

Moore Moore的一些路线预测
电子说
描述
编 者 按
上世纪中叶,IEEE电子和电子工程师协会在上世纪中叶设立了一个叫ITRS的组织,该组织每年都会发布一份半导体领域中技术路线图——ITRS(International Technology Roadmap for Semiconductors)路线图。但在2017年,IEEE停止更新ITRS,并将其重新重命名为IRDS,他们认为这样可以更全面地反应各种系统级新技术。
与此同时,业界提出了More Moore、Moore than Moore和Beyond COMS三种方法,来持续提升芯片性能。在本文中,我们摘译了IRDS最新版本的IRDS 2020,里面谈及Moore Moore的一些路线预测,欢迎大家阅读。
技术现状
大部分的半导体器件都是数字逻辑,那就需要去支持两种器件类型的技术平台:1)高性能逻辑;2)低功耗/高密度逻辑。该技术平台的关键考虑因素是速度、功耗、密度和成本。More Moore路线图为MOSFET的持续扩展提供了一个参考,以保持以更低的功耗和成本改进设备性能的历史趋势。
所谓“More Moore”,这是一个延续CMOS的整体思路方法,具体而言就是在器件结构、沟道材料、连接导线、高介质金属栅、架构系统、制造工艺等等方面进行创新研发,沿着摩尔定律一路微缩。
以下应用推动了IRDS中More Moore技术的需求:
•高性能计算——在恒定功率密度(受热约束)下的更高性能
•移动计算——以恒定的功耗(受电池限制)和成本提供更多的性能和功能
•自主感知和计算(IoT)——以减少泄漏( leakage)和变异性(variability)为目标
而技术驱动因素包括以下重点项目:逻辑技术(Logic technologies)、基本规则缩放(Ground rule scaling)、性能助推器(Performance boosters)、性能-功率-尺寸(PPA)缩放(Performance-power-area (PPA) scaling)、3D集成(3D integration)、内存技术(Memory technologies)、DRAM技术(DRAM technologies)、Flash技术(Flash technologies)、新兴的非易失性内存(NVM)技术(Emerging non-volatile-memory (NVM) technologies)
More Moore目标是每2——3年为节点扩展带来PPAC价值:
•(P)性能:在标度电源电压下,工作频率增加15%以上•(P)功率:在给定性能下,每次开关的能量损耗减少30%以上•(A)面积:减少30%的芯片面积;•(C)成本:晶圆成本增加《30% -缩放裸片成本减少15%。
这些标度目标推动了该行业的一些重大技术创新,包括材料和工艺的变化,如 high-κ栅极电介质和应变增强(strain enhancement),以及在不久的将来,新的架构,如栅极全方位(GAA);替代高迁移率沟道材料和新的3D集成方案,允许异构叠加/集成。这些创新将以快速的速度引入,因此及时地理解、建模和实现到制造业中对行业来说是至关重要的。
需要注意的是,成本指标(减少15%的裸片成本)和市场节奏(每年都需要推出新产品)在移动产业中越来越重要。由于应用严格要求所有figure-of-merits(FoM)同时满足,有必要推进一个有效的工艺技术清单,以维持某些设备架构的极限,例如在未来五年推动finFET架构。
在从一个逻辑世代到另一个逻辑世代的过程中,这种方法还有助于以降低风险的方式维持成本。由于多图形光刻步骤的增加,晶圆加工的成本越来越高,这就变得更加困难。我们还 需要在相同数量的晶体管上降低15%以上的成本,这只能通过在沟道材料、器件架构、接触工程(contact engineering)和器件隔离方面的新进展实现pitch scaling。增加的工艺复杂性也必须考虑到整个裸片良率。为了补偿复杂性的成本,需要加速设计效率,进一步扩大面积,以达到裸片成本的比例目标。
在ITRS的系统驱动技术工作组的早期工作中也观察到了这些设计诱导的缩放因子,它们被用作校准因子,以匹配行业的面积缩放趋势。设计比例因子(design scaling factor)现在被认为是More Moore技术路线图的关键元素之一。
半导体行业的目标是能够在降低功耗和成本的情况下继续扩大技术的整体性能。器件和最终芯片的性能可以通过许多不同的方式来衡量:更高的速度、更高的密度、更低的功耗、更多的功能,等等。从本质上讲,dimensional scaling已经足以带来上述的性能优点,但现在已经不是这样了。制程、工具和材料性能等,对继续扩展提出了困难的挑战。我们在表MM-5和表MM-6中总结了这些困难的挑战。这些挑战分为近期2020-2025年(表MM-5)和长期2026-2034年(表MM-6)。
如下图所示表MM-5展示了近期的挑战。
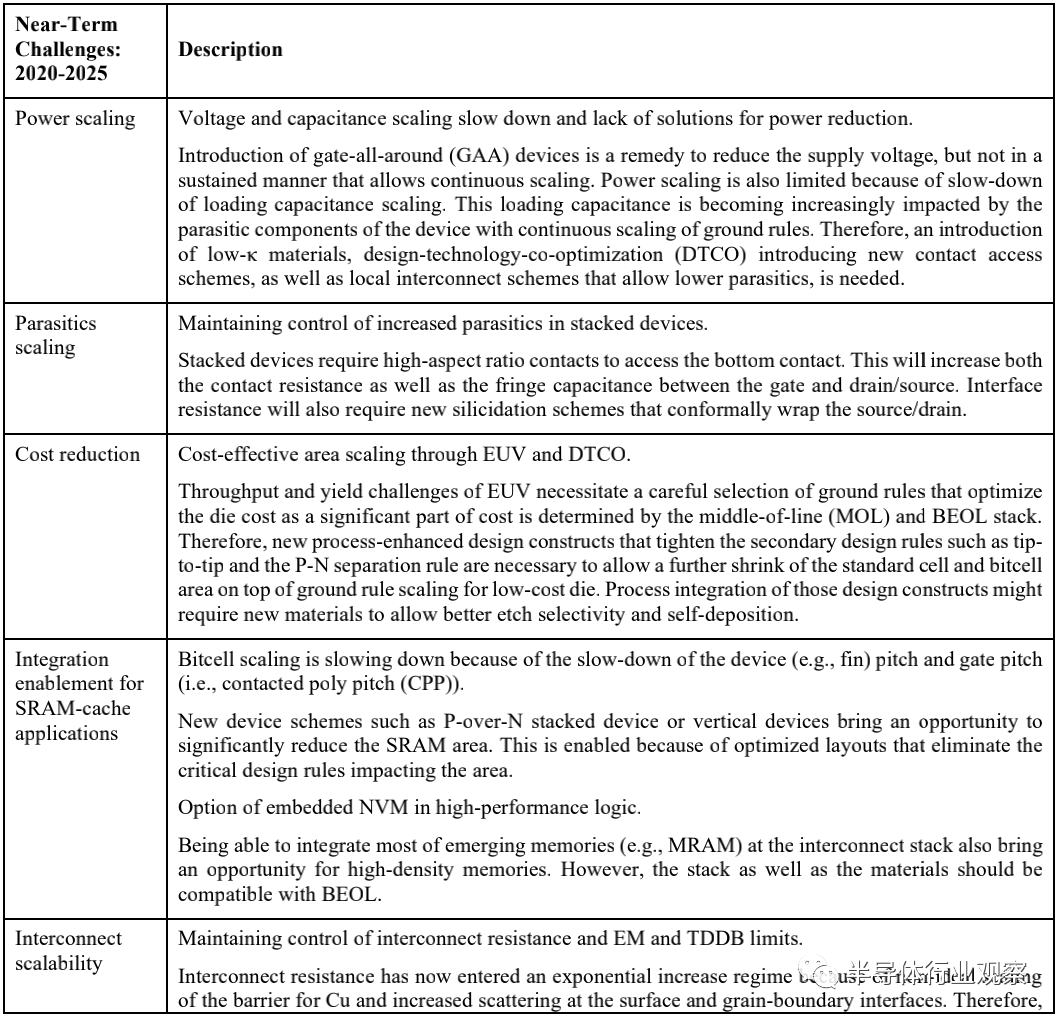

表MM-6则说明了长期的困难挑战
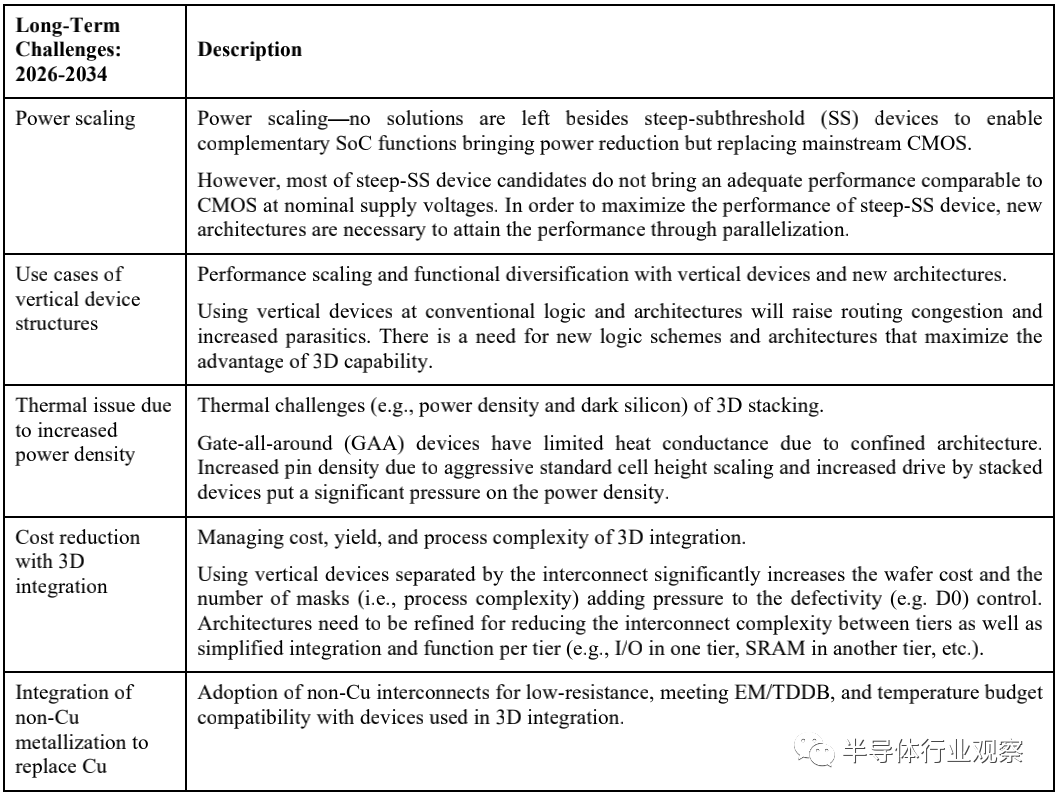
晶体管的演进
在More Moore路线图中,我们将重点放在了有效的解决方案上,以在缩放的尺寸和缩放的供电电压下维持性能和功率的缩放。基本规则缩放(Ground rule scaling )驱动裸片成本降低。然而,这种缩放增加了寄生在总负载中的部分,并在性能和功率缩放中带来的缩放收益递减。因此,有必要关注技术扩展的解决方案,同时扩展设备和互连的寄生。
基础规则缩放(Ground rule scaling )还需要使DTCO结构能够适应面积缩小,并收紧限制面积缩放的关键设计规则。由于multiple patterning的成本和过程的复杂性,EUV被用于以较少的制程步骤来解决模式严密的基本规则。规划的基本规则路线图和设备架构如表MM-7所示。基本规则的演化过程如图MM-2所示。对于不同的代工厂和集成设备制造商(IDMs)的节点命名还没有达成共识;
然而,计划规则给出了技术能力符合PPAC要求的指示。基础规则(ground rules)中的关键参数是栅极间距、金属间距、fin间距和栅极长度,它们是核心逻辑区域缩放的重要因素。
表MM-7逻辑器件的设备件、PPA和基本规则路线图。
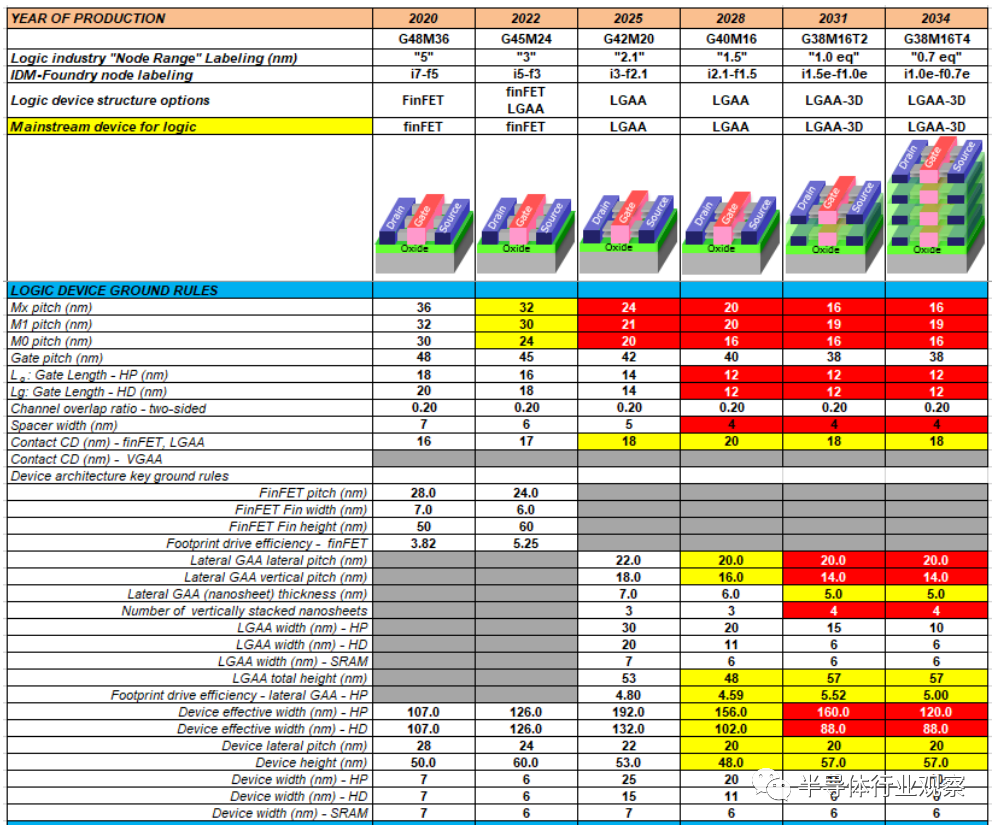
表中使用的首字母缩写(按外观顺序):LGAA-lateral gate-all-around-device (GAA), 3DVLSI-fine-pitch 3D逻辑顺序集成。
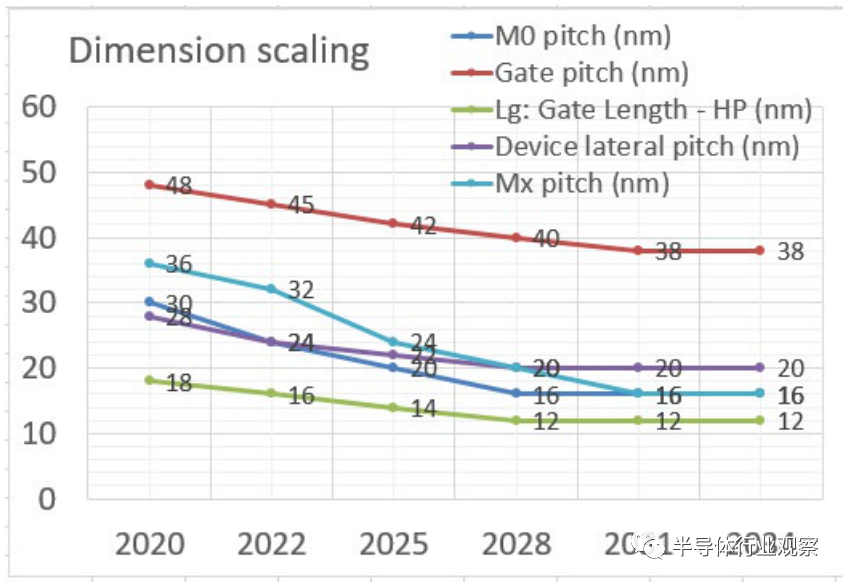
图MM-2关键基本规则的投影比例
仅按基本规则缩放(Ground rule scaling )不足以缩放单元格高度。有必要将设计比例系数付诸实践。例如,标准单元高度将通过缩放标准单元中有源器件的数量/宽度以及缩放次要规则(例如尖端到尖端(tip-to-tip)、延伸、P-N分离(P-N separation)和最小面积规则)来进一步减小。
类似地,可以通过关注关键设计规则(如边缘fin的fin端接等)和启用结构(如有源接触)来减小标准单元宽度。此外,需要仔细选择接触结构,以降低连接处电流密度增加的风险。预计到2028年,P和N器件可以堆叠在一起,从而进一步降低成本。标准单元缩放的趋势如图MM-3所示。
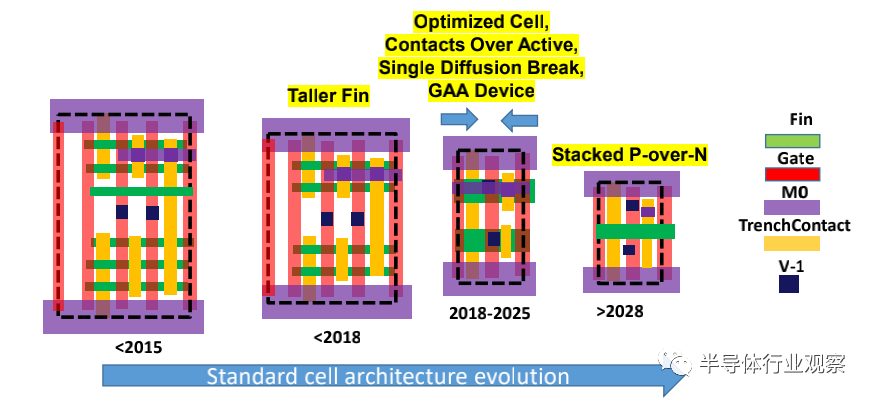
图MM-3通过fin去填充和设备堆叠缩放标准单元高度和宽度
在我们看来,2031年以后,就没有二维微缩的空间了,使用顺序/堆叠集成方法的电路和系统的三维超大规模集成(VLSI)将是必要的。这是由于没有接触放置(contactplacement )的空间,以及由于gate pitch scaling和metal pitch scaling而导致性能恶化。
据预测,由于静电效应的恶化,物理沟道长度将在12nm左右饱和,而gate pitch将在38nm处饱和,以便为器件接触预留足够的宽度(~14nm),提供可接受的寄生。3D VLSI期望为目标节点带来PPAC增益,并为异构和/或混合集成铺平道路。
这种3D集成的挑战是如何划分系统,以更好地利用设备、互连和子系统(如内存、模拟和I/O)。这就是为什么在2031年后需要进行functional scaling和/或重大架构更改的原因。这可能是Beyond CMOS和专业技术设备/组件的时代,将系统微缩到单位功率密度和单位立方体积下的高系统性能。
在130nm节点出现之前的最初几年,晶体管遵循着Dennard scaling,其中等效氧化物厚度(EOT)、晶体管栅极长度(Lg)和晶体管宽度(W)均采用常数因子进行微缩,以便在恒定功率密度下提供延迟改善。
目前,有许多输入参数可以改变,而输出参数是这些输入参数的复杂函数。可发现其它组投射的参数值(即,不同的缩放场景)来实现相同的目标。为了维持低电压下的定标,近年来的定标主要集中在提高性能的其他解决方案上,如在沟道中引入应变、应力助推器、high-κ金属栅、降低接触电阻和改善静电。所有这些都是为了补偿栅极驱动损耗的同时,还满足高性能移动应用所需要的低电源电压。
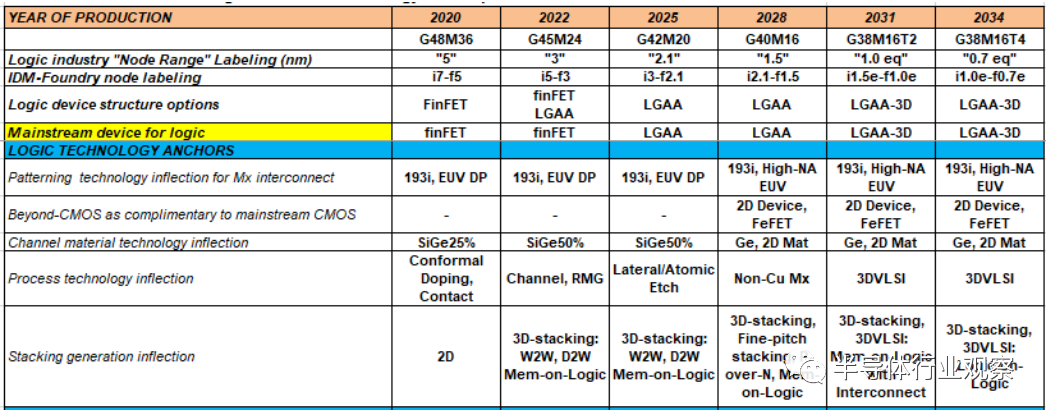
设备架构、关键模块和performance boosters的路线图概述如表MM-8所示。
表MM-8More Moore微缩的设备路线图和技术锚定。
FinFET仍然是关键的晶体管架构,目前看来他们还可以持续扩展到2025年。ctrostatics和findepopulation仍然是改善性能的两种有效解决方案。寄生改进(Parasitics improvement)预计将继续作为性能改进的主要手段,作为收紧设计规则的结果。预计寄生( parasitics )将继续作为关键路径性能的主导项。
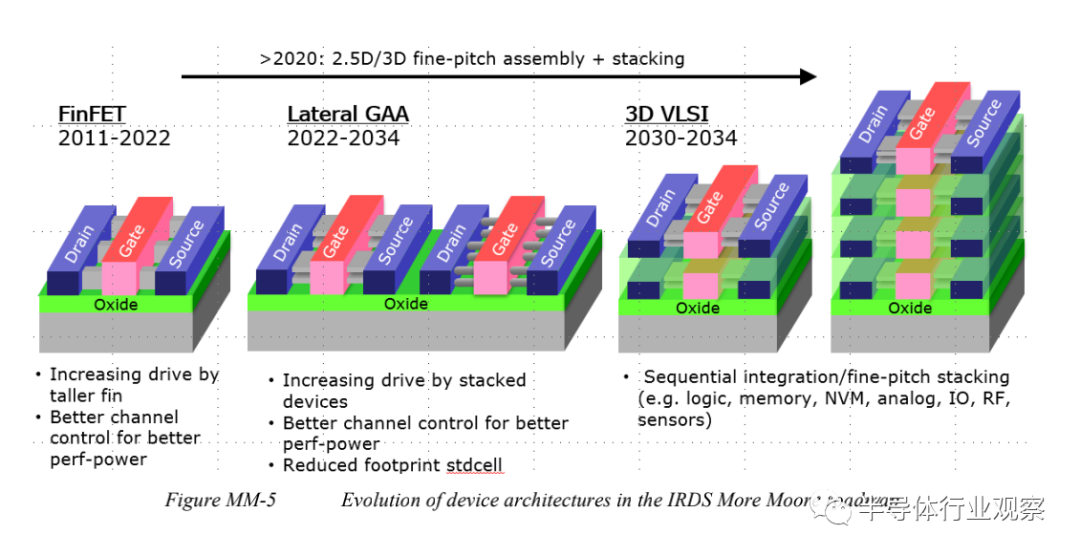
为了降低供电电压,未来的晶体管必须过渡到如横向 nanosheets这样的GAA结构,以维持栅极驱动改进的静电学。横向GAA结构最终将演变为与垂直GAA结构的混合形式,以弥补由于在更紧密的pitches上增加寄生以及特殊SoC功能(如内存选择器)所造成的性能损失。
顺序集成(Sequential integration)将允许采用单片3D (monolithic 3D)集成在彼此之上进行堆叠。微缩的焦点则将从单线程性能提升转移到功耗降低,然后发展到高度并行的3D架构,允许低Vdd操作和更多的功能嵌入到单位立方体体积中。
虽然设备架构正在发生变化,但后续的模块预计也将发展。这些可能包括:
1.起始衬底,如Si到绝缘体体上硅(SOI)和SRA(strain-relaxation-buffer);2.从Si到SiGe、Ge、IIIV的沟道材料演变;3.接触模块从硅化物演变为提供更低肖特基阻隔高度(SBH)的新型材料,并采用包裹式接触集成方案来增加接触表面积。
正如前面提到的,finFET可能可能会维持到2025年。到2022年以后,横向GAA晶体管的过渡预计将开始,并可能包括纵向GAA设备的混合形式与横向GAA,潜在的3D混合memory-on-logic应用。这种情况是由于fin宽度缩放和接触宽度的限制。
Parasitic capacitance penalty, Weff(effective drive width )和RMG9(replacement metal gate )集成对GAA的应用构成了挑战。一个折衷的解决方案可能是EGAA(electrically GAA)架构,它大大减少寄生电容,并增加有效宽度,以带来更好的短沟道控制和更强的驱动。晶体管架构的演进规划如图MM-5和图MM-5所示。
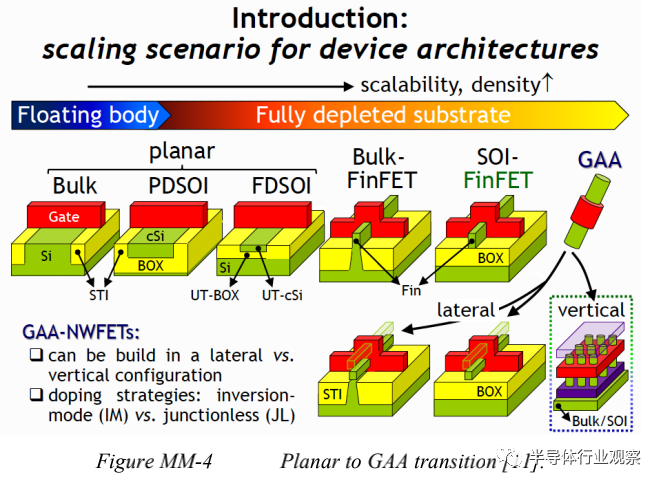
体硅仍将是主流衬底,而绝缘体上硅(SOI)和SRB将分别用于支持更好的隔离(例如,射频集成)和无缺陷集成的高迁移率沟道。
我们知道,像Ge和III-V族材料这样的高迁移率材料在通过增加一个数量级的固有迁移率来增加驱动电流方面带来了希望。随着栅极长度的缩放,由于速度饱和,迁移率对漏极电流的影响变得有限。
另一方面,当栅极长度进一步缩小时,载流子传输变成了ballistic。这使得载流子的速度(也称为“注入速度”)随着移动性的增加而导致漏极电流的增加。然而,对于高迁移率器件,低有效质量(low effective mass)实际上会在较高的供电电压下产生高的隧穿电流。这可能会降低III-V器件在短沟道工作函数调谐后的有效性能(例如,阈值电压增加),以降低漏电流(Ioff),以补偿隧穿电流。
高迁移率沟道需要考虑的另一个问题是较低的态密度( lower density of states)。电流与沟道中的漂移速度和载流子浓度的乘积成正比。这就需要正确选择栅极长度(Lg)、电源电压(Vdd)和器件结构,以最大化这一乘积,而这些参数的选择将因所使用的沟道材料类型不同而不同。这一切都需要整体解决。
很可能,高移动性沟道将用于连续集成,以协同集成高速IOs、RF(如5G及以上)和photonics协集成。
在过去十年中,应变工程(Strain engineering)已被用作最有效的解决方案之一,如32nm节点和早期的所示。然而,这些压力源的影响可能不能直观地推进到新的节点上。随着栅极间距的缩小,源漏外延(S/D EPI)接触和SRB上的SiGe仍然是高迁移率沟道材料的两倍以上的迁移率的有效助推器。工程师们在使用SRB的7nm CMOS平台上成功地演示了PMOS的SiGe沟道和NMOS的应变Si沟道。
另一方面,SRB或S/D应力源可能对垂直器件中的沟道应力产生不起作用。其他应变工程技术还包括gate stressor 和ground plane stressors。
互联和3D异构集成
对于芯片的未来,互联也是一个重要方面,而互连最困难的挑战是引入满足导线导电性要求、降低介电常数和满足可靠性要求的新材料。对于导电性,必须减小尺寸效应对互连结构的影响。尺寸控制是当今和未来几代互连技术面临的一个关键挑战,由此产生的刻蚀难题是在 low-κ介电材料中形成精确的沟道和通孔结构,以减少阻容(RC)的变化。
为了获得最大的性能,互连结构不能容忍剖面的变化而不产生不希望的RC退化。这些尺寸控制要求对测量高深宽比结构的高通量成像计量提出了新的要求。新的计量技术也需要在线监测附着力和缺陷。更大的晶圆和限制测试晶圆的需要将推动更多的现场过程控制技术的采用。表MM-12突出并区分了最主要的挑战,表MM-13显示了互连扩展路线图。
表MM-12互连难题
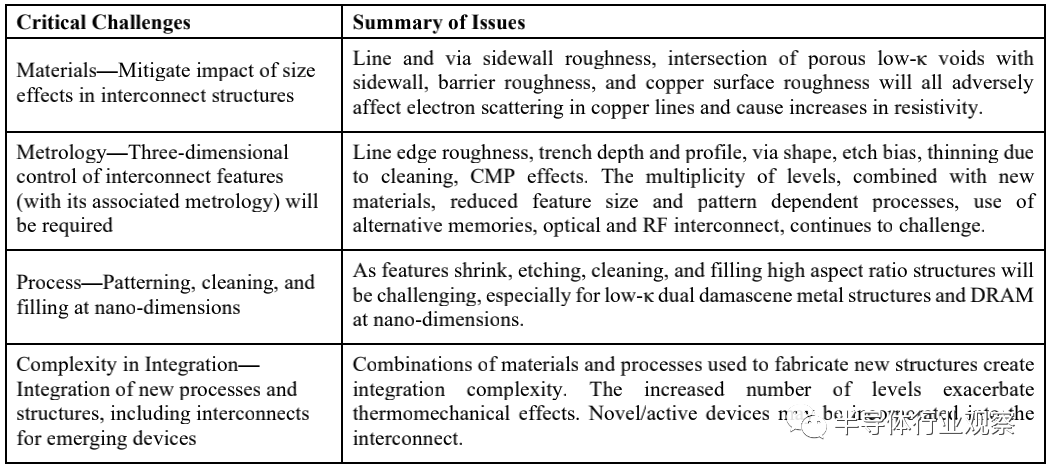

表MM-13互连扩展路线图
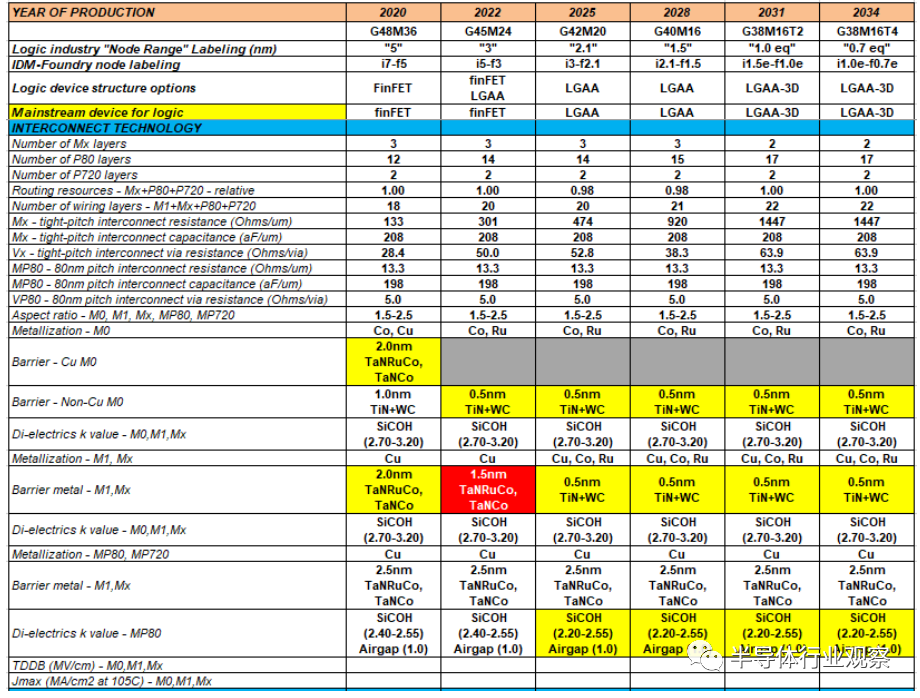
至少到2025年,铜(Cu)预计仍将是互连金属的首选解决方案,而非铜溶液(例如Co和Ru)预计将用于本地互连(M0)。另一方面,由于电迁移的限制,局部互连(middle-of-line:MOL))、M1和Mx水平将使用如钴(Co)这样的非铜方案,特别是对于通孔,因为它有更好的集成窗口来填充狭窄的沟槽,同时它在缩放尺寸上有比铜更低的电阻。
铜布线、线阻挡材料必须防止铜扩散到邻近的介电介质中,但也必须与铜形成合适的、高质量的界面,以限制空位扩散,并实现可接受的电迁移寿命。Ta(N)是一个知名的行业解决方案。Mn(N)在近年来也受到了人们的高度关注。对于新型材料,SAMs(self-assembled monolayers)则是候选材料之一。
同时,3D异构集成也成为大家关注的一个方向。
众所周知,每一代的逻辑节点都需要为其添加新的函数,以保持单价不变(以保持利润率)。由于以下挑战,这变得更加困难:
•留在板上/系统上的协同集成功能更少•每个功能专用的异构核心和每个专用核心所需的专用性能改进需求•封装外存储器与逻辑协同集成成本高,技术与基线CMOS不兼容(可能需要晶圆/芯片级堆叠)
到目前为止,裸片成本的降低是通过栅极间距(gate pitch)、金属间距(metal pitch)和单元高度(cell height)的同步缩放实现的。预计这种情况将持续到2028年。在单元和物理设计中,三维器件(如finFET和横向GAA)和DTCO结构可能会追求单元高度缩放。然而,这种微缩途径预计将面临更大的挑战,因为电气/系统效益的减少,以及SoC水平上面积减少的减少。
因此,有必要寻求3D集成的,例如器件对器件堆叠(device-over-device stacking)、精细间距层转移(fine-pitch layer transfer)和/或monolithic 3D(或sequential integration)。这些追求将保持系统性能和功率增益,同时潜在地保持成本优势,例如在其他地方处理昂贵的非缩放组件,并使用最适合每层功能的技术。
3DVLSI可以在门级或晶体管级布线。3DVLSI提供了堆叠层的可能性,实现了层级别的高密度接触(每平方毫米高达几百万个过孔)。栅极级的分区允许由于导线长度减少而获得IC性能增益,同时通过将nFET堆叠在pFET上(或相反)在晶体管级别进行分区,实现两种类型晶体管的独立优化(定制实现沟道材料/衬底定向/沟道和提高的源极/漏极应变等),同时与平面共集成相比降低工艺复杂度,例如在SiGe pFET上方堆叠III-V nFET。
这些高迁移率晶体管非常适合3DVLSI,因为它们的工艺温度很低。具有高接触密度的3DVLSI还可以实现与高密度3D过孔进行异质共集成的应用,例如用于气体传感的CMOS的NEMS或高度小型化的成像器。集成器件对器件堆叠(例如P器件对N器件)以解耦沟道工程(例如用于PMOS的Ge沟道)以获得更好的性能是一个巨大的发展势头。
为了解决从2D到3DVLSI的过渡,路线图中预测了以下几代:
(1)Die-to-wafer和wafer-to-wafer 堆叠:
方法:细间距(Fine-pitch)介质/混合键合和/或倒装芯片组装
机会:减少系统上的材料清单、异构集成、逻辑上的高带宽和低延迟内存
挑战:设计/架构划分
(2)设备对设备(例如P-over-N堆叠)
方法:顺序集成
机会:减少标准单元和/或位单元的2D占用空间
挑战:最小化互连开销是N&P之间实现低成本的关键
(3)添加逻辑3D SRAM和/或MRAM堆栈(嵌入式/堆叠)
方法:顺序集成和/或晶圆转移
机会:2D区域增益,逻辑和内存之间更好的连接,使系统延迟增益。
挑战:如果使用堆叠方法,则解决较低层互连的热预算,重新审视缓存层次结构和应用程序需求、电源和时钟分布
(4)添加模拟和I/O方法:顺序集成和/或晶圆传输
机遇:给予设计者更多的自由,并允许集成高移动性沟道,将非微缩组件推到另一层,IP复用,可扩展性
挑战:热预算、可靠性要求、电源和时钟分配
(5)True-3D超大规模集成电路:集群功能堆栈
方法:顺序集成和/或晶圆片转移
机会:互补功能,而不是CMOS替代,如神经形态,高带宽内存或纯逻辑应用纳入新的数据流方案有利于3D连接。应用实例包括神经形态结构中的图像识别,宽io传感器接口(例如,DNA测序,分子分析),以及高度并行的内存逻辑计算。
挑战:架构应用程序,在低能量、低频率和高度并行接口可以利用,映射应用到非冯·诺伊曼架构。
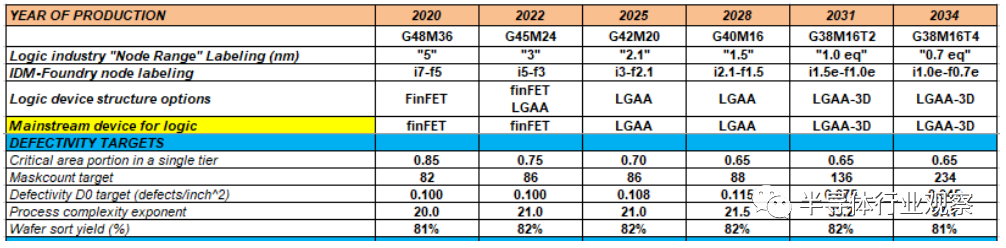
More Moore缩放需要增加金属化层的数量,因此,如果在patterning技术上没有进步,就需要增加mask。预计从193i光刻到EUV的过渡将可能拯救mask。然而,由于对金属化和用于3D集成的FEOL)和MOL集成的重复掩模的需求增加,掩模数量预计将在2031年后上升。这反过来会增加过程的复杂性,从而增加缺陷(D0)需求。2034年所需的D0水平预计将减少2.2倍,以保持80mm2移动裸片(表MM-15)的良率在控制之下。
表MM-15 80mm2裸片的缺陷率(D0)要求。
存储技术也要齐头并进
CMOS逻辑和存储器共同构成了半导体器件生产的主要部分。在探讨完逻辑器件之后,我们需要考虑存储器。
正如大家所熟知,存储器的类型有DRAM和非易失性存储器(NVM)。我们重点放在商品化的、独立的芯片上,因为这些芯片倾向于驱动存储器技术。然而,嵌入式存储芯片预计将遵循与商品存储芯片相同的趋势,通常有一定的时滞。对于DRAM和NVM,都考虑了详细的技术要求和潜在的解决方案。
对于DRAM,主要目标是继续微缩1T-1C单元的占用空间,达到4F2的实际限制。挑战是垂直晶体管结构,high-κ电介质提高电容密度,同时保持低泄漏。从当前的技术看来,DRAM的技术要求随着微缩而变得越来越困难。近年来,DRAM中引入了许多新技术,如193 nm ArF浸没式高钠光刻技术,包括Fin型晶体管在内的改进cell的FET技术,buried word line和cell FET等技术。
由于DRAM存储电容在物理尺寸上变得越来越小,EOT(equivalent oxide thickness)必须急剧下降,以保持足够的存储电容。为了测量EOT,需要具有较高的相对介电常数(κ)的介质材料。因此,我们采用MIM(metal-insulator-metal )电容器,选用high-κ (ZrO2/Al2O/ZrO2)材料。这种材料的发展和改进一直持续到20nm HP和超high-κ (perovskite κ 》 50 ~ 100)材料的释放。此外,high-κ绝缘子的物理厚度应按比例缩小,以适应最小特征尺寸。因此,电容器的三维结构将由圆柱形变为柱状。
另一方面,随着外围CMOS器件的微缩,这些器件形成后的工艺步骤需要低温工艺制程。这对于通常在CMOS器件形成之后构造DRAM cell工艺是一个挑战,因此仅限于低温处理。DRAM外围设备的要求可以放宽Ioff,但需要更多的LSTP(Ion of low standby power )设备。但是,未来需要high-κ金属栅来维持性能。
另一个重要的话题是从6F2迁移到4F2 cell。由于half-pitch缩放变得非常困难,这是不可能维持的成本趋势。保持成本趋势并通过生成增加总比特输出的最有前途的方法是改变单元大小因子(cell size factor)a的缩放(a = [DRAM cell大小]/[DRAMhalf pitch]]2)。目前6F2 (a = 6)是最常见的。例如,垂直cell 晶体管是需要的,但仍然有一些挑战。
总而言之,保持足够的存储电容和足够的cell晶体管性能是需要在未来保持时间特性。为了继续扩大DRAM设备的规模,并获得更大的产品容量,它们的困难指数也在不断增加,。此外,如果成本缩放的效率与引入新技术相比变差,则停止DRAM缩放,采用3D cell堆叠结构,或采用新的DRAM概念。讨论了3D cell堆叠和新的概念DRAM,但没有明确的途径进一步扩展2D DRAM。
在DRAM之外,还有几种存储技术,他们都有一个共同的特征——非易变性。根据应用的不同,要求和挑战也不同,从只需要Kb存储的RFID到芯片中数百Gb的高密度存储。非易失性存储器可分为两大类——闪存(NAND闪存和NOR闪存)和非基于电荷存储的存储器。非易失性内存基本上是普遍存在的,许多应用使用的嵌入式内存通常不需要前沿技术节点。More Moore 非易失性内存表只跟踪内存挑战和领先的独立部件的潜在解决方案。
闪存是基于简单的单晶体管(1T)单元,其中晶体管既是存取(或单元选择)设备又是存储节点。目前闪存服务于99%以上的应用。
当存储的电子数量达到统计极限时,即使可以进一步缩放器件并实现更小的单元,存储阵列中所有器件的阈值电压分布也变得无法控制,逻辑状态也无法预测。因此,不能通过持续扩展基于电荷的设备来无限期地增加存储密度。但是,有效的密度增加可以通过垂直堆叠存储层来继续。
通过完成一个设备层然后再完成另一个设备层的堆叠经济是值得怀疑的。如图MM-12所示,堆叠多层设备后,bit成本开始上升。此外,由于互连增加和复杂处理造成的产量损失,阵列效率的降低可能进一步降低这种3D叠加的bit成本效益。
2007年,业内提出了一种新的制造方法,大大简化了制程步骤。这种方法无需重复处理,只需几步就可以制作出3D堆叠设备,从而为NAND flash提供了一种新的低成本缩放路径。图MM-12说明了一种方法。这种架构最初被称为bitcost -scalable(简称BiCS),它将NAND string 从水平位置转向垂直位置90度。word line(WL)保持在水平面上。如图MM-12所示,这种类型的3D方法比堆叠完整的设备要经济得多,而且成本效益在相当高的层数时不会饱和。
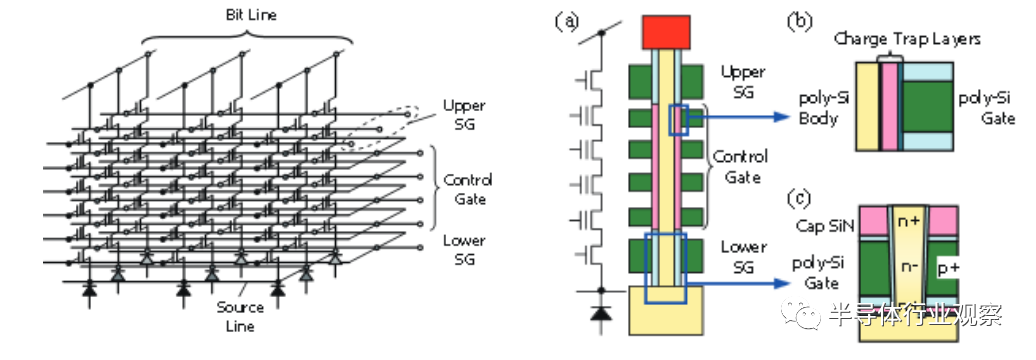
自2007年以来,人们提出了许多基于BiCS概念的架构,其中一些架构,包括一些使用floating gate 代替charge trapping 的存储架构,这些技术在过去的2 - 3年已经进入量产。总的来说,所有3D NAND方法都采用了比传统2D NAND更大的面积占用策略。与最小的2D NAND的~15nm相比,3D NAND的x-和y-尺寸(相当于2D细胞尺寸)在100nm和更高的范围内。更大的“单元尺寸”是通过堆叠大量的存储层来实现具有竞争力的封装密度。
3D NAND的经济效益进一步被其复杂和独特的制造需求所困扰。虽然较大的cell尺寸似乎放宽了细线光刻的要求,但为了实现高数据速率,需要使用较大的page size,而这反过来又转化为细线间距的位线和金属线。因此,即使单元尺寸很大,金属线仍然需要约20nm的半间距,这只能通过193i光刻和双图案实现。深孔的刻蚀困难且缓慢,并且刻蚀吞吐量通常很低。沉积多层电介质和/或多晶硅,以及多层膜和深孔的计量都是一个挑战。这些都转化为对新设备和占地面积的巨大投资,以及对晶圆flow和良率的新挑战。
闪存最终可以堆叠多少层?这似乎是一个未知之数。因为在层的堆叠上似乎没有严格的物理限制。但我们清楚认识到,超过一定的纵横比(也许是100:1?)后,蚀刻停止现象会发生,当反应离子蚀刻过程中的离子由于侧壁上的静电荷弯曲而无法向下传播时,可能会限制一次操作可以蚀刻多少层。
但是,可以通过堆叠更少的层,蚀刻和堆叠更多的层(以更高的成本)来绕过此问题。堆叠许多层可能会产生高应力,从而使晶圆弯曲,尽管需要仔细设计,但这似乎并不是一个无法解决的物理极限。即使在200层(每层约50nm)处,总堆叠高度约为10μm,仍与逻辑IC的10-15个金属层处于相同范围内。这种层的厚度不会显着影响裸片的厚度(到目前为止,最薄的厚度约为40μm)。
然而,在1000层时,总的层厚度可能导致不符合用于在薄封装中堆叠多个裸片(例如16或32)的形状因数的厚裸片。现在闪存已经到了170多层,我们认为未来的256层也有可能。
当堆积更多的层被证明太难时,面积x-y可能最终开始缩小。然而,这种趋势并不能保证。如果孔宽高比是限制,收缩 footprint不会降低比率,因此也不会有帮助。此外,与紧凑的2D NAND相比,更大的单元尺寸似乎至少部分地有助于3D NAND的性能(速度和循环可靠性)更好。x-y缩放是否还能提供这样的性能还不清楚。可能需要新的创新或更强大的新兴存储器来进一步降低 bit成本。
由于2D NAND Flash缩放受存储电荷太少所致的统计波动的限制,因此,一些不基于电荷存储的非常规非易失性存储器(铁电或FeRAM,磁性或MRAM,相变或PCRAM,电阻性或ReRAM)正在被开发并形成通常被称为“新兴”存储器的类别。
即使2D NAND被3D NAND取代(不再受电子数量不足的困扰),基于非电荷的新兴存储器的某些特性(如低压操作或随机存取)对于各种应用也很有吸引力。因此继续发展这些新兴的存储器通常具有两端结构(例如,电阻器或电容器),因此难以兼用作单元选择装置。存储器单元通常以1T-1C,1T-1R或1D-1R的形式组合单独的访问设备。
(1)FeRAM
FeRAM器件通过切换和检测铁电电容器的极化状态来实现非易失性。要读取存储状态,必须跟踪铁电电容器的hysteresis loop,并销毁存储的数据,并且必须在读取后将其写回(破坏性读取,如DRAM)。由于这种“破坏性读取”,寻找铁电和电极材料在延长的工作周期内既能提供足够的极化变化又能提供必要的稳定性是一个挑战。许多铁电材料是CMOS制造材料的常规补充材料所不具备的,并且可以通过常规CMOS工艺条件进行降解。
FeRAM快速,低功耗和低电压,因此适用于RFID,智能卡,ID卡和其他嵌入式应用。但加工难度限制了其广泛采用。最近有人提出了基于HfO2的铁电FET,其铁电作用于改变FET的Vt,从而形成类似闪存的1T电池。如果发展成熟,这种新的记忆可能会成为一种低功耗、非常快的类似闪存的记忆。
(2) MRAM
MRAM(Magnetic RAM)设备采用磁性隧道结(MTJ)作为存储元件。MTJ电池由两种铁磁材料组成,两种铁磁材料之间有一层薄绝缘层,充当隧道屏障。当一层magnetic moment与另一层magnetic moment对齐(或与另一层magnetic moment方向相反)时,电流通过MTJ的有效电阻就会改变。可以通过读取隧穿电流的大小来指示存储的是1还是0。
场开关MRAM可能是最接近理想的“通用存储器”,因为它是非易失性和快速的,并且可以无限循环。因此,它可以作为NVM以及SRAM和DRAM使用。然而,在集成电路中产生磁场既困难又低效。但现场切换MTJ MRAM已经成功制成产品。然而,开关所需的磁场随着存储元件的扩展而增加,而电迁移限制了可用来产生更高H场的电流密度。
因此,预计场开关MTJ MRAM不太可能扩展到超过65nm节点以下。最近的STT有可能找到新的机会。
随着NAND闪存技术的快速发展,以及3D NAND技术的引入有望继续实现等量扩展,STT-MRAM取代NAND的希望似乎遥不可及。然而,它类似sram的性能和比传统6T-SRAM小得多的内存占用已经引起了人们对sram应用的极大兴趣,尤其是在不需要高循环耐力的移动设备上,比如在计算方面。因此,STT-MRAM现在主要被认为不是一个独立的内存,而是一个嵌入式内存,并且不在独立的NVM表中进行跟踪。
STT-MRAM不仅是嵌入式SRAM的替代方案,也是嵌入式Flash (NOR)的替代方案。这对于物联网应用来说可能特别有趣,因为低功耗是最重要的。另一方面,对于其他使用更高内存密度的嵌入式系统应用来说,NOR Flash预计将继续占据主导地位,因为它仍然具有更大的成本效益。此外,闪存也建立了能够忍受PCB板焊接过程(~ 250°C)不失其加载代码,许多新兴的记忆尚未能够证明可行。
此外还有PCRAM、 Crosspoint存储器和ReRAM值得关注,但限于篇幅,我们不一一介绍。
责任编辑:lq
-
新人求一些关于ARM学习的一些经验2015-06-22 4296
-
关于物联网应用的一些预测2020-09-01 1549
-
MOORE型有限状态机的几种设计方法是什么2021-05-07 2010
-
讲一些MEMS相关的普及知识2021-11-17 1665
-
窗户清洗无人机获Gordon E. Moore奖,奖金7.5万美元2018-07-10 1698
-
大数据有哪一些功能模块2020-03-20 1997
-
如何使用Moore状态机设计一序列检测计实验的工程文件免费下载2020-12-04 865
-
More Moore技术的发展路线预测2021-03-08 3552
-
浅读最新的全面More Moore路线图2021-03-22 4364
-
基于Moore型状态机的交通灯控制系统2021-06-17 1167
-
学习linux内核的一些建议2022-05-07 1120
-
有关芯片光刻路线图的一些知识2022-06-30 3742
-
有关芯片光刻路线图的一些知识分享2022-07-10 4791
全部0条评论

快来发表一下你的评论吧 !
