

语音压缩编码技术的性能分析与比较
描述
引言
Internet的巨大成功。必将使IP成为未来信息网络的支柱技术,以IP为核心的分组化和以移动通信为核心的无线化已成为电信网络演进的主流方向。TCP/IP的网络技术不但无可置疑地成为数据领域的主导技术,而且已经开始进入电信领域,其突破口就是电话业务。
IP网络电话是一项涉及计算机网络、信令协议、数字信号处理等多个领域的综合性技术,它具有价格低廉、可以灵活地提供各种增值业务、有利于企业建立高效综合服务内部网、有利于运营商开拓新的市场、有助于和IP网络新技术的融合、促进网络技术的发展等独特的优势。其中价格低廉是IP电话能够进入市场的首要因素,其根本原因是IP电话均采用语音分组技术、语音压缩编码和统计复用,带宽利用率高,完成一次通信所需的成本大幅度降低。IP电话中的语音处理主要需要解决两个问题:一是在保证一定话音质量的前提下尽可能地降低编码比特率,二是在IP网络环境下保证一定的通话质量。前者正是我们要研究的语音编码技术。
1、语音编码技术
1.1 语音编码技术的分类
根据语音编码的发展过程,把语音编码技术归纳为以下3类:
1.1.1 波形编码
波形编码方式是能够忠实地表现波形的编码方式。语音信号的波形编码力图使重建的语音波形保持原语音信号的波形状态。这类编码器通常是将语音信号作为一般的波形信号来处理,所以它具有适应能力强、话音质量好、抗噪抗误码能力强等特点,但是波形编码所需的编码速率比较高,其速率一般在64 kbit/s~16 kbit/s。其中64 kbit/s PCM的语音编码方式是其中的一个代表。
1.1.2 参数编码
参数编码是根据声音的形成模型,把声音变换成参数的编码方式。其基本方法是通过对语音信号特征参数的提取及编码,力图使重建语音信号具有尽可能高的可懂性,即保持原语音的语义。而重建的信号的波形同原语音信号的波形可能会有相当大的差别。参数编码的最大优点是编码速率低,通常小于 4.8kbit/s,有时可以低至600 bit/s~2.4 kbit/s。缺点是合成语音质量差,自然度较低,对讲话环境噪声较敏感,且时延大。
参数编码的典型例子就是语音信号的线性预测编码(LPC),它已被公认为是目前参数编码中最有效的方法。
1.1.3 混合编码
混合编码结合了以上两种编码方式的优点,采用线性技术构成声道模型,不只传输预测参数和清浊音信息,而且预测误差信息和预测参数同时传输,在接收端构成新的激励去激励预测参数构成的合成滤波器,使得合成滤波器输出的信号波形与原始语声信号的波形最大程度的拟合,从而获得自然度较高的语声。这种编码技术的关键是:如何高效地传输预测误差信息。依据对激励信息的不同处理,这类编码主要有:多脉冲线性预测编码(MPLPC)、规则脉冲激励线性预测编码(RPELPC)、码激励线性预测编码(CELPC)、低时延的码激励线性预测编码(LD-CELPC)。
混合编码克服了原有波形编码器与声码器的弱点,而结合了它们的优点,在4 kbit/s~16 kbit/s速率上能够得到高质量合成语音。在本质上具有波形编码的优点,有一定抗噪和抗误码的性能,但时延较大。
1.2 语音压缩编码的原理
IP网络电话中的语音处理需要解决的一个重要问题就是在保证一定话音质量的前提下,尽可能降低编码比特率。这主要依靠语音编码技术来解决。IP 电话宜使用ITU-T定义的低比特率编码标准,其比特率为5.3 kbit/s~16 kbit/s,均为低复杂度编码算法,话音分组长度在30 ms以下,话音质量较好。从前面列举的几种编码方式也可看出,同一段语音信号,采用不同的编码方式,其编码后的比特率各不相同。那么为什么我们能够对语音信号进行压缩编码从而达到降低语音信号的比特率呢?
1.2.1 利用了语音信号的相关性
语音信源是相关信源,因此经过采样和量化的信号之间还有很强的相关性,为了降低编码速率,人们就希望尽可能多地去除语音信号之间的相关性。线性预测编码技术(LPC)就是一种用来去除语音信号之间相关性的常用技术。语音信号中存在两种类型的相关性:其一是在样点之间短时相关性。语音信号在某些短时段中呈现出随机噪声的特性,在另一些短时段中,则呈现出周期信号的特性,其他一些是二者的混合。简而言之,语音信号的特征是随时间而变化的,只是在一短段时间中,语音信号才保持相对稳定一致的特征,也就是语音信号的短时平稳性。其二是相邻基音周期之间存在的长时相关性。由于语音信号中的短时相关性和长时相关性很强,通过减弱这些相关性,使语音信号之间相关性降低,然后再进行编码,这样就可以实现语音压缩编码,降低比特率。
1.2.2 利用了人耳的听觉特性
利用人耳的掩蔽效应也可以进行语音压缩编码,降低比特率。两个响度不等的声音作用于人耳时,响度较高的频率成分的存在会影响到对响度较低的频率成分的感觉,使其变得不易被察觉,这就是我们所说的掩蔽效应。在语音频谱中,能 量较高的频段即共振峰处的噪声相对于能量较低频段的噪声而言不易被感知。因此在度量原始语音与合成语音之间的误差时可计入这一因素。在语音能量高的频段,允许二者的误差大一些,从而进一步降低编码比特率。为此引入一个频域感觉加权滤波器W(f)来计算二者的误差。感觉加权滤波器的频率响应中的峰、谷值正好与语音谱中相反。所以感觉加权滤波器的作用就是使实际误差信号的谱不再平坦。而是有着与语音信号谱具有相似的包络形状。这就使误差度量的优化过程与感觉上的共振峰对误差的掩蔽效应相吻合,产生较好的主观听觉效果。
1.2.3 线性预测分析——合成编码方法
IP网络电话中所使用的语音信号压缩编码方式大多数是基于合成—分析法的线性预测编码(ABS-LPC)方法,这是一种混合编码方法。线性预测技术就是用过去样点的线性组合来预测当前样点。假如用S(n)代表原始语音信号,用线性预测的方法求出预测器的系统预测系数αi,构成线性预测逆滤波 器,S(n)通过该滤波器后得到了去除短时相关性的语音信号。再将其进行基音预测,建立基音逆滤波器。去除它的长时相关性后,就可得到最后的残差信号。残差信号是完全随机的、不可预测的部分。根据速率的不同要求,可对残差信号采用不同的量化方法,从而得到不同的编码速率,让量化后的残差信号作为激励信号依次通过基音滤波器与线性预测滤波器后,便得到了合成语音信号,见图1。

图1 语音生成模型
编码的过程就是不断改变模型参数,使模型更好地适应原始语音信号。为此又引入了合成分析的概念。同时,利用人耳的掩蔽效应,引入了感觉加权滤波器。综合以上两方面,可以得到图2所示的线性预测分析—合成编码的方框图。
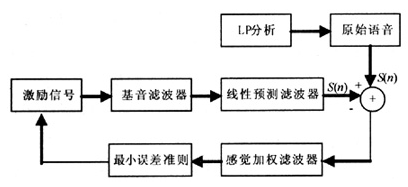
图2 线性预测分析—合成编码方案
合成—分析法的基本原理可以概括如下:假定—原始信号可以用一个模型来表示,这个模型又是由一组参数来决定的,随着这组参数的变化,模型所产生的合成信号就会改变,原始信号与合成信号之间的误差也随之而变化。为了使模型参数能更好地适应原始信号,可以规定一个误差准则:当误差越小,模型合成信号就和原始信号越接近。这样总能找到一组参数,使误差最小,此时这组参数决定的模型就可以使用。一般在编码端配备编码和本地解码两个部分。配备本地解码的目的是完成合成功能,以便计算原始语音信号与合成语音信号之间的误差值。在图2中之所以采用反馈控制,是为了求出最佳模型参数,使合成语音与原始语音在某种准则下最为接近。
基于合成—分析法的线性预测编码的过程实质上就是不断地改变模型参数,使模型更好地适应原始语音信号的过程。原始语音信号被分成帧,帧的长度和模型参数决定了编码速率。
2、IP语音压缩编码算法及性能分析
2.1 常用的语音压缩编码算法
IP电话经常使用ITU定义的两个标准:G.723.1、G.729。它们采用的都是线性预测分析-合成编码和码本激励矢量量化技术,即混合编码的方法。
2.1.1 G.723协议
G.723协议是一个双速率语音编码建议[1],其两种速率分别是5.3 kbit/s和6.3 kbit/s。此协议是一个数字传输系统概况协议,适用于低速率多媒体服务中语音或音频信号的压缩算法。它作为完整的H.324系列标准的一部分,主要配合低速率图像编码H.263标准。在IP电话网关中,G.723协议被用来实现实时语音编码解码处理。
G.723.1协议的编解码算法中两种速率的编解码基本原理是一样的,只是激励信号的量化方法有差别。对高速率(6.3 kbit/s)编码器,其激励信号采用多脉冲最大似然量化(MP-MLQ)法进行量化,对低速率(5.3 kbit/s)编码器,其激励信号采用代数码激励线性预测(ACELP)法量化。
编码过程是首先选速率为64 kbit/s的PCM语音信号转化成均匀量化的PCM信号,然后把输入语音信号的每240个样点组成一个帧,也就是30 ms的帧长。每个帧通过高通滤波器后再分为4个子帧。对于每个子帧,计算出10阶线性预测滤波器的系数。为了适于矢量量化,把预测系数转化为线性频谱对(LSP:line spectrum pair)。量化前的系数构成短时感觉加权滤波器,原始语音信号经过该滤波器得到感觉加权语音信号。对于每两个子帧,编码器用感觉加权语音信号求得开环基音周期,基音周期范围从18个样点到142个样点。此后编码器所进行的操作都是基于60个样点进行的。最后,激励信号被量化,然后把这些参数和激励信号量化结果传送到解码器。由于帧长为30 ms,并存在另外的7.5 ms的前向延迟,导致37.5 ms总的编码延迟。
G.723.1协议是为了低速可视会议业务而设计的。由于可视会议业务每秒钟只传输很少数量的帧,而且又有比较大的时延,这就是G.723.1 允许有30 ms帧长的原因。这个帧长比较大,却正好适合可视会议这种情况。而且它的编码速度比较低,可以把尽可能多的比特用在图像传输上。
2.1.2 G.729协议
G.729协议是一个能在8 kbit/s速率上实现高质量语音编码的建议,也是H.323协议中有关音频编码的标准[2]。在IP电话网关中,G.729协议被用来实现实时语音编码处理。G.729协议采用的是CS-ACELP即共轭结构算术码激励线性预测的算法。CS- ACELP以CELP编码模型为基础,它把语音分成帧,每帧10 ms,也就是80个采样点。对于每一帧语音,编码器从中分析出CELP模型参数,其中包括线性预测系数,自适应码本和随机码本的索引值和增益。然后把这些参数传送到解码端,解码器利用这些参数构成激励源和合成滤波器,从而重现原始语音。
编码过程是首先将速率为64 kbit/s的PCM语音信号转化成均匀量化的PCM信号,通过高通滤波器后,把输入语 音信号的每80个样点组成一个帧,也就是10 ms的帧长。对于每个帧用线性预测法求得LP滤波器系数,为了适于矢量量化,把预测系数转化为LSP。利用合成-分析方法,使原始语音和合成语音之间的误差最小,来获得最佳激励信号。激励信号的量化是通过两个码本来实现的,即自适应码本和随机码本。自适应码本反映的是长时预测结果,也就是基音预测结果。随机码本反映的是经过长时预测和短时预测后的残留信号。
2.2 性能分析与比较
语音编码的主要问题是怎样在编码质量、编码速率、算法复杂度以及抗误码性能、编解码时延等方面求得最佳。这几个因素相互联系,密切相关。下面就这些方面对G.729与G.723.1系统进行分析与比较,并给出了实验的结果[3]。
2.2.1 编码质量
编码质量是衡量语音编码优劣的关键性能之一,对它的评价通常有客观评价与主观评价两种。信噪比是衡量语音编码质量的客观标准。其计算可采用长时信噪比和短时信噪比两种准则。由于在语音信号中小能量占信号能量的比率较小,而恰恰小信号对主观听音效果又有比较大的影响,因此长时信噪比不能反应小能量量化的质量,在语音信号处理中经常采用短时信噪比。设每段有M个语音样点,则第m段的分段信噪比定义为
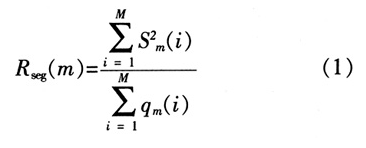
其中分式的分子分母分别表示M个语音样点的总能量和量化噪声的总能量。如果输入语音共有N段,则平均分段信噪比为

此次试验分别对男声、女声、童声以及混声进行了测试,它们得到的信噪比(尤其是时域信噪比)并不很高,然而经过主观评价即MOS(mean opinion score)分评价,它们的听音质量还相对较高,其结果如表1所示,由此说明了基于参数编码与波形编码的语音编码器的不同。
表1 ITU-T语音编码标准的比较
项目 G.729 G.723.1 G.729 annex A
比特率/(kbit/s) 8 5.3/6.3 8
帧大小/ms 10 30 10
头开销/ms 5 1.5 5
MOS 4 3.7 4
出台时间 1995年 1995年 1996年
2.2.2 编码速率
就目前而言,与ITU-T的其他编码标准相比,G.723.1的码速是最低的。它的码率为5.3/6.3 kbit/s,在编码码率方面拥有优势。G.729语音编码速率为8 kbit/s,在编码速率方面仅次于G.723.1,因而它们都较好地解决了通信过程中带宽不足的矛盾,有良好的应用前景。
2.2.3 编解码复杂度
编解码的复杂度与语音编码的质量有密切的关系,在同样的码率下,采用复杂的算法将获得更好的语音质量。表2给出了G.729与G.723.1在硬件实现上所需的资源。G.729在时延方面较G.723.1有优势;在复杂度方面,G.723.1相对G.729较优,但是G.729 annex A却有更大的优势。
表2 G.723.1,G.729与G.729annex A的比较
项目 G.723.1 G.729 G.729 annex A
比特率/(kbit/s) 5.3/6.4 8.0 8.0
帧长/ms 30 10 10
头开销/ms 7.5 5 5
整个编码时延/ms 37.5 15 15
指令/(百万条/s) 16 20 10.5
RAM/byte 2 200 3 000 2 000
2.2.4 抗误码性能
抗误码性能是衡量语音编码质量的因素之一。测试表明,当随机误差为0.1%,G.729编码系统的性能与32 kbit/s G726 ADPCM相当,当误码率为10%,人耳虽能感觉到语音质量的下降,但仍能听懂语音含义;G.723.1抗误码性能与G.729基本相当。
2.2.5 编解码时延
增加算法的复杂度可以提高语音的编码质量。但往往也带来编解码的时延,在实时语音通信中对通话质量有很大影响。对于G.729系统而言由于码率为8kbit/s,每帧80个样点,因此帧大小为10 ms,再加上头开销5ms,整个系统的编解码时延为15ms,大大低于G.723.1的37.5 ms的时延(帧大小为30ms,再加上头开销7.5 ms)。因此在编解码时延方面G.729较G.723.1为优。
3、结论
混合编码中把激励模型和语音的时域波形结合到一起,从而改善了合成语音的质量。以上两种语音压缩编码算法的主要区别在于激励模型的不同。
虽然IP电话目前正处于蒸蒸日上的阶段。但它也存在这样或那样一些不尽如人意的方面。如何提高IP分组语音通信的质量,或者更一般地说,如何在IP网络上实现包括实时通信业务在内的综合业务通信,这正是我们需要进一步研究的。
责任编辑:gt
-
MPEG-2压缩编码技术原理应用2008-05-14 17221
-
视音频压缩编码技术的发展2009-07-29 626
-
图像压缩编码原理2009-09-19 1610
-
数字压缩编码技术2010-01-27 934
-
matlab压缩编码效率很高的静止图像压缩编码算法SPIHT2010-02-08 724
-
IP网络电话中常用的语音压缩编码技术的性能分析2010-07-22 809
-
AMBE-2000TM语音压缩编码电路分析2010-07-06 3146
-
图像压缩编码和解码原理2010-09-27 4848
-
H.264与MPEG-4压缩编码标准的分析与比较2011-09-02 1422
-
JPEG压缩编码标准2016-02-18 990
-
使用FPGA实现MELP语音压缩编码器的详细资料说明2021-01-22 1453
-
基于DCT快速变换的图像压缩编码算法_张爱华2021-07-26 1159
-
DCT的图像压缩编码算法的MATLAB实现2021-09-23 1145
-
统计压缩编码机理分析(上篇)2022-12-21 2414
-
统计压缩编码机理分析(下篇)2022-12-26 2097
全部0条评论

快来发表一下你的评论吧 !
