

胶囊网络在小样本做文本分类中的应用(下)
描述
论文提出Dynamic Memory Induction Networks (DMIN) 网络处理小样本文本分类。
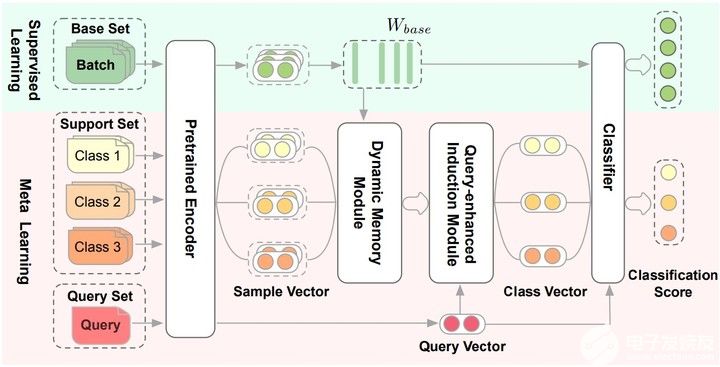
两阶段的(two-stage)few-shot模型:
在监督学习阶段(绿色的部分),训练数据中的部分类别被选为base set,用于finetune预训练Encoder和分类器也就是Pretrained Encoder和Classfiier图中的部分。
在元学习阶段(红色的部分),数据被构造成一个个episode的形式用于计算梯度和更新模型参数。对于C-way K-shot,一个训练episode中的Support Set是从训练数据中随机选择C个类别,每个类别选择K个实例构成的。每个类别剩下的样本就构成Query Set。也就是在Support Set上训练模型,在Query Set上计算损失更新参数。
Pretrained Encoder
用[CLS]预训练的句子的Bert-base Embedding来做fine-tune。$W_{base}$ 就作为元学习的base特征记忆矩阵,监督学习得到的。
Dynamic Memory Module
在元学习阶段,为了从给定的Support Set中归纳出类级别的向量表示,根据记忆矩阵 $W_{base}$ 学习Dynamic Memory Module(动态记忆模块)。

给定一个 $M$ ( $W_{base}$ )和样本向量 q , q 就是一个特征胶囊,所以动态记忆路由算法就是为了得到适应监督信息 $ W_{base} $ 的向量 $q^{'}$ ,
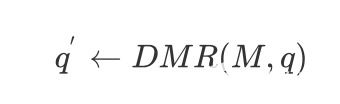
$$ q^{'} \leftarrow DMR(M, q) $$ 学习记忆矩阵 $M$ 中的每个类别向量 $M^{'} $ 进行更新,
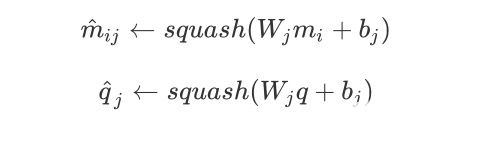
其中
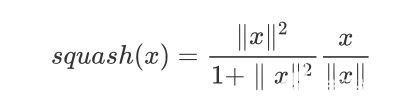
这里的 $W_j$ 就是一个权重。因此变换权重 $W_j$ 和偏差 $b_j$ 在输入时候是可以共享的, 因此计算 $\hat{m}{ij}$ 和 $\hat{q}_j$ 之间的皮尔逊相关系数
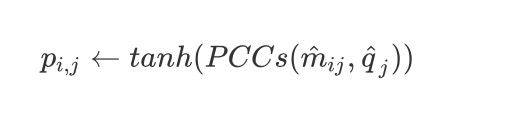
其中
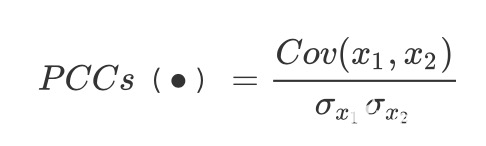
接下来就是进行动态路由算法学习最佳的特征映射(这里添加了$p_{ij}$到路由协议中),到第11行为止。从第12行开始也会根据监督学习的记忆矩阵和胶囊的皮尔逊相关系数来更新$p_{ij}$,最后把部分胶囊
编辑:jq
-
pyhanlp文本分类与情感分析2019-02-20 3404
-
TensorFlow的CNN文本分类2019-10-31 3034
-
NLPIR平台在文本分类方面的技术解析2019-11-18 2434
-
基于文章标题信息的汉语自动文本分类2009-04-13 1441
-
高维小样本分类问题中特征选择研究综述2017-11-27 946
-
深度学习:小样本学习下的多标签分类问题初探2021-01-07 8689
-
文本分类的一个大型“真香现场”来了2021-02-05 2835
-
基于深度神经网络的文本分类分析2021-03-10 2471
-
胶囊网络在短文本多种意图识别的应用及研究2021-04-07 1068
-
基于不同神经网络的文本分类方法研究对比2021-05-13 1409
-
一种为小样本文本分类设计的结合数据增强的元学习框架2021-05-19 5606
-
基于双通道词向量的卷积胶囊网络文本分类算法2021-05-24 1715
-
基于LSTM的表示学习-文本分类模型2021-06-15 1332
-
PyTorch文本分类任务的基本流程2023-02-22 2178
-
卷积神经网络在文本分类领域的应用2024-07-01 2330
全部0条评论

快来发表一下你的评论吧 !
