

浅谈GPU: 衡量计算效能的正确姿势(2)
描述
这次我们准备聊下决定系统计算性能的两大关键指标,1. 浮点运算能力(FLOPS), 2. 内存带宽(Memory Bandwidth)。
一· 为什么这两个指标很重要
目前无论是嵌入式系统,PC还是大型服务器都遵循了冯。诺依曼结构。
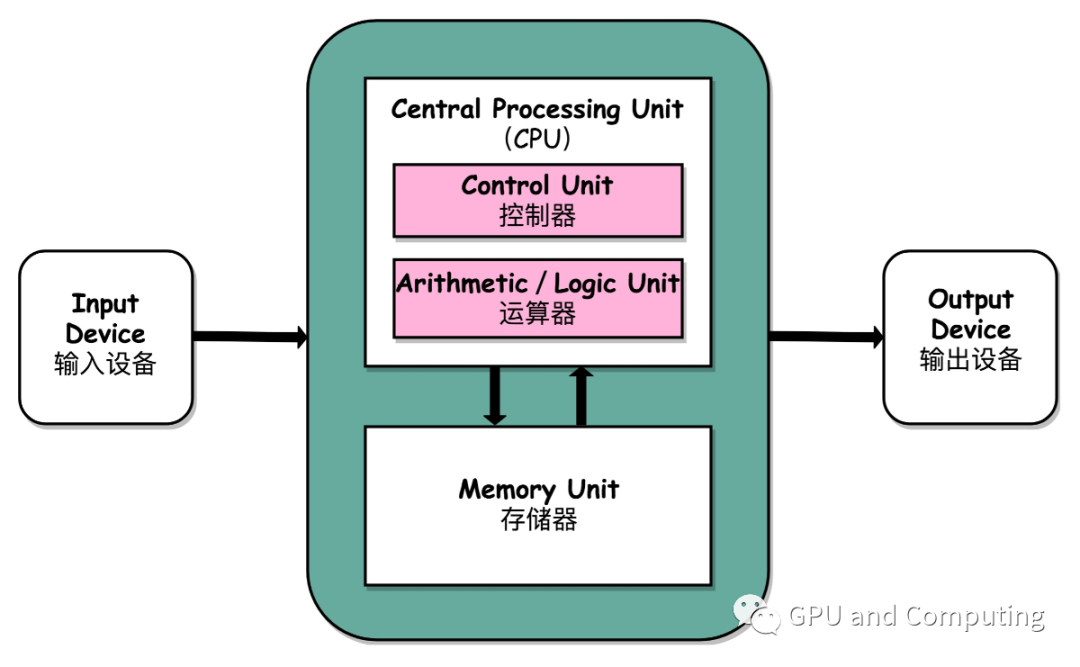
对CPU密集型程序来说,执行时候系统的内部交互主要在处理器(包括控制器和运算器)和存储器之间展开,大概是如下图过程。
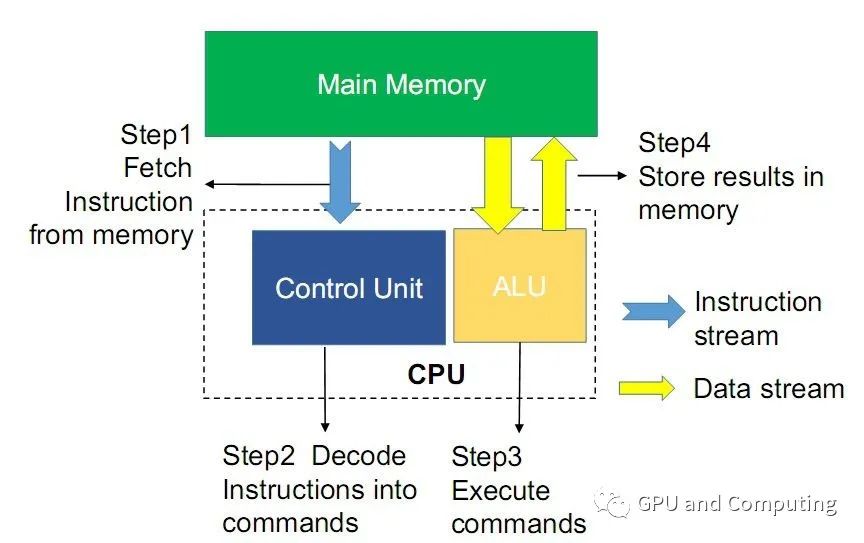
所以CPU的处理能力以及访存的效率对程序的性能起到了关键作用。大家知道计算一个程序执行时间的公式如下(假设该程序是CPU Bound),
程序执行时间(time) = 程序指令数目(Intructions) * 指令的平均时钟数(CPI, Clock cycles/Instruction) * 时钟周期(Seconds/Clock cycle)
为支持计算所需的精度和广度,CPU/GPU ALU支持浮点运算,单精度甚至双精度都是必须的要求。这里我们引入FLOPS(floating point operations per second)的概念来表征CPU/GPU浮点运算能力,所以针对浮点计算密集型程序,把FLOPS套到上面公式,我们可以用浮点运算数目/FLOPS来估摸程序大概执行时间。
访存效率的重要性我们这里也可以再提一下,以GPU为例,无论是游戏还是深度学习,都有大量的内存读写数据量。比如graphics里,有三角面片模型装载,纹理采样,深度测试(depth test),Alpha混合,以及图像输出等等。深度学习训练的时候,巨大的训练集/测试集输入,迭代过程几十万,百万级别参数读写。如果访存成为瓶颈(Memory Bound),强大的计算能力也无从发挥。
二,如何知道FLOPS 和内存带宽
我们先看下如何得到两个指标的理论数值。
关于内存带宽,假设某款GPU,其显示内存的时钟频率为1546 MHZ,显存的位宽(Interface Width)为384 bit, 则其带宽的理论峰值计算如下,具体也可以参考https://en.wikipedia.org/wiki/Memory_bandwidth。
BW = 1546(clocks per second) * 384(memory interface width) * 2(DDR) / 8(In bytes) = 148GB/s
而GPU的理论FLOPS计算就要微妙很多,各个厂家对演算过程讳莫如深,一般不会公开,我们这里也不多着墨,大家参考厂家给出的数据罢了。ARM的网站写过一篇文章探讨FLOPS营销噱头一地鸡毛的状态,Flipping the FLOPS - how ARM measures GPU compute performance,搜来看看,可以起到心理预防的作用。
相比理论数值,对码农来说,我们更关心是我们程序运行的实际性能数值,这才是关系我们饭碗的要紧之处。假设一个程序的核心运算是如下SAXPY,恰当地部署到GPU或者多核CPU后,比如平均运行时间为1us,我们该如何计算实际访存带宽和FOPS?
int N = 1 《《 22;
void saxpy(float a, float *x, float *y){
for (int i = 0; i 《 n; ++i)
y[i] = a*x[i] + y[i];
}
我们可以看到每次迭代,有三次内存访问(x读一次,y读写各一次),而有两次浮点运算(乘加各一次)。所以实际BW和FOPS的计算如下,
BW = (3 * N * 4) / (1 / 1e9) = 120GB/s
FOPS = (2 * N) / (1 / 1e9) = 20GFLOPS
我们可以把实际数值和理论峰值比较下,确认运算瓶颈在何处,是memory bound还是cpu bound,然后进一步优化,关于这部分内容,我们以后介绍roofline模型的时候还会涉及。
三,ALU和访存的功耗水平
下图来自David A. Patterson的另一本著作《计算机体系结构:量化研究方法》,罗列45nm制程各种类型ALU和访存的功耗大小以及他们相对水平,可以看到32b的内存访问的功耗远超同样位宽大小的运算。
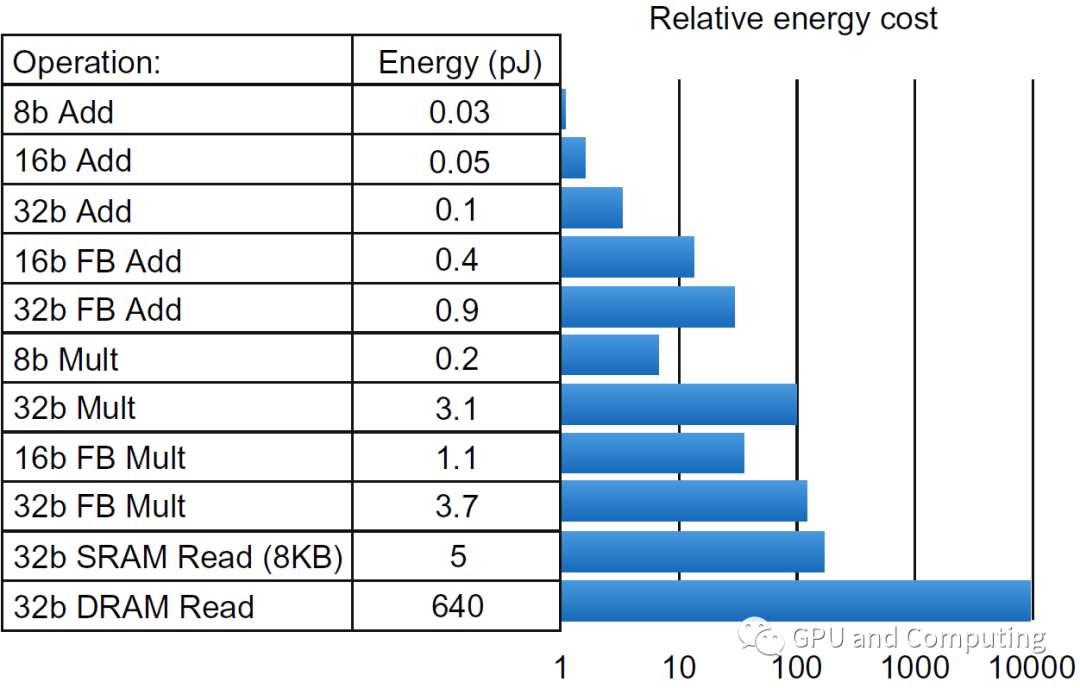
为什么我们要在这里留意功耗水平?移动设备由于电池供电,尺寸大小散热限制,对功耗异常敏感,功耗大小直接决定设备的使用价值。以后我们谈到移动GPU的设计的时候,可以了解如何在消除减少内存访问方面极尽所能。另外比特币矿场矿机,数据中心的服务器,其数目都是以万记,它们更是电老虎,每天的电力消耗才是运营的最大费用,会极大地影响了投资回报率,所以功耗水平有很重要的经济效果。最后目前全民倡导碳中和,绿色计算,身处产业链的我们,从硬件和软件角度,努力提升功耗水平,也有很大社会意义。
编辑:lyn
-
调理电路的噪声余量计算如何计算2025-01-21 435
-
柴油发电机容量计算2021-09-10 2049
-
电池的电量计算2021-08-12 6313
-
浅谈GPU: 衡量计算效能的正确姿势(1)2021-04-16 2635
-
线圈电感量计算软件2016-11-10 1324
-
电感量计算软件2015-11-18 4982
-
常用流量计算软件2011-04-18 1457
-
钢筋工程量计算规则2011-01-01 981
-
CDMA的容量计算公式2009-09-18 15465
-
空心线圈电感量计算2009-08-07 3108
-
gprs流量计算软件2008-06-15 12426
-
流量计算机2008-05-19 2021
全部0条评论

快来发表一下你的评论吧 !
