

你们知道什么是叶脊网络吗
描述
今天这个故事,要从67年前开始说起。
1953年,贝尔实验室有一位名叫Charles Clos的研究员,发表了一篇名为《A Study of Non-blocking Switching Networks》的文章,介绍了一种“用多级设备来实现无阻塞电话交换”的方法。
自从1876年电话被发明之后,电话交换网络历经了人工交换机、步进制交换机、纵横制交换机等多个阶段。20世纪50年代,纵横制交换机处于鼎盛时期。
纵横交换机的核心,是纵横连接器。如下图所示:

纵横制接线器
这种交换架构,是一种开关矩阵,每个交点(Crosspoint)都是一个开关。交换机通过控制开关,来完成从输入到输出的转发。
可以看出,开关矩阵很像一块布的纤维。所以,交换机的内部架构,被称为Switch Fabric。Fabric,就是“纤维、布料”的意思。
Fabric这个词,我相信所有核心网工程师和数通工程师都非常熟悉。“Fabric平面”、“Fabric总线”等概念,经常出现在工作中。
随着电话用户数量急剧增加,网络规模快速扩大,基于crossbar模型的交换机在能力和成本上都无法满足要求。于是,才有了文章开头Charles Clos的那篇研究文章。
Charles Clos提出的网络模型,核心思想是:用多个小规模、低成本的单元,构建复杂、大规模的网络。例如下图:
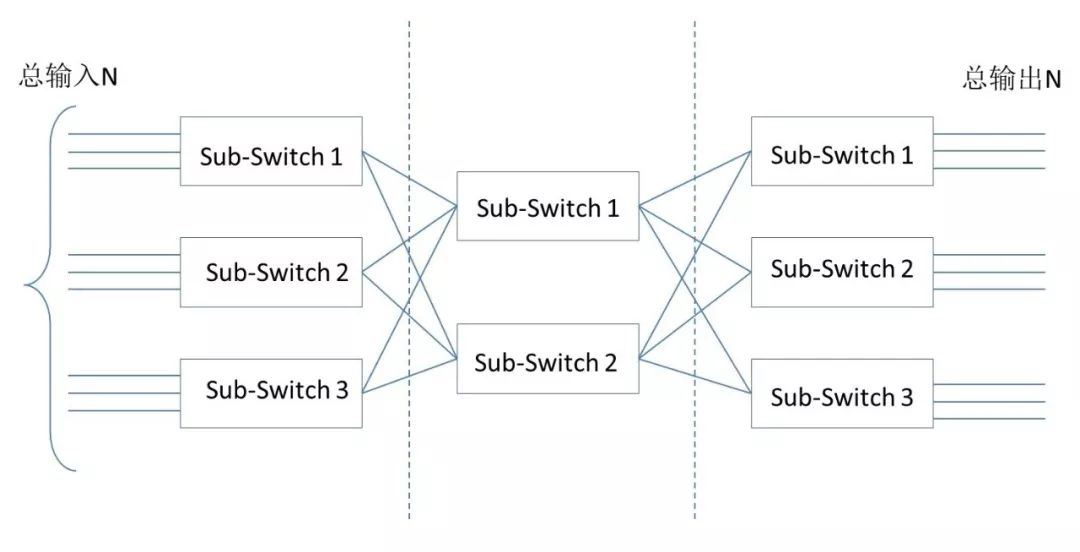
图中的矩形,都是低成本的转发单元。当输入和输出增加时,中间的交叉点并不需要增加很多。
这种模型,就是后来产生深远影响的CLOS网络模型。
到了80年代,随着计算机网络的兴起,开始出现了各种网络拓扑结构,例如星型、链型、环型、树型。
树型网络逐渐成为主流,大家也非常熟悉。
传统的树型网络,带宽是逐级收敛的。什么是收敛呢?物理端口带宽一致,二进一出,不就1:2的收敛了嘛。
2000年之后,互联网从经济危机中复苏,以谷歌和亚马逊为代表的互联网巨头开始崛起。他们开始推行云计算技术,建设大量的数据中心(IDC),甚至超级数据中心。
面对日益庞大的计算规模,传统树型网络肯定是不行的了。于是,一种改进型树型网络开始出现,它就是胖树(Fat-Tree)架构。
胖树(Fat-Tree)就是一种CLOS网络架构。
相比于传统树型,胖树(Fat-Tree)更像是真实的树,越到树根,枝干越粗。从叶子到树根,网络带宽不收敛。
胖树架构的基本理念是:使用大量的低性能交换机,构建出大规模的无阻塞网络。对于任意的通信模式,总有路径让他们的通信带宽达到网卡带宽。
胖树架构被引入到数据中心之后,数据中心变成了传统的三层结构:
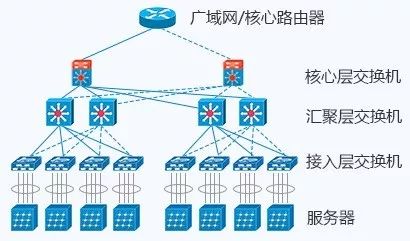
接入层:用于连接所有的计算节点。通常以机柜交换机(TOR,Top of Rack,柜顶交换机)的形式存在。
汇聚层:用于接入层的互联,并作为该汇聚区域二三层的边界。各种防火墙、负载均衡等业务也部署于此。
核心层:用于汇聚层的的互联,并实现整个数据中心与外部网络的三层通信。
在很长的一段时间里,三层网络结构在数据中心十分盛行。在这种架构中,铜缆布线是主要的布线方式,使用率达到了80%。而光缆,只占了20%。
用着用着,人们发现,传统三层架构有很多的缺点。
首先,是资源的浪费。
传统三层结构中,一台下层交换机会通过两条链路与两台上层交换机互连。
由于采用的是STP协议( Spanning Tree Protocol,生成树协议),实际承载流量的只有一条。其它上行链路,是被阻塞的(只用于备份)。这就造成了带宽的浪费。
其次,是故障域比较大。
STP协议由于其本身的算法,在网络拓扑发生变更时需要重新收敛,容易发生故障,从而影响整个VLAN的网络。
第三点,也是最重要的一点——随着时间推移,数据中心的流量走向发生了巨大变化。
2010年之后,为了提高计算和存储资源的利用率,所有的数据中心都开始采用虚拟化技术。网络中开始出现了大量的虚拟机(VM,Virtual Machine)。
与此同时,微服务架构开始流行,很多软件开始推行功能解耦,单个服务变成了多个服务,部署在不同的虚拟机上。虚拟机之间的流量,大幅增加。
这种平级设备之间的数据流动,我们称之为“东西向流量”。
相对应的,那种上上下下的垂直数据流动,称为“南北向流量”。这个很容易理解,“上北下南,左西右东”嘛。
东西向流量,其实也就是一种“内部流量”。这种数据流量的大幅增加,给传统三层架构带来了很大的麻烦——因为服务器和服务器之间的通信,需要经过接入交换机、汇聚交换机和核心交换机。
这意味着,核心交换机和汇聚交换机的工作压力不断增加。要支持大规模的网络,就必须有性能最好、端口密度最大的汇聚层核心层设备。这样的设备成本高,价格非常昂贵。
于是乎,网络工程师们提出了“Spine-Leaf网络架构”,也就是我们今天的主角——叶脊网络(有时候也被称为脊叶网络)。Spine的中文意思是脊柱,Leaf是叶子。
叶脊网络架构,和胖树结构一样,同属于CLOS网络模型。
相比于传统网络的三层架构,叶脊网络进行了扁平化,变成了两层架构。如下图所示:
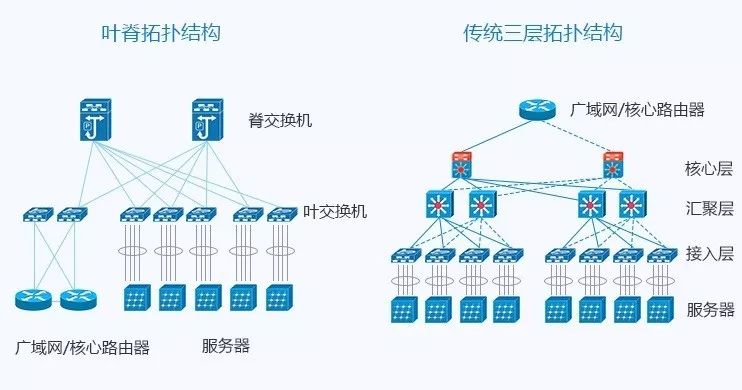
叶交换机,相当于传统三层架构中的接入交换机,作为 TOR(Top Of Rack)直接连接物理服务器。叶交换机之上是三层网络,之下都是个独立的 L2 广播域。如果说两个叶交换机下的服务器需要通信,需要经由脊交换机进行转发。
脊交换机,相当于核心交换机。叶和脊交换机之间通过ECMP(Equal Cost Multi Path)动态选择多条路径。
脊交换机下行端口数量,决定了叶交换机的数量。而叶交换机上行端口数量,决定了脊交换机的数量。它们共同决定了叶脊网络的规模。
叶脊网络的优势非常明显:
1、带宽利用率高每个叶交换机的上行链路,以负载均衡方式工作,充分的利用了带宽。
2、网络延迟可预测在以上模型中,叶交换机之间的连通路径的条数可确定,均只需经过一个脊交换机,东西向网络延时可预测。
3、扩展性好当带宽不足时,增加脊交换机数量,可水平扩展带宽。当服务器数量增加时,增加脊交换机数量,也可以扩大数据中心规模。总之,规划和扩容非常方便。
4、降低对交换机的要求南北向流量,可以从叶节点出去,也可从脊节点出去。东西向流量,分布在多条路径上。这样一来,不需要昂贵的高性能高带宽交换机。
5、安全性和可用性高传统网络采用STP协议,当一台设备故障时就会重新收敛,影响网络性能甚至发生故障。叶脊架构中,一台设备故障时,不需重新收敛,流量继续在其他正常路径上通过,网络连通性不受影响,带宽也只减少一条路径的带宽,性能影响微乎其微。
我们来结合一个案例模型,分析一下叶脊网络的支持能力。
假设一个这样的资源条件:
脊交换机数量:16台 每个脊交换机的上联端口:8个 × 100G每个脊交换机的下联端口:48个 × 25G叶交换机数量:48台每个叶交换机的上联端口:16个 × 25G每个叶交换机的下联端口:64个 × 10G
在理想情况下,这样的叶脊网络总共可支持的服务器数量为:48×64=3072台。(注意,叶脊交换机北向总带宽一般不会和南向总带宽一致,通常大于1:3即可。上例为400:640,有点奢侈了。)
从这个例子也可以看出,叶脊网络带来了一个趋势,那就是对光模块的数量需求大幅增加。
下图就是传统三层架构和叶脊架构所使用光模块数量的对比案例,差别可能达到15-30倍之多。
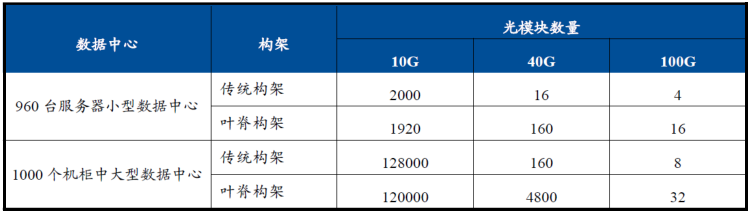
(来自国泰君安证券研究)
正因为如此,资本市场对叶脊网络非常关注,希望借此带动光模块市场的增长,尤其是100G、400G这样的高速率光模块。
叶脊拓扑网络从2013年左右开始出现,发展速度惊人,很快就取代了大量的传统三层网络架构,成为现代数据中心的新宠。
最具有代表性的,是Facebook在2014年公开的数据中心架构。Facebook使用了一个五级CLOS架构,甚至是一个立体的架构。大家有兴趣可以研究一下。
Facebook数据中心架构
除了Facebook之外,谷歌公司的第五代数据中心架构Jupiter也大规模采用了叶脊网络,其可以支持的网络带宽已经达到Pbps级。谷歌数据中心中10万台服务器的每一个,都可以用任意模式以每秒10千兆比特的速度互相通信。
好啦,关于叶脊网络的介绍,今天就到这里。
感谢大家的耐心观看,我们下期再见!
编辑:jq
-
求助脊波网络编程2015-01-12 2315
-
贝叶斯网络精确推理算法的研究2009-08-15 966
-
贝叶斯网络分析2017-03-31 1584
-
脊叶网络架构下的布线是怎样的2020-01-02 1849
-
脊叶网络架构下的布线系统说明2020-12-25 1088
-
叶脊网络Spine-Leaf架构布线方式的说明2021-12-23 7392
-
Underlay网络之叶脊网络介绍2023-02-23 2864
-
SDN系统方法-叶棘网络2023-06-15 1278
-
网络布局与光模块配置需求深度解析2024-04-01 3206
全部0条评论

快来发表一下你的评论吧 !
