

STM32中重要的C语言知识点总结
电子说
描述
说在前面的话一位初学单片机的小伙伴让我推荐C语言书籍,因为C语言基础比较差,想把C语言重新学一遍,再去学单片机,我以前刚学单片机的时候也有这样子的想法。
其实C语言是可以边学单片机边学的,学单片机的一些例程中,遇到不懂的C语言知识,再去查相关的知识点,这样印象才会深刻些。
下面就列出了一些STM32中重要的C语言知识点,初学的小伙伴可以多读几遍,其中大多知识点之前都有写过,这里重新整理一下,更详细地分析解释可以阅读附带的链接。
assert_param断言(assert)就是用于在代码中捕捉这些假设,可以将断言看作是异常处理的一种高级形式。
断言表示为一些布尔表达式,程序员相信在程序中的某个特定点该表达式值为真。
可以在任何时候启用和禁用断言验证,因此可以在测试时启用断言,而在部署时禁用断言。同样,程序投入运行后,最终用户在遇到问题时可以重新启用断言。
注意assert()是一个宏,而不是函数。
在STM32中,常常会看到类似代码:
assert_param(IS_ADC_ALL_INSTANCE(hadc-》Instance));
assert_param(IS_ADC_SINGLE_DIFFERENTIAL(SingleDiff));
这是用来检查函数传入的参数的有效性。STM32中的assert_param默认是不使用的,即:
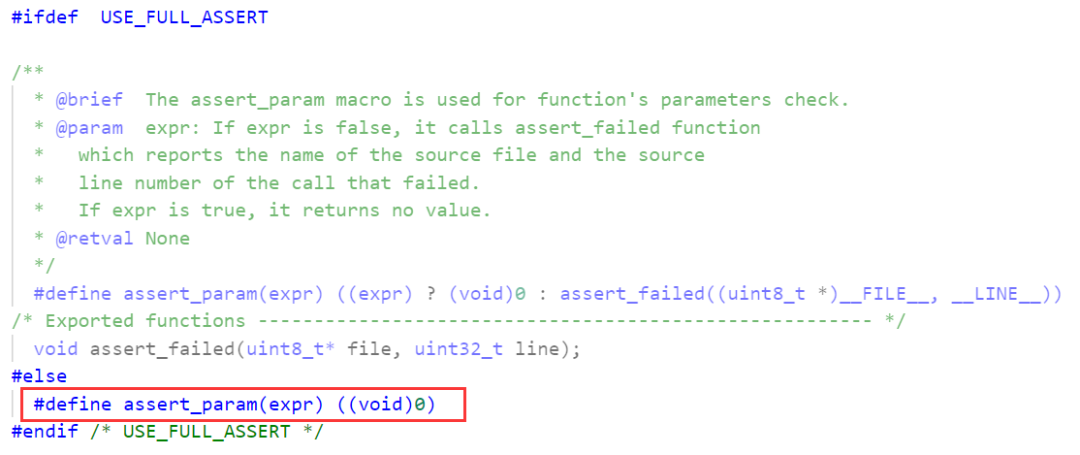
如果要使用,需要定义USE_FULL_ASSERT宏,并且需要自己实现assert_failed函数。特别的,使用STM32CubeMX生成代码的话,会在main.c生成:
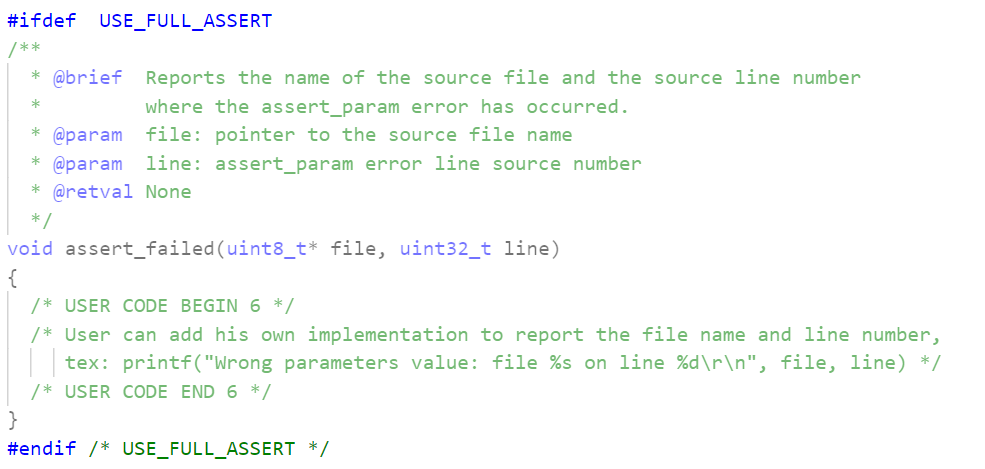
我们在这进行填充就好。
下面分享一下assert的应用例子:
// 公众号:嵌入式大杂烩
#include 《stdio.h》
#include 《assert.h》
int main(void)
{
int a, b, c;
printf(“请输入b, c的值:”);
scanf(“%d %d”, &b, &c);
a = b / c;
printf(“a = %d”, a);
return 0;
}
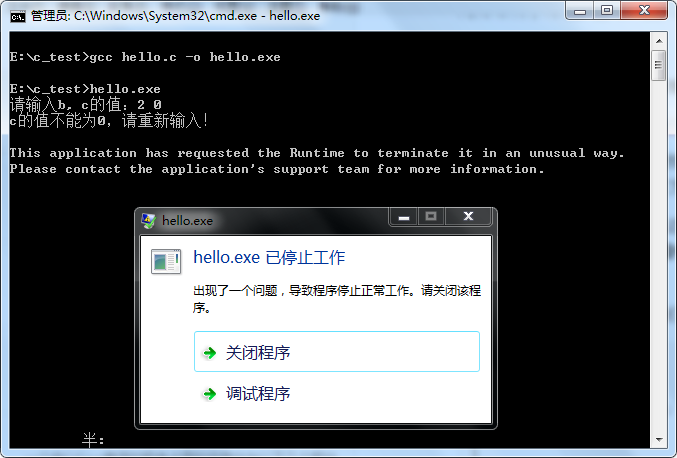
此处,变量c作为分母是不能等于0,如果我们输入2 0,结果是什么呢?结果是程序会蹦:
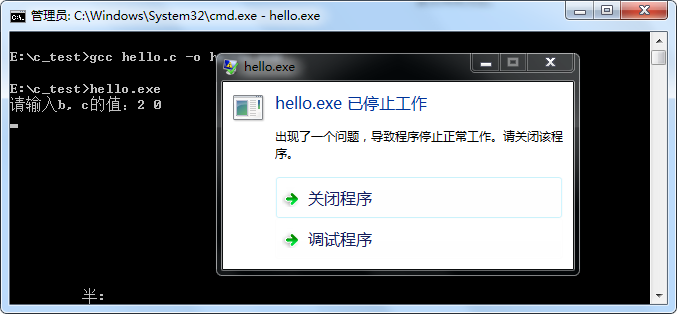
这个例子中只有几行代码,我们很快就可以找到程序蹦的原因就是变量c的值为0。但是,如果代码量很大,我们还能这么快的找到问题点吗?
这时候,assert()就派上用场了,以上代码中,我们可以在a = b / c;这句代码之前加上assert(c);这句代码用来判断变量c的有效性。此时,再编译运行,得到的结果为:
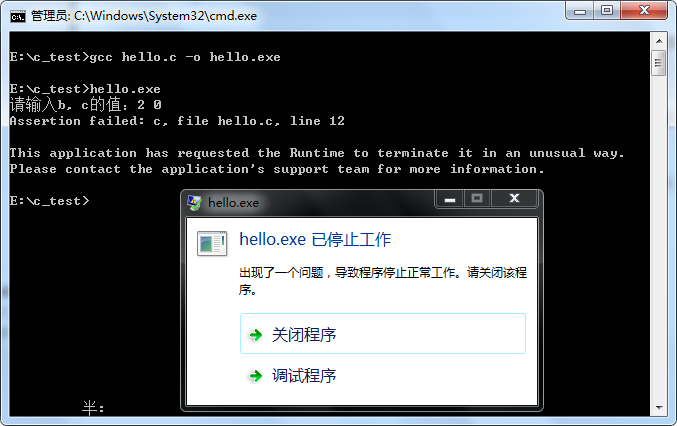
可见,程序蹦的同时还会在标准错误流中打印一条错误信息:
Assertion failed:c, file hello.c, line 12
这条信息包含了一些对我们查找bug很有帮助的信息:问题出在变量c,在hello.c文件的第12行。这么一来,我们就可以迅速的定位到问题点了。
这时候细心的朋友会发现,上边我们对assert()的介绍中,有这么一句说明:
如果表达式的值为假,assert()宏就会调用_assert函数在标准错误流中打印一条错误信息,并调用abort()(abort()函数的原型在stdlib.h头文件中)函数终止程序。
所以,针对我们这个例子,我们的assert()宏我们也可以用以下代码来代替:
if (0 == c)
{
puts(“c的值不能为0,请重新输入!”);
abort();
}
这样,也可以给我们起到提示的作用:
但是,使用assert()至少有几个好处:
1)能自动标识文件和出问题的行号。
2)无需要更改代码就能开启或关闭assert机制(开不开启关系到程序大小的问题)。如果认为已经排除了程序的bug,就可以把下面的宏定义写在包含assert.h的位置的前面:
#define NDEBUG
并重新编译程序,这样编辑器就会禁用工程文件中所有的assert()语句。如果程序又出现问题,可以移除这条#define指令(或把它注释掉),然后重新编译程序,这样就可以重新启用了assert()语句。
相关文章:【C语言笔记】assert()怎么用?
预处理指令1、#error
#error “Please select first the target STM32L4xx device used in your application (in stm32l4xx.h file)”
#error 指令让预处理器发出一条错误信息,并且会中断编译过程。
#error的例子:
// 公众号:嵌入式大杂烩
#include 《stdio.h》
#define RX_BUF_IDX 100
#if RX_BUF_IDX == 0
static const unsigned int rtl8139_rx_config = 0;
#elif RX_BUF_IDX == 1
static const unsigned int rtl8139_rx_config = 1;
#elif RX_BUF_IDX == 2
static const unsigned int rtl8139_rx_config = 2;
#elif RX_BUF_IDX == 3
static const unsigned int rtl8139_rx_config = 3;
#else
#error “Invalid configuration for 8139_RXBUF_IDX”
#endif
int main(void)
{
printf(“hello world
”);
return 0;
}
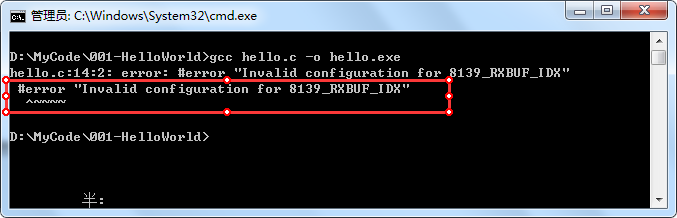
这段示例代码很简单,当RX_BUF_IDX宏的值不为0~3时,在预处理阶段就会通过#error 指令输出一条错误提示信息:
“Invalid configuration for 8139_RXBUF_IDX”
下面编译看一看结果:
2、#if、#elif、#else、#endif、#ifdef、#ifndef
(1)#if
#if (USE_HAL_ADC_REGISTER_CALLBACKS == 1)
void (* ConvCpltCallback)(struct __ADC_HandleTypeDef *hadc);
// 。..。..
#endif /* USE_HAL_ADC_REGISTER_CALLBACKS */
#if的使用一般使用格式如下
#if 整型常量表达式1
程序段1
#elif 整型常量表达式2
程序段2
#else
程序段3
#endif
执行起来就是,如果整形常量表达式为真,则执行程序段1,以此类推,最后#endif是#if的结束标志。
(2)#ifdef、#ifndef
#ifdef HAL_RTC_MODULE_ENABLED
#include “stm32l4xx_hal_rtc.h”
#endif /* HAL_RTC_MODULE_ENABLED */
#ifdef的作用是判断某个宏是否定义,如果该宏已经定义则执行后面的代码,一般使用格式如下:
#ifdef 宏名
程序段1
#else
程序段2
#endif
它的意思是,如果该宏已被定义过,则对程序段1进行编译,否则对程序段2进行编译,通#if一样,#endif也是#ifdef的结束标志。
#ifndef __STM32L4xx_HAL_ADC_EX_H
#define __STM32L4xx_HAL_ADC_EX_H
// 。..。..
#endif
#ifndef的作用与#ifdef的作用相反,用于判断某个宏是否没被定义。
(3)#if defined、#if !defined
defined用于判断某个宏是否被定义, !defined与defined的作用相反。这样一来#if defined可以达到与#ifdef一样的效果。如例子:
#if defined(STM32L412xx)
#include “stm32l412xx.h”
#elif defined(STM32L422xx)
#include “stm32l422xx.h”
//。..。..。.
#elif defined(STM32L4S9xx)
#include “stm32l4s9xx.h”
#else
#error “Please select first the target STM32L4xx device used in your application (in stm32l4xx.h file)”
#endif
如果STM32L412xx宏被定义,则包含头文件stm32l412xx.h,以此类推。
既然已经有#ifdef、#ifndef了,#if defined与#if !defined是否是多余的?
不是的,#ifdef和#ifndef仅能一次判断一个宏名,而defined能做到一次判断多个宏名,例如:
#if defined(STM32L4R5xx) || defined(STM32L4R7xx) || defined(STM32L4R9xx) || defined(STM32L4S5xx) || defined(STM32L4S7xx) || defined(STM32L4S9xx)
// 。..。..
#endif /* STM32L4R5xx || STM32L4R7xx || STM32L4R9xx || STM32L4S5xx || STM32L4S7xx || STM32L4S9xx */
更进一步,可以构建一些更密切地因果处理,如:
#if defined(__ARMCC_VERSION) && (__ARMCC_VERSION 《 400677)
#error “Please use ARM Compiler Toolchain V4.0.677 or later!”
#endif
#define PI (3.14)
#define R (6)
#if defined(PI) && defined(R)
#define AREA (PI*R*R)
#endif
3、#pragma指令
#pragma指令为我们提供了让编译器执行某些特殊操作提供了一种方法。这条指令对非常大的程序或需要使用特定编译器的特殊功能的程序非常有用。
#pragma指令的一般形式为:#pragma para ,其中,para为参数。如
#if defined ( __GNUC__ )
#pragma GCC diagnostic push
#pragma GCC diagnostic ignored “-Wsign-conversion”
#pragma GCC diagnostic ignored “-Wconversion”
#pragma GCC diagnostic ignored “-Wunused-parameter”
#endif
这一段的作用是忽略一些gcc的警告。#pragma命令中出现的命令集在不同的编译器上是不一样的,使用时必须查阅所使用的编译器的文档来了解有哪些命令、以及这些命令的功能。
下面简单看一下#pragma命令的常见用法。
(1)、#pragma pack
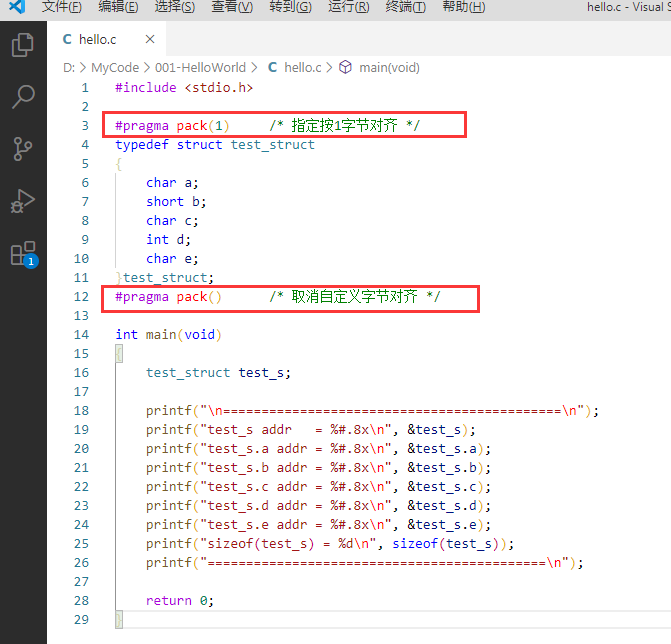
我们可以利用#pragma pack来改变编译器的对齐方式:
#pragma pack(n) /* 指定按n字节对齐 */
#pragma pack() /* 取消自定义字节对齐 */
我们使用#pragma pack指令来指定对齐的字节数。例子:
①指定按1字节对齐
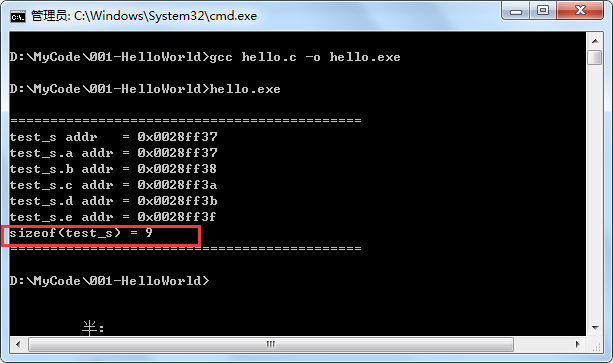
运行结果为:
②指定2字节对齐
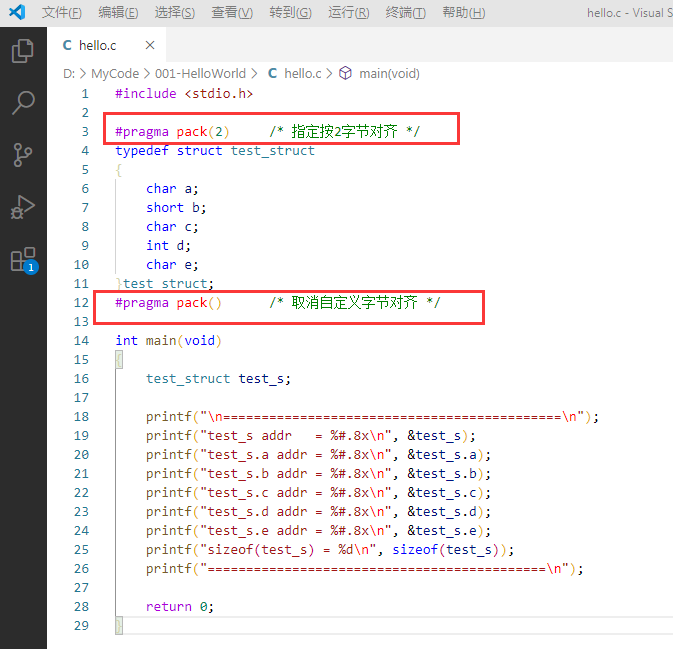
运行结果为:
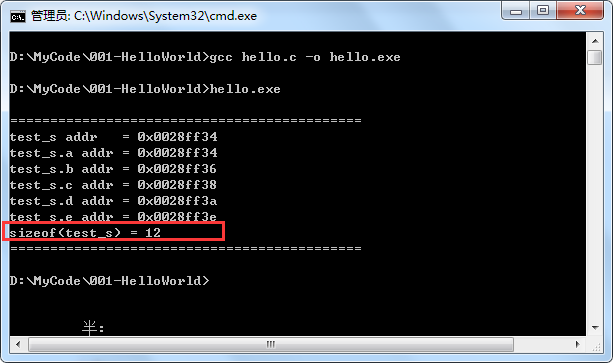
可见,指定的对齐的字节数不一样,得到的结果也不一样。指定对齐有什么用呢,大概就是可以避免了移植过程中编译器的差异带来的代码隐患吧。比如两个编译器的默认对齐方式不一样,那可能会带来一些bug。
(2)#pragma message
该指令用于在预处理过程中输出一些有用的提示信息,如:
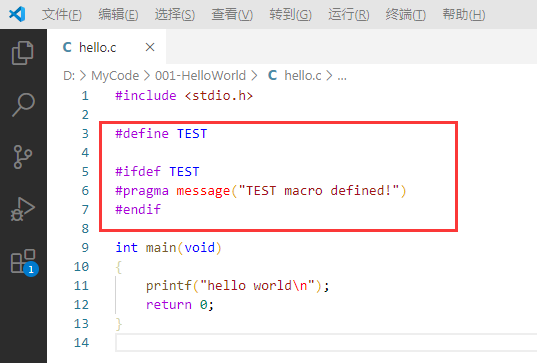
运行结果为:
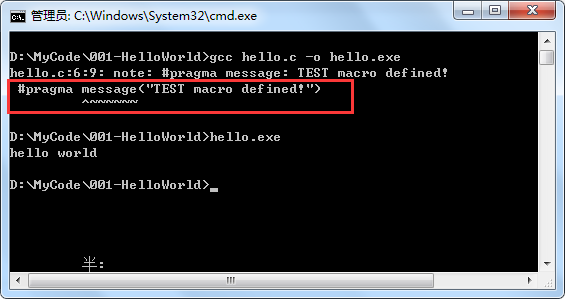
如上,我们平时可以在一些条件编译块中加上类似信息,因为在一些宏选择较多的情况下,可能会导致代码理解起来会混乱。不过现在一些编译器、编辑器都会对这些情况进行一些很明显的区分了,比如哪块代码没有用到,那块代码的背景色就会是灰色的。
(3)#pragma warning
该指令允许选择性地修改编译器警告信息。
例子:
#pragma warning( disable : 4507 34; once : 4385; error : 164 )
等价于:
#pragma warning(disable:4507 34) // 不显示4507和34号警告信息
#pragma warning(once:4385) // 4385号警告信息仅报告一次
#pragma warning(error:164) // 把164号警告信息作为一个错
这个指令暂且了解这么多,知道有这么一回事就可以。
关于#pragma指令还有很多用法,但比较冷门,这里暂且不列举,有兴趣的朋友可以自行学习。
相关文章:认识认识#pragma、#error指令
extern “C”#ifndef __STM32L4S7xx_H
#define __STM32L4S7xx_H
#ifdef __cplusplus
extern “C” {
#endif /* __cplusplus */
#ifdef __cplusplus
}
#endif /* __cplusplus */
#endif /* __STM32L4S7xx_H */
加上extern “C”后,会指示编译器这部分代码按C语言(而不是C++)的方式进行编译。因为C、C++编译器对函数的编译处理是不完全相同的,尤其对于C++来说,支持函数的重载,编译后的函数一般是以函数名和形参类型来命名的。
例如函数void fun(int, int),编译后的可能是_fun_int_int(不同编译器可能不同,但都采用了类似的机制,用函数名和参数类型来命名编译后的函数名);而C语言没有类似的重载机制,一般是利用函数名来指明编译后的函数名的,对应上面的函数可能会是_fun这样的名字。
相关文章:干货 | extern “C”的用法解析
#与##运算符#define __STM32_PIN(index, gpio, gpio_index)
{
index, GPIO##gpio##_CLK_ENABLE, GPIO##gpio, GPIO_PIN_##gpio_index
}
1、#运算符
我们平时使用带参宏时,字符串中的宏参数是没有被替换的。例如:
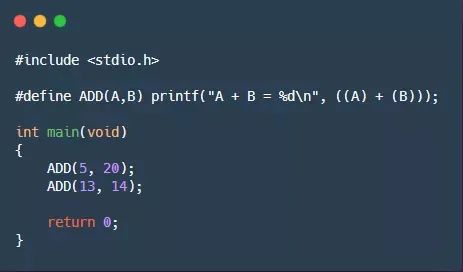
输出结果为:
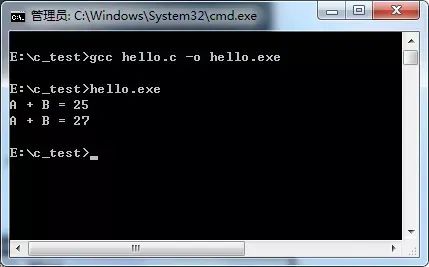
然而,我们期望输出的结果是:
5 + 20 = 25
13 + 14 = 27
这该怎么做呢?其实,C语言允许在字符串中包含宏参数。在类函数宏(带参宏)中,#号作为一个预处理运算符,可以把记号转换成字符串。
例如,如果A是一个宏形参,那么#A就是转换为字符串“A”的形参名。这个过程称为字符串化(stringizing)。以下程序演示这个过程:
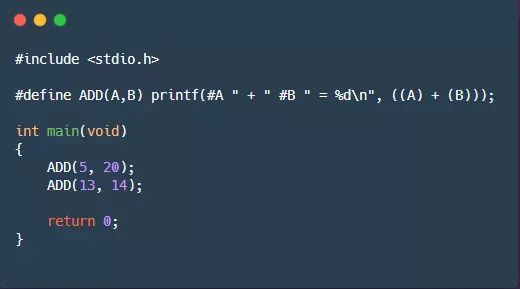
输出结果为:
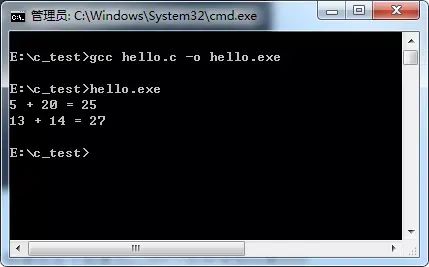
这就达到我们想要的结果了。所以,#运算符可以完成字符串化(stringizing)的过程。
2、##运算符
与#运算符类似,##运算符可用于类函数宏(带参宏)的替换部分。##运算符可以把两个记号组合成一个记号。例如,可以这样做:
#define XNAME(n) x##n
然后,宏XNAME(4)将展开x4。以下程序演示##运算符的用法:
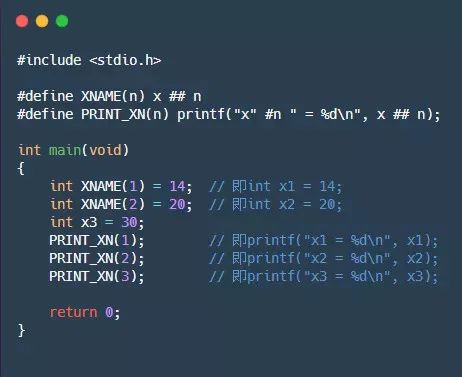
输出结果为:
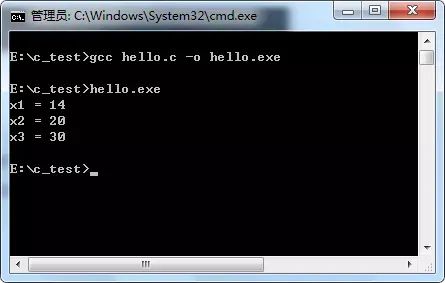
注意:PRINT_XN()宏用#运算符组合字符串,##运算符把记号组合为一个新的标识符。
其实,##运算符在这里看来并没有起到多大的便利,反而会让我们感觉到不习惯。但是,使用##运算符有时候是可以提高封装性及程序的可读性的。
相关文章:这两个C运算符你可能没用过,但却很有用~
_IO、 _I、 _O、volatile一些底层结构体成员中,常常使用_IO、 _O、 _I这三个宏来修饰,如:
typedef struct
{
__IO uint32_t TIR; /*!《 CAN TX mailbox identifier register */
__IO uint32_t TDTR; /*!《 CAN mailbox data length control and time stamp register */
__IO uint32_t TDLR; /*!《 CAN mailbox data low register */
__IO uint32_t TDHR; /*!《 CAN mailbox data high register */
} CAN_TxMailBox_TypeDef;
而这三个宏其实是volatile的替换,即:
#define __I volatile /*!《 Defines ‘read only’ permissions */
#define __O volatile /*!《 Defines ‘write only’ permissions */
#define __IO volatile /*!《 Defines ‘read / write’ permissions */
volatile的作用就是不让编译器进行优化,即每次读取或者修改值的时候,都必须重新从内存或者寄存器中读取或者修改。 在我们嵌入式中, volatile 用在如下的几个地方:
中断服务程序中修改的供其它程序检测的变量需要加 volatile;
多任务环境下各任务间共享的标志应该加 volatile;
存储器映射的硬件寄存器通常也要加 volatile 说明,因为每次对它的读写都可能由不 同意义;
例如:
/* 假设REG为寄存器的地址 */
uint32 *REG;
*REG = 0; /* 点灯 */
*REG = 1; /* 灭灯 */
此时若是REG不加volatile进行修饰,则点灯操作将被优化掉,只执行灭灯操作。
位操作STM32中,使用外设都得先配置其相关寄存器,都是使用一些位操作。比如库函数的内部实现就是一些位操作:
static void TI4_Config(TIM_TypeDef* TIMx, uint16_t TIM_ICPolarity, uint16_t TIM_ICSelection,
uint16_t TIM_ICFilter)
{
uint16_t tmpccmr2 = 0, tmpccer = 0, tmp = 0;
/* Disable the Channel 4: Reset the CC4E Bit */
TIMx-》CCER &= (uint16_t)~TIM_CCER_CC4E;
tmpccmr2 = TIMx-》CCMR2;
tmpccer = TIMx-》CCER;
tmp = (uint16_t)(TIM_ICPolarity 《《 12);
/* Select the Input and set the filter */
tmpccmr2 &= ((uint16_t)~TIM_CCMR1_CC2S) & ((uint16_t)~TIM_CCMR1_IC2F);
tmpccmr2 |= (uint16_t)(TIM_ICSelection 《《 8);
tmpccmr2 |= (uint16_t)(TIM_ICFilter 《《 12);
/* Select the Polarity and set the CC4E Bit */
tmpccer &= (uint16_t)~(TIM_CCER_CC4P | TIM_CCER_CC4NP);
tmpccer |= (uint16_t)(tmp | (uint16_t)TIM_CCER_CC4E);
/* Write to TIMx CCMR2 and CCER registers */
TIMx-》CCMR2 = tmpccmr2;
TIMx-》CCER = tmpccer ;
}
看似很复杂,其实就是按照规格书来配置就可以。虽然实际应用中,很少会采用直接配置寄存器的方法来使用,但是也需要掌握,一些特殊的地方可以直接操控寄存器,比如中断中。
位操作简单例子:
首先,以下是按位运算符:
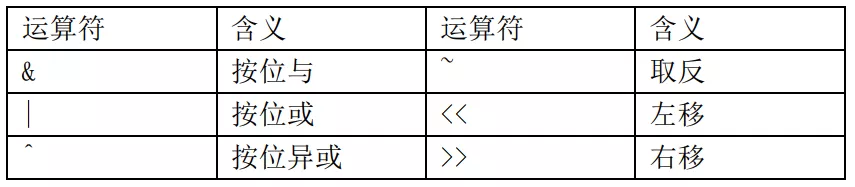
在嵌入式编程中,常常需要对一些寄存器进行配置,有的情况下需要改变一个字节中的某一位或者几位,但是又不想改变其它位原有的值,这时就可以使用按位运算符进行操作。下面进行举例说明,假如有一个8位的TEST寄存器:

当我们要设置第0位bit0的值为1时,可能会这样进行设置:
TEST = 0x01;
但是,这样设置是不够准确的,因为这时候已经同时操作到了高7位:bit1~bit7,如果这高7位没有用到的话,这么设置没有什么影响;但是,如果这7位正在被使用,结果就不是我们想要的了。
在这种情况下,我们就可以借用按位操作运算符进行配置。
对于二进制位操作来说,不管该位原来的值是0还是1,它跟0进行&运算,得到的结果都是0,而跟1进行&运算,将保持原来的值不变;不管该位原来的值是0还是1,它跟1进行|运算,得到的结果都是1,而跟0进行|运算,将保持原来的值不变。
所以,此时可以设置为:
TEST = TEST | 0x01;
其意义为:TEST寄存器的高7位均不变,最低位变成1了。在实际编程中,常改写为:
TEST |= 0x01;
这种写法可以一定程度上简化代码,是 C 语言常用的一种编程风格。设置寄存器的某一位还有另一种操作方法,以上的等价方法如:
TEST |= (0x01 《《 0);
第几位要置1就左移几位。
同样的,要给TEST的低4位清0,高4位保持不变,可以进行如下配置:
TEST &= 0xF0;
do {}while(0)这是在宏定义中用的,STM32的标准库中没有使用这种用法,HAL库中有大量的用法例子,如:
#define __HAL_FLASH_INSTRUCTION_CACHE_RESET() do { SET_BIT(FLASH-》ACR, FLASH_ACR_ICRST);
CLEAR_BIT(FLASH-》ACR, FLASH_ACR_ICRST);
} while (0)
下面以一个例子来分析do {}while(0)的用法:
// 公众号:嵌入式大杂烩
#define DEBUG 1
#if DEBUG
#define DBG_PRINTF(fmt, args.。.)
{
printf(“《《File:%s Line:%d Function:%s》》 ”, __FILE__, __LINE__, __FUNCTION__);
printf(fmt, ##args);
}
#else
#define DBG_PRINTF(fmt, args.。.)
#endif
这个宏打印有什么缺陷?
我们与if、else使用的时候,会有这样的一种使用情况:

此时会报语法错误。为什么呢?
同样的,我们可以先来看一下我们的demo代码预处理过后,相应的宏代码会被转换为什么。如:
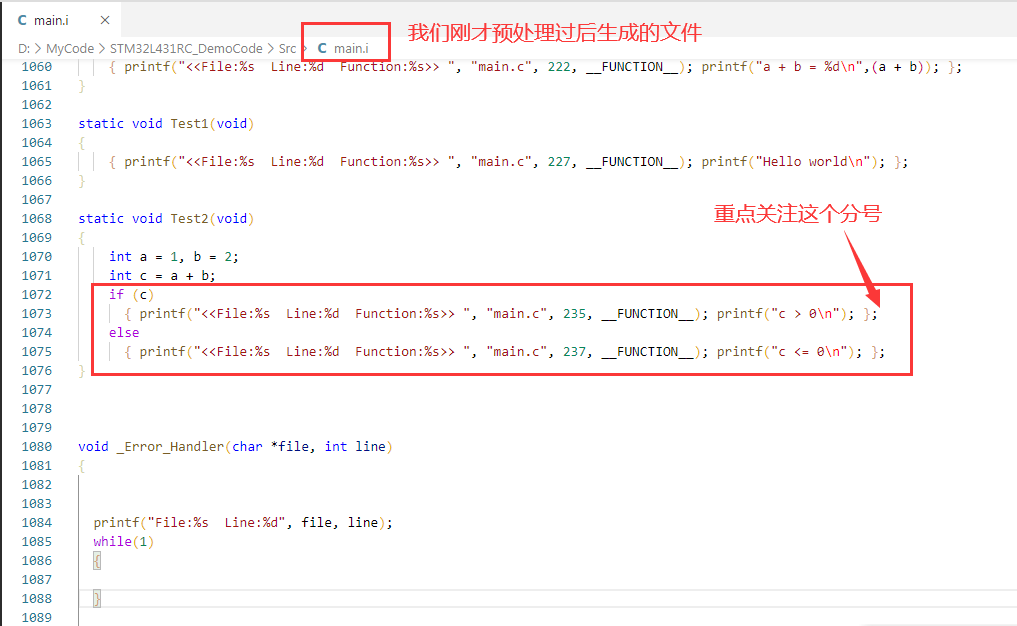
这里我们可以看到,我们的if、else结构代码被替换为如下形式:
if(c)
{ /* 。..。..。 */ };
else
{ /* 。..。..。 */ };
显然,出现了语法错误。if之后的大括号之后不能加分号,这里的分号其实可以看做一条空语句,这个空语句会把if与else给分隔开来,导致else不能正确匹配到if,导致语法错误。
为了解决这个问题,有几种方法。第一种方法是:把分号去掉。代码变成:

第二种方法是:在if之后使用DBG_PRINTF打印调试时总是加{}。代码变成:

以上两种方法都可以正常编译、运行了。
但是,我们C语言中,每条语句往往以分号结尾;并且,总有些人习惯在if判断之后只有一条语句的情况下不加大括号;而且我们创建的DBG_PRINTF宏函数的目的就是为了对标printf函数,printf函数的使用加分号在任何地方的使用都是没有问题的。
基于这几个原因,我们有必要再对我们的DBG_PRINTF宏函数进行一个改造。
下面引入do{}while(0)来对我们的DBG_PRINTF进行一个简单的改造。改造后的DBG_PRINTF宏函数如下:
#define DBG_PRINTF(fmt, args.。.)
do
{
printf(“《《File:%s Line:%d Function:%s》》 ”, __FILE__, __LINE__, __FUNCTION__);
printf(fmt, ##args);
}while(0)
这里的do.。.while循环的循环体只执行一次,与不加循环是效果一样。并且,可以避免了上面的问题。预处理文件:
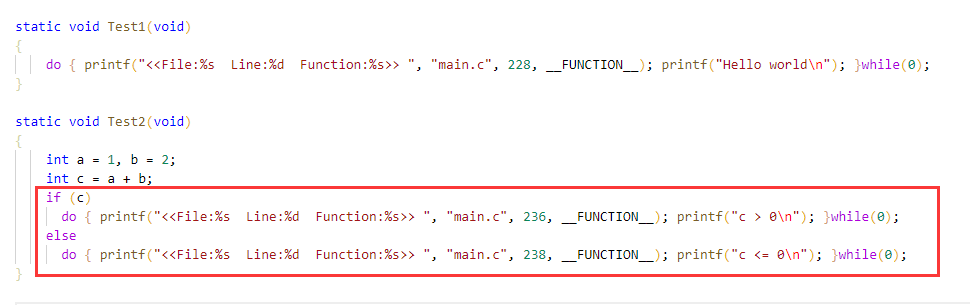
我们的宏函数实体中,while(0)后面不加分号,在实际调用时补上分号,既符合了C语言语句分号结尾的习惯,也符合了do.。.while的语法规则。
使用do{}while(0)来封装宏函数可能会让很多初学者看着不习惯,但必须承认的是,这确确实实是一种很常用的方法。
static与extern1、static

static主要有三种用法:在函数内用于修饰变量、用于修饰函数、用于修饰本.c文件全局变量。后两个容易理解,用于修饰函数与全局变量表明变量与函数在本模块内使用。
下面看看static在函数内用于修饰变量的例子:
// 公众号:嵌入式大杂烩
#include 《stdio.h》
void test(void)
{
int normal_var = 0;
static int static_var = 0;
printf(“normal_var:%d static_var:%d
”, normal_var, static_var);
normal_var++;
static_var++;
}
int main(void)
{
int i;
for ( i = 0; i 《 3; i++)
{
test();
}
return 0;
}
运行结果:

可以看出,函数每次被调用,普通局部变量都是重新分配,而static修饰的变量保持上次调用的值不变,即只被初始化一次。
2、extern
extern的用法简单,用于声明多个模块共享的全局变量、声明外部函数。

原文标题:STM32中C语言知识点:初学者必看,老鸟复习(长文总结)
文章出处:【微信公众号:玩转单片机】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
C语言链表知识点(2)2023-08-22 712
-
C语言最重要的知识点2023-02-16 1074
-
C语言与C++面试知识点总结2022-05-12 2316
-
嵌入式C语言知识点总结2022-04-13 3993
-
嵌入式C语言的知识点汇总,绝对实用2022-02-17 1334
-
STM32中常用的C语言知识点,开始复习!2022-01-13 971
-
[STM32]STM32F407系列教程之三,c语言知识点巩固 指令执行过程2021-11-26 987
-
C语言程序小知识点总结2021-11-05 1342
-
关于STM32中重要的C语言知识点看完你就懂了2021-10-13 1430
-
嵌入式知识点总结2021-07-30 2046
-
STM32中重要的C语言知识点整理2021-02-10 3622
-
C语言学习入门知识点/干货2019-07-18 7109
-
【信盈达】C语言知识点的总结2018-10-08 2612
全部0条评论

快来发表一下你的评论吧 !
