

一种为小样本文本分类设计的结合数据增强的元学习框架
描述
01
研究背景及动机
近些年,元学习已经成为解决小样本问题的主流技术,并且取得不错的成果。然而,由于现有的元学习方法大多数集中在图像分类上,而对文本分类上的关注比较少。与图像不同,同一类别中文本具有多种表达方式,这使得当前元学习方法的性能更容易受到每个类别样本数(即shot的数量)的影响。因此,现有的元学习方法很难在小样本文本分类上取得令人满意的结果。
为了解决这个问题,我们在元学习中引入了数据增强,它带来的好处是我们可以产生增强样本以增加新类别的样本数量,并使训练样本多样化。然而,这带来了一个新的挑战,如何在小样本的情况下产生置信度高的样本?
为此,我们提出了一种新颖的数据增强方法,称为Ball generator,图1给出了一个简单的例子。首先,我们计算支持集的最小包围球,并在该球中合成样本。我们认为该球中的样本具有较高的置信度,因为所有支持集样本都包含在该球中,并且它们与球心的最远距离最小。
其次,为避免合成样本偏差的影响,我们引入了变换模块,以使合成样本靠近自己的球心,并远离其他球心。此外,我们还提出了一个新的基于数据增强的元学习框架(MEta-Learning with Data Augmentation,MEDA),以联合训练ball generator和meta-learner,使二者协同进化。与普通元学习相比,通过增加新类别的样本数量,有效地提高了meta-learning在小样本情况下的泛化能力。
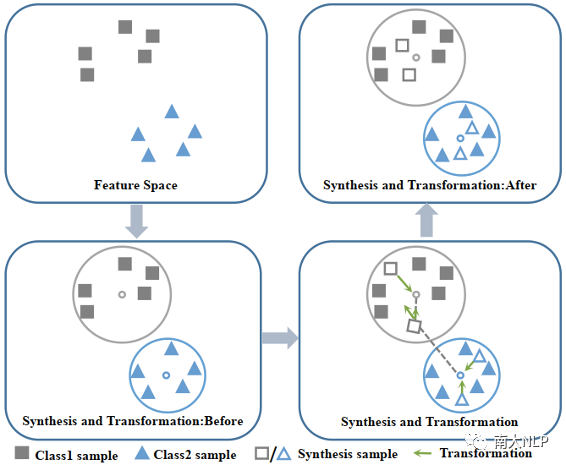
图1:Ball generator示例
02
MEDA
MEDA的框架如图2所示。它是两模块组成:一个是ball generator模块,它负责利用支持集生成增强支持集,并得到扩展支持集。另一个模块是meta-learner,它在给定了扩展支持集的条件下计算每个查询实例在类别上的概率分布,表示为。而不同的meta-learner的区别在于如何实现。这里我们选择原型网络和关系网络作为MEDA的meta-learner。
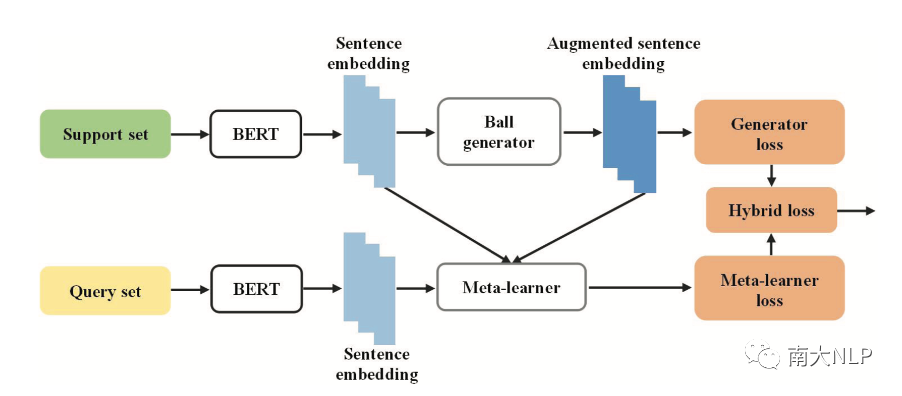
图2: MEDA
其中,ball generator是一种特征空间数据增强方法。它的核心思想是在特征空间中进行样本的合成,并对合成的样本进行调整。因此,整个ball generator由两个子模块组成:合成模块和变换模块。
合成模块利用空间采样算法获得相应的合成样本。具体是将采样空间限制为支持集的最小包围球,这里是球心,是半径。然后,通过如下公式计算得到合成样本:
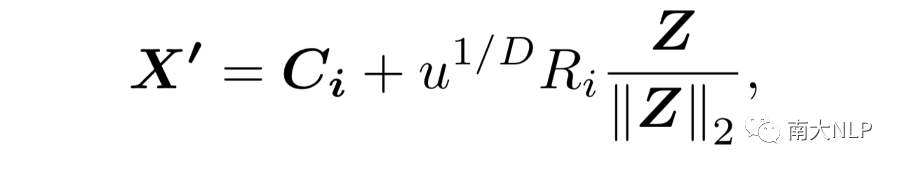
这里,和。
变换模块,它是为了进一步避免合成样本偏差的影响,在特征空间中对合成的样本进行变换操作,使合成样本更接近自己类别的球心,而远离其他球心。因此,我们将变换操作写成函数,该函数以合成样本作为输入,产生一个增强样本作为输出。
03
实验
本文的实验是在SNIPS和ARSC数据集上进行的。我们将MEDA与三组baseline模型进行了比较。第一组是数据增强的模型;第二组是传统的元学习模型;第三组是最新的小样本文本分类的SOTA模型。实验结果如表1和2所示。
表1:SNIPS实验结果
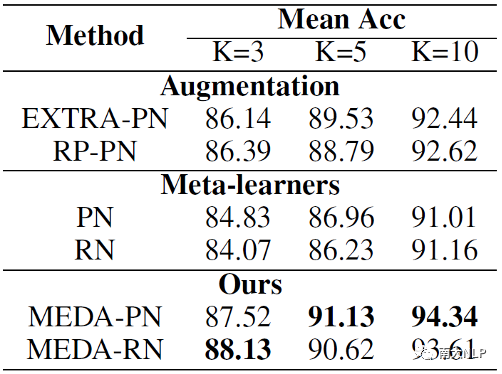
表2: ARSC实验结果
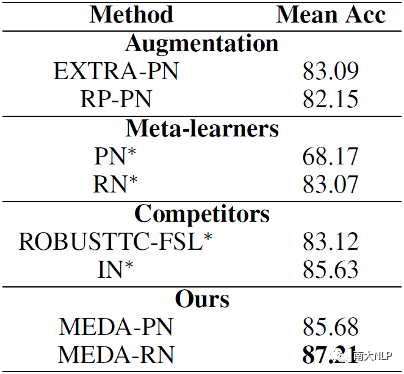
从实验结果上来看,由于通过数据增强获得更多的训练样本,使得MEDA在两个数据集上都取得一致且显著的提升。
为了更进一步说明模型的shot数量对模型的影响,我们设计相应的实验。如图3所示,我们可以观察到MEDA在所有设置中都取得了最好的表现。特别地,MEDA的准确率随着shot数量的减少而增加(间距变大),这表明当shot数相对较小时,模型效果的提升更明显。
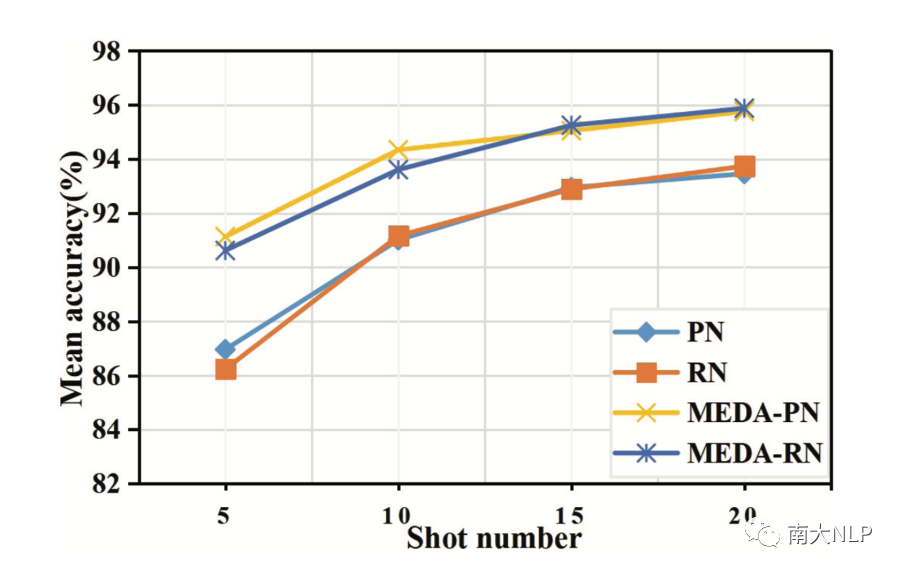
图3: 不同shot数量对模型准确率的影响
此外,我们还研究了模型的准确性如何随着增强样本数量的变化而变化。我们画出不同模型在SNIPS数据集上的准确率变化情况。如图4所示:
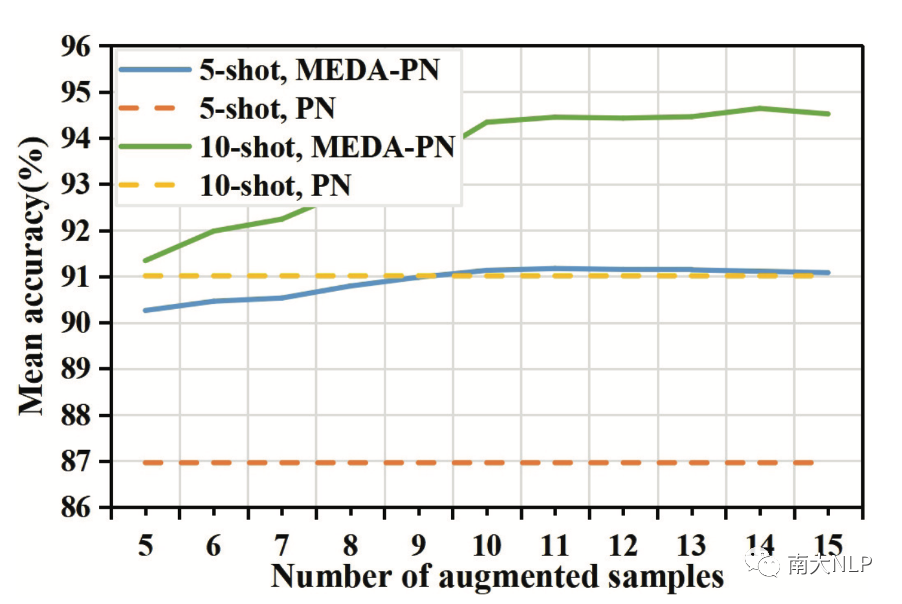
图4: 不同模型的平均准确率随增强样本数量的变化而变化
可以看到,随着增强样本数量的增加,模型的准确率有所提高。同时,我们比较5-shot和10-shot的实验设置,我们发现通过模型增强5个样本与使用5个真实样本的效果几乎相同,这意味着我们的MEDA不是简单地复制样本,而是为模型生成有意义的样本。
04
—
总结
在本文中,我们提出了一种新颖的数据增强方法,称为ball generator,以增加新类别的样本数量。此外,我们还提出了一个新的框架MEDA,该框架联合优化了ball generator和meta-learner,从而使ball generator可以学习生成最适合meta-learner的增强样本。更多的细节、结果以及分析请参考原论文。
编辑:jq
-
NLPIR平台在文本分类方面的技术解析2019-11-18 2418
-
基于文章标题信息的汉语自动文本分类2009-04-13 1400
-
高维小样本分类问题中特征选择研究综述2017-11-27 930
-
一些解决文本分类问题的机器学习最佳实践2018-07-31 8084
-
如何使用Spark计算框架进行分布式文本分类方法的研究2018-12-18 1639
-
深度学习:小样本学习下的多标签分类问题初探2021-01-07 8606
-
一种单独适配于NER的数据增强方法2021-01-18 4008
-
一种针对小样本学习的双路特征聚合网络2021-03-22 980
-
一种基于BERT模型的社交电商文本分类算法2021-04-13 1355
-
融合文本分类和摘要的多任务学习摘要模型2021-04-27 1621
-
胶囊网络在小样本做文本分类中的应用(下)2021-09-27 3154
-
基于LSTM的表示学习-文本分类模型2021-06-15 1305
-
一种基于伪标签半监督学习的小样本调制识别算法2022-02-10 1537
-
基于深度学习的小样本墙壁缺陷目标检测及分类2022-04-24 1062
-
PyTorch文本分类任务的基本流程2023-02-22 2121
全部0条评论

快来发表一下你的评论吧 !
