

恩智浦i.MX 8M Plus帮助实现并行机器学习推理网络
描述
当下,大多数研究与论文都侧重于针对特定任务的机器学习(ML)模型,分析在执行该模型时达到的精度以及处理架构的效率,但在现场部署实际解决方案时,还有其他诸多需要考虑的因素。恩智浦i.MX 8M Plus应用处理器中集成的,能够提供高达2.3 TOPS加速性能的专用神经网络处理单元(NPU),为用户应用的开发提供更好的选择和灵活性,帮助他们使用机器学习和视觉技术来实现广泛的应用。
Arcturus Networks就开发了一种用于监控银行ATM机网点情况的应用,充分体现了在网络边缘的设备安全相关应用中需要的多功能和技术。恩智浦也非常荣幸邀请到我们的伙伴,Arcturus创新总监David Steele,分享关于该项目及其开发方法的详细信息。
Arcturus团队最近与某家银行合作开展了一个项目,帮助他们监控ATM机网点。该银行希望防止ATM机区域出现拥挤现象,并限制佩戴面罩或头盔者进入。这一应用就是一个很好的边缘人工智能示例,因为网络边缘既是数据源所在的位置,也是需要执行本地操作的位置。同时它也带来了一些非常有趣的挑战。
设计需求与挑战
对采样数据的分析表明,在狭小封闭的ATM空间内,摄像头通常呈俯拍角度,由于它明显呈现自上而下的拍摄角度(图1),会导致检测可信度降低。
另外,该应用还需要区分佩戴和未佩戴面罩的人。这并非只是改进现有类别的检测,使其包括佩戴面罩者那么简单。由于实际操作中头盔或其他面部遮盖物也被视为个人防护装备(PPE),因而需要创建多个新的检测类别(图2)。
此外,该银行还希望扩展分析功能,以便检测可疑行为,包括来回游荡等。
为了提高检测可信度,在网络中增加新检测类别,我们需要使用特定域数据,并进行模型微调或重复的训练。这个过程是从边缘离线完成的,其结果将与正确标记数据集进行对照。此过程迭代进行,但通过使用特定域的数据,其结果可提供非常关键的模型改进。
模型经过训练、微调和验证之后,可将其转移至基于集成专用2.3 TOPS NPU的i.MX 8M Plus应用处理器作主控的设备。另外为了高效利用NPU,模型必须从本地32位浮点(FP32)精度转换为8位整数(INT8)精度。这个量化过程可能会导致一些精度损失,可能需要多次验证。
我们需要通过运行时推理引擎将模型加载到i.MX 8M Plus。恩智浦eIQ机器学习(ML)软件开发环境支持经过移植和验证的Arm NN和TensorFlow Lite推理引擎。不过,边缘运行库版本并不支持所有类型网络需要的所有层——比较新的模型和不太流行的模型通常没有得到广泛支持。
为帮助减少训练和部署边缘人工智能系统所需的时间,Arcturus提供了一个目录,其中包含使用不同精度的预构建模型。这些模型经过预先验证,可支持所有主要边缘运行库;包括支持在CPU、GPU、NPU上运行的Arm NN、TensorFlow Lite和TensorRT。他们还提供工具,用于训练或微调模型,以及数据集管理、图像抓取和增强。与运行相同模型的其他公开发布的系统相比,通过将优化运行库、量化模型和NPU硬件组合在一起,可以提供40倍性能提升(图3)。
提高分析精度
一旦模型在边缘高效运行,就需要具备对输出进行分析的能力。如果对静态图像执行分析,二进制分类可以确定是否存在PPE。如果对实时视频执行分析,可能要困难一点,因为局部遮挡和身体姿势将导致检测结果的差异。为了提高精度,我们需要对多个帧进行更智能的判定。为了达到这个目标,我们需要对每个人进行跟踪,以获得更大的样本。运动模型跟踪是一种简单轻量级方法,适合完成此任务,但它依赖于连续检测。如果存在遮挡和障碍物,或者人员离开并重新进入视场,都会导致跟踪丢失。因此,要检测来回游荡的人员,就需要更强大的跟踪方法,能够进行重新识别,而不受时间或空间的影响。
重新识别是通过使用生成视觉外观嵌入的网络来实现的。这个工作流程要求目标识别与分类网络将定位、帧和分类信息传递到嵌入网络(图4)。网络和数据流之间的同步至关重要,因为任何时间偏差都可能导致推理错误。将输出与运动模型数据进行比较,确定身份分配。嵌入可在多个摄像头系统之间共享,它们可用于存档搜索,以创建活动观察列表,甚至通过应用集群技术,进一步进行后期处理。
多目标追踪
要将视觉外观嵌入添加到运动模型跟踪,就需要对每个检测目标进行处理。因此,更多的目标意味着需要更多的处理。在我们的应用中,人数本身受到了物理空间的限制。但是,在视场较大的情况下,这可能带来严重的瓶颈。
为了解决这个问题,Arcturus开发了视觉管道架构,其中不同的处理阶段由节点表示,例如推理、算法、数据或外部服务。每个节点的作用类似于一项微服务,通过紧密同步的序列化数据流来互连。这些节点共同构成了完整的视觉管道,从图像采集一直到本地操作。对于基本应用,各个管道节点可在同一物理硬件上运行。比较复杂的管道的节点可能分布在各个硬件上,例如在CPU、GPU、NPU上,甚至在云端。各个管道在运行时进行协调,使其具有出色的灵活性和可扩展性,有助于确保边缘计算投资能够经受未来考验。每个节点都严谨地模块化,从而可以轻松替换系统的某一部分,例如,即便模型时序发生变化,也可以在不影响系统其余部分的情况下更新推理模型。
这种管道架构是Arcturus Brinq Edge Creator SDK的核心,使我们能够扩展人工智能的性能,进一步讲单一应用处理器的处理能力发挥到极致。例如,在一个基于i.MX 8M Plus设备执行检测的同时,让第二个基于i.MX 8M Plus设备生成嵌入。这些器件可以使用网络结构来轻松进行互连,每个处理器使用两个专用以太网MAC中的一个MAC。如果更进一步,可以将这种软件与Arcturus Atlas硬件平台结合使用,该硬件平台使用包括i.MX 8M Plus的多种硬件配置,可扩展到187fps(图5).
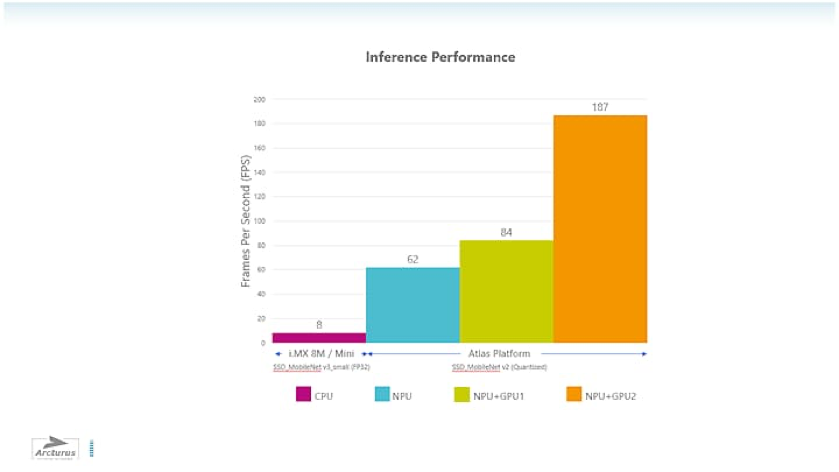
图5 :Arcturus Atlas硬件平台性能(使用具有加速选项的恩智浦i.MX 8M Plus)
总结一下,进行应用整体设计时,应该考虑到您的需求可能会发生变化。基于类别的检测可能需要利用算法或其他网络来增强。要让您的边缘人工智能经受未来考验,可以基于可扩展管道架构(例如Brinq Edge Creator SDK)进行构建,并且充分利用可扩展的硬件性能,例如采用恩智浦i.MX 8M Plus处理器和NPU加速器的Atlas平台。
原文标题:实现并行机器学习推理网络:i.MX 8M Plus原来可以这么用!
文章出处:【微信公众号:NXP客栈】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
如何下载 i.MX 8M Plus SDK?2026-04-16 159
-
请问qemu 可以模拟 i.MX 8M Plus 吗?2026-03-05 348
-
恩智浦FRDM i.MX 8M Plus开发板上架2025-08-16 2604
-
i.MX 8M Plus中的ISP图像信号处理模块特性概述2024-08-02 2860
-
NXP开发板有哪些?基于NXP i.MX 6UL、i.MX 8M Mini、i.MX 8M Plus、LS1028A的开发板概述2023-09-15 5109
-
如何在i.MX 8M Plus上使用多个显示器?2023-03-16 537
-
i.MX 8M Plus的工业特性2022-08-03 2726
-
如何利用i.MX 8M Plus处理器开创AI应用2022-02-21 5468
-
i.MX 8M Plus的相关资料推荐2022-02-07 1296
-
i.MX 8M Plus开发板拥有哪些优势2021-09-24 3370
-
搭载恩智浦i.MX 8M Plus处理器的核心板,它来了!2021-08-31 1172
-
恩智浦正式推出新款产品i.MX 8M Nano UltraLite处理器2021-06-16 3532
-
恩智浦i.MX 8M Plus应用处理器满足开发需求2021-05-18 4177
全部0条评论

快来发表一下你的评论吧 !
