

深兰在自然语言处理领域欧洲顶会上取得好成绩
电子说
描述
2021年4月19-23日,EACL2021因疫情影响于线上正式召开,这是计算语言学和自然语言处理领域的重要国际会议,在Google Scholar计算语言学刊物指标中排名第七。深兰科技DeepBlueAI团队参加了Shared Task on Sarcasm and Sentiment Detection in Arabic 比赛,并在其两个子任务讽刺检测和情感识别中,分别获得了第二名和第三名的好成绩,在深兰荣誉榜上再添新篇。
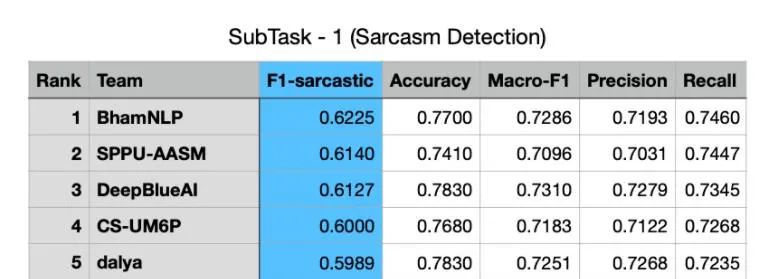
获奖技术方案分享
任务介绍
讽刺检测要求识别一段文字中是否包含讽刺的内容,讽刺是当前情感分析系统的主要挑战之一,因为具有讽刺性的句子通常用积极的表达方式去表示消极的情感。文本所表达的情感以及作者真正想表达的情感之间存在不同,这种情况给情感分析系统带来了巨大的挑战。
讽刺检测、情感识别在其他语言中引起了很大的关注,但是在阿拉伯语上则没有太多进展,该任务则是针对阿拉伯语,针对给定的一个推特文本,判断是积极、消极或者中立情感,以及是否具有讽刺性。
数据分析
任务数据集名字为ArSarcasm-v2[1],数据包含以下几个字段,tweet, sarcasm, sentiment, dialect,tweet代表推特文本,sarcasm为讽刺检测的标签,sentiment为情感分类的标签,dialect表示当前文本确切属于阿拉伯语中的哪个方言。
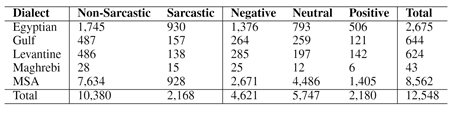
数据集统计如上图所示,Arsarcasm-V2 共有12548条训练文本,其中MSA占比达到了68.2%,Maghrebi占比较少,仅有42条。此外我们还分析了具有讽刺文本中的情感分布情况,占比如下图所示。可以看出讽刺文本中89%具有消极情感,只有3%具有正面情感,可见讽刺一般情况下传递消极的信息。
模型
模型采用当前比较流行的预训练模型,因为语言为阿拉伯语,我们采用了专门针对阿拉伯语的预训练模型bert-large-arabertv02[2],以及多语言预训练模型xlm-roberta-large[3]。其中模型结构如下,选取模型多层[CLS]位置的输出进行加权平均得到[CLS]位置向量,然后经过全连接层,之后经过Multi-sample dropout[4]得到损失。对于讽刺检测为二分类,我们采用Binary Cross Entropy 损失函数,对于情感识别为三分类,我们采用Cross Entropy损失函数。
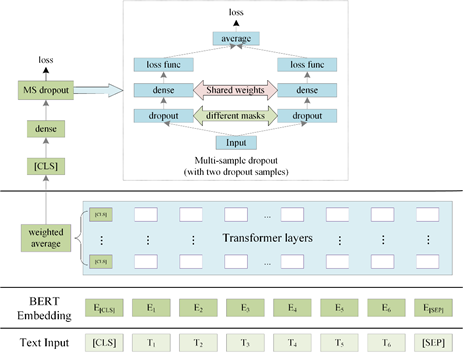
Multi-sample dropout 是dropout的一种变种,传统 dropout 在每轮训练时会从输入中随机选择一组样本(称之为 dropout 样本),而 multi-sample dropout 会创建多个 dropout 样本,然后平均所有样本的损失,从而得到最终的损失,multi-sample dropout 共享中间的全连接层权重。通过综合 M 个 dropout 样本的损失来更新网络参数,使得最终损失比任何一个 dropout 样本的损失都低。这样做的效果类似于对一个 minibatch 中的每个输入重复训练 M 次。因此,它大大减少训练迭代次数,从而大幅加快训练速度。因为大部分运算发生在 dropout 层之前的BERT层中,Multi-sample dropout 并不会重复这些计算,所以对每次迭代的计算成本影响不大。实验表明,multi-sample dropout 还可以降低训练集和验证集的错误率和损失。
训练策略
任务自适应预训练(TAPT)[5],在当前和任务相关的数据集上进行掩码语言模型(MLM)训练,提升预训练模型在当前数据集上的性能。
对抗训练是一种引入噪声的训练方式,可以对参数进行正则化,从而提升模型的鲁棒性和泛化能力。我们采用FGM (Fast Gradient Method)[6],通过在嵌入层加入扰动,从而获得更稳定的单词表示形式和更通用的模型,以此提升模型效果。
知识蒸馏[7]由Hinton在2015年提出,主要应用在模型压缩上,通过知识蒸馏用大模型所学习到的有用信息来训练小模型,在保证性能差不多的情况下进行模型压缩。我们将利用模型压缩的思想,采用模型融合的方案,融合多个不同的模型作为teacher模型,将要训练的作为student模型。
假设:采用arabertv模型,F1得分为70,采用不同参数、不同随机数,训练多个arabertv 模型融合后F1可以达到71;在采用xlm-roberta模型,训练多个模型后与arabertv模型进行融合得到最终的F1为72。基于最后融合的多个模型,采用交叉验证的方式给训练集打上 soft label,此时的soft label已经包含多个模型学到的知识。随后再去训练arabertv模型,模型同时学习soft label以及本来hard label,学习soft label采用MSE损失函数,学习hard label依旧采用交叉熵损失,通过这种方式训练出来的arabertv模型的F1可以达到71点多,最后将蒸馏学出来的模型再与原来的模型融合,得到最后的结果。
模型融合
为了更好地利用数据,我们采用7折交叉验证,针对每一折我们使用了两种预训练模型,又通过改变不同的参数随机数种子以及不同的训练策略训练了多个模型,之后对训练集和测试集进行预测。为了更好地融合模型,我们针对讽刺检测采用了线性回归模型进行融合,针对情感识别模型,采用支持向量机SVM进行融合。
实验结果
评价标准,针对讽刺检测,只评价讽刺类的F1,针对情感分类则对各个类的F1求平均,为了更好地评估模型的好坏,我们采用7折交叉验证的形式,以下结果是交叉验证结果的平均。
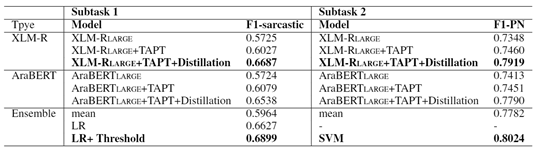
从下表中可以看出,无论是讽刺检测任务还是情感分类任务都是XLM-Roberta 模型相对好一些,经过TAPT和知识蒸馏后效果都有着显著提升。对于讽刺检测因为不同模型之间分数相差比较大,直接求平均效果不行,而采用线性回归后则达到了一个不错的水平,由于讽刺检测类别不平衡,我们将阈值调整为0.41,即大于0.41为1类。同样在情感分类任务中,由于多个模型之间的性能相差较大直接求平均也会造成性能的下降,我们最终采用SVM进行模型融合。
原文标题:赛道 | 深兰载誉自然语言处理领域欧洲顶会EACL2021
文章出处:【微信公众号:DeepBlue深兰科技】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
自然语言处理与机器学习的关系 自然语言处理的基本概念及步骤2024-12-05 2951
-
Transformer架构在自然语言处理中的应用2024-07-09 2592
-
自然语言处理属于人工智能的哪个领域2024-07-03 3866
-
神经网络在自然语言处理中的应用2024-07-01 1590
-
自然语言处理的概念和应用 自然语言处理属于人工智能吗2023-08-23 2825
-
什么是自然语言处理2021-09-08 2752
-
什么是自然语言处理?2021-07-23 2201
-
自然语言处理的语言模型2020-04-16 2789
-
【推荐体验】腾讯云自然语言处理2019-10-09 2923
-
语义理解和研究资源是自然语言处理的两大难题2019-09-19 2580
-
什么是自然语言处理_自然语言处理常用方法举例说明2017-12-28 18772
-
RNN在自然语言处理中的应用2017-11-28 6364
全部0条评论

快来发表一下你的评论吧 !
