

应用的编程环境HALCON18.05
描述
最近特无聊是吧,那在家学点做点科技类的小事业吧。
应用的编程环境HALCON18.05,这里讲一种常用套路
* 表示程序注释
1. 采图或者自己写下字母和数字,分成训练与识别两个部分;
2. 阈值分割出字符;
3. 创建手写体识别器;
4. 训练该识别器;
5. 执行识别;
具体过程如下:
**--------------------------------------
*(1) Training of the OCR ofhandwrite letter
* 关闭更新
dev_update_off()
* Set theimage path (make sure, that you have set HALCONIMAGES to the HALCON imagedirectory)
*
* Step 0:Preparations 文件路径
FontName:= 'E:/Halcon/OCR/handwirteC/'
*
* Step 1:Segmentation 读图与字符分割
dev_update_window('off')
dev_get_window(WindowHandle)
read_image(Image,FontName+ '/handword1.jpg')

有时间可以写各种字符,每个相同字符多写几次,越多越好,增加训练的精准度;
把这栏作为训练样本
阈值分割出字符。注意:这里要用一次膨胀,把i与j这些字符的点与字符体连接在一起,构成一个整体字符;

threshold(ImageReduced, RawSegmentation, 0, 75)
* Connectthe i's and j's with their dots
* 将i与j的点与线连接起来,构成一个整体
dilation_circle(RawSegmentation, RegionDilation, 19)
dev_set_color('green')
dev_display(RegionDilation)
connection(RegionDilation, ConnectedRegions)
* Reduceeach connected component (character) to its original shape
intersection(ConnectedRegions, RegionDilation, RegionIntersection)
count_obj(ConnectedRegions, Number)
sort_region(RegionIntersection, FinalLetters, 'first_point', 'true', 'column')
*Displaysegments
*显示分割块
dev_clear_window()
dev_display(ImageReduced)
dev_set_color('green')
dev_set_line_width(2)
dev_set_shape('rectangle1')
dev_set_draw('margin')
dev_display(FinalLetters)
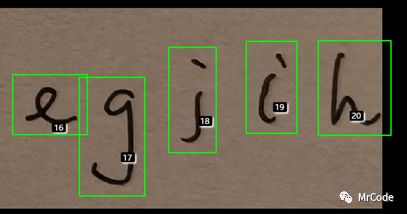
我们来检查一下各个字符的分割与排序情况,尤其是对于i,j这类字符有没有实现整体性

我们看到20个字母被分割成了21个,原因就是这个j 没有被构成一个整体。然后我们再次调整一下dialation参数到22,并且注意也被膨胀太多了把相邻字母也连进来了
dilation_circle(RawSegmentation, RegionDilation, 22)
这次很好,20个字母完整分割
* Step2: Training filegeneration
* 把teacher信号自己手写进来,创建训练文件TrainingFileName,训练文件都是.trf格式的,可以在硬盘里查询到。
*这里我们用append的函数把teacher信号一个一个地与被训练字符联系起来。
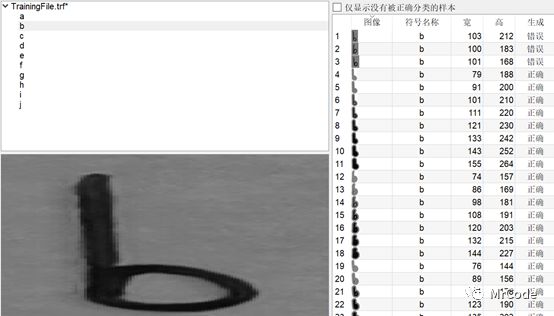
TrainingNames:= ['b','b','a','b','d','c','e','f','h','i','i','i','d','c','e','e','g','j','i','h']
*训练文件TrainingFileName
TrainingFileName:= FontName + 'TrainingFile.trf'
sort_region(FinalLetters, SortedRegions, 'first_point', 'true', 'column')
shape_trans(SortedRegions, RegionTrans, 'rectangle1')
area_center(RegionTrans, Area, Row, Column)
MeanRow:= mean(Row)
dev_set_check('give_error')
for I :=0 to |TrainingNames| -1by 1
select_obj (SortedRegions, CharaterRegions,I+1)
append_ocr_trainf (CharaterRegions, Image,TrainingNames[I], TrainingFileName)
disp_message(WindowHandle, TrainingNames[I], 'image', MeanRow - 140, Column[I] - 6,'yellow', 'false')
endfor

可以查询一下训练文件
* Step3: Training 执行训练
CharNames:= uniq(sort(TrainingNames))
create_ocr_class_mlp(8, 10, 'constant', 'default', CharNames, 10, 'none', 10, 42, OCRHandle)
trainf_ocr_class_mlp(OCRHandle, TrainingFileName, 200, 1, 0.01, Error, ErrorLog)
*write_ocr_class_mlp产生一个.omc文件
write_ocr_class_mlp(OCRHandle, FontName+'Classifier')
clear_ocr_class_mlp(OCRHandle)
_________________________________
Do OCR执行识别
打开新的图片,建立被识别区域,步骤如下

* Step 0: Preparations
FontName :='E:/Halcon/OCR/handwirteC/'
TrainingDocument:=FontName+'Classifier.omc'
*TrainingDocument:=FontName+'Class1.omc'
*
* Step 1: Segmentation
dev_update_window ('off')
dev_get_window (WindowHandle)
read_image (Image,FontName+'/handword1.jpg')
gen_rectangle1 (ROI_new, 2077.7,301.848, 2327.78, 2235.87)
reduce_domain (Image, ROI_new,ImageReducedNew)
binary_threshold (ImageReducedNew,Region_1, 'max_separability', 'dark', UsedThreshold1)
dilation_circle (Region_1,RegionDilation, 25.5)
dev_set_color ('green')
dev_display (RegionDilation)
connection (RegionDilation,ConnectedRegions)
intersection (ConnectedRegions,RegionDilation, RegionIntersection)
sort_region (RegionIntersection,Characters, 'character', 'true', 'row')
在这里,我们还是要查看一下膨胀的设置是否正确,尤其对于i,j类字符

*Step 3 读取分类器
read_ocr_class_mlp(TrainingDocument, OCRHandle1)
*Classification
do_ocr_multi_class_mlp(Characters, Image, OCRHandle1, Class, Confidence)
* Step 4 Display results
area_center(Characters, Area, Row, Column)
dev_display(Image)
set_display_font(WindowHandle, 16, 'sans', 'true', 'false')
disp_message(WindowHandle, Class, 'image', Row - 146, Column + 8, 'blue', 'false')
*set_display_font(WindowHandle, 16, 'mono', 'true', 'false')
disp_message(WindowHandle, 'Classification result', 'window', 12, 12, 'black', 'true')

我们看到手写体的确不容易做好,这里与训练样本有关系,所以需要更大的样本量来优化识别器。
这里我们可以打开训练文件.trf,在不自己继续添加样本的情况下做一下无监督学习,把已有的字体做扭曲与各种变换的训练。
然后再次训练这个.trf文件,替换掉之前的训练文件。
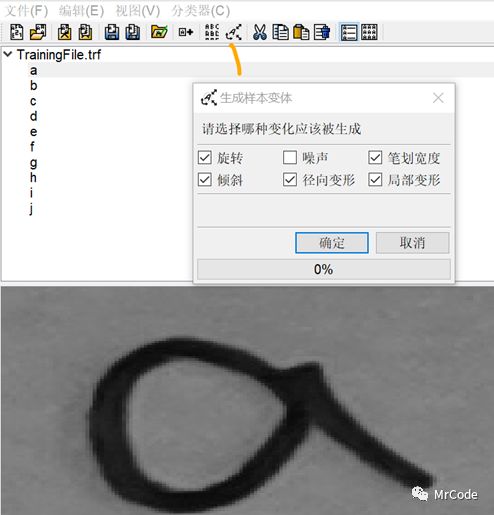

训练完后,再次读取新的分类器,执行OCR, 这里重复代码
*Step 3 读取分类器
read_ocr_class_mlp(TrainingDocument, OCRHandle1)
*Classification
do_ocr_multi_class_mlp(Characters, Image, OCRHandle1, Class, Confidence)
* Step 4 Display results
area_center(Characters, Area, Row, Column)
dev_display(Image)
set_display_font(WindowHandle, 16, 'sans', 'true', 'false')
disp_message(WindowHandle, Class, 'image', Row - 146, Column + 8, 'blue', 'false')
*set_display_font(WindowHandle, 16, 'mono', 'true', 'false')
disp_message(WindowHandle, 'Classification result', 'window', 12, 12, 'black', 'true')
我们看到,新的识别器(上图)效果好于第一次的识别器(下图)
从 7/12提高到8/12
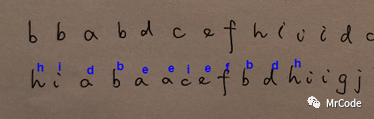

最后有必要就可以写操作界面了, 这里不再赘述
责任编辑:lq
-
Labview与Halcon图片Image互相转换2024-06-27 6560
-
halcon与LabVIEW Vision混合编程接口问题2016-06-29 20233
-
Labview里面使用Halcon的函数。 方法一:直接调用Halcon的函数。2016-08-15 54376
-
求助:labview与halcon之间的对象转换2016-08-24 12315
-
labview通过.NET调用Halcon函数示例2019-05-07 9404
-
Labview调用Halcon直接调用dll2019-06-14 6465
-
labview调用halcon推理2019-12-02 5879
-
LabVIEW调用Halcon程序的操作步骤2021-07-30 17259
-
Halcon9.0编程技术详解2015-12-22 743
-
在基于Arm的平台上使用HALCON免费下载2020-12-08 1591
-
HALCON项目应使用哪种编程语言2021-08-18 8019
-
HALCON机器视觉软件有哪些优点?2021-08-25 12485
-
labview联合halcon的编程方法2023-05-23 1188
-
如何选择Halcon算法库应用软件集成开发环境2023-06-25 1082
-
史上最全VisionPro和Halcon 的详细对比2023-06-26 5235
全部0条评论

快来发表一下你的评论吧 !
