

我们可以使用transformer来干什么?
描述
前言
2021年4月,距离论文“Attention is all you need”问市过去快4年了。这篇论文的引用量正在冲击2万大关。
笔者所在的多个学习交流群也经常有不少同学在讨论:transformer是什么?transformer能干啥?为什么要用transformer?transformer能替代cnn吗?怎么让transformer运行快一点?以及各种个样的transformer技术细节问题。
解读以上所有问题不再本文范畴内,但笔者也将在后续文章中继续探索以上问题。本文重点关注:我们用transformer干啥?
我们用transformer干啥?笔者突然发现这句话有两种理解(orz中文博大精深),希望我的语文不是体育老师教的。
疑问句:
我们使用transformer在做什么?
解决什么深度学习任务?
反问句:
我们用用transformer干啥?
为啥不用LSTM和CNN或者其他神经网络呢?
疑问句:用transformer干啥?
谷歌学术看一眼。
为了简洁+有理有据回答这个问题(有缺失之处忘大家指出),笔者首先在谷歌学术上搜寻了一下“Attention is all you need”看了一下被引,到底是哪些文章在引用transformer呢?
“Attention is all you need”被引:19616次。
先看一下前几名引用的被引:
最高引用的“Bert:Pre-training of deep bidirectional transformers for language understanding“被引:17677次。BERT在做自然语言处理领域的语言模型。
第2和4名:“Squeeze and Excitaion Networks”被引用6436次,“Non-local neural networks”。计算机视觉领域,但还没有直接用transformer。
第3名:“Graph attention networks”被引用3413,一种图神经网络,该文也不是直接使用transformer的,但使用了attention。
第5和6名:“Xlnet:Generalized autoregressive pretraining for language undersstanding“ 2318次和 ”Improving language understanding by generative pretraining“ 1876次。自然语言处理领域预训练/语言模型/生成模型。
第7名“self-attention generative adversarial networks” 1508次。基于self-attetnion的生成对抗网络。
第8、9、10都属于自然语言处理领域,一个是GLUE数据集,一个做multi-task learning。
从Top的引用已经看出自然语言处理领域肯定是使用transformer的大头了。随后笔者对熟悉的深度学习任务关键词搜了一下被引用:
计算机视觉领域vision前2的被引用:“Vibert”和“Stand-alone self-attetnion in vision model”分别为385和171次。
语音信号处理领域speech:“state-of-the-art speech recognition with sequence-to-sequence model” 被引710次。
多模态任务modal:“Unicoder-Vl:
A universal encoder for vision and language by cross-model pre-training。
检索领域etrieval:“multilingual universal sentence encoder for semantic retrieval”被引73次
推荐领域recommendation:惊讶的我发现居然只有10篇文章orz。
初步结论:transformer在自然语言处理任务中大火,随后是语音信号领域和计算机视觉领域,然后信息检索领域也有所启航,推荐领域文章不多似乎刚刚起步。
执着的笔者扩大搜索范围直接谷歌搜索了一下,找到了这篇文章BERT4Rec(被引用128):”BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer“。
Github上搜一搜。
排名第1的是HuggingFace/transformers代码库。笔者对这个库还算熟悉,但最近疯狂新增的模型缺失还没有完全跟进过,于是也整理看了一下。
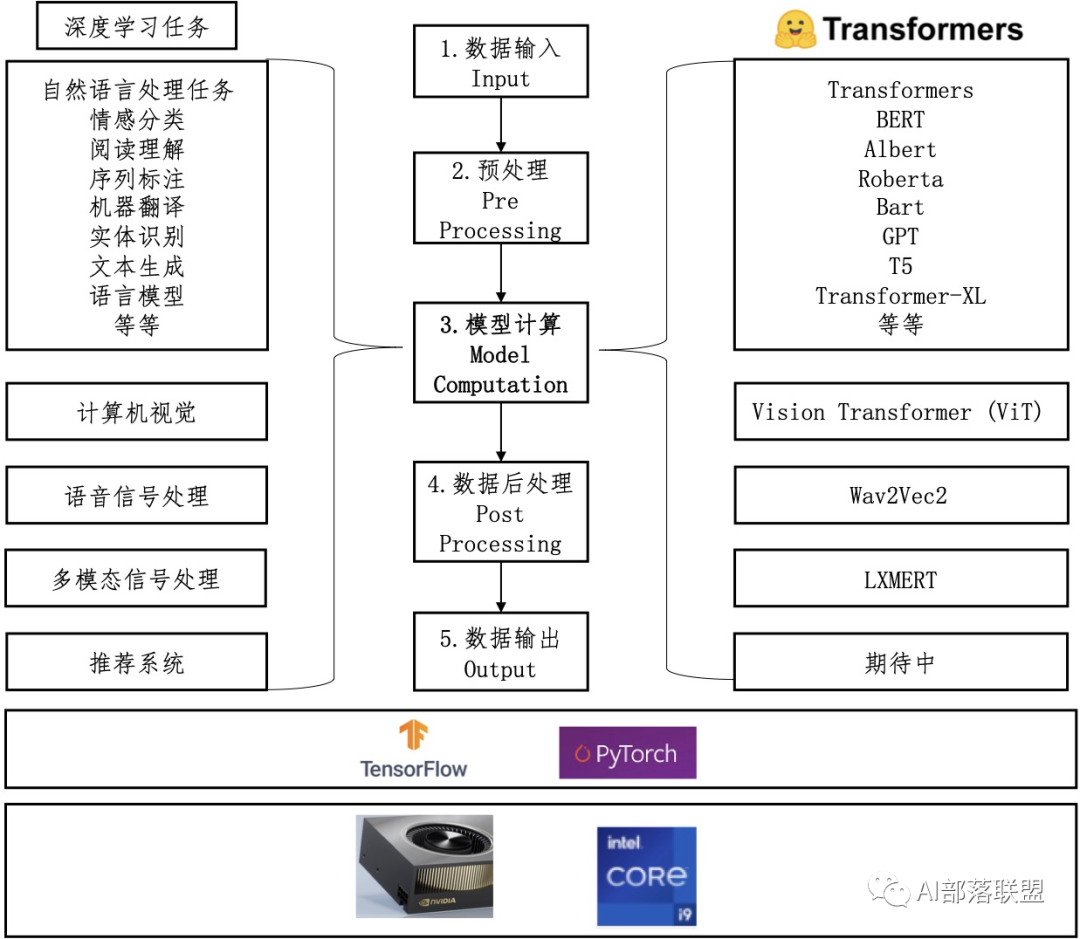
图1 HuggingFace/transformers代码库关系图
如图1所示,左边展示了Huggingface/transformers代码库能处理的各种深度学习任务,中间展示的是处理这些任务的统一流水线(pipeline),右边展示的是与任务对应的transformers模型名称,下方表示用transformers解决这些深度学习任务可以在cpu或者gpu上进行,可以使用tensorflow也可以使用pytorch框架。
那么根据谷歌和github结果基本可以得到这个核心结论啦:transformer能干啥?目前已有的transformer开源代码和模型里自然语言处理任务占大头(几乎覆盖了所有自然语言处理任务),随后是计算机视觉和语音信号处理,最后自然而然进行多模态信号处理啦,推荐系统中的序列建模也逐步开始应用transformer啦。
有一点值得注意:自然语言处理里,所有研究同学的词表库基本统一,所有谷歌/facebook在大规模语料上预训练的transformer模型大家都可以使用。推荐系统不像自然语言处理,各家对user ID,Item ID或者物品类别ID的定义是不一样的,所以各家的pretrain的模型基本也没法分享给其他家使用(哈哈哈商业估计也不让分享),也或许也是为什么transformer的开源推荐系统较少的原因之一吧,但不代表各大厂/研究机构用的少哦。
反问句:用transformer干啥?
为什么非要使用transformer呢?
笔者从一个散修(哈哈修仙界对修炼者的一种称呼)的角度聊一聊自己的看法。
不得不用。
首先谷歌/Facebook一众大厂做出来了基于transformer的BERT/roberta/T5等,刷新了各种任务的SOTA,还开源了模型和代码。
注意各种任务啊,啊这,咱们做论文一般都得在几个数据集上验证自己的方法是否有效,人家都SOTA了,咱得引,得复现呀,再说,站在巨人的肩上创下新SOTA也是香的。
的确好用。
Transformer是基于self-attetion的,self-attention的确有着cnn和lstm都没有的优势:
比如比cnn看得更宽更远,比lstm训练更快。
重复累加多层multi-head self-attetion还在被不短证明着其强大的表达能力!
改了继续用。
如果不说transformer的各种优点,说一个大缺点自然就是:
参数量大、耗时耗机器。
但这些问题又被一众efficient transformers再不断被解决。
比如本来整型数运算的硬件开发板无法使用transformers,随后就有INT-BERT说我们不仅可以用,还能更快更好。
上手就用。
以Huggingface/Transformers为例子,一个代码库包含多种深度学习任务,多个开源的transfromer模型,各种预训练transformer模型,以至于各种深度学习任务上手就来,十分方便。
笔者似乎并没有看到其他模型结构有如此大的应用范围和规模了。
未来还要用。
从上一章节可以看出,transformer这股风已经从自然语言处理领域吹出去了,其他领域的SOTA也在不断被transformer打破,那么以为这,自然语言处理领域的历史逐渐在其他领域复现(当然只是笔者个人观点哈)。
原文标题:我们用transformer干啥?
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
- 相关推荐
- 热点推荐
- Transforme
- 深度学习
-
这些坏的板,能干什么,还可以改造吗?2015-11-19 7495
-
sim808可以干什么2016-07-25 3746
-
LABVIEW里面做吉利时的源表的程序时用node是干什么的?node in和node out是干什么的?2017-12-11 2861
-
覆铜板是干什么的2020-01-07 3223
-
0欧电阻不能阻挡电流的电阻我们要它干什么用?2021-06-18 1581
-
单片机可以干什么?如何学习单片机?2022-02-15 1726
-
USB 3.0是什么?你能用它来干什么?2009-04-19 3490
-
晶圆厂是干什么的2018-03-16 110135
-
汽车示波器能干什么?2019-06-19 10819
-
学完单片机之后,我们可以用它来干什么2021-03-29 4652
-
特殊电阻可以干什么?资料下载2021-03-28 1309
-
转换器是干什么用的2021-10-01 25276
-
什么是阻焊,阻焊的目的是干什么2023-08-28 11303
-
云服务器是干什么的2024-02-18 3164
-
美国云服务器是干什么的2024-02-19 1497
全部0条评论

快来发表一下你的评论吧 !
