

浅论深层卷积神经网络的剪枝优化
电子说
描述
摘要: 随着近几年来深度学习的兴起,其在目标检测、图像分类、语音识别、自然语言处理等机器学习领域都取得了重大的突破,其中以卷积神经网络在深度学习中的运用较多。自VGGNet出现以来,深度学习逐渐向深层的网络发展,网络越来越深,这不仅增大了对硬件平台存储、运行内存的需求,还大大增加了计算量,对硬件平台资源的要求越来越高。
因此将深度学习应用于嵌入式平台尤为困难。对此,通过对模型进行剪枝的方法将训练好的网络模型压缩处理,在基本保证准确率的情况下去除不重要的参数,缩减模型,减小网络的计算复杂度,将深度学习应用于嵌入式平台。
0 引言
深度学习起源于人工神经网络,后来LECUN Y提出了卷积神经网络LeNet-5[1],用于手写数字识别,并取得了较好的成绩,但当时并没有引起人们足够的注意。随后BP算法被指出梯度消失的问题,当网络反向传播时,误差梯度传递到前面的网络层基本接近于0,导致无法进行有效的学习。
2006年HINTON G E提出多隐层的网络可以通过逐层预训练来克服深层神经网络在训练上的困难[2],随后深度学习迎来了高速发展期。一些新型的网络结构不断被提出(如AlexNet、VGGNet、GoogleNet、ResNet等),网络结构不断被优化,性能不断提升,用于图像识别可以达到很好的效果。然而这些网络大都具有更多的网络层,对计算机处理图像的能力要求很高,需要更多的计算资源,一般使用较好的GPU来提高训练速度,不利于在硬件资源(内存、处理器、存储)较低的设备运行,具有局限性。
深度学习发展到目前阶段,其研究大体可以分为两个方向:(1)设计复杂的网络结构,提高网络的性能;(2)对网络模型进行压缩,减少计算复杂度。在本文将讨论第二种情况,去除模型中冗余的参数,减少计算量,提高程序运行速度。
目前很多网络都具有更复杂的架构设计,这就造成网络模型中存在很多的参数冗余,增加了计算复杂度,造成不必要的计算资源浪费。模型压缩大体有以下几个研究方向:(1)设计更为精细的网络结构,让网络的性能更为简洁高效,如MobileNet网络[3];(2)对模型进行裁剪,越是结构复杂的网络越存在大量参数冗余,因此可以寻找一种有效的评判方法,对训练好的模型进行裁剪;
(3)为了保持数据的精度,一般常见的网络模型的权重,通常将其保存为32 bit长度的浮点类型,这就大大增加了数据的存储和计算复杂度。因此,可以将数据进行量化,或者对数据二值化,通过数据的量化或二值化从而大大降低数据的存储。除此之外,还可以对卷积核进行核的稀疏化,将卷积核的一部分诱导为0,从而减少计算量[4]。
本文着重讨论第二种方法,对模型的剪枝,通过对无用权重参数的裁剪,减少计算量。
1 CNN卷积神经网络
卷积神经网络是一种前馈式网络,网络结构由卷积层、池化层、全连接层组成[5]。卷积层的作用是从输入层提取特征图,给定训练集:

在卷积层后面一般会加一个池化层,池化又称为降采样,池化层可以用来降低输入矩阵的纬度,而保存显著的特征,池化分为最大池化和平均池化,最大池化即给出相邻矩阵区域的最大值。池化层具有减小网络规模和参数冗余的作用。
2 卷积神经网络剪枝

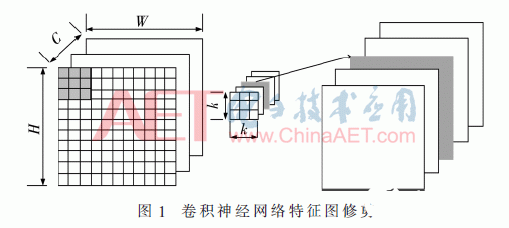
2.1 模型压缩的方法
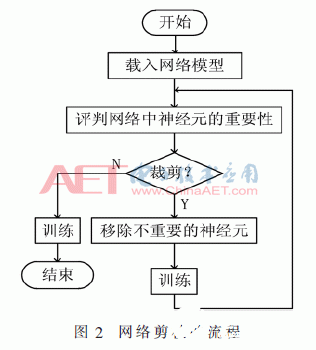
本文用以下方法修剪模型:(1)首先使用迁移学习的方法对网络训练,然后对网络进行微调,使网络收敛并达到最优,保存模型;(2)对保存的模型进行修剪,并再次训练,对修剪后的模型参数通过训练进行微调,如此反复进行,直到检测不到可供裁剪的卷积核;(3)对上一步裁剪后的模型再次训练,直到训练的次数达到设定的标准为止。具体的流程如图2所示。
上述的处理流程比较简单,重点是如何评判网络模型中神经元的重要性。本文用价值函数C(W)作为评判重要性的工具。对于数据集D,经训练后得到网络模型Model,其中的权重参数为:

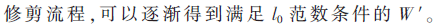
2.2 参数评估
网络参数的评估在模型压缩中有着非常重要的作用。一般采用下面的这种方法,通过比较权重参数的l2范数的大小,删除l2范数较小的卷积核[8]。除此之外,还可以通过激活验证的方法对参数进行评判,将数据集通过网络前向传播,对于某个网络节点,若有大量通过激活函数后的数值为0或者小于一定的阈值,则将其舍去。
2.2.1 最小化l2范数

3 实验结果
3.1 训练和剪枝结果
本设计在Ubuntu16.04系统,搭载1080Ti显卡的高性能服务器上进行实验,使用Pytorch深度学习框架进行训练和测试。本设计使用VGG16网络,对16类常见的路面障碍物图片进行训练,其中数据集中的训练集有24 000张图片,训练集12 000张图片。在VGG16网络中有16个卷积网络层,共4 224个卷积核。采用迁移学习的方法对其进行训练,设置epoch为30,训练的结果如图3所示。
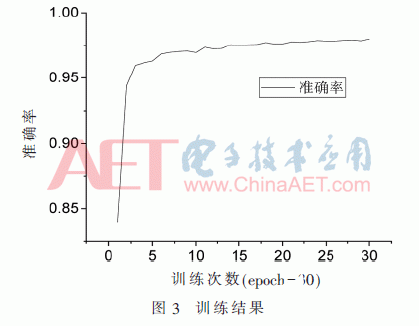
图3纵轴表示训练的准确率,横轴表示迭代次数,最后的训练准确率为97.97%。
将上面的训练参数保存为模型,对其进行剪枝,分5次对其修剪,首先会根据l2范数最小值筛选出要修剪的网络层中的卷积核,每次去除512个卷积核,修剪后模型中剩余的卷积核数量如图4所示。
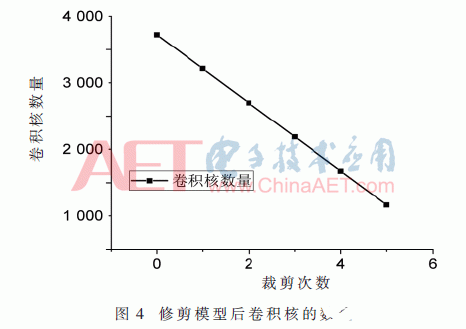
图4中纵轴表示模型中保留的卷积核的数量,从最初的4 224降到1 664,裁剪率达到60.6%。5次迭代修剪后的准确率如图5所示。
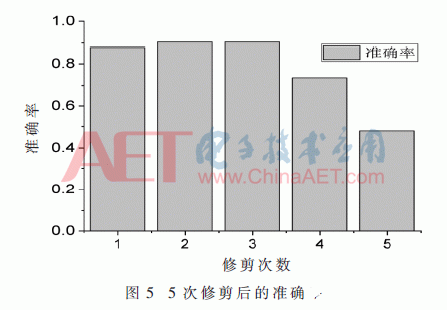
对修剪后的网络重新训练得到最终的修剪模型,训练过程如图6所示。
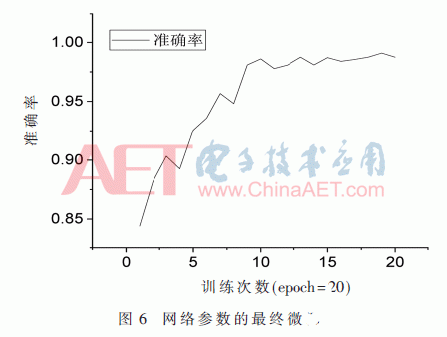
最后达到98.7%的准确率。剪枝前模型大小为512 MB,剪枝后模型可以缩小到162 MB,将模型的内存占用降低了68.35%。
3.2 嵌入式平台下的移植测试
在嵌入式平台树莓派3代B型上移植Pytorch框架,树莓派3b拥有1.2 GHz的四核BCM2837 64位ARM A53处理器,1 GB运行内存,板载BCM43143WiFi。由于树莓派运行内存有限,故增加2 GB的swap虚拟内存,用于编译Pytorch框架源码。将在GPU服务器上训练好的网络模型移植到嵌入式平台,对其进行测试。
对123张测试图片进行检测分类,载入裁剪前的原始模型,用时109.47 s,准确率为95.08%。载入剪枝后的模型,同样对123张图片进行测试,用时41.85 s,准确率达到96.72%。结果如图7所示,可以看到对模型裁剪后时间上减少了61%,速度有了很大提升。

4 结论
目前深度学习是一个热门的研究方向,在图像检测、分类、语音识别等方面取得了前所未有的成功,但这些依赖于高性能高配置的计算机,也出现了各种深度学习框架以及网络模型,但是可以预见深度学习即将迈入一个发展平缓期,如果不能有一个宽阔的应用领域,深度学习的发展将很快被搁浅。诚然,将其应用于嵌入式平台将会是一个非常好的发展方向。相信未来深度学习在嵌入式领域会有一个更大的突破,部署于移动平台将不再是一个难题。
作者:马治楠 韩云杰 彭琳钰 周进凡 林付春 刘宇红
编辑:jq
-
卷积神经网络的应用 卷积神经网络通常用来处理什么2023-08-21 6662
-
卷积神经网络原理:卷积神经网络模型和卷积神经网络算法2023-08-17 2574
-
卷积神经网络模型发展及应用2022-08-02 13370
-
卷积神经网络一维卷积的处理过程2021-12-23 2067
-
基于剪枝与量化的卷积神经网络压缩算法2021-05-17 1265
-
改善深层神经网络--超参数优化、batch正则化和程序框架 学习总结2020-06-16 1594
-
卷积神经网络的优点是什么2020-05-05 3636
-
什么是图卷积神经网络?2019-08-20 2411
-
卷积神经网络如何使用2019-07-17 2876
-
全连接神经网络和卷积神经网络有什么区别2019-06-06 6013
-
【PYNQ-Z2申请】基于PYNQ的卷积神经网络加速2018-12-19 3964
全部0条评论

快来发表一下你的评论吧 !
