

高速流水线浮点加法器的FPGA实现
模拟技术
描述
高速流水线浮点加法器的FPGA实现
0 引言
现代信号处理技术通常都需要进行大量高速浮点运算。由于浮点数系统操作比较复杂,需要专用硬件来完成相关的操作(在浮点运算中的浮点加法运算几乎占到全部运算操作的一半以上),所以,浮点加法器是现代信号处理系统中最重要的部件之一。FPGA是当前数字电路研究开发的一种重要实现形式,它与全定制ASIC电路相比,具有开发周期短、成本低等优点。但多数FPGA不支持浮点运算,这使FPGA在数值计算、数据分析和信号处理等方面受到了限制,由于FPGA中关于浮点数的运算只能自行设计,因此,研究浮点加法运算的FPGA实现方法很有必要。
1 IEEE 754单精度浮点数标准
浮点数可以在更大的动态范围内提供更高的精度,通常,当定点数受其精度和动态范围所限不能胜任时,浮点数标准则能够提供良好的解决方案。
IEEE协会制定的二进制浮点数标准的基本格式是32位宽(单精度)和64位宽(双精度),本文采用单精度格式。图1所示是IEEE754单精度浮点数格式。图中,用于单精度的32位二进制数可分为三个独立的部分,其中第0位到22位构成尾数,第23位到第30位构成指数,第31位是符号位。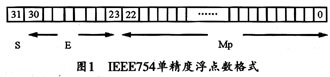
实际上,上述格式的单精度浮点数的数值可表示为: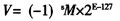
上式中,当其为正数时,S为0;当其为负数时,S为1;(-1)s表示符号。指数E是ON255的变量,E减127可使指数在2-127到2128变化。尾数采用科学计算法表示:M=1.m22m21m20……m0。m22,m21,…,m0,mi为Mp的各位,设计时应注意尾数中隐含的整数部分1。0是一个特殊的数,0的指数位和尾数位均为0,符号位可以是1,也可以是0。
2电路的流水线结构
一般情况下,结构化设计是电路设计中最重要的设计方法之一,采用结构化设计方法可以将一个复杂的电路分割为独立的功能子模块,然后按一定的原则将各子模块组合成完整的电路,这几乎是电路设计的通用模式。这种设计方法便于设计人员分工合作、实现设计和功能测试,缩短上市时间、升级和二次开发,因而具有其它方法无法比拟的优势。
结构化设计基本上可归结为两种方法:流水线(pipeline)和握手原则。其中握手原则适用于各功能子模块内部运算比较复杂、数据运算时延(latency)不确定的设计。由于数据运算时延不确定,所以,各子模块间的时序配合必须通过握手信号的交互才能完成。握手原则设计的电路一般采用复杂的有限状态机(FSM)作为控制单元,工程设计难度大,故在设计时应慎重使用。流水线法适用于各功能子模块内部运算简单整齐、数据运算时延确定的设计。由于数据运算时延比较确定,各前后级功能子模块不需要任何交互信号就能完成时序配合,故可方便地实现数据的串行流水运算。流水线控制比较简单,一般不需要设计专门的有限状态机,而且工程设计容易,设计时可优先选用。
3 工程的FPGA实现
3.1开发环境和器件选择
本工程开发可在FPGA集成开发环境QuartusII 8.0 spl中完成。OuartusⅡ是世界著名PLD设计生产厂商——Altera公司的综合性PLD开发软件,内嵌综合器和仿真器,并有可与第三方工具协作的灵活接口,可以完成从设计输入到硬件配置的完整PLD设计流程,而且运行速度快,界面统一,功能集中,易学易用。
本设计中的器件选用Stratix IIEP2S15F484C3。Stratix II是Altera公司的高性能FPGA Stratix系列的第二代产品,具有非常高的内核性能,在存储能力、架构效率、低功耗和面市及时等方面均有优势。
本系统的顶层框图如图2所示。为了显示清楚,图2被分成两个部分显示。本工程采用异步置位的同步电路设计方法,其中clk、reset、enab分别为系统时钟、系统异步置位、系统使能信号。din_a、din_b分别为两个输入的单精度浮点数,data_out则是符合IEEE 754标准的两输入浮点数之和。
3.2浮点加法运算的实现
浮点加法运算可总结为比较、移位、相加、规范化等四个步骤,分别对应于compare、shift、sum、normalize四个模块。
(1)compare模块
本模块主要完成两输入浮点数的比较,若din_a、din_b为两个输入单精度浮点数,则在一个时钟周期内完成的运算结果如下:
◇大数指数b_exp这里的大数指绝对值的比较;
◇两浮点数的指数差sube,正数;
◇大数尾数b_ma;
◇小数尾数s_ma,该尾数已加入隐含1;
◇和符号c_sgn,为确定输出结果的符号;
◇加减选择add_sub,两输入同符号时为0(相加)、异符号时为1(相减),sum模块中使用实现加减选择。
(2)shift模块
shift模块的作用主要是根据两个输入浮点数的指数差来执行小数尾数(已加入隐含1)向右移动相应的位数,以将输入的两个浮点数指数调整为相同的数(同大数),若b_exp、sube、b_ma、s_ma、c_sgn、add_sub为输入信号(其含义见compare模块),则可输出如下运算结果(在一个时钟周期内完成):
◇大数指数(sft_bexp),将b_exp信号用寄存器延迟一个周期,以实现时序同步;
◇小数尾数(sft_sma),已完成向右移动相应的sube位;
◇大数尾数(sft_bma),将b_ma信号用寄存器延迟一个周期,以实现时序同步;
◇和符号(sft_csgn),将c_sgn信号用寄存器延迟一个周期,以实现时序同步;
◇加减选择(sft_addsub),将add_sub信号用寄存器延迟一个周期,以实现时序同步;
(3)sum模块
本模块可根据加减选择(sft_addsub(信号完成两输入浮点数尾数(已加入隐含1)的加减,若sft_bexp、sft_sma、sft_bma、sft_csgn、sft_addsub为输入信号(其含义见shift模块),则可输出如下运算结果(在一个时钟周期内完成):
◇大数指数(sum_bexp),将sft_bexp信号用寄存器延迟一个周期,以实现时序同步;
◇尾数和(sum_ma),为大数尾数与移位后小数尾数的和,差(两尾数已加入隐含1);
◇和符号(sum_csgn),将sft_csgn信号用寄存器延迟一个周期,以实现时序同步;
(4)normalize模块
normalize模块的作用主要是将前三个模块的运算结果规范为IEEE 754单精度浮点数标准,若sum_bexp、sum_ma、sum_csgn为输入信号(其含义见sum模块),则其输出的运算结果(在一个时钟周期内完成)只有一个和输出(data_out),也就是符合IEEE754浮点数标准的两个输入浮点数的和。
4系统综合与仿真
由于本工程是由compare、shift、sum、normalize四个模块组成的,而这四个模块通过串行方式进行连接,每个模块的操作都在一个时钟周期内完成,因此,整个浮点数加法运算可在四个时钟周期内完成。这使得工程不仅有确定的数据运算时延(latency),便于流水线实现,而且方便占用的时钟周期尽可能减少,从而极大地提高了运算的实时性。
4.1工程综合结果
经过Quartus II综合可知,本设计使用的StratixⅡEP2S15F484C3芯片共使用了641个ALUT(高级查找表)、188个寄存器、0位内存和可达到80 MHz的时钟频率,因此可证明,本系统利用合理的资源实现了高速浮点数加法运算。
4.2工程仿真结果
本工程仿真可使用Quartus II 8.0内嵌式仿真工具来编写Matlab程序,以生成大量随机单精度浮点数(以便于提高仿真代码覆盖率,提高仿真的精确度),然后计算它们相加的结果,并以文本形式存放在磁盘文件中。编写Matlab程序可产生作为仿真输入的*.vec文件,然后通过时序仿真后生成*.tbl文件,再编写Matlab程序提取其中有用的结果数据,并与先前磁盘文件中的结果相比较,以验证设计的正确性。
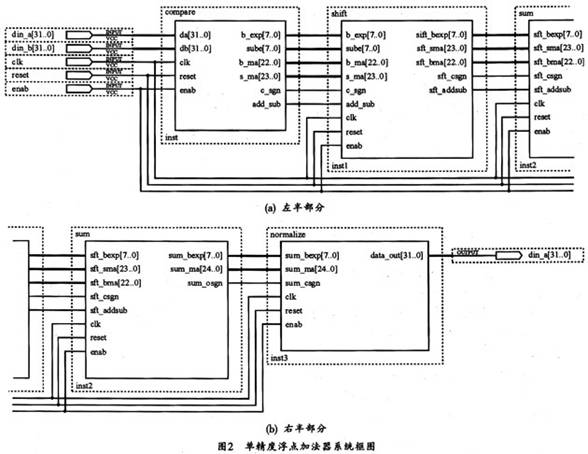
图3所示是其仿真的波形图。
从图3可以看出表1所列的各种运算关系。表2所列为其实际的测试数据。
表中“A+B实数表示(M)”指Matlab计算的结果;“误差”指浮点处理器计算结果与Matlab计算结果之差。
综上所述,本工程设计的浮点加法器所得到的运算结果与Matlab结果的误差在10-7左右,可见其精度完全能够符合要求。
5 结束语
本工程设计完全符合IP核设计的规范流程,而且完成了Verilog HDL建模、功能仿真、综合、时序仿真等IP核设计的整个过程,电路功能正确。实际上,本系统在布局布线后,其系统的最高时钟频率可达80MHz。虽然使用浮点数会导致舍入误差,但这种误差很小,可以忽略。实践证明,本工程利用流水线结构,方便地实现了高速、连续、大数据量浮点数的加法运算,而且设计结构合理,性能优异,可以应用在高速信号处理系统中。
-
求解原理图和PCB,流水线大神帮帮忙2014-12-18 2625
-
Verilog流水线加法器always块中应该采用阻塞赋值(=),还是非阻塞赋值(<=)?2016-09-09 29180
-
如何利用FPGA实现高速流水线浮点加法器研究?2019-08-15 2148
-
FPGA中的流水线设计2020-10-26 3310
-
请问一下高速流水线浮点加法器的FPGA怎么实现?2021-05-07 2129
-
加法器,加法器是什么意思2010-03-08 5996
-
基于FPGA的高速流水线浮点乘法器设计与实现2012-02-29 4344
-
FPU加法器的设计与实现2012-07-06 1308
-
基于Skewtolerant Domino的新型高速加法器2017-01-22 755
-
流水线状态机20进制,101序列检测,8位加法器流水线的程序2017-05-24 1597
-
基于流水线加法器的数字相关器设计[图]2018-01-18 3176
-
流水线设计的思想介绍与设计实例2019-02-04 9157
-
使用流水线结构设计加法器的方案和工程文件免费下载2020-09-07 1147
-
加法器的原理及采用加法器的原因2023-06-09 6979
-
基于FPGA实现Mem加法器2023-10-17 1649
全部0条评论

快来发表一下你的评论吧 !
