

一文带你手撕 STL 容器源码(下)
电子说
描述
distance(begin(), end(), result);
return result;
}
size_type max_size() const { return size_type(-1); }
// 返回第一个元素的值
reference front() { return *begin(); }
const_reference front() const { return *begin(); }
// 返回最后一个元素的值
reference back() { return *(--end()); }
const_reference back() const { return *(--end()); }
// 交换
void swap(list《T, Alloc》& x) { __STD::swap(node, x.node); }
。。。
};
template 《class T, class Alloc》
inline void swap(list《T, Alloc》& x, list《T, Alloc》& y) {
x.swap(y);
}
list 的头插和尾插
因为 list 是一个循环的双链表, 所以 push 和 pop 就必须实现是在头插入,删除还是在尾插入和删除。
在 list 中,push 操作都调用 insert 函数, pop 操作都调用 erase 函数。
template 《class T, class Alloc = alloc》
class list {
。。。
// 直接在头部或尾部插入
void push_front(const T& x) { insert(begin(), x); }
void push_back(const T& x) { insert(end(), x); }
// 直接在头部或尾部删除
void pop_front() { erase(begin()); }
void pop_back() {
iterator tmp = end();
erase(--tmp);
}
。。。
};
上面的两个插入函数内部调用的 insert 函数。
class list {
。。。
public:
// 最基本的insert操作, 之插入一个元素
iterator insert(iterator position, const T& x) {
// 将元素插入指定位置的前一个地址
link_type tmp = create_node(x);
tmp-》next = position.node;
tmp-》prev = position.node-》prev;
(link_type(position.node-》prev))-》next = tmp;
position.node-》prev = tmp;
return tmp;
}
这里需要注意的是
节点实际是以 node 空节点开始的。
插入操作是将元素插入到指定位置的前一个地址进行插入的。
删除操作
删除元素的操作大都是由 erase 函数来实现的,其他的所有函数都是直接或间接调用 erase。
list 是链表,所以链表怎么实现删除元素, list 就在怎么操作:很简单,先保留前驱和后继节点, 再调整指针位置即可。
由于它是双向环状链表,只要把边界条件处理好,那么在头部或者尾部插入元素操作几乎是一样的,同样的道理,在头部或者尾部删除元素也是一样的。
template 《class T, class Alloc = alloc》
class list {
。。。
iterator erase(iterator first, iterator last);
void clear();
// 参数是一个迭代器 修改该元素的前后指针指向再单独释放节点就行了
iterator erase(iterator position) {
link_type next_node = link_type(position.node-》next);
link_type prev_node = link_type(position.node-》prev);
prev_node-》next = next_node;
next_node-》prev = prev_node;
destroy_node(position.node);
return iterator(next_node);
}
。。。
};
。。。
}
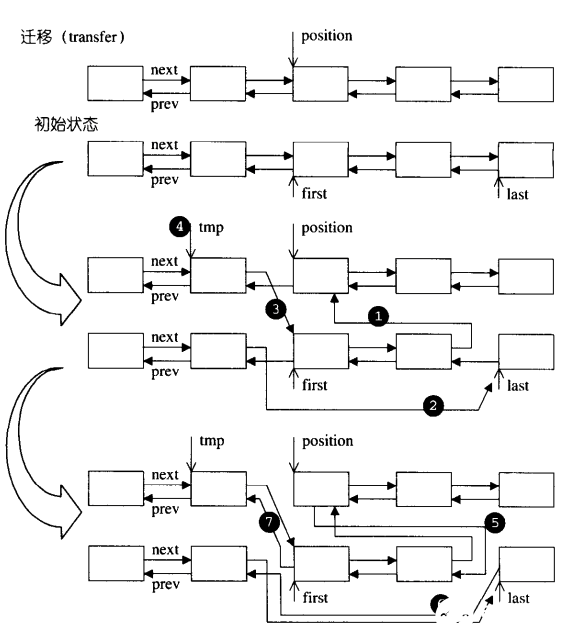
list 内部提供一种所谓的迁移操作(transfer):将某连续范围的元素迁移到某个特定位置之前,技术上实现其实不难,就是节点之间的指针移动,只要明白了这个函数的原理,后面的 splice,sort,merge 函数也就一一知晓了,我们来看一下 transfer 的源码:
template 《class T, class Alloc = alloc》
class list {
。。。
protected:
void transfer(iterator position, iterator first, iterator last) {
if (position != last) {
(*(link_type((*last.node).prev))).next = position.node;
(*(link_type((*first.node).prev))).next = last.node;
(*(link_type((*position.node).prev))).next = first.node;
link_type tmp = link_type((*position.node).prev);
(*position.node).prev = (*last.node).prev;
(*last.node).prev = (*first.node).prev;
(*first.node).prev = tmp;
}
}
。。。
};
上面代码的七行分别对应下图的七个步骤,看明白应该不难吧。
另外 list 的其它的一些成员函数这里限于篇幅,就不贴出源码了,简单说一些注意点。
splice函数: 将两个链表进行合并:内部就是调用的 transfer 函数。
merge 函数: 将传入的 list 链表 x 与原链表按从小到大合并到原链表中(前提是两个链表都是已经从小到大排序了)。 这里 merge 的核心就是 transfer 函数。
reverse 函数: 实现将链表翻转的功能:主要是 list 的迭代器基本不会改变的特点, 将每一个元素一个个插入到 begin 之前。
sort 函数: list 这个容器居然还自己实现一个排序,看一眼源码就发现其实内部调用的 merge 函数,用了一个数组链表用来存储 2^i 个元素, 当上一个元素存储满了之后继续往下一个链表存储, 最后将所有的链表进行 merge归并(合并), 从而实现了链表的排序。
赋值操作: 需要考虑两个链表的实际大小不一样时的操作:如果原链表大 : 复制完后要删除掉原链表多余的元素;如果原链表小 : 复制完后要还要将x链表的剩余元素以插入的方式插入到原链表中。
resize 操作: 重新修改 list 的大小,传入一个 new_size,如果链表旧长度大于 new_size 的大小, 那就删除后面多余的节点。
clear 操作: 清除所有节点:遍历每一个节点,销毁(析构并释放)一个节点。
remove 操作: 清除指定值的元素:遍历每一个节点,找到就移除。
unique 操作: 清除数值相同的连续元素,注意只有“连续而相同的元素”,才会被移除剩一个:遍历每一个节点,如果在此区间段有相同的元素就移除之。
感兴趣的读者可以自行去阅读源码体会。
list 总结
我们来总结一下。
list 是一种双向链表。每个结点都包含一个数据域、一个前驱指针 prev 和一个后驱指针 next。
由于其链表特性,实现同样的操作,相对于 STL 中的通用算法, list 的成员函数通常有更高的效率,内部仅需做一些指针的操作,因此尽可能选择 list 成员函数。
优点
在内部方便进行插入删除操作。
可在两端进行push和pop操作。
缺点
不支持随机访问,即下标操作和.at()。
相对于 vector 占用内存多。
deque下面到了本篇最硬核的内容了,接下来我们学习一下 双端队列 deque 。
deque 的功能很强大。
首先来一张图吧。
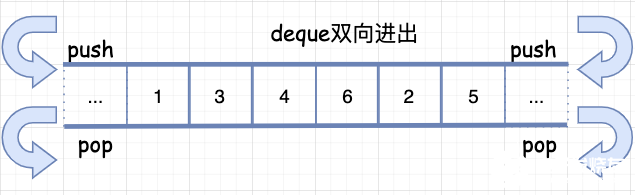
上面就是 deque 的示例图,deque 和 vector 的最大差异一在于 deque 允许常数时间内对头端或尾端进行元素的插入或移除操作。
二在于 deque 没有所谓的容量概念,因为它是动态地以分段连续空间组合而成随时可以增加一块新的空间并拼接起来。
虽然 deque 也提供 随机访问的迭代器,但它的迭代器和前面两种容器的都不一样,其设计相当复杂度和精妙,因此,会对各种运算产生一定影响,除非必要,尽可能的选择使用 vector 而非 deque。一一来探究下吧。
deque 的中控器
deque 在逻辑上看起来是连续空间,内部确实是由一段一段的定量连续空间构成。
一旦有必要在 deque 的前端或尾端增加新空间,deque 便会配置一段定量的连续空间,串接在整个 deque 的头部或尾部。
设计 deque 的大师们,想必设计的时候遇到的最大挑战就是如何在这些分段的定量连续空间上,还能维护其整体连续的假象,并提供其随机存取的接口,从而避开了像 vector 那样的“重新配置-复制-释放”开销三部曲。
这样一来,虽然开销降低,却提高了复杂的迭代器架构。
因此 deque 数据结构的设计和迭代器前进或后退等操作都非常复杂。
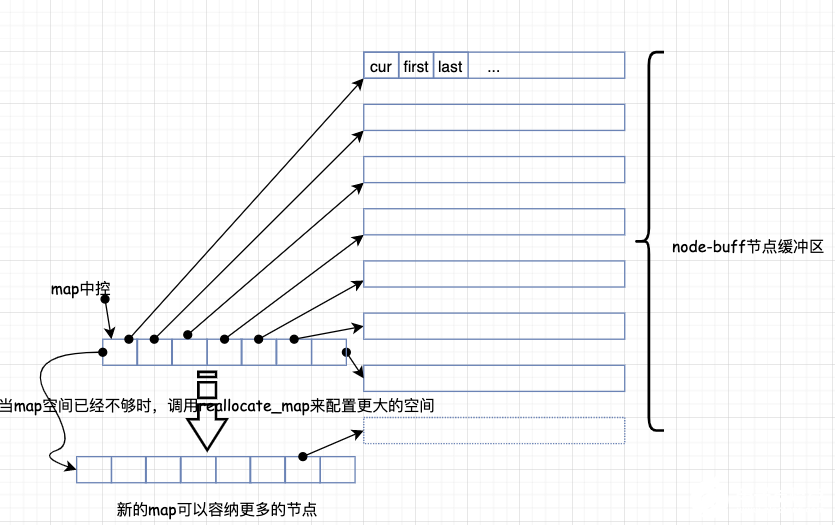
deque 采用一块所谓的 map (注意不是 STL 里面的 map 容器)作为中控器,其实就是一小块连续空间,其中的每个元素都是指针,指向另外一段较大的连续线性空间,称之为缓冲区。在后面我们看到,缓冲区才是 deque 的储存空间主体。
#ifndef __STL_NON_TYPE_TMPL_PARAM_BUGtemplate 《class T, class Ref, class Ptr, size_t BufSiz》
class deque {public:
typedef T value_type;
typedef value_type* pointer;
。。。
protected:
typedef pointer** map_pointer;
map_pointer map;//指向 map,map 是连续空间,其内的每个元素都是一个指针。
size_type map_size;
。。。
};
其示例图如下:deque 的结构设计中,map 和 node-buffer 的关系如下:
deque 的迭代器
deque 是分段连续空间,维持其“整体连续”假象的任务,就靠它的迭代器来实现,也就是 operator++ 和 operator-- 两个运算子上面。
在看源码之前,我们可以思考一下,如果让你来设计,你觉得 deque 的迭代器应该具备什么样的结构和功能呢?
首先第一点,我们能想到的是,既然是分段连续,迭代器应该能指出当前的连续空间在哪里;
其次,第二点因为缓冲区有边界,迭代器还应该要能判断,当前是否处于所在缓冲区的边缘,如果是,一旦前进或后退,就必须跳转到下一个或上一个缓冲区;
第三点,也就是实现前面两种情况的前提,迭代器必须能随时控制中控器。
有了这样的思想准备之后,我们再来看源码,就显得容易理解一些了。
template 《class T, class Ref, class Ptr, size_t BufSiz》
struct __deque_iterator {
// 迭代器定义
typedef __deque_iterator《T, T&, T*, BufSiz》 iterator;
typedef __deque_iterator《T, const T&, const T*, BufSiz》 const_iterator;
static size_t buffer_size() {return __deque_buf_size(BufSiz, sizeof(T)); }
// deque是random_access_iterator_tag类型
typedef random_access_iterator_tag iterator_category;
// 基本类型的定义, 满足traits编程
typedef T value_type;
typedef Ptr pointer;
typedef Ref reference;
typedef size_t size_type;
typedef ptrdiff_t difference_type;
// node
typedef T** map_pointer;
map_pointer node;
typedef __deque_iterator self;
。。。
};
deque 的每一个缓冲区由设计了三个迭代器(为什么这样设计?)
struct __deque_iterator {
。。。
typedef T value_type;
T* cur;
T* first;
T* last;
typedef T** map_pointer;
map_pointer node;
。。。
};
对啊,它为什么要这样设计呢?回到前面我们刚才说的,因为它是分段连续的空间。
下图描绘了deque 的中控器、缓冲区、迭代器之间的相互关系:
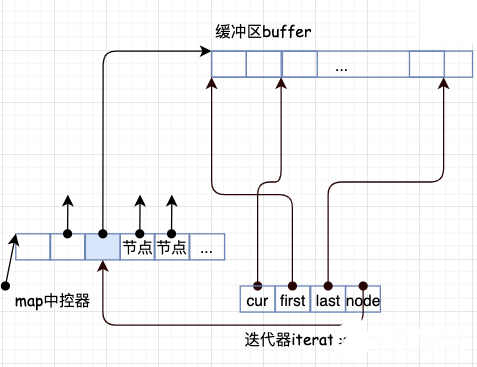
看明白了吗,每一段都指向一个缓冲区 buffer,而缓冲区是需要知道每个元素的位置的,所以需要这些迭代器去访问。
其中cur 表示当前所指的位置;
first 表示当前数组中头的位置;
last 表示当前数组中尾的位置。
这样就方便管理,需要注意的是 deque 的空间是由 map 管理的, 它是一个指向指针的指针, 所以三个参数都是指向当前的数组,但这样的数组可能有多个,只是每个数组都管理这3个变量。
那么,缓冲区大小是谁来决定的呢?这里呢,用来决定缓冲区大小的是一个全局函数:
inline size_t __deque_buf_size(size_t n, size_t sz) {
return n != 0 ? n : (sz 《 512 ? size_t(512 / sz): size_t(1));
}
//如果 n 不为0,则返回 n,表示缓冲区大小由用户自定义//如果 n == 0,表示 缓冲区大小默认值//如果 sz = (元素大小 sizeof(value_type)) 小于 512 则返回 521/sz//如果 sz 不小于 512 则返回 1
我们来举例说明一下:
假设我们现在构造了一个 int 类型的 deque,设置缓冲区大小等于 32,这样一来,每个缓冲区可以容纳 32/sizeof(int) = 4 个元素。经过一番操作之后,deque 现在有 20 个元素了,那么成员函数 begin() 和 end() 返回的两个迭代器应该是怎样的呢?
如下图所示:
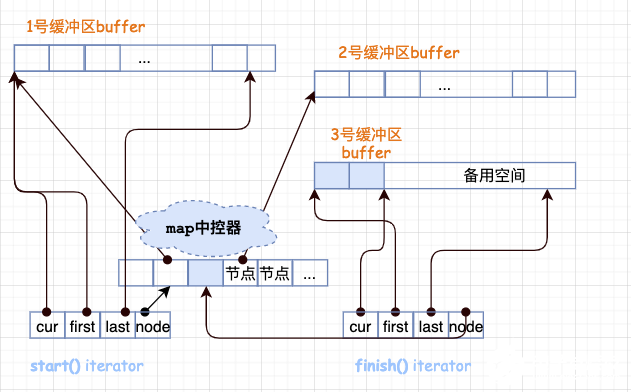
20 个元素需要 20/(sizeof(int)) = 3 个缓冲区。
所以 map 运用了三个节点,迭代器 start 内的 cur 指针指向缓冲区的第一个元素,迭代器 finish 内的 cur 指针指向缓冲区的最后一个元素(的下一个位置)。
注意,最后一个缓冲区尚有备用空间,如果之后还有新元素插入,则直接插入到备用空间。
deque 迭代器的操作
主要就是两种:前进和后退。
operator++ 操作代表是需要切换到下一个元素,这里需要先切换再判断是否已经到达缓冲区的末尾。
self& operator++() {
++cur; //切换至下一个元素
if (cur == last) { //如果已经到达所在缓冲区的末尾
set_node(node+1); //切换下一个节点
cur = first;
}
return *this;
}
operator-- 操作代表切换到上一个元素所在的位置,需要先判断是否到达缓冲区的头部,再后退。
self& operator--() {
if (cur == first) { //如果已经到达所在缓冲区的头部
set_node(node - 1); //切换前一个节点的最后一个元素
cur = last;
}
--cur; //切换前一个元素
return *this;
} //结合前面的分段连续空间,你在想一想这样的设计是不是合理呢?
deque 的构造和析构函数
deque 的构造函数有多个重载函数,接受大部分不同的参数类型,基本上每一个构造函数都会调用 create_map_and_nodes,这就是构造函数的核心,后面我们来分析这个函数的实现。
template 《class T, class Alloc = alloc, size_t BufSiz = 0》
class deque {
。。。
public: // Basic types
deque() : start(), finish(), map(0), map_size(0){
create_map_and_nodes(0);
} // 默认构造函数
deque(const deque& x) : start(), finish(), map(0), map_size(0) {
create_map_and_nodes(x.size());
__STL_TRY {
uninitialized_copy(x.begin(), x.end(), start);
}
__STL_UNWIND(destroy_map_and_nodes());
}
// 接受 n:初始化大小, value:初始化的值
deque(size_type n, const value_type& value) : start(), finish(), map(0), map_size(0) {
fill_initialize(n, value);
}
deque(int n, const value_type& value) : start(), finish(), map(0), map_size(0) {
fill_initialize(n, value);
}
deque(long n, const value_type& value) : start(), finish(), map(0), map_size(0){
fill_initialize(n, value);
}
。。。
下面我们来看一下 deque 的中控器是如何配置的。
void deque《T,Alloc,BufSize》::create_map_and_nodes(size_type_num_elements) {
//需要节点数= (每个元素/每个缓冲区可容纳的元素个数+1)
//如果刚好整除,多配一个节点
size_type num_nodes = num_elements / buffer_size() + 1;
//一个 map 要管理几个节点,最少 8 个,最多是需要节点数+2
map_size = max(initial_map_size(), num_nodes + 2);
map = map_allocator::allocate(map_size);
// 计算出数组的头前面留出来的位置保存并在nstart.
map_pointer nstart = map + (map_size - num_nodes) / 2;
map_pointer nfinish = nstart + num_nodes - 1;
map_pointer cur;//指向所拥有的节点的最中央位置
。。。
}
注意了,看了源码之后才知道:deque 的 begin 和 end 不是一开始就是指向 map 中控器里开头和结尾的,而是指向所拥有的节点的最中央位置。
这样带来的好处是可以使得头尾两边扩充的可能性和一样大,换句话来说,因为 deque 是头尾插入都是 O(1), 所以 deque 在头和尾都留有空间方便头尾插入。
那么,什么时候 map 中控器 本身需要调整大小呢?触发条件在于 reserve_map_at_back 和 reserve_map_at_front 这两个函数来判断,实际操作由 reallocate_map 来执行。
那 reallocate_map 又是如何操作的呢?这里先留个悬念。
// 如果 map 尾端的节点备用空间不足,符合条件就配置一个新的map(配置更大的,拷贝原来的,释放原来的)void reserve_map_at_back (size_type nodes_to_add = 1) {
if (nodes_to_add + 1 》 map_size - (finish.node - map))
reallocate_map(nodes_to_add, false);
}
// 如果 map 前端的节点备用空间不足,符合条件就配置一个新的map(配置更大的,拷贝原来的,释放原来的)void reserve_map_at_front (size_type nodes_to_add = 1) {
if (nodes_to_add 》 start.node - map)
reallocate_map(nodes_to_add, true);
}
deque 的插入元素和删除元素
因为 deque 的是能够双向操作,所以其 push 和 pop 操作都类似于 list 都可以直接有对应的操作,需要注意的是 list 是链表,并不会涉及到界线的判断, 而deque 是由数组来存储的,就需要随时对界线进行判断。
push 实现
template 《class T, class Alloc = alloc, size_t BufSiz = 0》
class deque {
。。。
public: // push_* and pop_*
// 对尾进行插入
// 判断函数是否达到了数组尾部。 没有达到就直接进行插入
void push_back(const value_type& t) {
if (finish.cur != finish.last - 1) {
construct(finish.cur, t);
++finish.cur;
}
else
push_back_aux(t);
}
// 对头进行插入
// 判断函数是否达到了数组头部。 没有达到就直接进行插入
void push_front(const value_type& t) {
if (start.cur != start.first) {
construct(start.cur - 1, t);
--start.cur;
}
else
push_front_aux(t);
}
。。。
};
pop 实现
template 《class T, class Alloc = alloc, size_t BufSiz = 0》
class deque {
。。。
public:
// 对尾部进行操作
// 判断是否达到数组的头部。 没有到达就直接释放
void pop_back() {
if (finish.cur != finish.first) {
--finish.cur;
destroy(finish.cur);
}
else
pop_back_aux();
}
// 对头部进行操作
// 判断是否达到数组的尾部。 没有到达就直接释放
void pop_front() {
if (start.cur != start.last - 1) {
destroy(start.cur);
++start.cur;
}
else
pop_front_aux();
}
。。。
};
pop 和 push 都先调用了 reserve_map_at_XX 函数,这些函数主要是为了判断前后空间是否足够。
删除操作
不知道还记得,最开始构造函数调用 create_map_and_nodes 函数,考虑到 deque 实现前后插入时间复杂度为O(1),保证了在前后留出了空间,所以 push 和 pop 都可以在前面的数组进行操作。
现在就来看 erase,因为 deque 是由数组构成,所以地址空间是连续的,删除也就像 vector一样,要移动所有的元素。
deque 为了保证效率尽可能的高,就判断删除的位置是中间偏后还是中间偏前来进行移动。
template 《class T, class Alloc = alloc, size_t BufSiz = 0》
class deque {
。。。
public: // erase
iterator erase(iterator pos) {
iterator next = pos;
++next;
difference_type index = pos - start;
// 删除的地方是中间偏前, 移动前面的元素
if (index 《 (size() 》》 1)) {
copy_backward(start, pos, next);
pop_front();
}
// 删除的地方是中间偏后, 移动后面的元素
else {
copy(next, finish, pos);
pop_back();
}
return start + index;
}
// 范围删除, 实际也是调用上面的erase函数。
iterator erase(iterator first, iterator last);
void clear();
。。。
};
最后讲一下 insert 函数
deque 源码的基本每一个insert 重载函数都会调用了 insert_auto判断插入的位置离头还是尾比较近。
如果离头进:则先将头往前移动,调整将要移动的距离,用 copy 进行调整。
如果离尾近:则将尾往前移动,调整将要移动的距离,用 copy 进行调整。
注意 : push_back 是先执行构造在移动 node,而 push_front 是先移动 node 在进行构造,实现的差异主要是 finish 是指向最后一个元素的后一个地址而 first指 向的就只第一个元素的地址,下面 pop 也是一样的。
deque 源码里还有一些其它的成员函数,限于篇幅,这里就不贴出来了,简单的过一遍
reallocate_map:判断中控器的容量是否够用,如果不够用,申请更大的空间,拷贝元素过去,修改 map 和 start,finish 的指向。
fill_initialize 函数:申请空间,对每个空间进行初始化,最后一个数组单独处理。毕竟最后一个数组一般不是会全部填充满。
clear 函数:删除所有元素,分两步执行:
首先从第二个数组开始到倒数第二个数组一次性全部删除,这样做是考虑到中间的数组肯定都是满的,前后两个数组就不一定是填充满的,最后删除前后两个数组的元素。
deque 的 swap 操作:只是交换了 start, finish, map,并没有交换所有的元素。
resize 函数: 重新将 deque 进行调整, 实现与 list一样的。
析构函数: 分步释放内存。
deque 总结
deque 其实是在功能上合并了 vector 和 list。
优点:
1、随机访问方便,即支持 [ ] 操作符和 vector.at();
2、在内部方便的进行插入和删除操作;
3、可在两端进行 push、pop
缺点:因为涉及比较复杂,采用分段连续空间,所以占用内存相对多。
使用区别:
1、如果你需要高效的随即存取,而不在乎插入和删除的效率,使用 vector。
2、如果你需要大量的插入和删除,而不关心随机存取,则应使用 list。
3、如果你需要随机存取,而且关心两端数据的插入和删除,则应使用 deque 。
栈和队列以 deque 为底层容器的适配器
最后要介绍的三种常用的数据结构,准确来说其实是一种适配器,底层都是已其它容器为基准。
栈-stack:先入后出,只允许在栈顶添加和删除元素,称为出栈和入栈。
队列-queue:先入先出,在队首取元素,在队尾添加元素,称为出队和入队。
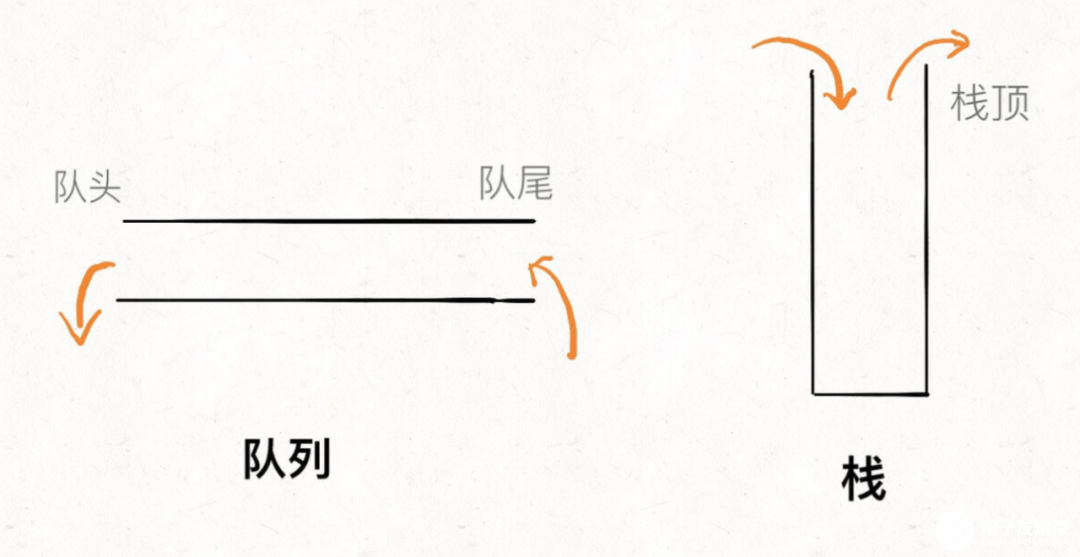
优先队列-priority_queue:带权值的队列。
常见栈的应用场景包括括号问题的求解,表达式的转换和求值,函数调用和递归实现,深度优先遍历 DFS 等;
常见的队列的应用场景包括计算机系统中各种资源的管理,消息缓冲队列的管理和广度优先遍历 BFS 等。
翻一下源码,就知道 stack 和 queue 的底层其实就是使用 deque,用 deque 为底层容器封装。
stack 的源码:
#ifndef __STL_LIMITED_DEFAULT_TEMPLATEStemplate 《class T, class Sequence = deque《T》 》
#else
template 《class T, class Sequence》
#endif
class stack {public:
typedef typename Sequence::value_type value_type;
typedef typename Sequence::size_type size_type;
typedef typename Sequence::reference reference;
typedef typename Sequence::const_reference const_reference;
protected:
Sequence c;
queue 的源码:
#ifndef __STL_LIMITED_DEFAULT_TEMPLATEStemplate 《class T, class Sequence = deque《T》 》
#else
template 《class T, class Sequence》
#endif
class queue {public:
typedef typename Sequence::value_type value_type;
typedef typename Sequence::size_type size_type;
typedef typename Sequence::reference reference;
typedef typename Sequence::const_reference const_reference;
protected:
Sequence c;
heap堆最后我们来看一下,heap ,heap 并不是一个容器,所以他没有实现自己的迭代器,也就没有遍历操作,它只是一种算法。
push_heap 插入元素
插入函数是 push_heap, heap 只接受 RandomAccessIterator 类型的迭代器。
template 《class RandomAccessIterator》
inline void push_heap(RandomAccessIterator first, RandomAccessIterator last) {
__push_heap_aux(first, last, distance_type(first), value_type(first));
}
template 《class RandomAccessIterator, class Distance, class T》
inline void __push_heap_aux(RandomAccessIterator first, RandomAccessIterator last, Distance*, T*) {
// 这里传入的是两个迭代器的长度, 0, 还有最后一个数据
__push_heap(first, Distance((last - first) - 1), Distance(0), T(*(last - 1)));
}
pop_heap 删除元素
pop 操作其实并没有真正意义去删除数据,而是将数据放在最后,只是没有指向最后的元素而已,这里使用 arrary 也可以,毕竟没有对数组的大小进行调整。
pop 的实现有两种,这里都罗列了出来,另一个传入的是 cmp 仿函数。
template 《class RandomAccessIterator, class Compare》
inline void pop_heap(RandomAccessIterator first, RandomAccessIterator last,
Compare comp) {
__pop_heap_aux(first, last, value_type(first), comp);
}
template 《class RandomAccessIterator, class T, class Compare》
inline void __pop_heap_aux(RandomAccessIterator first,
RandomAccessIterator last, T*, Compare comp) {
__pop_heap(first, last - 1, last - 1, T(*(last - 1)), comp,
distance_type(first));
}
template 《class RandomAccessIterator, class T, class Compare, class Distance》
inline void __pop_heap(RandomAccessIterator first, RandomAccessIterator last,
RandomAccessIterator result, T value, Compare comp,
Distance*) {
*result = *first;
__adjust_heap(first, Distance(0), Distance(last - first), value, comp);
}
template 《class RandomAccessIterator, class T, class Distance》
inline void __pop_heap(RandomAccessIterator first, RandomAccessIterator last,
RandomAccessIterator result, T value, Distance*) {
*result = *first; // 因为这里是大根堆, 所以first的值就是最大值, 先将最大值保存。
__adjust_heap(first, Distance(0), Distance(last - first), value);
}
make_heap 将数组变成堆存放
template 《class RandomAccessIterator》
inline void make_heap(RandomAccessIterator first, RandomAccessIterator last) {
__make_heap(first, last, value_type(first), distance_type(first));
}
template 《class RandomAccessIterator, class T, class Distance》
void __make_heap(RandomAccessIterator first, RandomAccessIterator last, T*,
Distance*) {
if (last - first 《 2) return;
// 计算长度, 并找出中间的根值
Distance len = last - first;
Distance parent = (len - 2)/2;
while (true) {
// 一个个进行调整, 放到后面
__adjust_heap(first, parent, len, T(*(first + parent)));
if (parent == 0) return;
parent--;
}
}
sort_heap 实现堆排序
其实就是每次将第一位数据弹出从而实现排序功。
template 《class RandomAccessIterator》
void sort_heap(RandomAccessIterator first, RandomAccessIterator last) {
while (last - first 》 1) pop_heap(first, last--);
}
template 《class RandomAccessIterator, class Compare》
void sort_heap(RandomAccessIterator first, RandomAccessIterator last,
Compare comp) {
while (last - first 》 1) pop_heap(first, last--, comp);
}
priority_queue 优先队列最后我们来看一下 priority_queue。
上一节分析 heap 其实就是为 priority_queue 做准备,priority_queue 是一个优先级队列,是带权值的, 支持插入和删除操作,其只能从尾部插入,头部删除, 并且其顺序也并非是根据加入的顺序排列的。
priority_queue 因为也是队列的一种体现, 所以也就跟队列一样不能直接的遍历数组,也就没有迭代器。
priority_queue 本身也不算是一个容器,它是以 vector 为容器以 heap为数据操作的配置器。
类型定义
#ifndef __STL_LIMITED_DEFAULT_TEMPLATEStemplate 《class T, class Sequence = vector《T》,
class Compare = less《typename Sequence::value_type》 》
#else
template 《class T, class Sequence, class Compare》
#endif
class priority_queue {public:
// 符合traits编程规范
typedef typename Sequence::value_type value_type;
typedef typename Sequence::size_type size_type;
typedef typename Sequence::reference reference;
typedef typename Sequence::const_reference const_reference;
protected:
Sequence c; // 定义vector容器的对象
Compare comp; // 定义比较函数(伪函数)
。。。
};
属性获取
priority_queue 只有简单的 3 个属性获取的函数, 其本身的操作也很简单, 只是实现依赖了 vector 和 heap 就变得比较复杂。
class priority_queue {
。。。
public:
bool empty() const { return c.empty(); }
size_type size() const { return c.size(); }
const_reference top() const { return c.front(); }
。。。
};
push 和 pop 实现
push 和 pop 具体都是采用的 heap 算法。
priority_queue 本身实现是很复杂的,但是当我们已经了解过 vector,heap 之后再来看,它其实就简单了。
就是将 vector 作为容器, heap 作为算法来操作的配置器,这也体现了 STL 的灵活性: 通过各个容器与算法的结合就能实现另一种功能。
最后,来自实践生产环境的一个体会:上面所列的所有容器的一个原则:为了避免拷贝开销,不要直接把大的对象直接往里塞,而是使用指针。
编辑:jq
-
智慧公交是什么?一文带你详解智慧公交的解决方案!2024-11-05 2066
-
C++中STL容器中的常见容器及基本操作2023-11-10 1480
-
空降攻略!一文带你玩转2023开放原子全球开源峰会2023-05-30 1593
-
C++之STL库中的容器2023-02-21 2729
-
一文带你读懂Docker容器 12023-02-03 1815
-
一文带你了解真正的PCB高可靠pdf.zip2022-12-30 556
-
RT-Thread记录(十一、UART设备—源码解析)2022-07-01 7523
-
一文带你了解步进电机的相关知识2021-07-08 2358
-
一文带你手撕 STL 容器源码(上)2021-04-30 2302
-
STL编写定时器程序编程方法2021-02-09 6174
-
STL源码剖析中的,这个new是什么用法?这个函数的作用是?2011-03-21 2876
-
effective stl中文版下载pdf2008-08-25 3251
全部0条评论

快来发表一下你的评论吧 !
