友圈高调公开公众号,还竟敢宣称有15年行业经验,大家不要信以为真,其实不过是一年经验重复了十几年而已。连知乎的小朋友都知道问问题的正确姿势,我真是有些汗颜。
言归正状,万事开头难,现在骑虎难下,也只好勉力为之。在这里想先介绍些今后文章经常会涉及的一些指标概念,希望能达成基本的共识,到时候交流起来会方便些。
Lateny和Throughput
1 延迟(latency),完成一个任务所需要的时间。
2.吞吐量(throughput),单位时间完成的任务量。
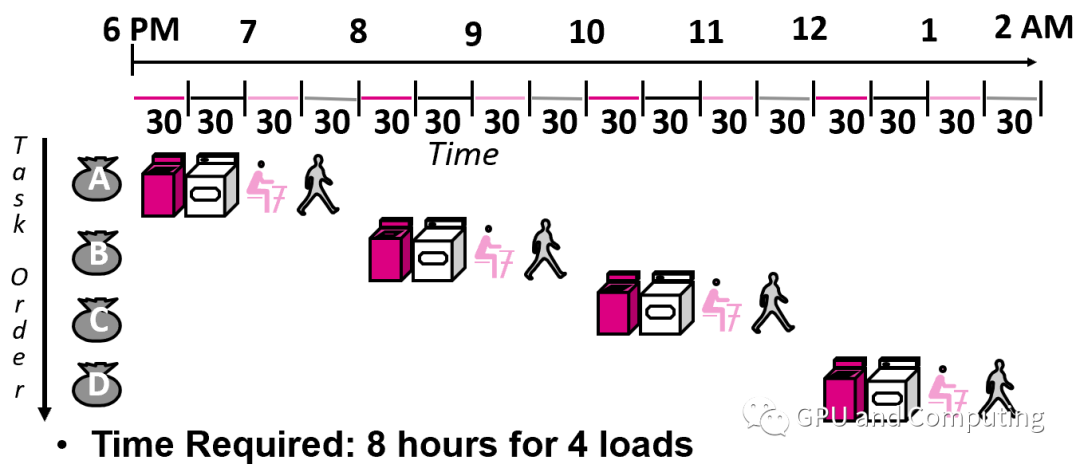
体系结构大神David.A.Patterson在他的著作《计算机组成和设计》用洗衣过程来做譬喻。洗衣过程由清洗,烘干,折叠,收纳四个环节组成,每个环节耗时30分钟,所以每次洗衣任务的latency是2个小时,没有优化以前,8个小时的完成4次洗衣任务,所以throughput只有0.5。
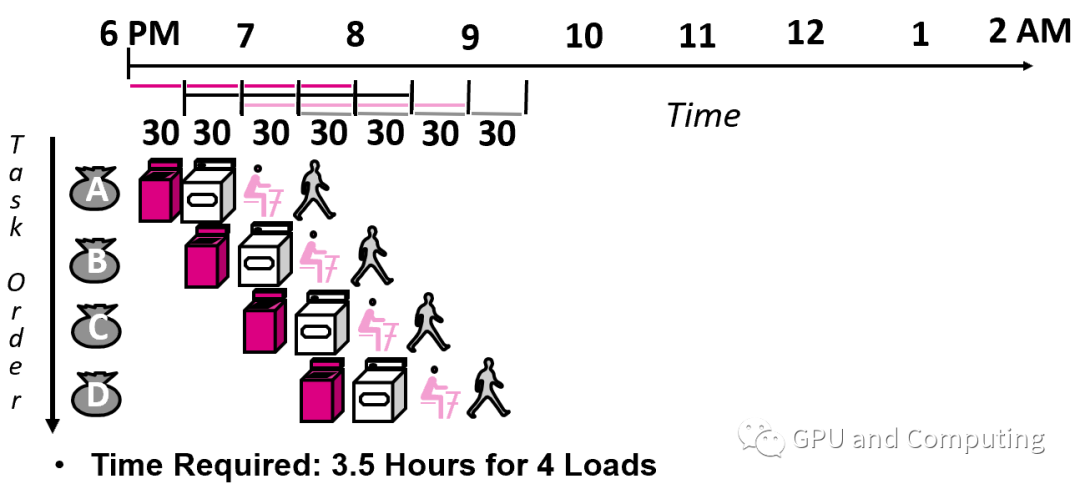
经过流水线改造以后,效率得到改善,虽然每次洗衣还是花费2小时,但单位时间完成的任务量大大提升,4次洗衣任务只花了3.5个小时。
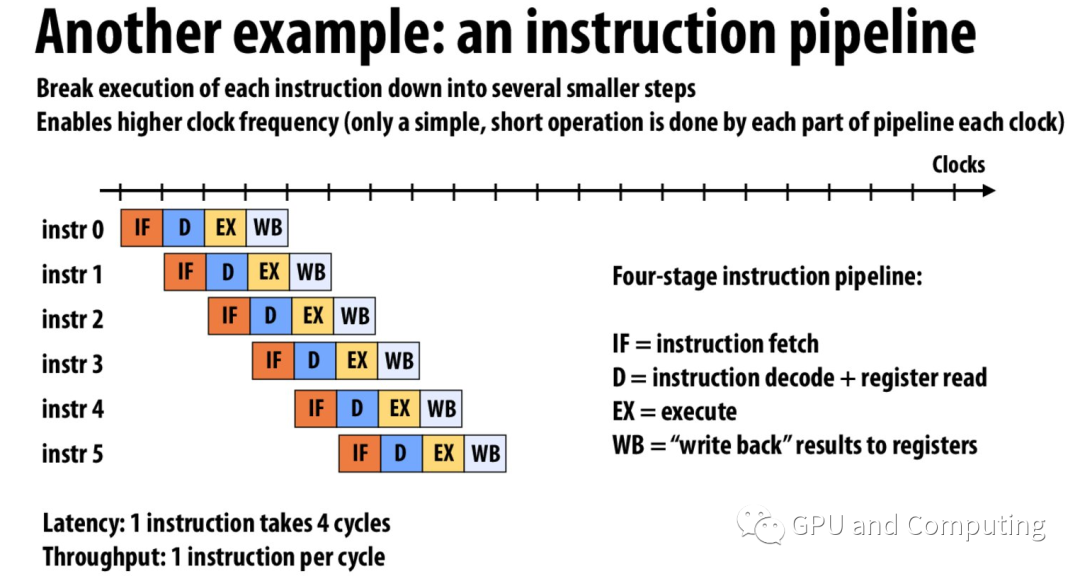
我们可以把生活常识映射到处理器的流水线(Pipeline)设计,处理器的指令Pipeline通过实现指令级的并行(Instruction Level Parallelism)来提高throughput。这种ILP的优化对码农们就是免费的午餐,躺着程序性能就上去了。
另外,如下图,我们也可以通过多核CPU或者内置很多计算单元的GPU来提高程序整体的性能(throughput),这种优化属于线程级并行(Thread Level Parallelism)。相比ILP,TLP对码农不太友好,不再供应免费的午餐,我们需要编写多线程程序,甚至通过专门的接口(CUDA/OpenCL)让CPU/GPU忙碌起来,才能得到性能的提升。
第一篇先写到这儿了,再长就没人看了,接下来会介绍其它几个重要概念。
编辑:lyn
-
柴油发电机容量计算2021-09-10 2060
-
电池的电量计算2021-08-12 6329
-
浅谈GPU: 衡量计算效能的正确姿势(2)2021-04-16 3457
-
线圈电感量计算软件2016-11-10 1341
-
电感量计算软件2015-11-18 5015
-
常用流量计算软件2011-04-18 1470
-
钢筋工程量计算规则2011-01-01 1043
-
CDMA的容量计算公式2009-09-18 15492
-
空心线圈电感量计算2009-08-07 3125
-
能源使用量计算:如何养护成本驱动2009-04-21 1031
-
gprs流量计算软件2008-06-15 12447
-
流量计算机2008-05-19 2040
全部0条评论

快来发表一下你的评论吧 !
