

简述C语言知识总结:宏,枚举,结构体,共用体
电子说
描述
1、define宏定义以#号开头的都是编译预处理指令,它们不是C语言的成分,但是C程序离不开它们,#define用来定义一个宏,程序在预处理阶段将用define定义的来内容进行了替换。因此在程序运行时,常量表中并没有用define定义的常量,系统不为它分配内存。
define定义的常量,预处理时只是直接进行了替换,它用来将一个标识符定义为一个字符串,该标识符被称为宏名,被定义的字符串称为替换文本。因此在编译时它不对宏的定义进行检查,作用域不影响对常量的访问 。它的常量值只能是字符串或数字。
该命令有两种格式:一种是简单的常量宏定义, 另一种是带参数的宏定义。
不带参数的宏:#define《 名字 》《 值 》
要注意,没有结尾的分号,因为不是C的语句,名字必须是一个单词,值可以是各种东西,宏定义是用宏名来表示一个字符串,在宏展开时又以该字符串取代宏名,这只是一种简单的代换,字符串中可以含任何字符,可以是常数,也可以是表达式,预处理程序对它不作任何检查。如有错误,只能在编译已被宏展开后的源程序时发现。
注意。宏定义不是说明或语句,在行末不必加分号,如加上分号则连分号也一起置换。宏定义其作用域为宏定义命令起到源程序结束。如要终止其作用域可使用#undef命令
带参数的宏 :
像函数的宏,一般的定义形式 :带参宏定义的一般形式为:「#define 宏名」(形参表)字符串,也是没有结尾的分号,可以带多个参数 ,#define NB(a,b)((a)》(b)?(b):(a)), 也可以组合(嵌套)使用其他宏,注意 带参数宏的原则 一切都要有括号,参数出现的每个地方都要有括号。带参数的宏在大型的程序的代码中使用非常普遍,在#和##这两个运算符的帮助下可以很复杂,如“产生函数”,但是有些宏会被inline函数代替(C++的函数)
使用宏好处:
“提高运行效”。定义的标识符不占内存,只是一个临时的符号,预编译后这个符号就不存在了。在简单的程序使用带参数的宏定义可完成函数调用的功能,又能减少系统开销,提高运行效率。正如C语言中所讲,函数的使用可以使程序更加模块化,便于组织,而且可重复利用。
“方便程序的修改”。使用宏定义可以用宏代替一个在程序中经常使用的常量。注意,是“经常”使用的。这样,当需要改变这个常量的值时,就不需要对整个程序一个一个进行修改,只需修改宏定义中的常量即可。且当常量比较长时,使用宏就可以用较短的有意义的标识符来代替它,这样编程的时候就会更方便,不容易出错。因此,宏定义的优点就是方便和易于维护。
//例子:/求球的体积#include《stdio.h》#include《math.h》//对于半径为 r 的球,其体积的计算公式为 V =4/3*Π*r^3 //这里取Π为3.14//这里给定r的值,求V#define PI 3.14int main(void) {
double r;
scanf(“%lf”, &r);
double sum = 0;
sum = (4.0 / 3.0) * PI*pow(r, 3);//这里用PI替换掉了 3.14
printf(“%f.2”, sum);
}
#include《stdio.h》//合例子:输入数字查看是星期几int main(void) {
enum week {Mon = 1, Tue, Wed, Thu, Fri, Sat, Sun}today;
//在这里我们给Mon赋值了一,后面Tue以后的都相应加一赋值
scanf(“%d”, &today);
switch (today) {
case Mon: puts(“Monday”); break;
case Tue: puts(“Tuesday”); break;
case Wed: puts(“Wednesday”); break;
case Thu: puts(“Thursday”); break;
case Fri: puts(“Friday”); break;
case Sat: puts(“Saturday”); break;
case Sun: puts(“Sunday”); break;
default: puts(“no day”);
}
return 0;
}
2、enum枚举枚举型是一个集合,集合中的元素(枚举成员)是一些命名的整型常量,元素之间用逗号,隔开。它是一种用户定义的数据类型,它用关键字enum以如下语法来声明,:enum 枚举类型名字,{名字0,。。。,名字n};第一个枚举成员的默认值为整型的0,后续枚举成员的值在前一个成员上加1 (当然这个是可以自定义成员值的)
枚举类型名字通常并不真的使用,要用的是在它大括号里边的名字,因为它们就是常量符号,它们的类型是int,值则是依次从零到n,如 enum week { Monday,Tuoesday,Wedenday}; 就创建了三个常量,Monday的值是0,Tuoesday是1,Wedenday是2,当需要一些可以可以排列起来的常量值的时候,定义枚举的意义就是给了这些常量名字。
虽然枚举类型可以当类型使用,但是实际上并不常用,但是如果是有意是排比名字,用枚举比宏定义方便,枚举比用好些,因为枚举有int类型,在C 语言中,枚举类型是被当做 int 或者 unsigned int 类型来处理的,既然枚举也是一种数据类型,所以它和基本数据类型一样也可以对变量进行声明,枚举也可以用typedef关键字将枚举类型定义成别名,并利用该别名进行变量声明
注意:
1、同一个程序中不能定义同名的枚举类型,不同的枚举类型中也不能存在同名的命名常量
2、枚举成员)是「常量」而不是变量,这个一定要搞清楚,因为枚举成员的是常量,所以不能对它们赋值,只能将它们的值赋给其他的变量
3、枚举类型的定义和变量的声明分开:如果对枚举型的变量赋整数值时,需要进行类型转换
enum DAY { MON=1, TUE, WED, THU, FRI, SAT, SUN };//枚举常量的值是可以在这里进行自定义的 MON=1//基本数据类型的赋值 :
int a, b, c;
a = 1;
b = 2;
c = 3;
//使用枚举赋值 :
enum DAY yesterday, today, tomorrow;//枚举定义变量
yesterday = MON;
today = TUE;
tomorrow = WED;
// today = (enum DAY) (yesterday + 1);//强制类型转换// tomorrow = (enum DAY) 30; //强制类型转换//tomorrow = 3; //错误
枚举在用switch-case结构中使用非常方便。
//综合例子:输入数字查看是星期几#include 《stdio.h》//枚举是define的代替 它是一个集合 //和switch连用很方便int main() {
enum week { Mon = 1,Tues, Wed, Thurs, Fri, Sat, Sun } day; //day可放到这
//enum week day;定义
scanf(“%d”, &day);
switch (day) {
case Mon: puts(“Monday”); break;//1 puts代替printf输出字符串
case Tues: puts(“Tuesday”); break;// 2
case Wed: puts(“Wednesday”); break;// 3
case Thurs: puts(“Thursday”); break;// 4
case Fri: puts(“Friday”); break;// 5
case Sat: puts(“Saturday”); break;// 6
case Sun: puts(“Sunday”); break;// 7
default: puts(“Error!”);
}
return 0;
}
枚举型是预处理指令#define的替代,枚举和宏其实非常类似,宏在「预处理阶段」将名字替换成对应的值,枚举在「编译阶段」将名字替换成对应的值,其中一个枚举常量的占的字节数为4个字节,恰好和int类型的变量占的字节数相同
3、struct 结构体struct即结构体,C程序中经常需要用相关的不同类型的数据来描述一个数据对象。例如,描述学生的综合信息时,需要使用学生的学号、姓名、性别等不同类型的数据时,像这种数据类型总是在一起出现,那么我们不如把这些变量装入同一个“文件夹”中,这时用的关键字struct声明的一种数据类型就是表示这个“文件夹”的使用。
那么在说明和使用之前必须先定义它,也就是构造它。如同在说明和调用函数之前要先定义一样。结构体是一种集合,它里面包含了多个变量或数组,它们的类型可以相同,也可以不同,每个这样的变量或数组都称为结构体的成员,结构体也是一种数据类型,它由程序员自己定义,可以包含多个其他类型的数据,成员又称为成员变量,它是结构体所包含的若干个基本的结构类型,必须用“{}”括起来,并且要以分号结束,每个成员应表明具体的数据类型,成员一般用名字访问。
结构体和数组类似,也是一组数据的集合,整体使用没有太大的意义。数组使用下标[ ]获访问元素,结构体使用点号。访问单个成员。通过这种方式可以获取成员的值,也可以给成员赋值
数组:a[0]=10; 结构体:today.day (指针结构体用-》访问) 结构体的成员可以包含其他结构体,也可以包含指向自己结构体类型的指针,而通常这种指针的应用是为了实现一些更高级的数据结构如链表和树等。
声明定义结构:
struct关键字+结构体的标志名+大括号里边是成员+}后面的声明此结构变量+末尾分号,一般有这些:
struct week{定义一 struct{定义二 struct week {定义三
int x; int x; int x;
char y; char y; int y;
}; }p1,p2;//在这里声明变量 }p1,p2;
//p1和p2都是一种无名结构, //常用的一种结构定义声struct week p1,p2; // 里边有X和y 访问一样用。 明形式 //声明变量p1,p2,里边都是week的值 //里边有x和y的值 //用。访问 :p1.x p2.x
// p1.y, p2.y
对于第一和第三种形式,都声明了结构名week,但是第二种没有声明结构名,只是定义了两个结构变量,
这种叫无名结构
无名结构: 可以定义无名结构体类型的变量。编译器对无名结构体的处理是随机生成一个不重复的变量名。
无名结构的定义方式就是定义无名结构体时必须定义该结构体类型的至少一个变量。
优点:无名结构体的妙用就是可以避免相同类型的结构体的重复定义,
这样可以对每一个具体类型的队列都可以定义一个结构体来管理该队列的头尾指针,
即使定义多个相同具体类型的队列也不会引发重复定义的编译错误。这样定义了两个队列,
其元素类型均为int类型,同时各得到了一个维护队列头尾指针的结构体
缺点:这里定义了一个无名的结构体,同时声明了三个此种类型的变量。
但是,因为没有名字,我们在这句之后,无法内再定义与那三种变量相同类型的变量了。
除非你再容次去定义一个这样的相同的结构体类型。
还有一个重要的原因就是没有办法在其他位置定义我们所需要的结构体变量,
每次需要新定义结构体变量的时候都必须要找到最开始结构体代码书写的位置才能定义新的结构体
所以实际编程中无名结构并不常用
注意:1、结构体本身并不会被作为数据而开辟内存,真正作为数据而在内存中存储的是这种结构体所定义的变量。
2、先声明结构体类型,再定义该类型的变量,声明结构体类型,不分配空间定义结构体类型变量,就要分配内存空间
3、量使用占为少的类型,如,在可能的时候使用short代替int,「按数据类型本身占用的位置从大到小排」
4、除了可以对成员进行逐一赋值,也可以在定义时整体赋值:p1={struct week}{5,10}; 相当于 p1.x=5,p1.y=10; p1=p2 表示 p1.x=p2.x , p1.y=p2.y; 不过整体赋值仅限于定义结构体变量的时候,在使用过程中只能对成员逐一赋值 5、结构体变量不能相加,相减,也不能相互乘除,但结构体可以相互赋值,也就是说,可以将一个结构体变量赋值给另一个结构体变量。但是前提是这两个结构体变量的结构体类型必须相同
结构体的运算:要访问整个结构,直接用结构变量的名字,对于整个结构,可以做赋值,取地址,也可以传递给函数参数
结构体数值
嵌套的结构体:
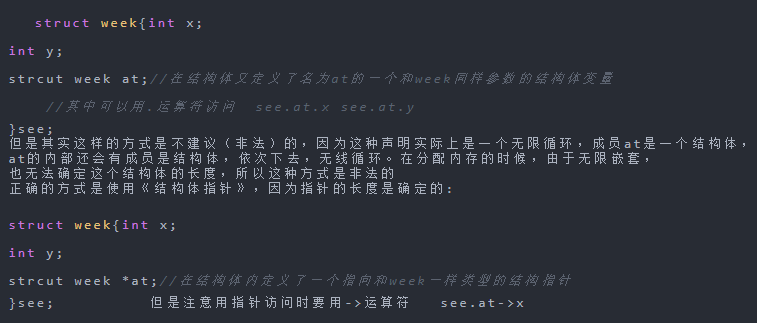
结构体相互引用:
一个结构体A中包含一个或多个与结构体B相关的成员, 且结构体B中也包含一个或多个与结构体A相关的成员称为结构体的互引用。 但是要注意:如果已经定义了两个结构A和B ,在定义结构体A的成员b时,结构体B对A还未可见,故此时编译器会报数据类型B未定义 解决的办法是使用不完整声明:
strcut A;//不完整声明
strcut B;//不完整声明
strcut _A{ strcut _B{
int x; int x;
int y; int y;
struct _B a; struct _A b; //在结构B中定义了一个名为b的和A结构一样类型的结构变量
//其中可以用点访问 A.a.x B.b.x
}A; }B;
//但是注意这种方式犯了一个和上面第一个嵌套结构的错误,就是结构体A和B都是直接包含了对方,
正确的用法还是使用指针:
strcut _A{ strcut _B{
int x; int x;
int y; int y;
struct _B *a; struct _A *b; //在结构B中定义了一个名为b的和A结构一样类型的结构指针
//其中指针要用-》访问 A.a-》x B.b-》x
}A; }B;
//但是注意这种方式犯了一个和上面第一个嵌套结构的错误,就是结构体A和B都是直接包含了对方,正确的用法还是使用指针:
strcut _A{ strcut _B{
int x; int x;
int y; int y;
struct _B *a; struct _A *b; //在结构B中定义了一个名为b的和A结构一样类型的结构指针
//其中指针要用-》访问 A.a-》x B.b-》x
}A; }B;
//所以使用互引用要注意:至少有一个结构必须在另一个结构体中以指针的形式被引用。
结构体函数与函数参数
结构体做函数形参:
整个结构可以作为参数的值传入函数,这时候是在函数内新建一个结构变量,并复制调用者结构的值,也可以返回一个值,这和数组完全不同 用结构体变量作实参时,采取的也是“值传递”方式,将 结构体变量所占的内存单元的内容(结构体变量成员列表) 全部顺序传递给形参,这里形参也得是结构体变量。
#include《stdio.h》typedef struct _node {
int n;
char a[100];
}NODE;
void add(NODE a);//这种形式只是用来做值的传递int main(void) {
//以传值方式传递结构需要对整个结构做一份拷贝
NODE t;
scanf(“%d %d”, &t.a[0], &t.n);//输入1 3
printf(“1-%d %d
”,t.a[0],t.n);//输出 1 3
add(t);
printf(“3-%d %d
”, t.a[0], t.n);//输出1 3//也就是说在add函数里边做修改根本就影响不了主函数这边的值
}
void add(NODE a) {
a.a[0] = 100;//在这里能接受到NODE结构里边的成员
a.n = 666;
printf(“2-%d %d
”, a.a[0], a.n);//输出100 666
}
****//解决办法是用指针(也是经常用的方式):****#include《stdio.h》typedef struct _node {
int n;
char a[100];
}NODE;
int add(NODE a);//这种形式只是用来做值的传递int main(void) {
//以传值方式传递结构需要对整个结构做一份拷贝
NODE t;
scanf(“%d %d”, &t.a[0], &t.n);//输入1 3
printf(“1-%d %d
”,t.a[0],t.n);//输出 1 3
add(&t);//这里传进去的是t的地址
printf(“3-%d %d
”, t.a[0], t.n);//输出100 666//传进去的是地址,所以就可以达到访问同一个变量的操作
}
int add(NODE *) {//定义一个结构指针
a.a[0] = 100;//在这里能接受到NODE结构里边的成员
a.n = 666;
printf(“2-%d %d
”, a.a[0], a.n);//输出100 666
return a;//这里返回的是指针 所以能达到访问主函数里边调用的值
//使用指针才可以用返回值
}
//常用的方式
另一种做法
结构体做函数:
/*上面的第一个的方案,把一个结构传入了函数,然后在函数中操作,但是没有返回回去
问题在于传入函数的是外面那个结构的克隆体,而不是指针,传入结构和传入数组是不同的,
解决办法是在这个输入函数中,在里边创建一个临时的结构变量,然后把这个结构返回给调用者*/#include《stdio.h》typedef struct _node {
int x;
int y;
}NODE;
struct _node add();//定义结构类型的函数int main(void) {
NODE a;
a.x = 0;
a.y = 0;
printf(“1-%d %d
”, a.x, a.y);// 0 0
a = add();//函数调用 /把n的值又返回到a
printf(“3-%d %d
”, a.x, a.y);//所以在这里的时候值已经被改变
return 0;
}
struct _node add() {
NODE n;
scanf(“%d”, &n.x);//输入1 3
scanf(“%d”, &n.y);
printf(“2-%d %d
”, n.x, n.y);//在这里的时候赋值就成功了
//return n;//把n的值带回出去
}
//这种方法也能达到“改变“的效果,但是往往开销内存较大,所以一般情况都是使用指针比较方便
用结构体变量名作参数,这种传递方式是单向的,如果在执行被调函数期间改变了形参(也是结构体变量)的值,该值不能返回主调函数,这往往造成使用上的不便,因此一般少用这种方法。
和本地变量一样。在函数内部声明的结构只能在函数内部使用,所以通常在函数外部声明一个结构类型的,这样就可以被多个函数所使用
//结构做函数参数例子 (输入今天计算明天)#include《stdio.h》#include《stdbool.h》//利用布尔数据类型struct date {
int year;
int month;
int day;
};
bool If(struct date p);//判断是否是闰年int number(struct date c);//判断是否是此月最后一天int main(void) {
struct date today,tomorrow;
printf(”年-月-日
“);
scanf(”%d %d %d“, &today.year, &today.month, &today.day);
//前面两个判断 是否此月最后一天 是否此年此月最后一天
if (today.day==number(today)&&today.month!=12) {//首月1号
tomorrow.day = 1;
tomorrow.month =today.month+1;
tomorrow.year = today.year;
}
else if (today.day == number(today) && today.month == 12) {//下一年
tomorrow.day = 1;
tomorrow.month = 1;
tomorrow.year =today.year+1;
}
else {
tomorrow.day =today.day+1;
tomorrow.month = today.month;
tomorrow.year = today.year;
}
printf(”明天是%d-%d-%d
“, tomorrow.year, tomorrow.month, tomorrow.day);
return 0;
}
int number(struct date c)//这里的形参接收的today结构体数据
{
int day;
const int a[12] = { 31,28,31,30,31,30,31,31,30,31,30,31 };//这个月最大的天数
if (c.month==22&&If(c)) {//查看是否是二月并且是润年
day = 29;//是润年
}
else {
day = a[c.month - 1];
}
return day;
}
bool If(struct date p) {//这里的形参接收的today结构体数据
//润年的特点,能被4整除,但不能被100整数,能被100整除,但是不能被400整除
if (p.year % 4 == 0 && p.year / 100 != 0 || p.year % 400 == 0) {
return true;
}
else {
return false;
}
}
//结构体做函数例子 (计算下一秒)#include《stdio.h》struct time {
int hour;
int minute;
int second;
};
struct time times(struct time now);//利用结构做函数返回值,形参也是使用结构体做为传值int main(void) {
struct time nows[5] = {
{11,50,20},{13,25,59},{12,59,59},{23,59,59},{00,00,00},
};
int i;
for (i = 0; i 《 5; i++) {
printf(”时间是 %d:%d:%d
“, nows[i].hour, nows[i].minute, nows[i].second);
nows[i] = times(nows[i]);
printf(”下一秒是 %d:%d:%d
“, nows[i].hour, nows[i].minute, nows[i].second);
}
return 0;
}
struct time times(struct time now) {
now.second++;
if (now.second == 60) {//60秒
now.minute++;
now.second = 0;
if (now.minute == 60)//60分
{
now.hour++;
now.minute = 0;
now.second = 0;
if (now.hour == 24) {//零点
now.hour=0;
now.minute = 0;
now.second = 0;
}
}
}
return now;//返回类型必须也函数类型一致,换句话说只有结构体类型才能返回结构体类型
}
结构体数组
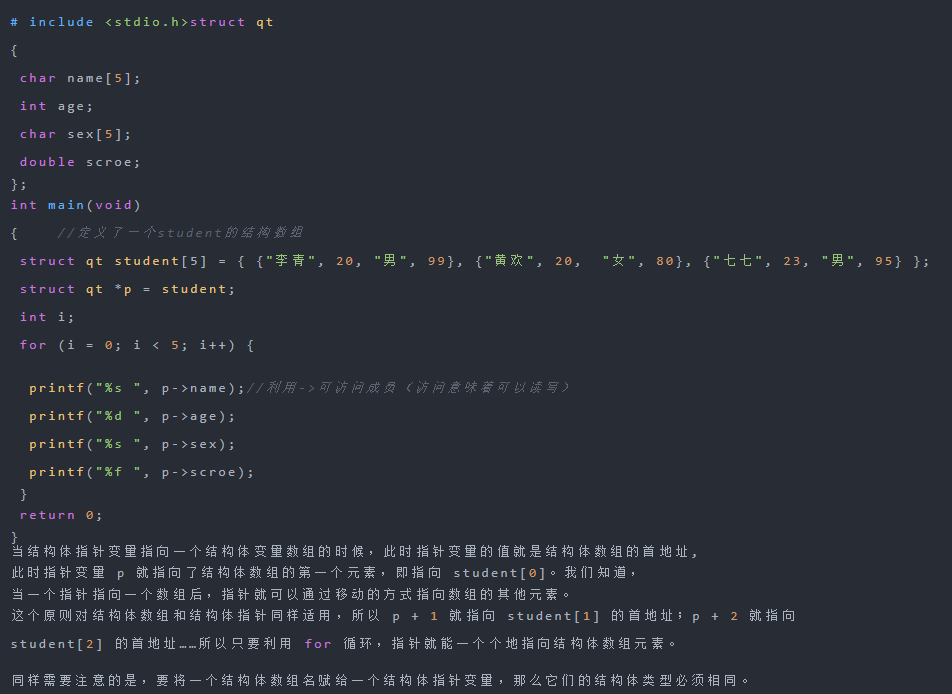
结构体数组,是指数组中的每个元素都是一个结构体。在实际应用中,C语言结构体数组常被用来表示一个拥有相同数据结构的群体,比如一个班的学生、一个车间的职工等。结构体可以存储不同的数据类型,将他们互相联系起来。结构体数组可以连续存储多个结构体,和数组作用相似。比如想定义同一个最小外接矩形的四个坐标值,并给予这个矩形一个特征编号。当需要存储多个最小外接矩形的信息时,就需要动态申请一个结构体数组
定义结构体数组的方法很简单,同定义结构体变量是一样的,只不过将变量改成数组。或者说同前面介绍的普通数组的定义是一模一样的:struct student tp[10]; 这就定义了一个结构体数组,共有 10 个元素,每个元素都是一个结构体变量,都包含所有的结构体成员。
结构体数组的初始化与前面讲的数值型数组的初始化也是一样的,数值型数组初始化的方法和需要注意的问题在结构体数组的初始化中同样适用,因为不管是数值型数组还是结构体数组都是数组。
//例子: //寻找学生中 学号最大的# include 《stdio.h》# include 《string.h》struct STU
{
char name[20];
int age;
char sex[20];
char num[20];
};
void OutputSTU(struct STU stu[]); //函数声明, 该函数的功能是输出成绩最大的学生信息int main(void)
{
int i;
struct STU stu[5];
for (i = 0; i 《 2; ++i)
{
printf(”请按照名字、年龄、性别、学号(1-9数字)输入第%d个学生的信息:“, i + 1);
scanf(”%s %d %s %s“, stu[i].name, &stu[i].age, stu[i].sex, stu[i].num);/*%c前面要加空格, 不然输入时会将空格赋给%c*/
}
OutputSTU(stu);
return 0;
}
void OutputSTU(struct STU stu[])
{
struct STU stumax = stu[0];//让临时结构stumax保存第一个学生的信息
int j;
for (j = 1; j 《 2; ++j)//第一个学生依次和后面的学生比较
{
if (strcmp(stumax.num, stu[j].num) 《 0) //strcmp函数的使用 s1》s2:1 s1《s2:-1
{
stumax = stu[j];//让临时结构保存那个学生的信息
}
}
printf(”学生姓名:%s 学生年龄:%d 学生性别:%s 学生分数:%s
“, stumax.name, stumax.age, stumax.sex, stumax.num);
}
结构体指针
和数组不同,结构变量的名字并不是结构变量的地址,必须使用&运算符 strcut node *tp=&nb; 指针一般用-》访问结构体里边的成员
指针变量非常灵活方便,可以指向任一类型的变量 ,若定义指针变量指向结构体类型变量,则可以通过指针来引用结构体类型变量。

这里说明:结构体和结构体变量是两个不同的概念:结构体是一种数据类型,是一种创建变量的模板,编译器不会为它分配内存空间,就像 int、float、char 这些关键字本身不占用内存一样;结构体变量才包含实实在在的数据,才需要内存来存储。所以用一个结构体去取一个结构体名的地址,这种写法是错误的,也不能将它赋值给其他变量。
#include《stdio.h》struct point {
int x;
int y;
};
struct point *gt(struct point*p);//结构指针函数void print(const struct point *p);//结构指针void out(struct point p);//普通的结构体做函数参数int main(void) {
struct point y = { 0,0 };//以point结构定义一个y的结构变量
//以下三种调用 等价
//注意gt是一个结构体的指针函数
gt(&y); //这是一个函数的返回结果函数 //取y结构的地址传入函数
out(y);
out(*gt(&y)); // (里边)的都是做为参数 *gt(&y)做为指针返回值 这个函数它的返回用指针表示
print(gt(&y)); //gt(&y)是一个返回值 这样表示的是利用gt函数的返回值在print函数里边操作
//*get(&y) = (struct point){ 1,2 }; //这也可以做的
}
struct point* gt(struct point*p) {// *p要的是&y的地址
scanf(”%d“, &p-》x);
scanf(”%d“, &p-》y);
printf(”a=%d,%d
“, p-》x, p-》y);//用-》来访问指针结构里边的成员
return p;// 用完指针后 返回指针
}
void out(struct point p) {
printf(”b=%d,%d
“, p.x, p.y);
}
void print(const struct point *p) {//加上const表示不再改动参数
printf(”c=%d,%d
“, p-》x, p-》y);
}
指向结构体数组的指针:
在之前讲数值型数组的时候可以将数组名赋给一个指针变量,从而使该指针变量指向数组的首地址,然后用指针访问数组的元素。结构体数组也是数组,所以同样可以这么做。我们知道,结构体数组的每一个元素都是一个结构体变量。如果定义一个结构体指针变量并把结构体数组的数组名赋给这个指针变量的话,就意味着将结构体数组的第一个元素,即第一个结构体变量的地址,也即第一个结构变量中的第一个成员的地址赋给了这个指针变量
typedef 别名
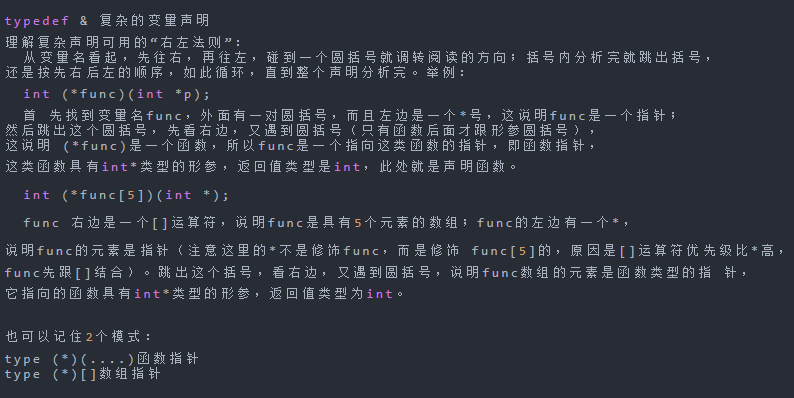
typedef是在编程语言中用来为复杂的声明定义简单的别名,新的名字是某种类型的别名,这样做改善了程序的可读性,它与宏定义有些差异。它本身是一种存储类的关键字,与auto、extern、mutable、static、register等关键字不能出现在同一个表达式中。
typedef为C语言的关键字,功能是用来声明一个已有的数据类型的新名字,比如 typedef int last ; 这就使得last成为 int 类型的别名 这样last这个名字就可以代替int出现在变量定义和参数声明的地方了
typedef也有一个特别的长处:它符合范围规则,使用typedef定义的变量类型其作用范围限制在所定义的函数或者文件内(取决于此变量定义的位置),而宏定义则没有这种特性。
结构体的内存对齐方式(存储空间)
结构体内存对齐:一个结构体变量定义完之后,其在内存中的存储并不等于其所包含元素的宽度之和,元素是按照定义顺序一个一个放到内存中去的,但并不是紧密排列的。从结构体存储的首地址开始,每个元素放置到内存中时,它都会认为内存是按照自己的大小来划分的,因此元素放置的位置一定会在自己宽度的整数倍上开始。
内存对齐可以大大提升内存访问速度,是一种用空间换时间的方法。内存不对齐会导致每次读取数据都会读取两次,使得内存读取速度减慢。
cpu把内存当成是一块一块的,块的大小可以是2,4,8,16 个字节,因此CPU在读取内存的时候是一块一块进行读取的,块的大小称为内存读取粒度。

如果结构体内存在长度大于处理器位数的元素,那么就以处理器的倍数为对齐单位;否则,如果结构体内的元素的长度都小于处理器的倍数的时候,便以结构体里面最长的数据元素为对齐单位。
另外 结构体的内存地址就是它第一个成员变量的地址 isa永远都是结构体中的第一个成员变量 所以结构体的地址也就是其isa指针的地址
内存对齐简介
由于内存的读取时间远远小于CPU的存储速度,这里用设定数据结构的对齐系数,即牺牲空间来换取时间的思想来提高CPU的存储效率。
内存对齐”应该是编译器的“管辖范围”。编译器为程序中的每个“数据单元”安排在适当的位置上。但是C语言的一个特点就是太灵活,太强大,它允许你干预“内存对齐”。如果你想了解更加底层的秘密,“内存对齐”对你就不应该再模糊了。这也是一个大小端模式的问题
每个特定平台上的编译器都有自己的默认“对齐系数”(也叫对齐模数)。程序员可以通过预编译命令#pragma pack(n)来改变这一系数,其中的n就是你要指定的“对齐系数”。
规则:
1、数据成员对齐规则:结构(struct)(或联合(union))的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员的对齐「按照#pragma pack指定的数值和这个数据成员自身长度中,比较小的那个进行」。
2、结构(或联合)的整体对齐规则:在数据成员完成各自对齐之后,结构(或联合)本身也要进行对齐,对齐将「按照#pragma pack 指定的数值和结构(或联合) 最大数据成员长度中,比较小的那个进行」对齐。
3、结合1、2可推断:当#pragma pack的n值等于或超过所有数据成员长度的时候,这个n值的大小将不产生任何效果。
#pragma pack(n) 设定变量以n字节为对齐方式:
「作用」:指定结构体、联合以及类成员
「语法」:#pragma pack( [show] | [push | pop] [, identifier], n )
1,pack提供数据声明级别的控制,对定义不起作用;
2,调用pack时不指定参数,n将被设成默认值;
n:可选参数;指定packing的数值,以字节为单位;缺省数值是8,合法的数值分别是1、2、4、8、16。其他参数都是可选的可先不了解
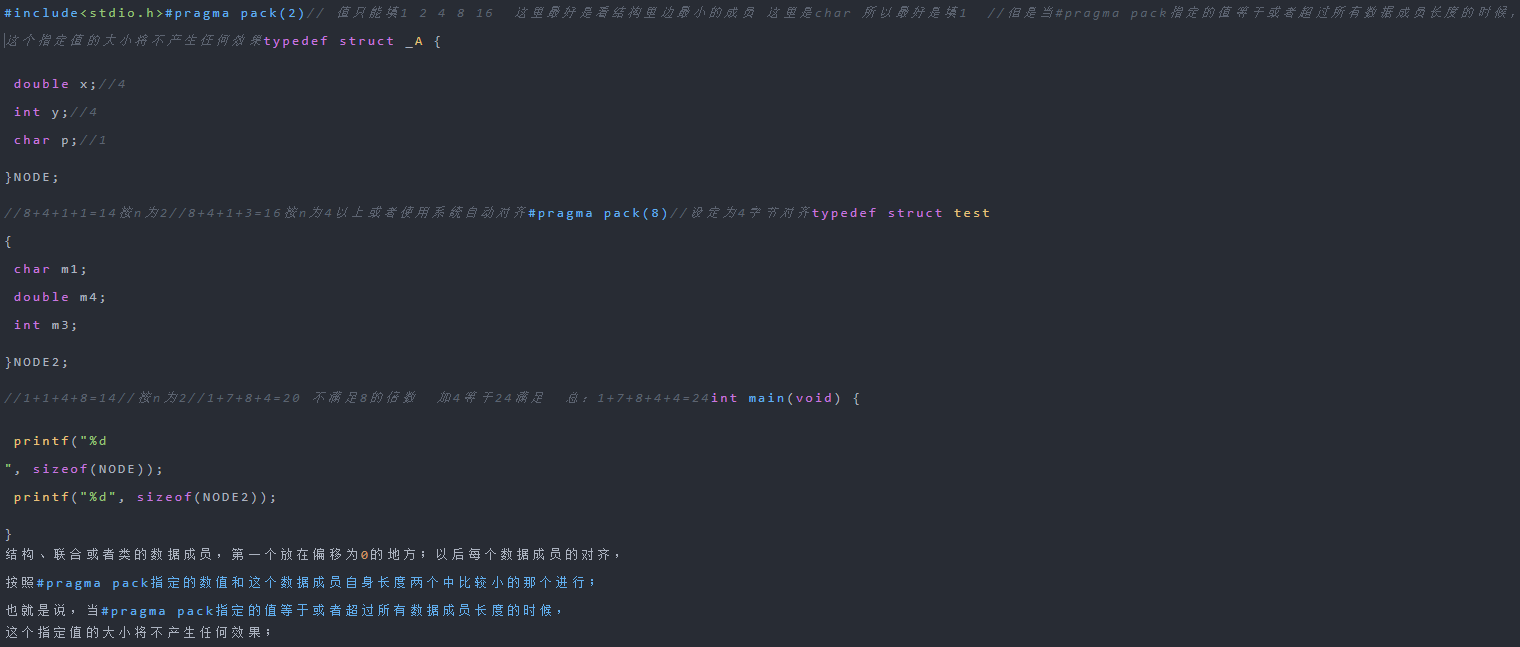
每个成员分别对齐,即每个成员按自己的方式对齐,并最小化长度;规则就是每个成员按其类型的对齐参数(通常是这个类型的大小)和指定对齐参数中较小的一个对齐。
大小端:
如:int 11 22 33 44
在存储的时候
大端:11 22 33 44
0 1 2 3
低地址----》 高地址
小端:44 33 22 11
0 1 2 3
低地址----》 高地址
大小端的差异在于存放顺序不同
常见的操作系统是小端,通讯协议是大端。
//结构体例子:使用尾插法创建链表#include《stdio.h》//单链表的创建typedef struct _node {
int nb;//数值
struct _node *nxte;//定义一个指向下一个的节点的指针
}NODE;
typedef struct _link{//利用这个结构体 封装 首尾节点
NODE *head;
NODE *qt;
}link;
void add(link *phead, link *qt, int n);//定义函数将 首尾指针传入int main(void) {
link head, q;//定义一个结构,连指针都不是的
head.head = q.qt = NULL;//初始化
int n;
for (scanf(”%d“, &n); n != -1; scanf(”%d“, &n)) {
add(&head, &q, n);//将地址 值传入
}
NODE *t;
t = head.head;//利用临时结构将链表输出
for (; t; t = t-》nxte) {
printf(”%d “, t-》nb);
}
return 0;
}
//尾插法void add(link *phead, link *qt, int n) {
NODE *p = (NODE*)malloc(sizeof(NODE));//为新结点开辟空间
p-》nb = n;
p-》nxte = NULL;
if (phead-》head == NULL) {//判断首结点是否为空
phead-》head = p;//是空的就让首结点等于新结点
}
else {//不为空时,让尾结点依次跑到后面去
qt-》qt-》nxte = p;
}
qt-》qt = p;
}
4、union 共用体(联合体)在进行某些算法的C语言编程的时候,需要使几种不同类型的变量存放到同一段内存单元中。也就是使用覆盖技术,几个变量互相覆盖。这种几个不同的变量共同占用一段内存的结构,在C语言中 以关键字union声明的一种数据结构,这种被称作“共用体”类型结构,也叫联合体。
“联合”与“结构”有一些相似之处。但两者有本质上的不同。在结构中各成员有各自的内存空间,一个结构体变量的总长度大于等于各成员长度之和。而在“联合”中,各成员共享一段内存空间,一个联合变量的长度等于各成员中最长的长度。注意这里所谓的共享不是指把多个成员同时装入一个联合变量内,而是指该联合变量可被赋予任一成员值,但每次只能赋一种值,赋入新值则冲去旧值,共用体变量中起作用的成员是最后一次存放的成员,在存入一个新成员后,原有成员就失去作用,共用体变量的地址和它的各成员的地址都是同一地址
一个联合类型必须经过定义之后,才能把变量说明为该联合类型:

注意:1、不能把共用体变量作为函数参数,也不能是函数带回共用体变量,但可以使专用指向共用体变量的指针
2、所有成员占用同一段内存,修改一制个成员会影响其余所有成员。
共用体的访问:共用体访问成员的值时一般使用。运算符,指针时用-》运算符(和结构体是一样的)
typedef union _node {
int a;
double b;
char c;
union _node *p;
}NODE;
int main(void) {
NODE a;//定义变量
NODE t;
a.b;//用。访问
t.p-》a;//指针用-》访问
}
联合的使用规则几乎和结构体strtct的规则用法一样,只不过是内部表示的不同。
补充:
还有一个是无名联合体,它是和无名结构体的工作原理是相同的
#include《stdio.h》//简单的例子#include《string.h》typedef union _node{
int a;
double b;
char c[20];
}NODE;
int main(void) {
NODE a;//这里只定义一个变量
a.a = 666;
printf(”%d
“, a.a);
a.b = 9.99;
printf(”%f
“, a.b);
strcpy(a.c, ”hello world!“);
printf(”%s
“, a.c);
//我们看到,三个都被完整的输出了,因为在同一时刻,只有一个成员是有效的
}
输出:
6669.990000
hellow world!
共用体的作用:
1、节省内存,有两个很长的数据结构,不会同时使用,比如一个表示老师,一个表示学生,如果要统计教师和学生的情况用结构体的话就有点浪费了!用结构体的话,只占用最长的那个数据结构所占用的空间,就足够了!
2、实现不同类型数据之间的类型转换,遇到各种类型的数据共用存储空间,很方便的实现了不同数据类型之间的转换,不需要显示的强制类型转换。
其他:1、确定CPU的模式:大端、小端模式确定
大小端不同,则存储的方式也存在差别,比如int需要4个字节,而char只需要1个字节,根据1个字节所在的具体位置即可判定CPU的模式
2、寄存器的定义,实现整体的访问和单项的访问//共用体综合例子:根据输入的数据类型输出需要的相应的数据#include《stdio.h》#include《string.h》//数据类型输出 5*4 m n n的第几个x union node {
int a;
double b;
char c[30];
}add[10000];
char p[10000][30]; //保存的字符串数组int main(void) {
int n, m;
scanf(”%d %d“, &n, &m);
int x;
double y;
char t[50];
int i, j;
for (i = 0; i 《 n; i++) {//输入
scanf(”%s“, &p[i]);//作为字符串数组,需要取地址
if (strcmp(”INT“, p[i]) == 0) {//整形
scanf(”%d“, &x);
add[i].a = x;
}
else if(strcmp(”DOUBLE“,p[i])==0){//浮点
scanf(”%lf“, &y);
add[i].b = y;
}
else if (strcmp(”STRCING“, p[i]) == 0) {//字符串
scanf(”%s“, t);
strcpy(add[i].c, t);
}
}
for (i = 0; i 《 m; i++) {//输出
scanf(”%d“, &j);
if (strcmp(”INT“, p[j]) == 0) {
printf(”%d
“, add[j].a);
}
else if (strcmp(”DOUBLE“, p[j]) == 0)
{
printf(”%f
“, add[j].b);
}else if(strcmp(”STRING“,p[j])==0)
{
printf(”%s
“, add[j].c);
}
}
return 0;
}
//输入:/*
5 4
INT 456
DOUBLE 123.56
DOUBLE 0.476
STRING welcomeToC
STRING LemonTree
0
1
2
4
*///输出:/*
456
123.56
0.48
LemonTree
*/
编辑:jq 1、define宏定义以#号开头的都是编译预处理指令,它们不是C语言的成分,但是C程序离不开它们,#define用来定义一个宏,程序在预处理阶段将用define定义的来内容进行了替换。因此在程序运行时,常量表中并没有用define定义的常量,系统不为它分配内存。
define定义的常量,预处理时只是直接进行了替换,它用来将一个标识符定义为一个字符串,该标识符被称为宏名,被定义的字符串称为替换文本。因此在编译时它不对宏的定义进行检查,作用域不影响对常量的访问 。它的常量值只能是字符串或数字。
该命令有两种格式:一种是简单的常量宏定义, 另一种是带参数的宏定义。
不带参数的宏:#define《 名字 》《 值 》
要注意,没有结尾的分号,因为不是C的语句,名字必须是一个单词,值可以是各种东西,宏定义是用宏名来表示一个字符串,在宏展开时又以该字符串取代宏名,这只是一种简单的代换,字符串中可以含任何字符,可以是常数,也可以是表达式,预处理程序对它不作任何检查。如有错误,只能在编译已被宏展开后的源程序时发现。
注意。宏定义不是说明或语句,在行末不必加分号,如加上分号则连分号也一起置换。宏定义其作用域为宏定义命令起到源程序结束。如要终止其作用域可使用#undef命令
带参数的宏 :
像函数的宏,一般的定义形式 :带参宏定义的一般形式为:「#define 宏名」(形参表)字符串,也是没有结尾的分号,可以带多个参数 ,#define NB(a,b)((a)》(b)?(b):(a)), 也可以组合(嵌套)使用其他宏,注意 带参数宏的原则 一切都要有括号,参数出现的每个地方都要有括号。带参数的宏在大型的程序的代码中使用非常普遍,在#和##这两个运算符的帮助下可以很复杂,如“产生函数”,但是有些宏会被inline函数代替(C++的函数)
使用宏好处:
“提高运行效”。定义的标识符不占内存,只是一个临时的符号,预编译后这个符号就不存在了。在简单的程序使用带参数的宏定义可完成函数调用的功能,又能减少系统开销,提高运行效率。正如C语言中所讲,函数的使用可以使程序更加模块化,便于组织,而且可重复利用。
“方便程序的修改”。使用宏定义可以用宏代替一个在程序中经常使用的常量。注意,是“经常”使用的。这样,当需要改变这个常量的值时,就不需要对整个程序一个一个进行修改,只需修改宏定义中的常量即可。且当常量比较长时,使用宏就可以用较短的有意义的标识符来代替它,这样编程的时候就会更方便,不容易出错。因此,宏定义的优点就是方便和易于维护。
//例子:/求球的体积#include《stdio.h》#include《math.h》//对于半径为 r 的球,其体积的计算公式为 V =4/3*Π*r^3 //这里取Π为3.14//这里给定r的值,求V#define PI 3.14int main(void) {
double r;
scanf(“%lf”, &r);
double sum = 0;
sum = (4.0 / 3.0) * PI*pow(r, 3);//这里用PI替换掉了 3.14
printf(“%f.2”, sum);
}
#include《stdio.h》//合例子:输入数字查看是星期几int main(void) {
enum week {Mon = 1, Tue, Wed, Thu, Fri, Sat, Sun}today;
//在这里我们给Mon赋值了一,后面Tue以后的都相应加一赋值
scanf(“%d”, &today);
switch (today) {
case Mon: puts(“Monday”); break;
case Tue: puts(“Tuesday”); break;
case Wed: puts(“Wednesday”); break;
case Thu: puts(“Thursday”); break;
case Fri: puts(“Friday”); break;
case Sat: puts(“Saturday”); break;
case Sun: puts(“Sunday”); break;
default: puts(“no day”);
}
return 0;
}
2、enum枚举枚举型是一个集合,集合中的元素(枚举成员)是一些命名的整型常量,元素之间用逗号,隔开。它是一种用户定义的数据类型,它用关键字enum以如下语法来声明,:enum 枚举类型名字,{名字0,。。。,名字n};第一个枚举成员的默认值为整型的0,后续枚举成员的值在前一个成员上加1 (当然这个是可以自定义成员值的)
枚举类型名字通常并不真的使用,要用的是在它大括号里边的名字,因为它们就是常量符号,它们的类型是int,值则是依次从零到n,如 enum week { Monday,Tuoesday,Wedenday}; 就创建了三个常量,Monday的值是0,Tuoesday是1,Wedenday是2,当需要一些可以可以排列起来的常量值的时候,定义枚举的意义就是给了这些常量名字。
虽然枚举类型可以当类型使用,但是实际上并不常用,但是如果是有意是排比名字,用枚举比宏定义方便,枚举比用好些,因为枚举有int类型,在C 语言中,枚举类型是被当做 int 或者 unsigned int 类型来处理的,既然枚举也是一种数据类型,所以它和基本数据类型一样也可以对变量进行声明,枚举也可以用typedef关键字将枚举类型定义成别名,并利用该别名进行变量声明
注意:
1、同一个程序中不能定义同名的枚举类型,不同的枚举类型中也不能存在同名的命名常量
2、枚举成员)是「常量」而不是变量,这个一定要搞清楚,因为枚举成员的是常量,所以不能对它们赋值,只能将它们的值赋给其他的变量
3、枚举类型的定义和变量的声明分开:如果对枚举型的变量赋整数值时,需要进行类型转换
enum DAY { MON=1, TUE, WED, THU, FRI, SAT, SUN };//枚举常量的值是可以在这里进行自定义的 MON=1//基本数据类型的赋值 :
int a, b, c;
a = 1;
b = 2;
c = 3;
//使用枚举赋值 :
enum DAY yesterday, today, tomorrow;//枚举定义变量
yesterday = MON;
today = TUE;
tomorrow = WED;
// today = (enum DAY) (yesterday + 1);//强制类型转换// tomorrow = (enum DAY) 30; //强制类型转换//tomorrow = 3; //错误
枚举在用switch-case结构中使用非常方便。
//综合例子:输入数字查看是星期几#include 《stdio.h》//枚举是define的代替 它是一个集合 //和switch连用很方便int main() {
enum week { Mon = 1,Tues, Wed, Thurs, Fri, Sat, Sun } day; //day可放到这
//enum week day;定义
scanf(“%d”, &day);
switch (day) {
case Mon: puts(“Monday”); break;//1 puts代替printf输出字符串
case Tues: puts(“Tuesday”); break;// 2
case Wed: puts(“Wednesday”); break;// 3
case Thurs: puts(“Thursday”); break;// 4
case Fri: puts(“Friday”); break;// 5
case Sat: puts(“Saturday”); break;// 6
case Sun: puts(“Sunday”); break;// 7
default: puts(“Error!”);
}
return 0;
}
枚举型是预处理指令#define的替代,枚举和宏其实非常类似,宏在「预处理阶段」将名字替换成对应的值,枚举在「编译阶段」将名字替换成对应的值,其中一个枚举常量的占的字节数为4个字节,恰好和int类型的变量占的字节数相同
3、struct 结构体struct即结构体,C程序中经常需要用相关的不同类型的数据来描述一个数据对象。例如,描述学生的综合信息时,需要使用学生的学号、姓名、性别等不同类型的数据时,像这种数据类型总是在一起出现,那么我们不如把这些变量装入同一个“文件夹”中,这时用的关键字struct声明的一种数据类型就是表示这个“文件夹”的使用。
那么在说明和使用之前必须先定义它,也就是构造它。如同在说明和调用函数之前要先定义一样。结构体是一种集合,它里面包含了多个变量或数组,它们的类型可以相同,也可以不同,每个这样的变量或数组都称为结构体的成员,结构体也是一种数据类型,它由程序员自己定义,可以包含多个其他类型的数据,成员又称为成员变量,它是结构体所包含的若干个基本的结构类型,必须用“{}”括起来,并且要以分号结束,每个成员应表明具体的数据类型,成员一般用名字访问。
结构体和数组类似,也是一组数据的集合,整体使用没有太大的意义。数组使用下标[ ]获访问元素,结构体使用点号。访问单个成员。通过这种方式可以获取成员的值,也可以给成员赋值
数组:a[0]=10; 结构体:today.day (指针结构体用-》访问) 结构体的成员可以包含其他结构体,也可以包含指向自己结构体类型的指针,而通常这种指针的应用是为了实现一些更高级的数据结构如链表和树等。
声明定义结构:
struct关键字+结构体的标志名+大括号里边是成员+}后面的声明此结构变量+末尾分号,一般有这些:
struct week{定义一 struct{定义二 struct week {定义三
int x; int x; int x;
char y; char y; int y;
}; }p1,p2;//在这里声明变量 }p1,p2;
//p1和p2都是一种无名结构, //常用的一种结构定义声struct week p1,p2; // 里边有X和y 访问一样用。 明形式 //声明变量p1,p2,里边都是week的值 //里边有x和y的值 //用。访问 :p1.x p2.x
// p1.y, p2.y
对于第一和第三种形式,都声明了结构名week,但是第二种没有声明结构名,只是定义了两个结构变量,
这种叫无名结构
无名结构: 可以定义无名结构体类型的变量。编译器对无名结构体的处理是随机生成一个不重复的变量名。
无名结构的定义方式就是定义无名结构体时必须定义该结构体类型的至少一个变量。
优点:无名结构体的妙用就是可以避免相同类型的结构体的重复定义,
这样可以对每一个具体类型的队列都可以定义一个结构体来管理该队列的头尾指针,
即使定义多个相同具体类型的队列也不会引发重复定义的编译错误。这样定义了两个队列,
其元素类型均为int类型,同时各得到了一个维护队列头尾指针的结构体
缺点:这里定义了一个无名的结构体,同时声明了三个此种类型的变量。
但是,因为没有名字,我们在这句之后,无法内再定义与那三种变量相同类型的变量了。
除非你再容次去定义一个这样的相同的结构体类型。
还有一个重要的原因就是没有办法在其他位置定义我们所需要的结构体变量,
每次需要新定义结构体变量的时候都必须要找到最开始结构体代码书写的位置才能定义新的结构体
所以实际编程中无名结构并不常用
注意:1、结构体本身并不会被作为数据而开辟内存,真正作为数据而在内存中存储的是这种结构体所定义的变量。
2、先声明结构体类型,再定义该类型的变量,声明结构体类型,不分配空间定义结构体类型变量,就要分配内存空间
3、量使用占为少的类型,如,在可能的时候使用short代替int,「按数据类型本身占用的位置从大到小排」
4、除了可以对成员进行逐一赋值,也可以在定义时整体赋值:p1={struct week}{5,10}; 相当于 p1.x=5,p1.y=10; p1=p2 表示 p1.x=p2.x , p1.y=p2.y; 不过整体赋值仅限于定义结构体变量的时候,在使用过程中只能对成员逐一赋值 5、结构体变量不能相加,相减,也不能相互乘除,但结构体可以相互赋值,也就是说,可以将一个结构体变量赋值给另一个结构体变量。但是前提是这两个结构体变量的结构体类型必须相同
结构体的运算:要访问整个结构,直接用结构变量的名字,对于整个结构,可以做赋值,取地址,也可以传递给函数参数
结构体数值
嵌套的结构体:
结构体相互引用:
一个结构体A中包含一个或多个与结构体B相关的成员, 且结构体B中也包含一个或多个与结构体A相关的成员称为结构体的互引用。 但是要注意:如果已经定义了两个结构A和B ,在定义结构体A的成员b时,结构体B对A还未可见,故此时编译器会报数据类型B未定义 解决的办法是使用不完整声明:
strcut A;//不完整声明
strcut B;//不完整声明
strcut _A{ strcut _B{
int x; int x;
int y; int y;
struct _B a; struct _A b; //在结构B中定义了一个名为b的和A结构一样类型的结构变量
//其中可以用点访问 A.a.x B.b.x
}A; }B;
//但是注意这种方式犯了一个和上面第一个嵌套结构的错误,就是结构体A和B都是直接包含了对方,
正确的用法还是使用指针:
strcut _A{ strcut _B{
int x; int x;
int y; int y;
struct _B *a; struct _A *b; //在结构B中定义了一个名为b的和A结构一样类型的结构指针
//其中指针要用-》访问 A.a-》x B.b-》x
}A; }B;
//但是注意这种方式犯了一个和上面第一个嵌套结构的错误,就是结构体A和B都是直接包含了对方,正确的用法还是使用指针:
strcut _A{ strcut _B{
int x; int x;
int y; int y;
struct _B *a; struct _A *b; //在结构B中定义了一个名为b的和A结构一样类型的结构指针
//其中指针要用-》访问 A.a-》x B.b-》x
}A; }B;
//所以使用互引用要注意:至少有一个结构必须在另一个结构体中以指针的形式被引用。
结构体函数与函数参数
结构体做函数形参:
整个结构可以作为参数的值传入函数,这时候是在函数内新建一个结构变量,并复制调用者结构的值,也可以返回一个值,这和数组完全不同 用结构体变量作实参时,采取的也是“值传递”方式,将 结构体变量所占的内存单元的内容(结构体变量成员列表) 全部顺序传递给形参,这里形参也得是结构体变量。
#include《stdio.h》typedef struct _node {
int n;
char a[100];
}NODE;
void add(NODE a);//这种形式只是用来做值的传递int main(void) {
//以传值方式传递结构需要对整个结构做一份拷贝
NODE t;
scanf(“%d %d”, &t.a[0], &t.n);//输入1 3
printf(“1-%d %d
”,t.a[0],t.n);//输出 1 3
add(t);
printf(“3-%d %d
”, t.a[0], t.n);//输出1 3//也就是说在add函数里边做修改根本就影响不了主函数这边的值
}
void add(NODE a) {
a.a[0] = 100;//在这里能接受到NODE结构里边的成员
a.n = 666;
printf(“2-%d %d
”, a.a[0], a.n);//输出100 666
}
****//解决办法是用指针(也是经常用的方式):****#include《stdio.h》typedef struct _node {
int n;
char a[100];
}NODE;
int add(NODE a);//这种形式只是用来做值的传递int main(void) {
//以传值方式传递结构需要对整个结构做一份拷贝
NODE t;
scanf(“%d %d”, &t.a[0], &t.n);//输入1 3
printf(“1-%d %d
”,t.a[0],t.n);//输出 1 3
add(&t);//这里传进去的是t的地址
printf(“3-%d %d
”, t.a[0], t.n);//输出100 666//传进去的是地址,所以就可以达到访问同一个变量的操作
}
int add(NODE *) {//定义一个结构指针
a.a[0] = 100;//在这里能接受到NODE结构里边的成员
a.n = 666;
printf(“2-%d %d
”, a.a[0], a.n);//输出100 666
return a;//这里返回的是指针 所以能达到访问主函数里边调用的值
//使用指针才可以用返回值
}
//常用的方式
另一种做法
结构体做函数:
/*上面的第一个的方案,把一个结构传入了函数,然后在函数中操作,但是没有返回回去
问题在于传入函数的是外面那个结构的克隆体,而不是指针,传入结构和传入数组是不同的,
解决办法是在这个输入函数中,在里边创建一个临时的结构变量,然后把这个结构返回给调用者*/#include《stdio.h》typedef struct _node {
int x;
int y;
}NODE;
struct _node add();//定义结构类型的函数int main(void) {
NODE a;
a.x = 0;
a.y = 0;
printf(“1-%d %d
”, a.x, a.y);// 0 0
a = add();//函数调用 /把n的值又返回到a
printf(“3-%d %d
”, a.x, a.y);//所以在这里的时候值已经被改变
return 0;
}
struct _node add() {
NODE n;
scanf(“%d”, &n.x);//输入1 3
scanf(“%d”, &n.y);
printf(“2-%d %d
”, n.x, n.y);//在这里的时候赋值就成功了
//return n;//把n的值带回出去
}
//这种方法也能达到“改变“的效果,但是往往开销内存较大,所以一般情况都是使用指针比较方便
用结构体变量名作参数,这种传递方式是单向的,如果在执行被调函数期间改变了形参(也是结构体变量)的值,该值不能返回主调函数,这往往造成使用上的不便,因此一般少用这种方法。
和本地变量一样。在函数内部声明的结构只能在函数内部使用,所以通常在函数外部声明一个结构类型的,这样就可以被多个函数所使用
//结构做函数参数例子 (输入今天计算明天)#include《stdio.h》#include《stdbool.h》//利用布尔数据类型struct date {
int year;
int month;
int day;
};
bool If(struct date p);//判断是否是闰年int number(struct date c);//判断是否是此月最后一天int main(void) {
struct date today,tomorrow;
printf(”年-月-日
“);
scanf(”%d %d %d“, &today.year, &today.month, &today.day);
//前面两个判断 是否此月最后一天 是否此年此月最后一天
if (today.day==number(today)&&today.month!=12) {//首月1号
tomorrow.day = 1;
tomorrow.month =today.month+1;
tomorrow.year = today.year;
}
else if (today.day == number(today) && today.month == 12) {//下一年
tomorrow.day = 1;
tomorrow.month = 1;
tomorrow.year =today.year+1;
}
else {
tomorrow.day =today.day+1;
tomorrow.month = today.month;
tomorrow.year = today.year;
}
printf(”明天是%d-%d-%d
“, tomorrow.year, tomorrow.month, tomorrow.day);
return 0;
}
int number(struct date c)//这里的形参接收的today结构体数据
{
int day;
const int a[12] = { 31,28,31,30,31,30,31,31,30,31,30,31 };//这个月最大的天数
if (c.month==22&&If(c)) {//查看是否是二月并且是润年
day = 29;//是润年
}
else {
day = a[c.month - 1];
}
return day;
}
bool If(struct date p) {//这里的形参接收的today结构体数据
//润年的特点,能被4整除,但不能被100整数,能被100整除,但是不能被400整除
if (p.year % 4 == 0 && p.year / 100 != 0 || p.year % 400 == 0) {
return true;
}
else {
return false;
}
}
//结构体做函数例子 (计算下一秒)#include《stdio.h》struct time {
int hour;
int minute;
int second;
};
struct time times(struct time now);//利用结构做函数返回值,形参也是使用结构体做为传值int main(void) {
struct time nows[5] = {
{11,50,20},{13,25,59},{12,59,59},{23,59,59},{00,00,00},
};
int i;
for (i = 0; i 《 5; i++) {
printf(”时间是 %d:%d:%d
“, nows[i].hour, nows[i].minute, nows[i].second);
nows[i] = times(nows[i]);
printf(”下一秒是 %d:%d:%d
“, nows[i].hour, nows[i].minute, nows[i].second);
}
return 0;
}
struct time times(struct time now) {
now.second++;
if (now.second == 60) {//60秒
now.minute++;
now.second = 0;
if (now.minute == 60)//60分
{
now.hour++;
now.minute = 0;
now.second = 0;
if (now.hour == 24) {//零点
now.hour=0;
now.minute = 0;
now.second = 0;
}
}
}
return now;//返回类型必须也函数类型一致,换句话说只有结构体类型才能返回结构体类型
}
结构体数组
结构体数组,是指数组中的每个元素都是一个结构体。在实际应用中,C语言结构体数组常被用来表示一个拥有相同数据结构的群体,比如一个班的学生、一个车间的职工等。结构体可以存储不同的数据类型,将他们互相联系起来。结构体数组可以连续存储多个结构体,和数组作用相似。比如想定义同一个最小外接矩形的四个坐标值,并给予这个矩形一个特征编号。当需要存储多个最小外接矩形的信息时,就需要动态申请一个结构体数组
定义结构体数组的方法很简单,同定义结构体变量是一样的,只不过将变量改成数组。或者说同前面介绍的普通数组的定义是一模一样的:struct student tp[10]; 这就定义了一个结构体数组,共有 10 个元素,每个元素都是一个结构体变量,都包含所有的结构体成员。
结构体数组的初始化与前面讲的数值型数组的初始化也是一样的,数值型数组初始化的方法和需要注意的问题在结构体数组的初始化中同样适用,因为不管是数值型数组还是结构体数组都是数组。
//例子: //寻找学生中 学号最大的# include 《stdio.h》# include 《string.h》struct STU
{
char name[20];
int age;
char sex[20];
char num[20];
};
void OutputSTU(struct STU stu[]); //函数声明, 该函数的功能是输出成绩最大的学生信息int main(void)
{
int i;
struct STU stu[5];
for (i = 0; i 《 2; ++i)
{
printf(”请按照名字、年龄、性别、学号(1-9数字)输入第%d个学生的信息:“, i + 1);
scanf(”%s %d %s %s“, stu[i].name, &stu[i].age, stu[i].sex, stu[i].num);/*%c前面要加空格, 不然输入时会将空格赋给%c*/
}
OutputSTU(stu);
return 0;
}
void OutputSTU(struct STU stu[])
{
struct STU stumax = stu[0];//让临时结构stumax保存第一个学生的信息
int j;
for (j = 1; j 《 2; ++j)//第一个学生依次和后面的学生比较
{
if (strcmp(stumax.num, stu[j].num) 《 0) //strcmp函数的使用 s1》s2:1 s1《s2:-1
{
stumax = stu[j];//让临时结构保存那个学生的信息
}
}
printf(”学生姓名:%s 学生年龄:%d 学生性别:%s 学生分数:%s
“, stumax.name, stumax.age, stumax.sex, stumax.num);
}
结构体指针
和数组不同,结构变量的名字并不是结构变量的地址,必须使用&运算符 strcut node *tp=&nb; 指针一般用-》访问结构体里边的成员
指针变量非常灵活方便,可以指向任一类型的变量 ,若定义指针变量指向结构体类型变量,则可以通过指针来引用结构体类型变量。
这里说明:结构体和结构体变量是两个不同的概念:结构体是一种数据类型,是一种创建变量的模板,编译器不会为它分配内存空间,就像 int、float、char 这些关键字本身不占用内存一样;结构体变量才包含实实在在的数据,才需要内存来存储。所以用一个结构体去取一个结构体名的地址,这种写法是错误的,也不能将它赋值给其他变量。
#include《stdio.h》struct point {
int x;
int y;
};
struct point *gt(struct point*p);//结构指针函数void print(const struct point *p);//结构指针void out(struct point p);//普通的结构体做函数参数int main(void) {
struct point y = { 0,0 };//以point结构定义一个y的结构变量
//以下三种调用 等价
//注意gt是一个结构体的指针函数
gt(&y); //这是一个函数的返回结果函数 //取y结构的地址传入函数
out(y);
out(*gt(&y)); // (里边)的都是做为参数 *gt(&y)做为指针返回值 这个函数它的返回用指针表示
print(gt(&y)); //gt(&y)是一个返回值 这样表示的是利用gt函数的返回值在print函数里边操作
//*get(&y) = (struct point){ 1,2 }; //这也可以做的
}
struct point* gt(struct point*p) {// *p要的是&y的地址
scanf(”%d“, &p-》x);
scanf(”%d“, &p-》y);
printf(”a=%d,%d
“, p-》x, p-》y);//用-》来访问指针结构里边的成员
return p;// 用完指针后 返回指针
}
void out(struct point p) {
printf(”b=%d,%d
“, p.x, p.y);
}
void print(const struct point *p) {//加上const表示不再改动参数
printf(”c=%d,%d
“, p-》x, p-》y);
}
指向结构体数组的指针:
在之前讲数值型数组的时候可以将数组名赋给一个指针变量,从而使该指针变量指向数组的首地址,然后用指针访问数组的元素。结构体数组也是数组,所以同样可以这么做。我们知道,结构体数组的每一个元素都是一个结构体变量。如果定义一个结构体指针变量并把结构体数组的数组名赋给这个指针变量的话,就意味着将结构体数组的第一个元素,即第一个结构体变量的地址,也即第一个结构变量中的第一个成员的地址赋给了这个指针变量
typedef 别名
typedef是在编程语言中用来为复杂的声明定义简单的别名,新的名字是某种类型的别名,这样做改善了程序的可读性,它与宏定义有些差异。它本身是一种存储类的关键字,与auto、extern、mutable、static、register等关键字不能出现在同一个表达式中。
typedef为C语言的关键字,功能是用来声明一个已有的数据类型的新名字,比如 typedef int last ; 这就使得last成为 int 类型的别名 这样last这个名字就可以代替int出现在变量定义和参数声明的地方了
typedef也有一个特别的长处:它符合范围规则,使用typedef定义的变量类型其作用范围限制在所定义的函数或者文件内(取决于此变量定义的位置),而宏定义则没有这种特性。
结构体的内存对齐方式(存储空间)
结构体内存对齐:一个结构体变量定义完之后,其在内存中的存储并不等于其所包含元素的宽度之和,元素是按照定义顺序一个一个放到内存中去的,但并不是紧密排列的。从结构体存储的首地址开始,每个元素放置到内存中时,它都会认为内存是按照自己的大小来划分的,因此元素放置的位置一定会在自己宽度的整数倍上开始。
内存对齐可以大大提升内存访问速度,是一种用空间换时间的方法。内存不对齐会导致每次读取数据都会读取两次,使得内存读取速度减慢。
cpu把内存当成是一块一块的,块的大小可以是2,4,8,16 个字节,因此CPU在读取内存的时候是一块一块进行读取的,块的大小称为内存读取粒度。
如果结构体内存在长度大于处理器位数的元素,那么就以处理器的倍数为对齐单位;否则,如果结构体内的元素的长度都小于处理器的倍数的时候,便以结构体里面最长的数据元素为对齐单位。
另外 结构体的内存地址就是它第一个成员变量的地址 isa永远都是结构体中的第一个成员变量 所以结构体的地址也就是其isa指针的地址
内存对齐简介
由于内存的读取时间远远小于CPU的存储速度,这里用设定数据结构的对齐系数,即牺牲空间来换取时间的思想来提高CPU的存储效率。
内存对齐”应该是编译器的“管辖范围”。编译器为程序中的每个“数据单元”安排在适当的位置上。但是C语言的一个特点就是太灵活,太强大,它允许你干预“内存对齐”。如果你想了解更加底层的秘密,“内存对齐”对你就不应该再模糊了。这也是一个大小端模式的问题
每个特定平台上的编译器都有自己的默认“对齐系数”(也叫对齐模数)。程序员可以通过预编译命令#pragma pack(n)来改变这一系数,其中的n就是你要指定的“对齐系数”。
规则:
1、数据成员对齐规则:结构(struct)(或联合(union))的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员的对齐「按照#pragma pack指定的数值和这个数据成员自身长度中,比较小的那个进行」。
2、结构(或联合)的整体对齐规则:在数据成员完成各自对齐之后,结构(或联合)本身也要进行对齐,对齐将「按照#pragma pack 指定的数值和结构(或联合) 最大数据成员长度中,比较小的那个进行」对齐。
3、结合1、2可推断:当#pragma pack的n值等于或超过所有数据成员长度的时候,这个n值的大小将不产生任何效果。
#pragma pack(n) 设定变量以n字节为对齐方式:
「作用」:指定结构体、联合以及类成员
「语法」:#pragma pack( [show] | [push | pop] [, identifier], n )
1,pack提供数据声明级别的控制,对定义不起作用;
2,调用pack时不指定参数,n将被设成默认值;
n:可选参数;指定packing的数值,以字节为单位;缺省数值是8,合法的数值分别是1、2、4、8、16。其他参数都是可选的可先不了解
每个成员分别对齐,即每个成员按自己的方式对齐,并最小化长度;规则就是每个成员按其类型的对齐参数(通常是这个类型的大小)和指定对齐参数中较小的一个对齐。
大小端:
如:int 11 22 33 44
在存储的时候
大端:11 22 33 44
0 1 2 3
低地址----》 高地址
小端:44 33 22 11
0 1 2 3
低地址----》 高地址
大小端的差异在于存放顺序不同
常见的操作系统是小端,通讯协议是大端。
//结构体例子:使用尾插法创建链表#include《stdio.h》//单链表的创建typedef struct _node {
int nb;//数值
struct _node *nxte;//定义一个指向下一个的节点的指针
}NODE;
typedef struct _link{//利用这个结构体 封装 首尾节点
NODE *head;
NODE *qt;
}link;
void add(link *phead, link *qt, int n);//定义函数将 首尾指针传入int main(void) {
link head, q;//定义一个结构,连指针都不是的
head.head = q.qt = NULL;//初始化
int n;
for (scanf(”%d“, &n); n != -1; scanf(”%d“, &n)) {
add(&head, &q, n);//将地址 值传入
}
NODE *t;
t = head.head;//利用临时结构将链表输出
for (; t; t = t-》nxte) {
printf(”%d “, t-》nb);
}
return 0;
}
//尾插法void add(link *phead, link *qt, int n) {
NODE *p = (NODE*)malloc(sizeof(NODE));//为新结点开辟空间
p-》nb = n;
p-》nxte = NULL;
if (phead-》head == NULL) {//判断首结点是否为空
phead-》head = p;//是空的就让首结点等于新结点
}
else {//不为空时,让尾结点依次跑到后面去
qt-》qt-》nxte = p;
}
qt-》qt = p;
}
4、union 共用体(联合体)在进行某些算法的C语言编程的时候,需要使几种不同类型的变量存放到同一段内存单元中。也就是使用覆盖技术,几个变量互相覆盖。这种几个不同的变量共同占用一段内存的结构,在C语言中 以关键字union声明的一种数据结构,这种被称作“共用体”类型结构,也叫联合体。
“联合”与“结构”有一些相似之处。但两者有本质上的不同。在结构中各成员有各自的内存空间,一个结构体变量的总长度大于等于各成员长度之和。而在“联合”中,各成员共享一段内存空间,一个联合变量的长度等于各成员中最长的长度。注意这里所谓的共享不是指把多个成员同时装入一个联合变量内,而是指该联合变量可被赋予任一成员值,但每次只能赋一种值,赋入新值则冲去旧值,共用体变量中起作用的成员是最后一次存放的成员,在存入一个新成员后,原有成员就失去作用,共用体变量的地址和它的各成员的地址都是同一地址
一个联合类型必须经过定义之后,才能把变量说明为该联合类型:
注意:1、不能把共用体变量作为函数参数,也不能是函数带回共用体变量,但可以使专用指向共用体变量的指针
2、所有成员占用同一段内存,修改一制个成员会影响其余所有成员。
共用体的访问:共用体访问成员的值时一般使用。运算符,指针时用-》运算符(和结构体是一样的)
typedef union _node {
int a;
double b;
char c;
union _node *p;
}NODE;
int main(void) {
NODE a;//定义变量
NODE t;
a.b;//用。访问
t.p-》a;//指针用-》访问
}
联合的使用规则几乎和结构体strtct的规则用法一样,只不过是内部表示的不同。
补充:
还有一个是无名联合体,它是和无名结构体的工作原理是相同的
#include《stdio.h》//简单的例子#include《string.h》typedef union _node{
int a;
double b;
char c[20];
}NODE;
int main(void) {
NODE a;//这里只定义一个变量
a.a = 666;
printf(”%d
“, a.a);
a.b = 9.99;
printf(”%f
“, a.b);
strcpy(a.c, ”hello world!“);
printf(”%s
“, a.c);
//我们看到,三个都被完整的输出了,因为在同一时刻,只有一个成员是有效的
}
输出:
6669.990000
hellow world!
共用体的作用:
1、节省内存,有两个很长的数据结构,不会同时使用,比如一个表示老师,一个表示学生,如果要统计教师和学生的情况用结构体的话就有点浪费了!用结构体的话,只占用最长的那个数据结构所占用的空间,就足够了!
2、实现不同类型数据之间的类型转换,遇到各种类型的数据共用存储空间,很方便的实现了不同数据类型之间的转换,不需要显示的强制类型转换。
其他:1、确定CPU的模式:大端、小端模式确定
大小端不同,则存储的方式也存在差别,比如int需要4个字节,而char只需要1个字节,根据1个字节所在的具体位置即可判定CPU的模式
2、寄存器的定义,实现整体的访问和单项的访问//共用体综合例子:根据输入的数据类型输出需要的相应的数据#include《stdio.h》#include《string.h》//数据类型输出 5*4 m n n的第几个x union node {
int a;
double b;
char c[30];
}add[10000];
char p[10000][30]; //保存的字符串数组int main(void) {
int n, m;
scanf(”%d %d“, &n, &m);
int x;
double y;
char t[50];
int i, j;
for (i = 0; i 《 n; i++) {//输入
scanf(”%s“, &p[i]);//作为字符串数组,需要取地址
if (strcmp(”INT“, p[i]) == 0) {//整形
scanf(”%d“, &x);
add[i].a = x;
}
else if(strcmp(”DOUBLE“,p[i])==0){//浮点
scanf(”%lf“, &y);
add[i].b = y;
}
else if (strcmp(”STRCING“, p[i]) == 0) {//字符串
scanf(”%s“, t);
strcpy(add[i].c, t);
}
}
for (i = 0; i 《 m; i++) {//输出
scanf(”%d“, &j);
if (strcmp(”INT“, p[j]) == 0) {
printf(”%d
“, add[j].a);
}
else if (strcmp(”DOUBLE“, p[j]) == 0)
{
printf(”%f
“, add[j].b);
}else if(strcmp(”STRING“,p[j])==0)
{
printf(”%s
“, add[j].c);
}
}
return 0;
}
//输入:/*
5 4
INT 456
DOUBLE 123.56
DOUBLE 0.476
STRING welcomeToC
STRING LemonTree
0
1
2
4
*///输出:/*
456
123.56
0.48
LemonTree
*/
编辑:jq
-
结构体-共用体和用户定义类型2018-01-31 3050
-
漫谈C语言结构体2018-11-15 4406
-
什么是C语言共用体?2019-10-25 1666
-
结构体与共用体的区别2021-07-20 1549
-
C语言的结构体和共用体在单片机中的妙用是什么2021-11-30 1090
-
怎样去使用C语言的结构体和共用体呢2022-01-17 1230
-
联合体/共用体的使用方法2022-02-28 1006
-
共用体和结构体的区别2017-11-19 38627
-
C语言程序设计教程之结构体与共用体的详细资料说明2019-03-01 1538
-
C语言的结构体和共用体在单片机中的妙用2021-11-20 829
-
一招搞定——结构体、共用体和枚举2022-01-14 533
-
C语言-枚举、共用体2022-09-09 2160
-
什么是C语言共用体类型2023-03-24 1660
-
详解C/C++结构体、联合体和枚举的区别与内存对齐2023-06-08 8804
-
C语言必备知识共用体2023-11-29 1953
全部0条评论

快来发表一下你的评论吧 !
