

解析Roofline模型实践
描述
在多核异构的时代,软件人员普遍面临的一个困惑是,面对如此复杂的系统,应该如何部署我们的算法,是应该让它运行在CPU,GPU还是甚至类似TPU的专门ASIC上才是最佳方案?另外给定特定的计算平台,我们的算法实现是不是已经榨干硬件平台的最大能力,还有没有进一步改善的空间?这些问题寻寻觅觅答案,真像雾里看花,我们渴望有一双慧眼,帮我们穿透迷津。
在衡量计算效能的正确姿势我们提到了内存带宽(memory bandiwidth)和以FLOPS为代表的算力是可以很好的刻画计算平台的两个指标。同时既然是要衡量算法的性能自然我们也要考虑算法的特性。基于此,论文《Roofline: An Insightful Visual Performance Model for Floating-Point Programs and Multicore Architectures》提出了Roofline模型,试图对硬件和软件通盘考虑,从而提出改善性能的洞见。
这里我们试着解释如下,首先我们要介绍运算强度(arithmetic intensity,简写成AI)的概念,指的是针对单位内存读写数据进行的运算次数,以FLOP/Byte为单位。比如衡量计算效能的正确姿势(2)介绍过的SAXPY,每次迭代,有三次内存访问(x读一次,y读写各一次),而有两次浮点运算(乘加各一次),所以其AI为(2 * N) / (3 * N * 4) = 1/6。
int N = 1 《《 22;
void saxpy(float a, float *x, float *y){
for (int i = 0; i 《 N; ++i)
y[i] = a*x[i] + y[i];
}
引进AI后,算力FLOPS就可以用以下公式来计算。
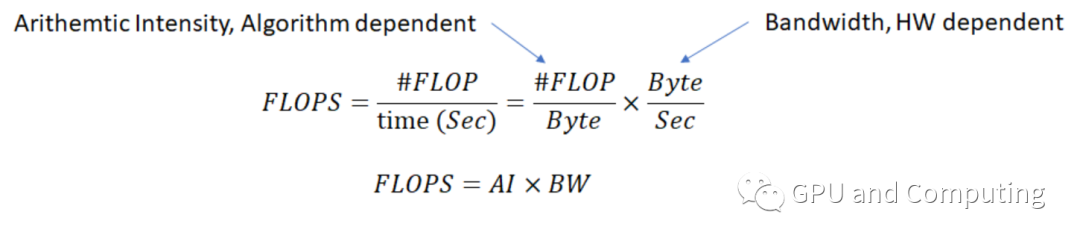
两边取对数,
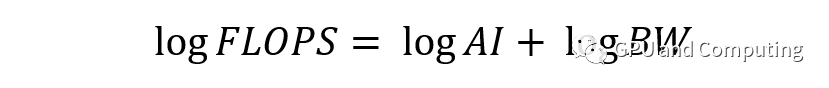
以logFLOPS为Y,logAI为X,我们可以得到斜截式 Y = X + logBW,另对特定平台,算力FLOPS存在极限值,据此我们可以作如下图。
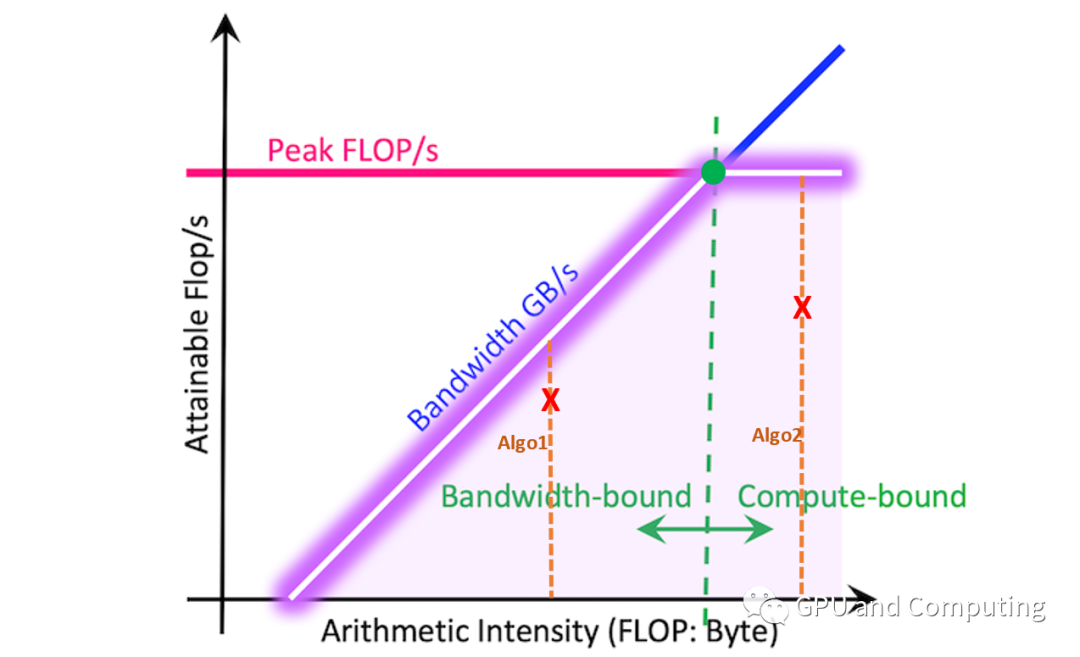
图中紫色的线条是不是很类似屋脊线,这正是该模型命名的由来。以脊点为界,左边区域构成内存带宽瓶颈区域,右边区域对应算力瓶颈区域。已知某算法的AI,其最大可获取FLOPS很容易计算得到,见如下公式,为AI所在竖直线与Roofline的交点。如算法Algo1的AI处于内存带宽受限区域,而算法Algo2的AI则位于算力受限区域,如果Algo1和Algo2为同一问题两种算法方案,显然Alg2更有机会获取满意的FLOPS。
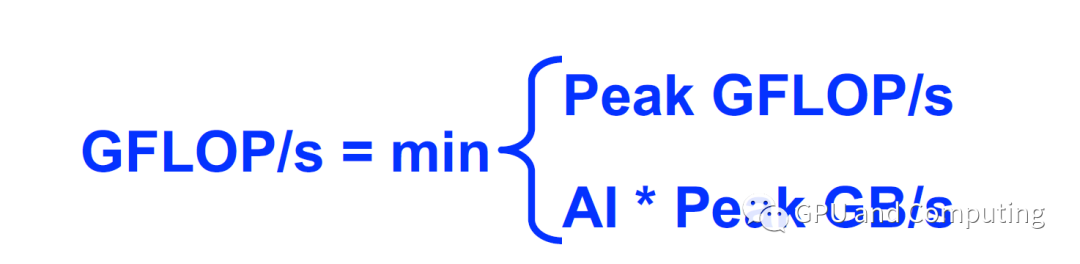
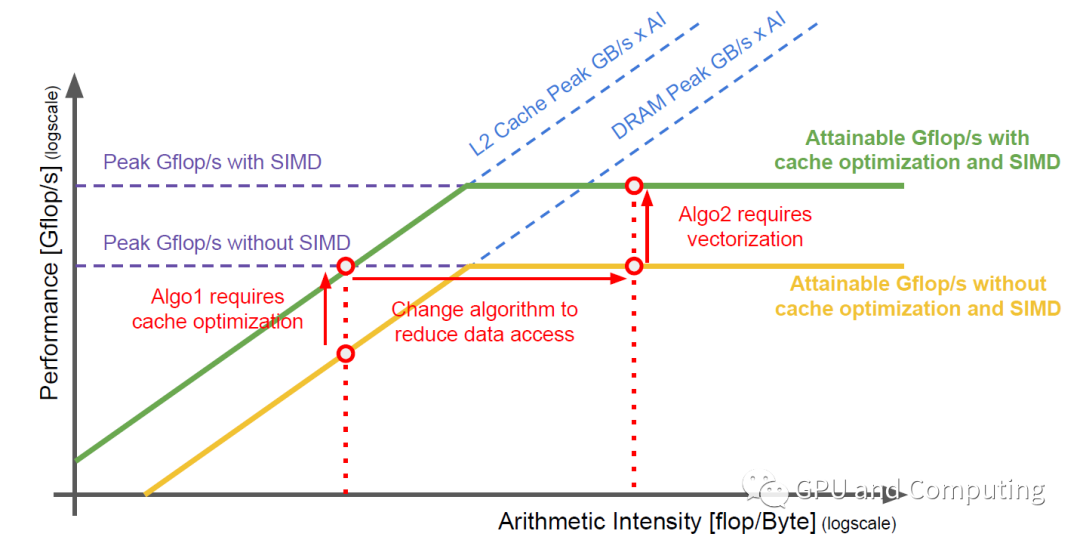
上面公式代表了理想化的情形,实际操作中,存在各种各样的天花板(Ceiling)障碍,算法优化的过程就是反复突破这些障碍而尽量接近roofline,最后得到理想的性能。如下图过程展示,介绍如何通过改善算法的数据局部性以充分利用Cache,并通过向量化而调用SIMD硬件资源来达到这一目的。
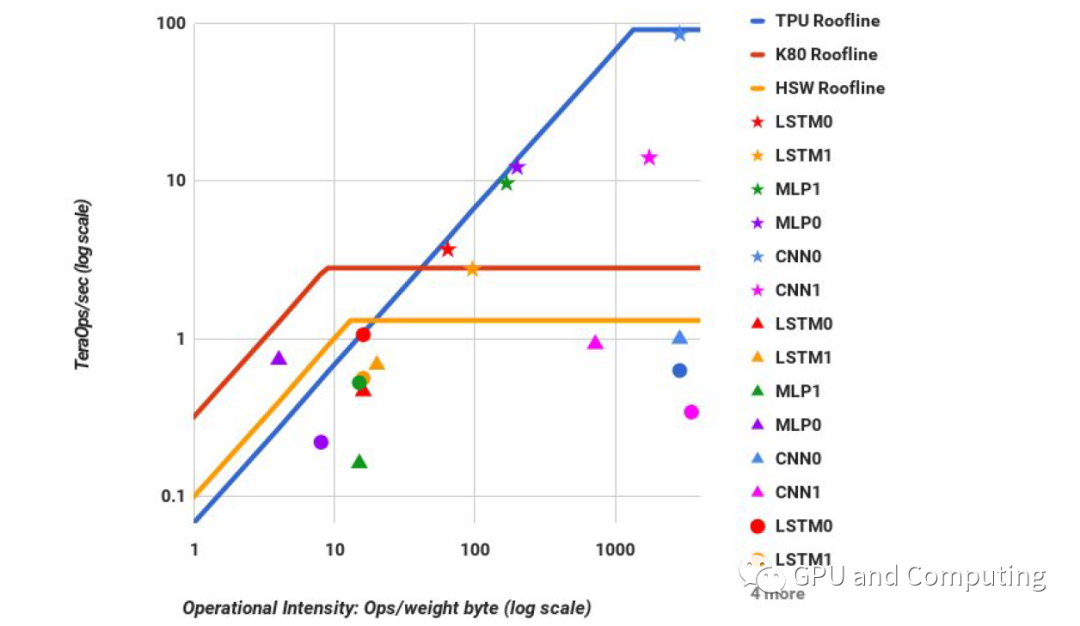
除了上面介绍的Roofline模型能够让我们在特定平台“纸上谈兵”改善算法性能,Roofline也可以可视化同一算法部署在不同平台时候性能的比较,结果让人一目了然。在Google的有关TPU(TPU是Google开发的专门用于神经网络算法加速的芯片)的论文《In-Datacenter Performance Analysis of a Tensor Processing Unit》里,作者利用Roofline图表来比较各种神经网络算法分别部署在同时代CPU、GPU和TPU的性能差异,令人印象深刻。五角星、三角形、圆形分别代表对应算法在TPU、GPU和CPU上运行状况。
需要指出的是,Roofline模型在实践中并不像想象般容易,运用的时候有很多细微的地方需要仔细推敲。但它仍不失为非常insightful的寻宝图,如果你能学会正确解读,它完全有机会帮我们找到算法性能优化的巨大宝藏。以后我们会有很多场合涉及它的理念和具体用法,敬请期待。
编辑:lyn
-
大语言模型:原理与工程实践+初识22024-05-13 1699
-
【大语言模型:原理与工程实践】探索《大语言模型原理与工程实践》2.02024-05-07 1503
-
【大语言模型:原理与工程实践】大语言模型的基础技术2024-05-05 1371
-
【大语言模型:原理与工程实践】揭开大语言模型的面纱2024-05-04 880
-
【大语言模型:原理与工程实践】探索《大语言模型原理与工程实践》2024-04-30 1325
-
名单公布!【书籍评测活动NO.31】大语言模型:原理与工程实践2024-03-18 7926
-
名单公布!【书籍评测活动NO.30】大规模语言模型:从理论到实践2024-03-11 16109
-
解析EMC滤波器:关键作用与应用实践?2024-02-21 1548
-
MCU人脸识别模型的设计注意事项和最佳实践2023-08-02 682
-
机器学习构建ML模型实践2023-07-05 1521
-
HDF Camera 驱动模型解析2021-11-15 2710
-
解析深度学习:卷积神经网络原理与视觉实践2020-06-14 3538
-
机器学习实践指南——案例应用解析2018-04-13 2315
全部0条评论

快来发表一下你的评论吧 !
