

基于深度学习的目标检测算法
描述
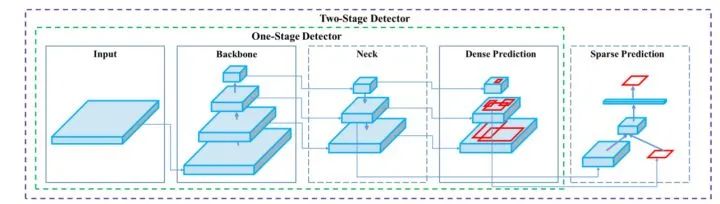
整体框架
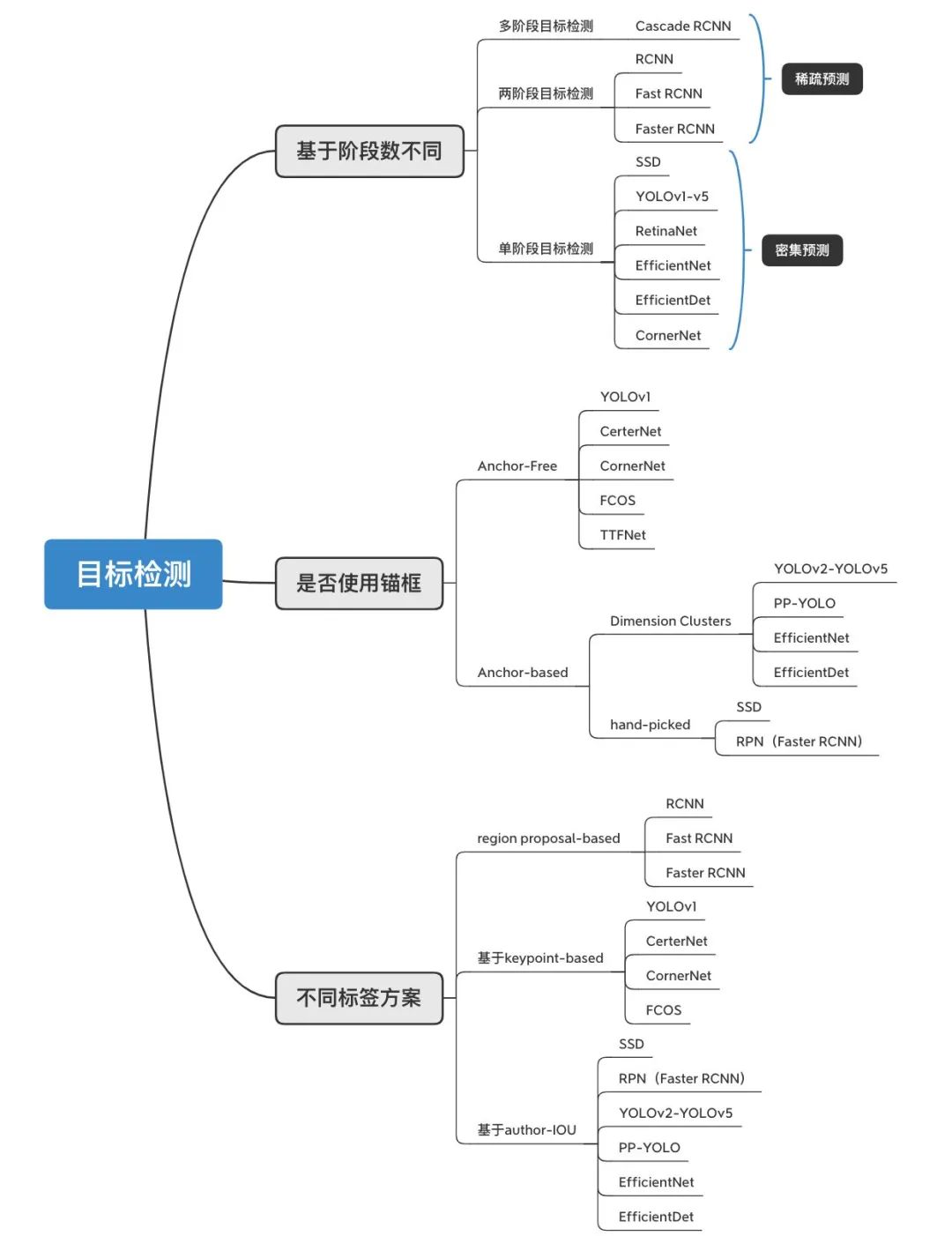
目标检测算法主要包括:【两阶段】目标检测算法、【多阶段】目标检测算法、【单阶段】目标检测算法
什么是两阶段目标检测算法,与单阶段目标检测有什么区别?
两阶段目标检测算法因需要进行两阶段的处理:1)候选区域的获取,2)候选区域分类和回归,也称为基于区域(Region-based)的方。与单阶段目标检测算法的区别:通过联合解码同时获取候选区域、类别
什么是多阶段目标检测算法?
【两阶段】和【多阶段】目标检测算法统称级联目标检测算法,【多阶段】目标检测算法通过多次重复进行步骤:1)候选区域的获取,2)候选区域分类和回归,反复修正候选区域
根据是否属于锚框分为:
1、Anchor-Free:
CornerNet
FCOS
TTFNet
YOLOv1(注意)
2、Anchor-based:
RetinaNet
YOLOv2-v5
PP-YOLO
SSD
主要考虑问题
1、准确性 2、实时性 3、多尺度 4、标签方案 5、目标重叠 6、模型训练 7、重复编码 8、数据增强 9、样本不平衡
两阶段目标检测算法
RCNN
1、模型通过【选择性搜索算法】获取潜在的候选区域 2、截取原图每个候选区域并resize输入到模型中进行特征抽取 3、使用SVM进行分类,以及进行bounding box 回归
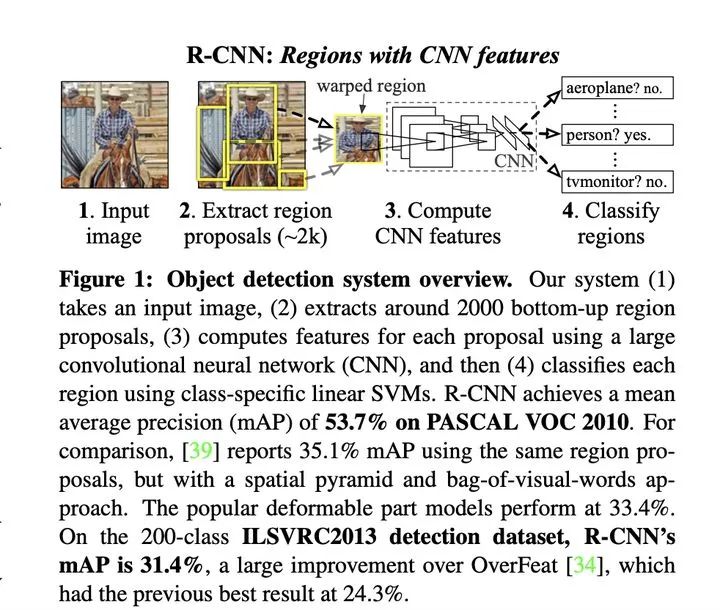
存在问题:
重复编码:由于候选区域存在重叠,模型需要重复进行重叠区域的特征图提取,计算冗余
模型训练:由于特征抽取模型和区域的分类回归模型分开训练,无法进行端到端的模型训练,训练过程需要提取每个包含重叠区域的候选区域特征并保存用于分类和回归训练
实时性差:重复编码导致实时性不佳,【选择性搜索算法】耗时严重
Fast-RCNN
考虑到RCNN的缺点,Fast-RCNN来了! 1、模型依旧通过【选择性搜索算法】获取潜在的候选区域
2、将原图通过特征抽取模型进行一次的共享特征图提取,避免了重复编码
3、在特征图中找到每一个候选区域对应的区域并截取【区域特征图】,ROI pooling层中将每个【区域特征图】池化到统一大小
4、分别进行softmax分类(使用softmax代替了RCNN里面的多个SVM分类器)和bbox回归
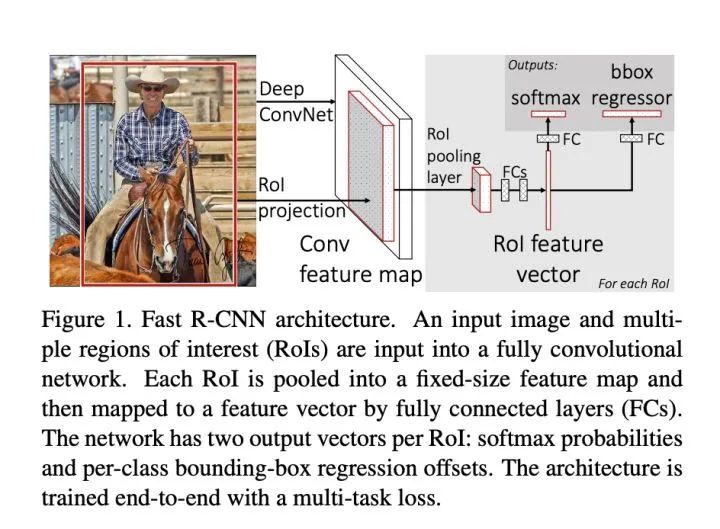
主要优点:
1、可以进行端到端模型训练 2、不需要存储中间特征向量用于SVM分类和回归模型训练 3、使用更高效的SPPnet特征提取网络
存在问题:
实时性差:选择性搜索获取候选区域耗时,主要通过贪婪算法合并低级特征超像素,单张图片耗时接近2s,且无法使用GPU加速
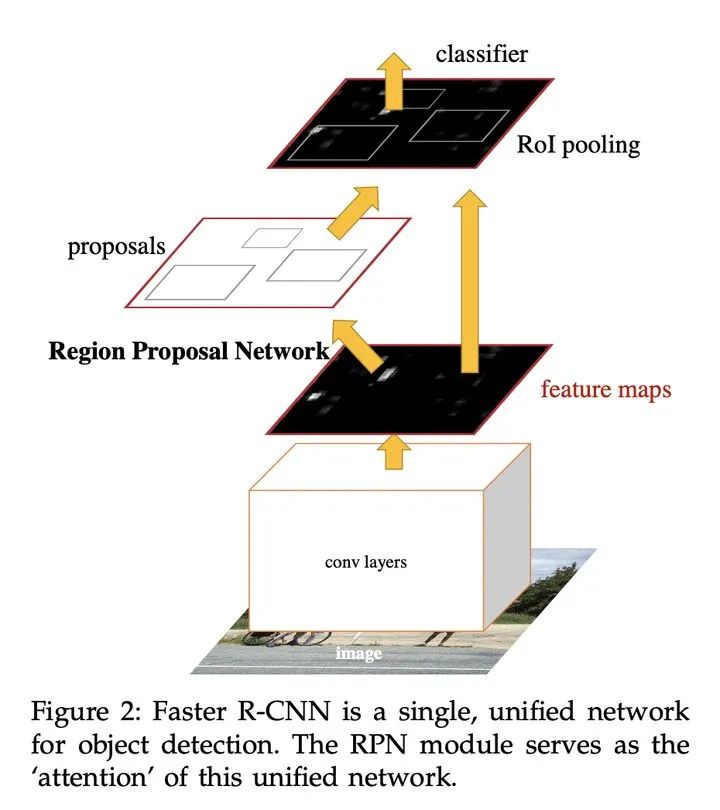
Faster R-CNN
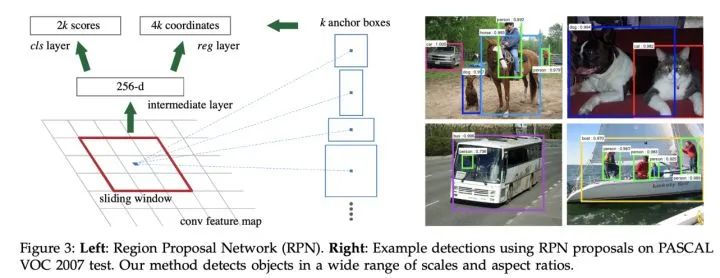
使用RPN网络代替Fast RCNN使用的选择性搜索进行候选区域的提取,相当于Faster R-CNN=RPN+Fast RCNN,且RPN和Fast RCNN共享卷积层。
1、多尺度目标:通过RPN网络候选区域,并使用不同大小和长宽比的anchors来解决多尺度问题
2、通过计算anchors与真实框的交并比IOU,并通过阈值建立正负样本
3、样本不平衡:每批次随机采样256个anchors进行边框回归训练,并尽可能保证正负样本数相同,避免负样本过多导致的梯度统治问题
论文:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
多阶段目标检测算法
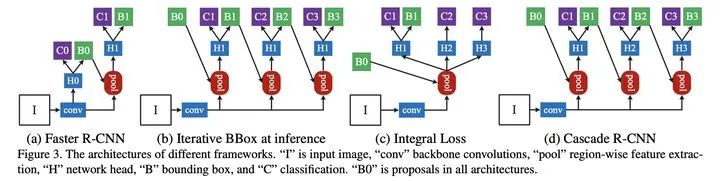
Cascade R-CNN
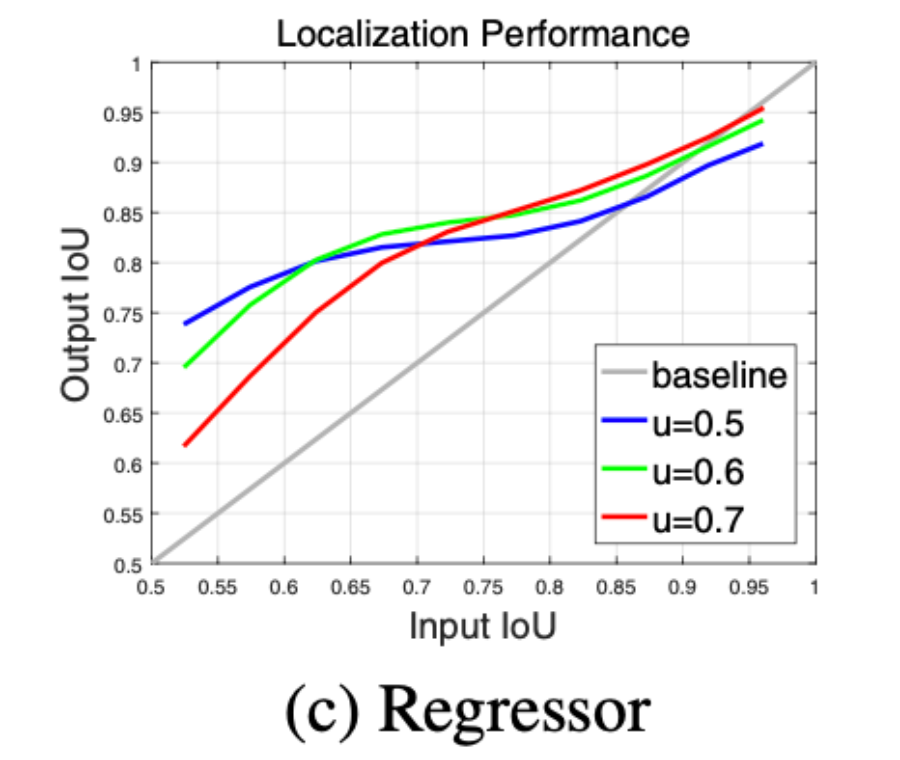
通过分析Faster RCNN在目标候选区域的位置修正能力, 如下图基于单个检测器的可优化性但优化的程度有限,通过多次将预测区域作为候选区域进行修正,使得输出的预测区域与真实标签区域的IOU逐级递增
主要优点:
1、准确性:碾压各种单双阶段目标检测算法,采用RoIAlign取代RoIPooling 2、多尺度:通过FPN网络集成多尺度特征图,利用归一化尺度偏差方法缓解不同尺度对Loss的影响程度 3、实时性:去除了Fater RCNN的全连接层,取而代之采用FCN网络,相比Fater RCNN,具有更少的模型参数和计算时间
主要不足:
单阶段目标检测算法
编码方式
1、基于中心坐标
方案1
通过计算IOU或者长宽比阈值筛选每个anchor位置对应的target,可能过滤比较极端的target,但缓解目标重叠情况下的编码重叠问题 通过对应anchor找到中心坐标位置(x,y)
方案2
通过iou最大值计算每个target对应的anchor位置,保证每个target至少对应一个,目标少的情况下但容易造成目标稀疏编码, 通过对应target找到中心坐标位置(x,y),YOLOv5中通过中心坐标结合四舍五入进行多中心坐标映射缓解目标稀疏问题 方案3 同时利用方案1和方案2,保证每个target至少对应一个anchor区域
YOLOv1
虽然是单阶段目标检测开山之作,但真正的鼻祖应该是Faster RCNN的RPN
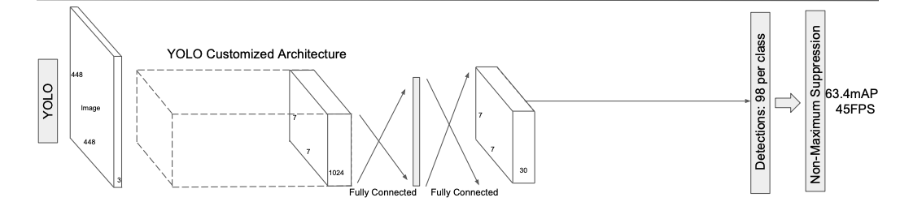
主要优点:
1、快 2、采用全局特征进行推理,由于利用全局上下文信息,相比于滑动窗口和建议框方法,对背景的判断更准确 3、泛化性,训练好的模型在新的领域或者不期望的输入情况下依然具有较好的效果
主要不足:
1、准确性:与Faster RCNN相比,correcct反映了YOLOv1准确率较低,background反映了召回率较高,但总体性能F1较低,虽然loss采用长宽平方根进行回归,试图降低大目标对loss的主导地位,但小目标的微小偏差对IOU的影响更严重,导致小目标定位不准
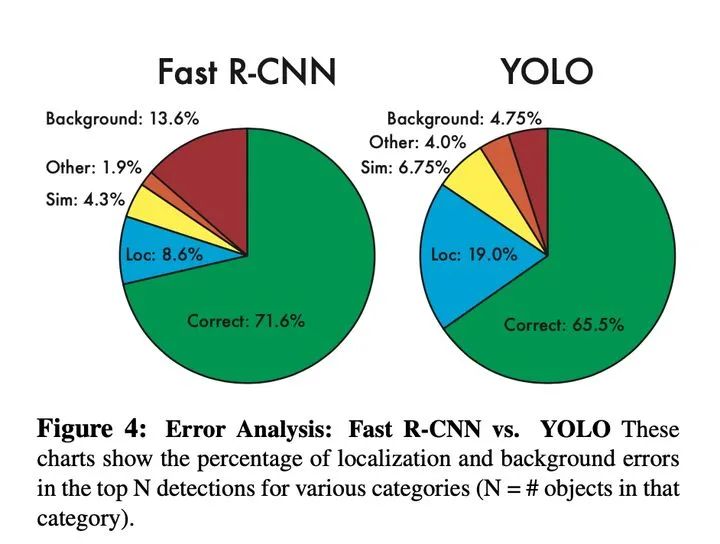
2、目标重叠:虽然通过每个S*S的网格点设置了2个预测框用于回归训练,但是每个网格点设置了一种类别,无法解决不同类别目标重叠率较大,导致映射到相同网格点上的问题
3、多尺度:由于模型只是简单使用下采样获得的粗糙特征,很难将其推广到具有新的或不同寻常的宽高比或配置的对象
4、实时性:虽然与Faster RCNN相比,速度很快,但还可以更快,主要是由于v1中使用了全连接网络,不是全卷积网络
全连接层参数=7x7x1024x4096+4096X7x7x30=2x10^8

SSD
通过使用FCN全卷积神经网络,并利用不同尺度的特征图进行目标检测,在速度和精度都得到了极大提升
主要优点
1、实时性:相比YOlOv1更快,因为去除了全连接层
2、标签方案:通过预测类别置信度和相对固定尺度集合的先验框的偏差,能够有效均衡不同尺度对loss的影响程度
3、多尺度:通过使用多个特征图和对应不同尺度的锚框进行多尺度目标预测
4、数据增强:通过随机裁剪的方式进行数据增强提高模型的鲁棒性
5、样本不平衡:通过困难样本挖掘,采用负样本中置信度最高的先验框进行训练,并设置正负样本比例为1:3,使得模型训练收敛更快
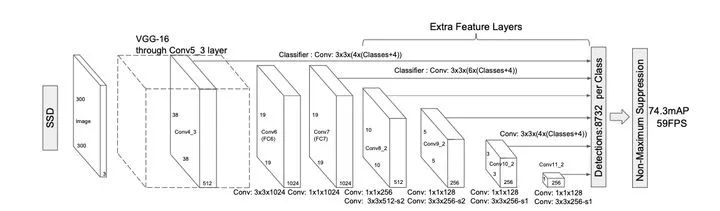
主要不足
1、通过人工先验设置的不同尺度的锚框无法适应真实的目标框的尺度分布 2、使用的多个特征图由于高分辨率的特征图不能有效地结合高层特征
YOLOv2
针对YOLOv1在解决多尺度和实时性方面的不足,提出了YOLOv2

主要优点:
1、更好 1)Batch Normalization:使得性能极大提升;
2)Higher Resolution Classifier:使预训练分类任务分辨率与目标检测的分辨率一致;
3)Convolutional With Anchor Boxes:使用全卷积神经网络预测偏差,而非具体的坐标,模型更容易收敛;
4)Dimension Clusters:通过聚类算法设置锚框的尺度,获得更好的先验框,缓解了不同尺度对loss的影响变化;
5)Fine-Grained Features:通过简单相加融合了低层的图像特征;
6)Multi-Scale Training:通过使用全卷积网络使得模型支持多种尺度图像的输入并轮流进行训练
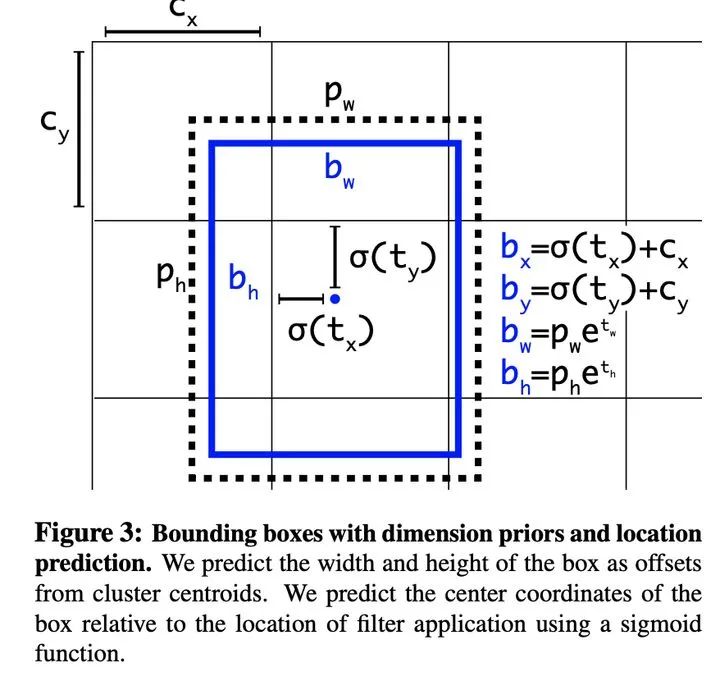
2、更快,构建Darknet-19代替VGG-16作为backbone具有更好的性能
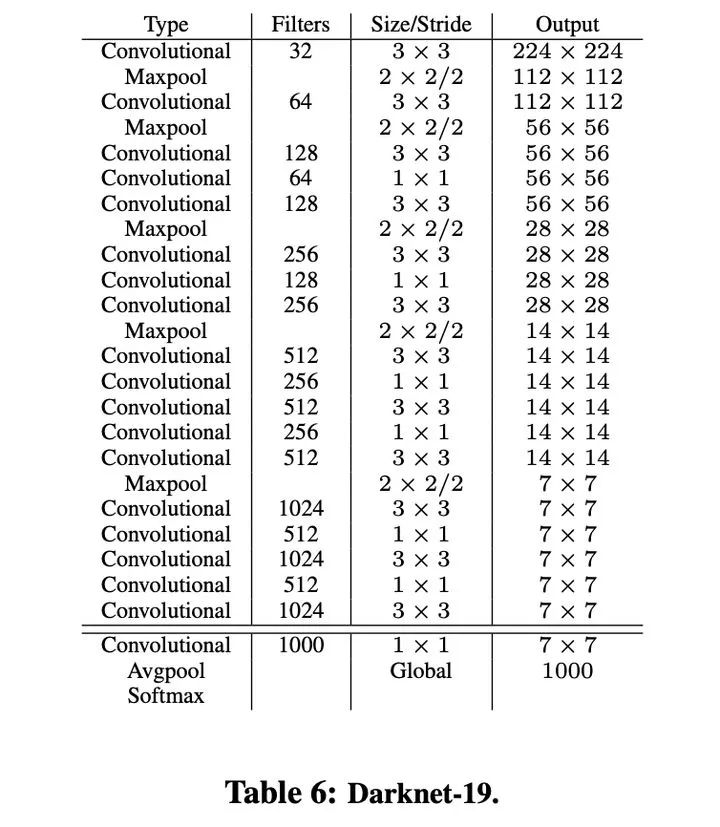
主要不足
1、多尺度:在模型维度只是简单融合底层特征,在输入维度进行多尺度图像分辨率的输入训练,不能克服模型本身感受野导致的多尺度误差
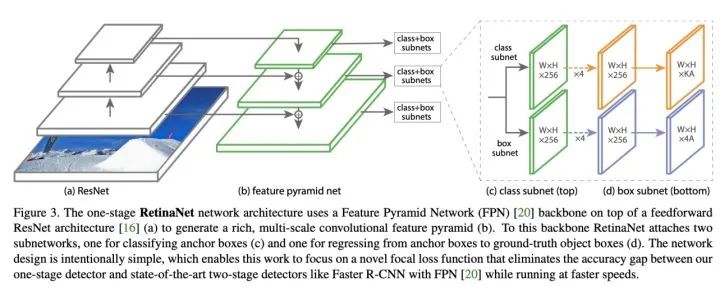
RetinaNet
论文:Focal Loss for Dense Object Detection
主要优点
1、多尺度:借鉴FPN网络通过自下而上、自上而下的特征提取网络,并通过无代价的横向连接构建增强特征提取网络,利用不同尺度的特征图检测不同大小的目标,利用了底层高分率的特征图有效的提高了模型对小尺度目标的检测精度 2、样本不平衡:引入Focal Loss用于候选框的【类别预测】,克服正负样本不平衡的影响及加大困难样本的权重
主要不足
1、实时性:网络使用ResNet-101作为主干特征提取网络,检测效率略微不足
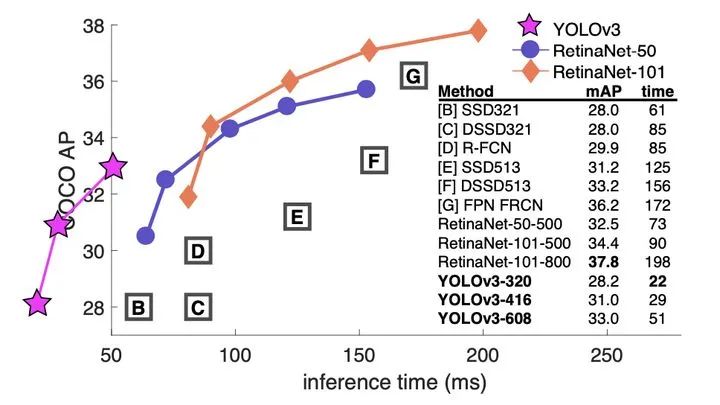
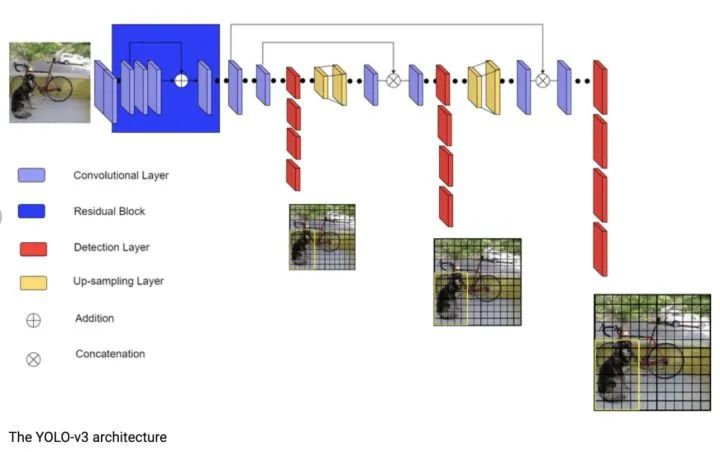
YOLOv3
论文:YOLOv3: An Incremental Improvement
主要优点
1、实时性:相比RetinaNet,YOLOv3通过牺牲检测精度,使用Darknet主干特征提取网络而不是Resnet101,从而获取更快的检测速度
2、多尺度:相比于YOLOv1-v2,与RetinaNet采用相同的FPN网络作为增强特征提取网络得到更高的检测精度
3、目标重叠:通过使用逻辑回归和二分类交叉熵损失函数进行类别预测,将每个候选框进行多标签分类,解决单个检测框可能同时包含多个目标的可能
主要不足
1、准确率:主要因为Darknet的特征提取不够强,未进行精细化结构模型设计
YOLOv4
论文:YOLOv4: Optimal Speed and Accuracy of Object Detection 鉴于YOLOv3的缺点,YOLOv5进行了Darknet53主干特征提取网络等一系列改进
主要优点
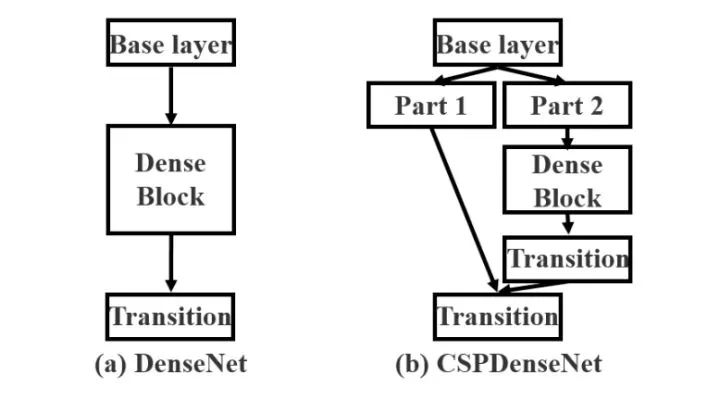
1、实时性:借鉴CSPNet网络结构将Darknet53改进为CSPDarknet53使模型参数和计算时间更短
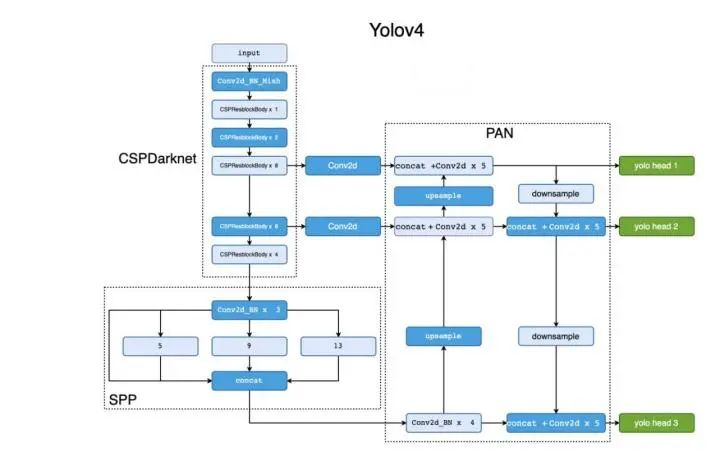
2、多尺度:颈部分别引入PAN和SPP网络结构作为增强特征提取网络,能够有效多尺度特征,相比于引入FPN网络准确度更高
3、数据增强:引入Mosaic数据增强,在使用BN的时候可以有效降低batch_size的影响
4、模型训练,采用IOU:GIoU,DIoU,CIoU作为目标框的回归,与YOLOv3使用的平方差损失相比具有更高的检测精度

YOLOv5
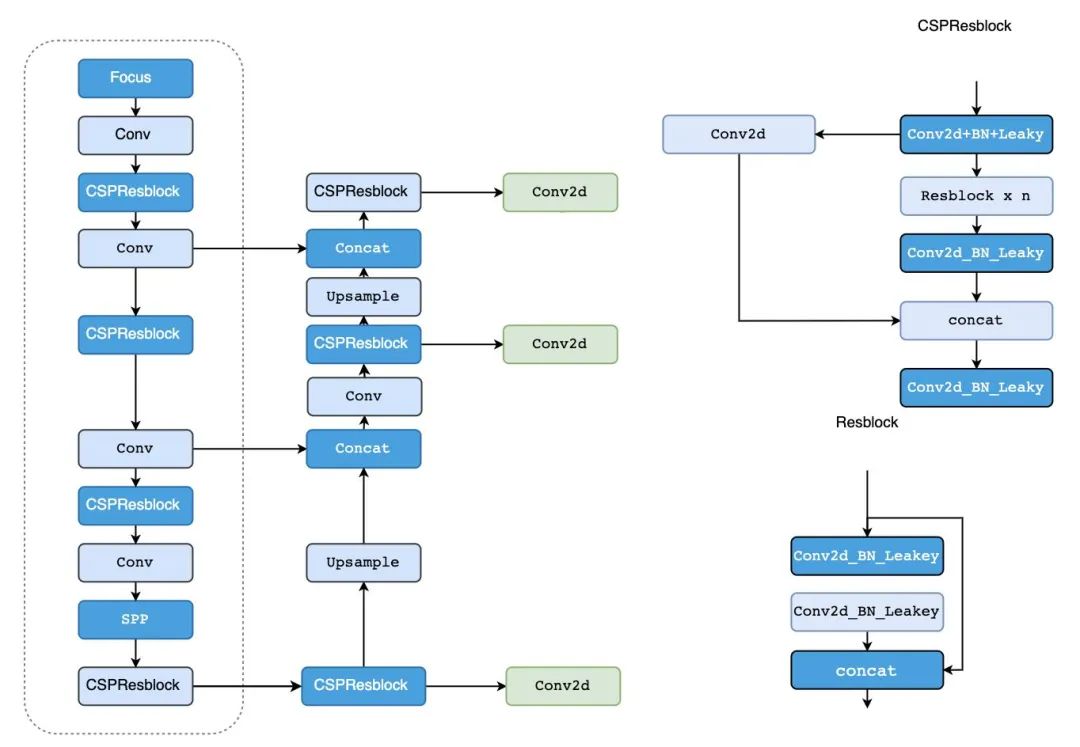
为了进一步提升YOLOv4的检测速度,YOLOv5采用了更轻量的网络结构
主要优点
1、多尺度:使用FPN增强特征提取网络代替PAN,使模型更简单,速度更快 2、目标重叠:使用四舍五入的方法进行临近位置查找,使目标映射到周围的多个中心网格点
主要不足
1、通过长宽比筛选并过滤了大小和长宽比较极端的真实目标框,而这些恰恰在真实检测任务极为重要,和重点解决的检测问题
编辑:jq
-
PowerPC小目标检测算法怎么实现?2019-08-09 2723
-
【HarmonyOS HiSpark AI Camera】基于深度学习的目标检测系统设计2020-09-25 1048
-
基于YOLOX目标检测算法的改进2023-03-06 1596
-
基于码本模型的运动目标检测算法2011-05-19 888
-
改进的ViBe运动目标检测算法_刘春2017-03-19 1430
-
如何基于深度学习的复杂气象条件下海上船只检测2018-12-19 1747
-
基于深度学习的疲劳驾驶检测算法及模型2021-03-30 1611
-
基于深度学习的目标检测研究综述2022-01-06 2893
-
浅谈红外弱小目标检测算法2022-08-04 8521
-
基于深度学习的目标检测算法解析2023-01-09 2047
-
如何学习基于Tansformer的目标检测算法2023-06-25 1666
-
无Anchor的目标检测算法边框回归策略2023-07-17 2379
-
基于强化学习的目标检测算法案例2023-07-19 1168
-
基于Transformer的目标检测算法2023-08-16 1194
全部0条评论

快来发表一下你的评论吧 !
