

吴恩达:一个机器学习团队80%的工作应该放在数据准备上
描述
【导读】模型好就能碾压一切吗?吴恩达泼冷水,机器学习发展80%依靠数据集的进步!这也激起了业内对MLOps工具链的关注。
机器学习的进步是模型带来的还是数据带来的,这可能是一个世纪辩题。 吴恩达对此的想法是,一个机器学习团队80%的工作应该放在数据准备上,确保数据质量是最重要的工作,每个人都知道应该如此做,但没人在乎。如果更多地强调以数据为中心而不是以模型为中心,那么机器学习的发展会更快。
当去arxiv上查找机器学习相关的研究时,所有模型都在围绕基准测试展示自己模型的能力,例如Google有BERT,OpenAI有GPT-3,这些模型仅解决了业务问题的20%,在业务场景中取得更好的效果需要更好的数据。 传统软件由代码提供动力,而AI系统是同时使用代码(模型+算法)和数据构建的。以前的工作方式是,当模型效果不理想,我们就会去修改模型,而没有想过可能是数据的问题。 机器学习的进步一直是由提高基准数据集性能的努力所推动的。研究人员的常见做法是在尝试改进代码的同时保持数据固定,以模型改进为中心对模型性能的提升实际上效率是很低的。但是,当数据集大小适中(<10,000个示例)时,则需要在代码上进行尝试改进。
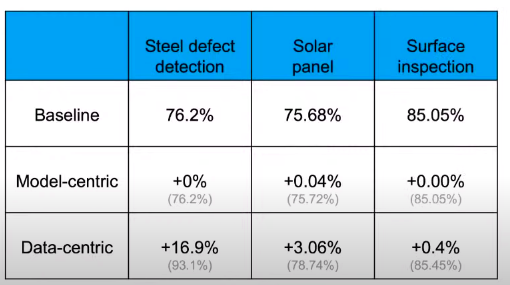
根据剑桥研究人员所做的一项研究,最重要但仍经常被忽略的问题是数据的格式不统一。当数据从不同的源流式传输时,这些源可能具有不同的架构,不同的约定及其存储和访问数据的方式。对于机器学习工程师来说,这是一个繁琐的过程,需要将信息组合成适合机器学习的单个数据集。 小数据的劣势在于少量的噪声数据就会影响模型效果,而大数据量则会使标注工作变得很困难,高质量的标签也是机器学习模型的瓶颈所在。 这番话也引起机器学习界对MLOps的重新思索。
MLOps是什么? MLOps,即Machine Learning和Operations的组合,是ModelOps的子集,是数据科学家与操作专业人员之间进行协作和交流以帮助管理机器学习任务生命周期的一种实践。
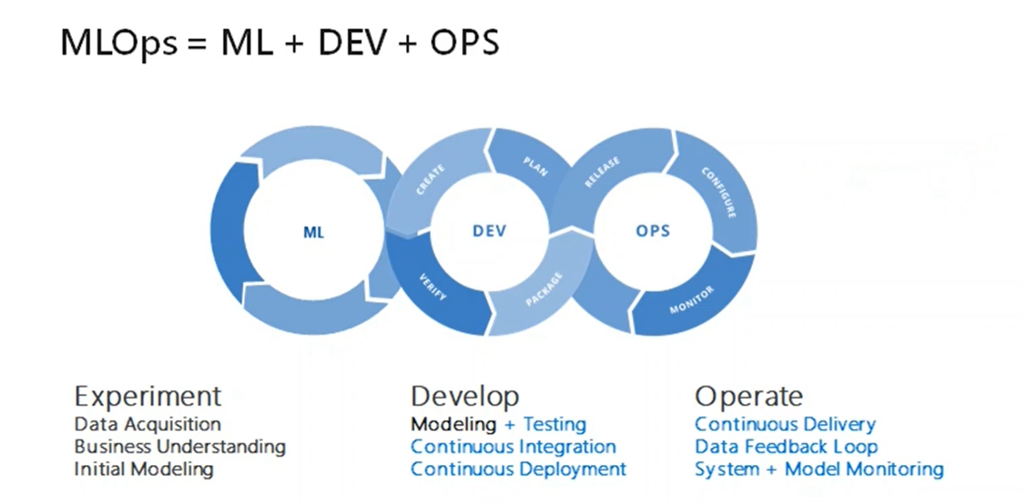
与DevOps或DataOps方法类似,MLOps希望提高自动化程度并提高生产ML的质量,同时还要关注业务和法规要求。 互联网公司通常用有大量的数据,而如果在缺少数据的应用场景中进行部署AI时,例如农业场景 ,你不能指望自己有一百万台拖拉机为自己收集数据。 基于MLOps,吴恩达也提出几点建议:
MLOps的最重要任务是提供高质量数据。
标签的一致性也很重要。检验标签是否有自己所管辖的明确界限,即使标签的定义是好的,缺乏一致性也会导致模型效果不佳。
系统地改善baseline模型上的数据质量要比追求具有低质量数据的最新模型要好。
如果训练期间出现错误,那么应当采取以数据为中心的方法。
如果以数据为中心,对于较小的数据集(<10,000个样本),则数据容量上存在很大的改进空间。
当使用较小的数据集时,提高数据质量的工具和服务至关重要。
一致性的数据定义,涵盖所有边界情况,从生产数据中得到及时的反馈,数据集大小合适。 吴恩达同时建议不要指望工程师去尝试改善数据集。相反,他希望ML社区开发更多MLOps工具,以帮助产生高质量的数据集和AI系统,并使他们具有可重复性。除此之外,MLOps是一个新生领域,MLOps团队的最重要目标应该是确保整个项目各个阶段的高质量和一致的数据流。
一些MLOps的工具已经取得了不错的成绩。 Alteryx处于自助数据分析运动的最前沿。公司的平台“ Designer”旨在快速发现、准备和分析客户的详细信息。该工具用于易于使用的界面,用户可以连接和清除数据仓库。Alteryx的工具还包括空间文件的数据混合,可以将其附加到其他第三方数据。
Paxata提供自适应的信息平台,它具有灵活的部署和自助操作。它使分析人员和数据科学家可以收集多个原始数据集,并将它们转换成有价值的信息,这些信息可以立即转换为执行模型训练所需要的格式。该平台是基于所见即所得设计,具有电子表格风格的数据展示,因此用户无需学习新工具。此外,该平台能够提供算法协助以推断所收集数据的含义。 TIBCO软件最近在这个快速发展的领域中崭露头角。它允许用户连接、清理、合并和整理来自不同来源的数据,其中还包括大数据存储。该软件使用户可以通过简单的在线数据整理进行数据分析,并且提供完整的API支持,可以根据自己的个性化需求进行更改。
网友表示,吴恩达老师说的太真实了!

也有网友表示,机器学习更像是数据分析,模型的搭建就是构建pipelines。
责任编辑:lq
-
吴恩达机器学习之Coursera-week2020-06-19 3539
-
吴恩达深度学习2020-05-28 2628
-
吴恩达机器学习笔记分享2020-05-25 1333
-
关于吴恩达机器学习2020-04-22 1705
-
吴恩达机器学习clustering分类算法2020-03-27 1937
-
吴恩达机器学习实际训练模型过程2020-03-09 1599
-
吴恩达团队最新成果,运用AI精确预测患者在高血压治疗中可能获得的效果2019-03-27 3624
-
机器学习训练秘籍——吴恩达2018-11-30 2952
-
吴恩达:将引领下一波机器学习技术”的迁移学习到底好在哪?2018-10-27 3447
-
吴恩达的7条机器学习训练秘籍2018-09-20 2325
-
吴恩达宣布Deeplearning.ai即将推出,将主要精力放在了深度学习上2018-06-04 1137
-
google机器学习团队开发机器学习系统Seti的一些经验教训2018-06-01 2042
-
吴恩达:机器学习和人工智能的未来2018-05-18 6804
-
吴恩达:如果高管懂机器学习 数百万人将会失业2018-05-17 666
全部0条评论

快来发表一下你的评论吧 !
