

OpenAI又放大招:连接文本与图像的CLIP
描述
2020年,通用模型产生了经济价值,特别是GPT-3,它的出现证明了大型语言模型具有惊人的语言能力,并且在执行其他任务方面也毫不逊色。
2021年,OpenAI 联合创始人 Ilya Sutskever预测语言模型会转向视觉领域。他说:“下一代模型,或许可以针对文本输入,从而编辑和生成图像。”
听话听音!OpenAI 践行了这一想法,几个小时前,OpenAI通过官方推特发布了两个崭新的网络,一个叫DALL-E(参见今天推送的头条),能够通过给定的文本创建出图片;一个叫CLIP,能够将图像映射到文本描述的类别中。
其中,CLIP可以通过自然语言监督有效学习视觉概念,从而解决目前深度学习主流方法存在的几个问题:
1.需要大量的训练数据集,从而导致较高的创建成本。
2.标准的视觉模型,往往只擅长一类任务,迁移到其他任务,需要花费巨大的成本。
3.在基准上表现良好的模型,在测试中往往不尽人意。
具体而言,OpenAI从互联网收集的4亿(图像、文本)对的数据集,在预训练之后,用自然语言描述所学的视觉概念,从而使模型能够在zero-shot状态下转移到下游任务。这种设计类似于GPT-2和GPT-3的“zero-shot”。
这一点非常关键,因为这意味着,可以不直接针对基准进行优化,同时表现出了优越的性能:稳健性差距(robustness gap)缩小了75%,性能和ResNet507相当。换句话说。无需使用其训练的128万个训练样本中的任何一个,即可与原始ResNet-50 在 Image Net Zero-shot的精确度相匹配。
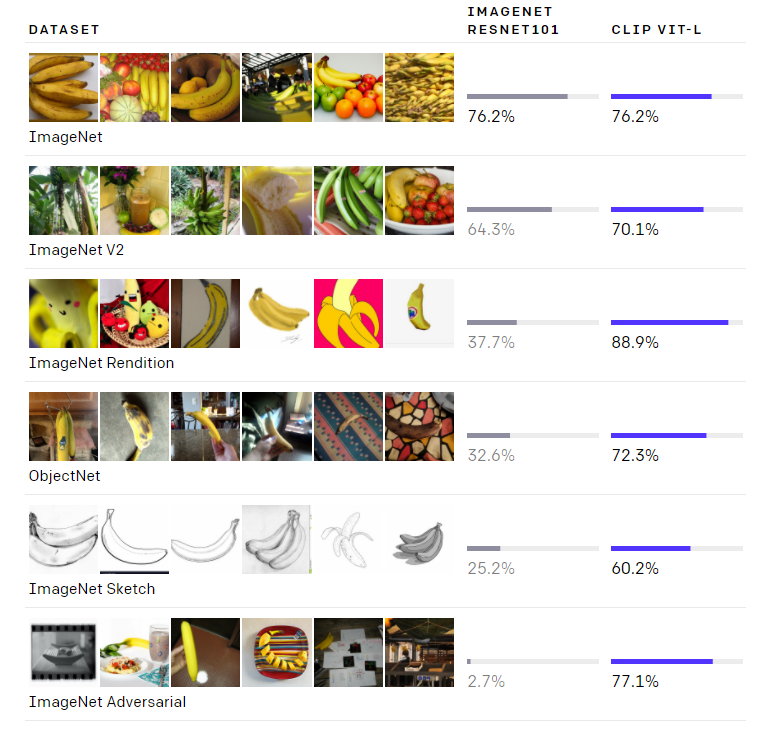
如上图所示,虽然两个模型在ImageNet测试集上的准确度相差无几,但CLIP的性能更能代表在非ImageNet设置下的表现。
CLIP网络中做了大量的工作是关于zero-shot 迁移的学习、自然语言监督、多模态学习。其实,关于零数据学习的想法可以追溯到十年前,但是最近在计算机视觉中火了起来。零数据学习的一个重点是:利用自然语言作为灵活的预测空间,从而实现泛化和迁移。另外,在2013年,斯坦福大学的Richer Socher通过训练CIFAR-10上的一个模型,在词向量嵌入空间中进行预测,并表明模型可以预测两个“未见过”的类别。Richer的工作提供了一个概念证明。
CLIP是过去一年,从自然语言监督中学习视觉表征工作中的一部分。CLIP使用了更现代的架构,如Transformer,包括探索自回归语言建模的Virtex,研究掩蔽语言建模的ICMLM等等。
1
方法
前面也提到,CLIP训练的数据来源于互联网上4亿数据对。用这些数据,CLIP需要完成的任务是:给定一幅图像,在32,768个随机抽样的文本片段中,找到能够匹配的那一个。
完成这个任务,需要CLIP模型学会识别图像中的各种视觉概念,并将概念和图片相关联。因此,CLIP模型可以应用于几乎任意的视觉分类任务。
例如,如果一个数据集的任务是对狗与猫的照片进行分类,而CLIP模型预测 “一张狗的照片 ”和 “一张猫的照片 ”这两个文字描述哪个更匹配。
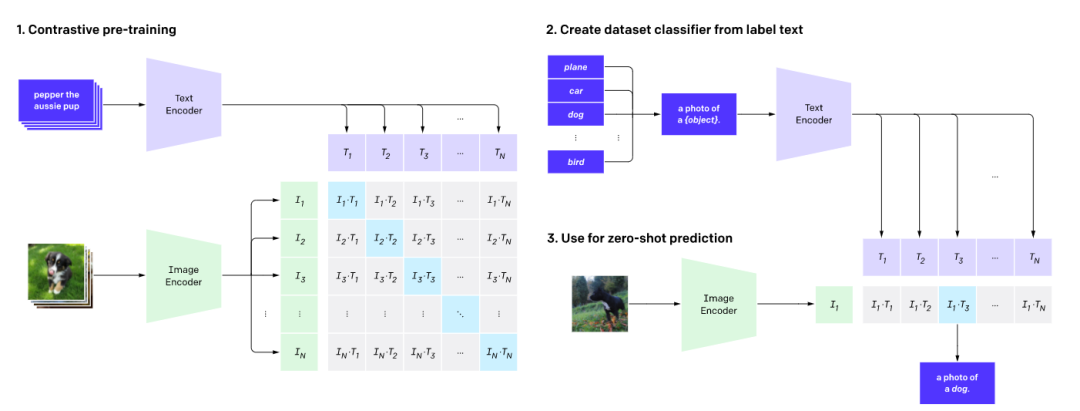
如上图所示,CLIP网络工作流程:预训练图编码器和文本编码器,以预测数据集中哪些图像与哪些文本配对。然后,将CLIP转换为zero-shot分类器。
此外,将数据集的所有类转换为诸如“一只狗的照片”之类的标签,并预测最佳配对的图像。
总体而言,CLIP能够解决:
1.昂贵的数据集:ImageNet中1400万张图片的标注,动用了25,000名劳动力。相比之下,CLIP使用的是已经在互联网上公开提供的文本-图像对。自我监督学习、对比方法、自我训练方法和生成式建模也可以减少对标注图像的依赖。
2.任务单一:CLIP可以适用于执行各种视觉分类任务,而不需要额外的训练。
3.实际应用性能不佳:深度学习中“基准性能”与“实际性能”之间存在差距是一直以来的“痛”。这种差距之所以会出现,是因为模型“作弊”,即仅优化其在基准上的性能,就像一个学生仅仅通过研究过去几年的试题就能通过考试一样。
CLIP模型可以不必在数据上训练,而是直接在基准上进行评估,因此无法以这种方式来“作弊”。此外,为了验证“作弊的假设”,测量了CLIP在有能力“研究” ImageNet时性能会如何变化。
当线性分类器根据CLIP的特性安装时,线性分类器能够将CLIP在ImageNet测试仪上的准确性提高近10%。但是,在评估“鲁棒性”的性能时,这个分类器在其余7个数据集的评估套件中并没有取得更好的平均表现。
2
优势1. CLIP非常高效
CLIP从未经过滤的、变化多端的、极其嘈杂的数据中学习,且希望能够在零样本的情况下使用。从GPT-2和GPT-3中,我们可以知道,基于此类数据训练的模型可以实现出色的零样本性能;但是,这类模型需要大量的训练计算。为了减少所需的计算,我们专注研究算法,以提高我们所使用方法的训练效率。我们介绍了两种能够节省大量计算的算法。
第一个算法是采用对比目标(contrastive objective),将文本与图像连接起来。最初我们探索了一种类似于VirTex的图像到文本的方法,但这种方法在拓展以实现最先进的性能时遇到了困难。在一些小型与中型实验中,我们发现CLIP所使用的对比目标在零样本ImageNet分类中的效率提高了4到10倍。
第二个算法是采用Vision Transformer,这个算法使我们的计算效率比在标准ResNet上提高了3倍。最后,性能最好的CLIP模型与现有的大规模图像模型相似,在256个GPU上训练了2周。我们最初是尝试训练图像到字幕的语言模型,但发现这种方法在零样本迁移方面遇到了困难。在16 GPU的日实验中,一个语言在训练了4亿张图像后,在ImageNet上仅达到16%的准确性。CLIP的效率更高,且以大约快10倍的速度达到了相同的准确度。
2. CLIP灵活且通用
由于CLIP模型可以直接从自然语言中学习许多视觉概念,因此它们比现有的ImageNet模型更加灵活与通用。我们发现,CLIP模型能够在零样本下执行许多不同的任务。为了验证这一点,我们在30多个数据集上测量了CLIP的零样本性能,任务包括细粒度物体分类,地理定位,视频中的动作识别和OCR等。其中,学习OCR时,CLIP取得了在标准ImageNet模型中所无法实现的令人兴奋的效果。
比如,我们对每个零样本分类器的随机非樱桃采摘预测进行了可视化。这一发现也反映在使用线性探测学习评估的标准表示中。
我们测试了26个不同的迁移数据集,其中最佳的CLIP模型在20个数据集上的表现都比最佳的公开ImageNet模型(Noisy Student EfficientNet-L2)出色。
在27个测试任务的数据集中,测试任务包括细粒度物体分类,OCR,视频活动识别以及地理定位,我们发现CLIP模型学会了使用效果更广泛的图像表示。与先前的10种方法相比,CLIP模型的计算效率也更高。
3
局限性
尽管CLIP在识别常见物体上的表现良好,但在一些更抽象或系统的任务(例如计算图像中的物体数量)和更复杂的任务(例如预测照片中距离最近的汽车有多近)上却遇到了困难。
在这两个数据集上,零样本CLIP仅仅比随机猜测要好一点点。与其他模型相比,在非常细粒度分类的任务上,例如区分汽车模型、飞机型号或花卉种类时,零样本CLIP的表现也不好。
对于不包含在其预训练数据集内的图像,CLIP进行泛化的能力也很差。
例如,尽管CLIP学习了功能强大的OCR系统,但从MNIST数据集的手写数字上进行评估时,零样本CLIP只能达到88%的准确度,远远低于人类在数据集中的99.75%精确度。
最后,我们观察到,CLIP的零样本分类器对单词构造或短语构造比较敏感,有时还需要试验和错误“提示引擎”才能表现良好。
4
更广的影响
CLIP允许人们设计自己的分类器,且无需使用任务特定的训练数据。
设计分类的方式会严重影响模型的性能和模型的偏差。例如,我们发现,如果给定一组标签,其中包括Fairface种族标签和少数令人讨厌的术语,例如“犯罪”,“动物”等,那么该模型很可能将大约32.3%的年龄为0至20岁的人的图像化为糟糕的类别。但是,当我们添加“儿童”这一类别时,分类比率将下降到大约8.7%。
此外,由于CLIP不需要任务特定的训练数据,因此它可以更轻松地解锁某些任务。
一些任务可能会增加隐私或监视相关的风险,因此我们通过研究CLIP在名人识别方面的表现来探索这一担忧。对100个名人图像进行识别时,CLIP实际分类的准确率最高为59.2%,对1000个名人进行识别时,准确率最高为43.3%。值得注意的是,尽管通过任务不可知的预训练可以达到这些效果,但与广泛使用的生产级别模型相比,该性能并不具有竞争力。
5
结论
借助CLIP,我们测试了互联网的自然语言上与任务无关的预训练(这种预训练为NLP的最新突破提供了动力)是否可以用来改善其他领域的深度学习性能。
目前,CLIP应用于计算机视觉所取得的效果令我们非常兴奋。像GPT家族一样,CLIP在预训练期间学习了我们通过零样本迁移所展示的各种任务。
CLIP在ImageNet上的表现也令人惊喜,其中零样本评估展示了CLIP模型的强大功能。
责任编辑:lq
-
OpenAI正深入探索文本水印技术的前沿领域2024-08-05 1496
-
马里兰&NYU合力解剖神经网络,CLIP模型神经元形似骷髅头2023-11-23 1463
-
基于AX650N+CLIP的以文搜图展示2023-11-01 2956
-
如何利用CLIP 的2D 图像-文本预习知识进行3D场景理解2023-10-29 3149
-
远程医疗支持系统 | 移远通信又放大招2023-01-13 2861
-
基于将 CLIP 用于下游few-shot图像分类的方案2022-09-27 6943
-
精准图片搜索 OpenAI最新技术 CLIP2021-02-11 3621
-
OpenAI重磅推出语言模型DALL·E和图像识别系统CLIP2021-01-15 5570
-
OpenAI发布根据文字生成图像的人工智能系统2021-01-07 1640
-
华为又放大招:发布正式商用的AI芯片——Ascend 910(昇腾910)2019-09-02 5016
-
Google又放大招,高效实时实现视频目标检测2019-04-08 4941
-
基于连通域的图像文本自动定位2009-12-07 2172
全部0条评论

快来发表一下你的评论吧 !
