

有什么方法可以减少Quartus II的编译时间吗?
电子说
描述
对于减少Quartus II的编译时间的方法,可从三个角度进行考虑。
第一,从开发所使用的计算机入手,选择合适的CPU、操作系统并进行合理的设置从而提高编译速度;
第二,从Quartus II软件入手,对编译相关的选项进行合理设置,从而提高编译效率;
第三,针对具体的工程,采用增量编译的方法,合理地进行分区和设置,从而减少编译时间。
第一种方法是网友在实际的使用过程中摸索出来的,第二种和第三种方法在Quartus II的开发手册中都有迹可循。
下面进行具体的介绍:
一、开发所使用的计算机方面的考虑
要使用最快的CPU,编译程序拼的就是CPU的速度,而增加RAM没有作用。
另外,切勿使用低电压和超低电压的CPU,要使用标准电压的CPU。
若使用的是Windows操作系统,在任务管理器的进程一栏,列出了CPU当前运行的各个进程,并且给出了内存使用情况。
在任意一个进程上点击右键,可以看到一个“设置优先级”的功能。
查大部分进程的优先级,都在“标准”状态。通过把一个进程的优先级设置为“高于标准”,可以给该进程分配更多的CPU资源,相应地,其运行速度也就上去了。
Quarutus II编译过程中,通常要顺序运行quartus_map、quartus_fit、quartus_asm、quartus_tan四个进程。
其中前两个进程占用了编译时间的95%以上。
手工修改这两个进程的优先级就可以保证Quartus II的编译过程不受干扰,从而实现调整编译速度的目的。
二、Quartus II开发工具方面的考虑
Quartus II的编译过程包括分析综合、布局布线、汇编、时序分析以及生成网表,编译的过程中耗时最多的是分析综合和布局布线,所以想提高编译速度也应该从这点入手。
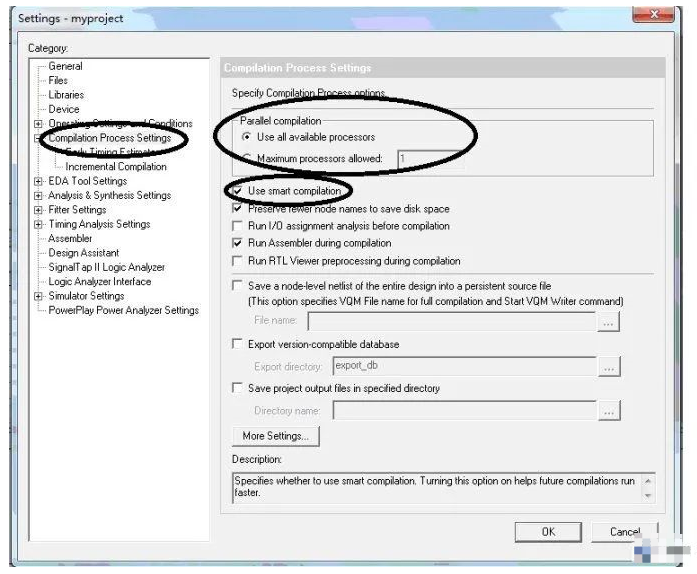
Quartus也有相关的自动增量编译的设置,如图1所示,
首先是可用处理器数目的设置,选择使用所有可用的处理器,这样可以提高整体的速度;
其次是采用Smart Compilation,即智能编译方式,它可以完成的功能是如果设计源文件没有改动,那Quartus II将不再进行分析综合,而直接进入布局布线阶段。
图1
另外,还可用通过编写TCL脚本的方法减少Quartus II综合时间。
使用Quartus II完成建立工程、编写HDL文件、设置以及分配管脚等操作,然后将qsf文件中的内容复制到TCL文件中。
将上述的TCL文件和其他工程文件放入相同的文件夹,运行CMD,使用CD命令将目录更改到设计文件的文件夹,运行命令quartus_sh -t test_top.tcl。
查看CMD窗口的报告,看是否有错误或警告,有则更改HDL设计文件,重新运行命令quartus_sh -t test_top.tcl即可。
还可以在TCL脚本中添加查看TimeQuest的时序报告命令,在Quartus II的帮助文件中可以查到这些命令。
但是这样只减少了Quartus II的综合时间,实际上使用TCL脚本建立工程、约束等比图形化操作Quartus II更省时间。
三、增量编译方面的考虑
增量编译的原理是减少每次编译里设计已经完成的部分,进而不需要再重复编译设计者认为已经完成的工作。
具体方法为,设计者手动得将整个工程分成N个子模块(此处指的是逻辑模块),并设定各个模块的状态(已经完成了,不需要更改了,编译时就采用上一次的结果),这样编译器在分析综合的时候便可以对那些不需修改的部分直接采用上次的结果。
布局布线的时候也是一样的,如果该子模块不需要更改了就采用上次的结果,如需更改再重新进行布局布线,只不过布局布线的过程要相比分析综合复杂一些。
而上面提到的将整个工程手动分成N个模块,我们就要用到Quartus II提供的两个高级工具——Design Partitions和LogicLock Regions。
增量编译技术的另一主要优点是保持性能不变。通过只对设计中的特定分区进行编译,其他分区的时序性能保持不变。
渐进式流程适用的设计环境:当改变源文件时,缩短编译时间;在加入其他逻辑前,优化设计部分结果;采用在系统逻辑分析器进行渐进式调试;实现基于团队的设计环境和自下而上的设计流程。
增量编译流程要比固定式编译需要进行更多的前端规划。
例如,必须构造源代码或者设计层次以保证逻辑能够正确分组,进行优化。
比起在设计后期重新构造代码,更容易在设计早期实现正确的逻辑分组。
设计分区后,设计人员需要将每个分区分配到器件中的某个物理位置,以建立设计平面规划。
不好的分区或者平面规划分配会劣化设计面积利用率和性能,很难达到时序逼近。
和固定式编译相比,增量编译通常需要设计人员严格按照良好的设计习惯进行设计。
规划设计时,设计人员应记住每个分区的大小和范围,随着设计的发展,知道设计的不同部分会怎样变化。
经常变化的逻辑应和设计中的固定部分分开。
设计层次应该和一个分区中的关键时序逻辑分开,最好和寄存端口边界分开,这样,软件能够高效的优化每个独立分区。
为进行增量编译需要在Hierarchy tab of the Project Navigator中对Design partitions进行定义,在定义之前需要运行Analysis & Elaboration生成design hierarchy,定义之后会在实体名字上面出现一个 标志,如图2所示。
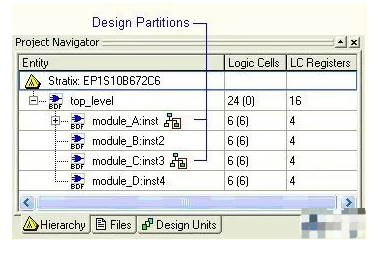
通过设置可使Design partitions在增量编译的过程中被保留或重新编译。
使用渐进式编译时,设计层次被映射到设计分区中,在编译过程中单独处理它,以实现渐进式编译功能。
设计中的每个实体或者实例不会被自动考虑为设计分区;设计人员必须将顶层以下的一个或者多个设计层次指定为渐进式编译设计分区。
当分区被声明后,该分区中的每个层次成为同一分区的组成部分。
当为已有分区中的层次建立新分区时,新的低层分区中的逻辑不再是上层分区的组成部分。
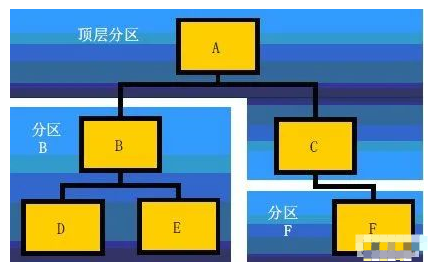
图3 所示是一个设计层次实例,其中,实例B 和F 被指定为设计分区。
分区B 包括子实例D 和E。
“顶层”默认分区含有顶层模块A 以及实例C,原因是它没有被分配到任何其他分区中。
责任编辑:lq6
- 相关推荐
- 热点推荐
- 处理器
- cpu
- 操作系统
- QUARTUS II
-
Quartus II 12.1破解2012-11-26 28533
-
quartus ii 编译问题 !!2013-07-13 10314
-
quartus ii使用教程,中文教程2009-04-21 6930
-
ALTERA QUARTUS II软件使用2009-10-27 813
-
Quartus II 中文教程2010-03-11 1654
-
Quartus II软件12.0的新功能详解2012-11-06 21245
-
Altera Quartus II软件v13.1编译时间缩短70%2013-11-06 3387
-
Quartus II使用Verilog设计介绍2015-11-24 1366
-
Quartus II中文用户教程2016-07-29 1159
-
Altera交付14.0版Quartus II软件,其编译时间业界最快2018-02-11 5993
-
一文详解Quartus II自动添加管脚分配的方法2018-05-16 53434
-
Altera推出Quartus II v13.0,支持实现世界上最快的FPGA设计2018-09-25 1683
-
EDA教程之Quartus II原理图输入方法的详细资料免费下载2018-10-18 1224
-
使用Quartus II编程CPLD和FPGA设备的教程说明2020-09-17 2367
-
Quartus II 13.0软件下载2022-12-21 1685
全部0条评论

快来发表一下你的评论吧 !
