

深度解读对残差网络动机的理解
电子说
1.4w人已加入
描述
神经网络以其强大的非线性表达能力而获得人们的青睐,但是将网络层数加深的过程中却遇到了很多困难,随着批量正则化,ReLU 系列激活函数等手段的引入,在多层反向传播过程中产生的梯度消失和梯度爆炸问题也得到了很大程度的解决。然而即便如此,随着网络层数的增加导致的拟合能力退化现象依然存在,如下图所示
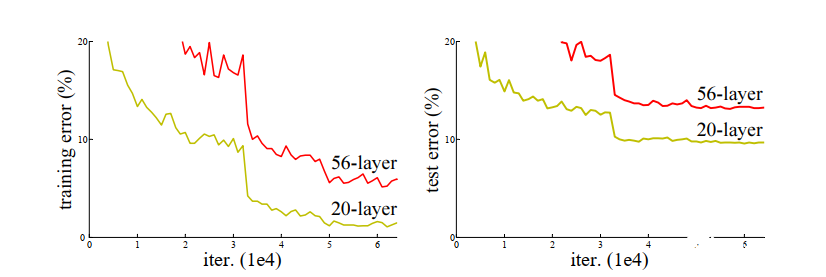
可以看到,训练误差和测试误差都随网络层数的增加而增加,可以排除过拟合造成的预测性能退化。所以这里存在一个逻辑上讲不通的问题,通常来说,我们认为神经网络可以学习出任意形状的函数,具体到这个问题上来,假如浅层网络可以获得一个不错的效果,那么理论上深层网络增加的额外层只需要学会恒等映射,即可获得与浅层网络相同的预测精度
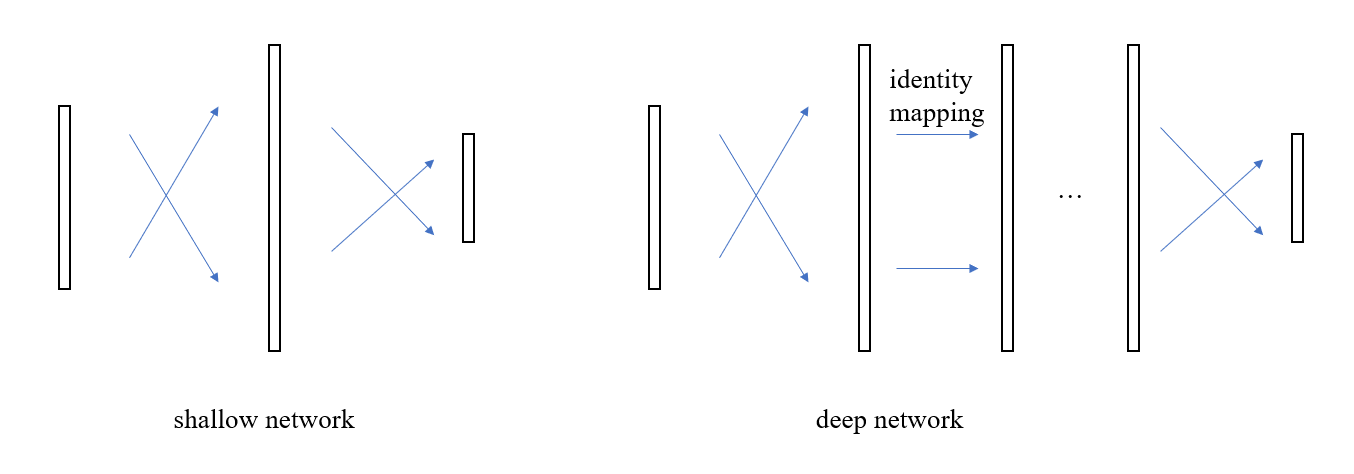
但实际情况根本不是这么回事儿,那么问题出在哪儿了呢?我们一厢情愿的认为中间层能够学会恒等映射,但事与愿违,这一假设不成立,也就是说,具有很强的非线性拟合能力的传统神经元结构却连最简单的恒等映射都模拟不了,抓住这一要点后,新的优化方向便映入眼帘了,既然这种交叉连接的神经元无法实现恒等映射,那么再增加一路恒等映射的连接不就行了
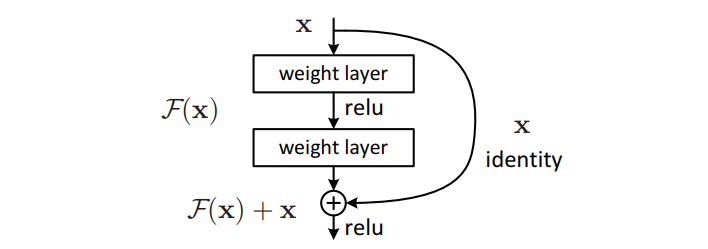
这样一来,假如两层之间的恒等映射是最优解,就像之前提到的那种情况,那么只需要权重层,即图中的 weight layer,学会把所有的权重都设为 0 就行了,而这种学习任务是很简单的。
所以可以总结道,resnet 的提出是因为发现了普通的神经网络连接方式无法实现有效的恒等映射,于是额外增加了一路恒等连接层来辅助学习。体现在最终效果上就是说普通神经网络的连接方式更容易学习到残差,所以这种方式就被称为残差学习。
编辑:jq
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
残差网络是深度神经网络吗2024-07-11 2530
-
一种新的深度注意力算法2023-05-24 544
-
无残差连接或归一化层,也能成功训练深度Transformer2022-12-12 1636
-
深度学习与图神经网络学习分享:CNN经典网络之-ResNet2022-10-12 1994
-
《图学学报》—深度残差网络的无人机多目标识别2021-12-02 2142
-
基于改进残差网络的水下图像重建修复2021-06-17 1128
-
基于多尺度残差网络的边缘检测技术2021-05-29 1111
-
基于深度残差神经网络的远程监督关系抽取模型2021-05-24 1308
-
基于残差连接的改进端到端文本识别网络结构2021-05-17 1047
-
一种改进的残差网络结构以减少卷积层参数2021-03-23 1642
-
一种采用深度残差网络的头部姿态估计方法2021-03-16 1158
-
由多残差模块组成的多窗口残差网络优化模型2021-03-10 1408
-
什么是深度残差收缩网络?2020-11-26 2736
-
如何使用深度残差网络进行无人机航拍图像识别2018-11-16 1800
全部0条评论

快来发表一下你的评论吧 !
