

一篇让你熟练掌握 MyBatis-Plus!
电子说
描述
MyBatis-plus 是一款 Mybatis 增强工具,用于简化开发,提高效率。下文使用缩写 mp来简化表示 MyBatis-plus,本文主要介绍 mp 搭配 Spring Boot 的使用。
注:本文使用的 mp 版本是当前最新的3.4.2,早期版本的差异请自行查阅文档
官方网站:baomidou.com/
快速入门
1.创建一个Spring Boot项目。
2.导入依赖
《?xml version=“1.0” encoding=“UTF-8”?》
《project xmlns=“http://maven.apache.org/POM/4.0.0” xmlns:xsi=“http://www.w3.org/2001/XMLSchema-instance”
xsi:schemaLocation=“http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd”》
《modelVersion》4.0.0《/modelVersion》
《parent》
《groupId》org.springframework.boot《/groupId》
《artifactId》spring-boot-starter-parent《/artifactId》
《version》2.3.4.RELEASE《/version》
《relativePath/》
《/parent》
《groupId》com.example《/groupId》
《artifactId》mybatis-plus《/artifactId》
《version》0.0.1-SNAPSHOT《/version》
《name》mybatis-plus《/name》
《properties》
《java.version》1.8《/java.version》
《/properties》
《dependencies》
《dependency》
《groupId》org.springframework.boot《/groupId》
《artifactId》spring-boot-starter《/artifactId》
《/dependency》
《dependency》
《groupId》org.springframework.boot《/groupId》
《artifactId》spring-boot-starter-test《/artifactId》
《scope》test《/scope》
《/dependency》
《dependency》
《groupId》org.springframework.boot《/groupId》
《artifactId》spring-boot-configuration-processor《/artifactId》
《/dependency》
《dependency》
《groupId》com.baomidou《/groupId》
《artifactId》mybatis-plus-boot-starter《/artifactId》
《version》3.4.2《/version》
《/dependency》
《dependency》
《groupId》mysql《/groupId》
《artifactId》mysql-connector-java《/artifactId》
《scope》runtime《/scope》
《/dependency》
《dependency》
《groupId》org.projectlombok《/groupId》
《artifactId》lombok《/artifactId》
《/dependency》
《/dependencies》
《build》
《plugins》
《plugin》
《groupId》org.springframework.boot《/groupId》
《artifactId》spring-boot-maven-plugin《/artifactId》
《/plugin》
《/plugins》
《/build》
《/project》
3.配置数据库
# application.yml
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc//localhost:3306/yogurt?serverTimezone=Asia/Shanghai
username: root
password: root
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl #开启SQL语句打印
4.创建一个实体类
package com.example.mp.po;
import lombok.Data;
import java.time.LocalDateTime;
@Data
public class User {
private Long id;
private String name;
private Integer age;
private String email;
private Long managerId;
private LocalDateTime createTime;
}
5.创建一个mapper接口
package com.example.mp.mappers;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.example.mp.po.User;
public interface UserMapper extends BaseMapper《User》 { }
6.在SpringBoot启动类上配置mapper接口的扫描路径
package com.example.mp;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@MapperScan(“com.example.mp.mappers”)
public class MybatisPlusApplication {
public static void main(String[] args) {
SpringApplication.run(MybatisPlusApplication.class, args);
}
}
7.在数据库中创建表
DROP TABLE IF EXISTS user;
CREATE TABLE user (
id BIGINT(20) PRIMARY KEY NOT NULL COMMENT ‘主键’,
name VARCHAR(30) DEFAULT NULL COMMENT ‘姓名’,
age INT(11) DEFAULT NULL COMMENT ‘年龄’,
email VARCHAR(50) DEFAULT NULL COMMENT ‘邮箱’,
manager_id BIGINT(20) DEFAULT NULL COMMENT ‘直属上级id’,
create_time DATETIME DEFAULT NULL COMMENT ‘创建时间’,
CONSTRAINT manager_fk FOREIGN KEY(manager_id) REFERENCES user (id)
) ENGINE=INNODB CHARSET=UTF8;
INSERT INTO user (id, name, age ,email, manager_id, create_time) VALUES
(1, ‘大BOSS’, 40, ‘boss@baomidou.com’, NULL, ‘2021-03-22 0900’),
(2, ‘李经理’, 40, ‘boss@baomidou.com’, 1, ‘2021-01-22 0900’),
(3, ‘黄主管’, 40, ‘boss@baomidou.com’, 2, ‘2021-01-22 0900’),
(4, ‘吴组长’, 40, ‘boss@baomidou.com’, 2, ‘2021-02-22 0900’),
(5, ‘小菜’, 40, ‘boss@baomidou.com’, 2, ‘2021-02-22 0900’)
8.编写一个SpringBoot测试类
package com.example.mp;
import com.example.mp.mappers.UserMapper;
import com.example.mp.po.User;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.List;
import static org.junit.Assert.*;
@RunWith(SpringRunner.class)
@SpringBootTest
public class SampleTest {
@Autowired
private UserMapper mapper;
@Test
public void testSelect() {
List《User》 list = mapper.selectList(null);
assertEquals(5, list.size());
list.forEach(System.out::println);
}
}
准备工作完成,数据库情况如下:
项目目录如下:
运行测试类
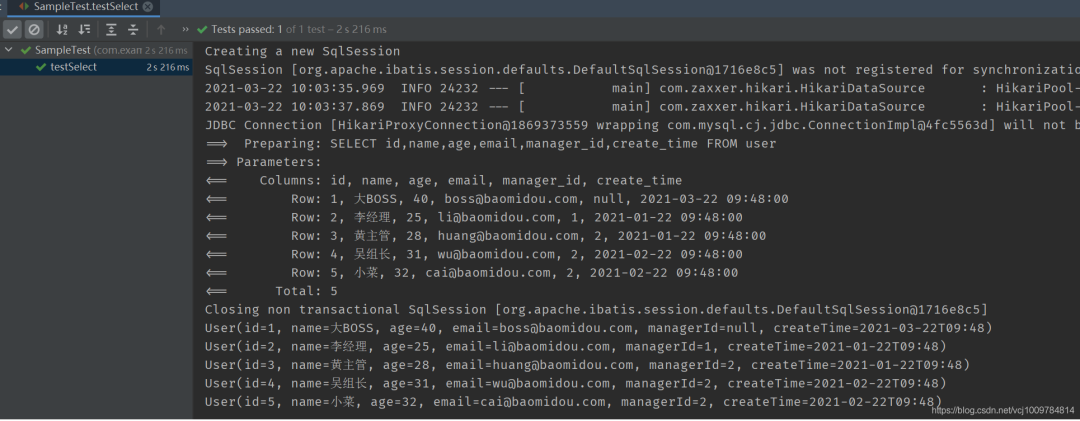
可以看到,针对单表的基本CRUD操作,只需要创建好实体类,并创建一个继承自BaseMapper的接口即可,可谓非常简洁。并且,我们注意到,User类中的managerId,createTime属性,自动和数据库表中的manager_id,create_time对应了起来,这是因为mp自动做了数据库下划线命名,到Java类的驼峰命名之间的转化。
核心功能
注解
mp一共提供了8个注解,这些注解是用在Java的实体类上面的。
@TableName
注解在类上,指定类和数据库表的映射关系。实体类的类名(转成小写后)和数据库表名相同时,可以不指定该注解。
@TableId
注解在实体类的某一字段上,表示这个字段对应数据库表的主键。当主键名为id时(表中列名为id,实体类中字段名为id),无需使用该注解显式指定主键,mp会自动关联。若类的字段名和表的列名不一致,可用value属性指定表的列名。另,这个注解有个重要的属性type,用于指定主键策略。
@TableField
注解在某一字段上,指定Java实体类的字段和数据库表的列的映射关系。这个注解有如下几个应用场景。关于Spring项目中的注解,这篇做了详细介绍:注解介绍
排除非表字段
若Java实体类中某个字段,不对应表中的任何列,它只是用于保存一些额外的,或组装后的数据,则可以设置exist属性为false,这样在对实体对象进行插入时,会忽略这个字段。排除非表字段也可以通过其他方式完成,如使用static或transient关键字,但个人觉得不是很合理,不做赘述
字段验证策略
通过insertStrategy,updateStrategy,whereStrategy属性进行配置,可以控制在实体对象进行插入,更新,或作为WHERE条件时,对象中的字段要如何组装到SQL语句中。
字段填充策略
通过fill属性指定,字段为空时会进行自动填充
@Version
乐观锁注解
@EnumValue
注解在枚举字段上
@TableLogic
逻辑删除
KeySequence
序列主键策略(oracle)
InterceptorIgnore
插件过滤规则
CRUD接口
mp封装了一些最基础的CRUD方法,只需要直接继承mp提供的接口,无需编写任何SQL,即可食用。mp提供了两套接口,分别是Mapper CRUD接口和Service CRUD接口。并且mp还提供了条件构造器Wrapper,可以方便地组装SQL语句中的WHERE条件。
Mapper CRUD接口
只需定义好实体类,然后创建一个接口,继承mp提供的BaseMapper,即可食用。mp会在mybatis启动时,自动解析实体类和表的映射关系,并注入带有通用CRUD方法的mapper。BaseMapper里提供的方法,部分列举如下:
insert(T entity) 插入一条记录
deleteById(Serializable id) 根据主键id删除一条记录
delete(Wrapper《T》 wrapper) 根据条件构造器wrapper进行删除
selectById(Serializable id) 根据主键id进行查找
selectBatchIds(Collection idList) 根据主键id进行批量查找
selectByMap(Map《String,Object》 map) 根据map中指定的列名和列值进行等值匹配查找
selectMaps(Wrapper《T》 wrapper) 根据 wrapper 条件,查询记录,将查询结果封装为一个Map,Map的key为结果的列,value为值
selectList(Wrapper《T》 wrapper) 根据条件构造器wrapper进行查询
update(T entity, Wrapper《T》 wrapper) 根据条件构造器wrapper进行更新
updateById(T entity)
。。。
下面讲解几个比较特别的方法
selectMaps
BaseMapper接口还提供了一个selectMaps方法,这个方法会将查询结果封装为一个Map,Map的key为结果的列,value为值
该方法的使用场景如下:
只查部分列
当某个表的列特别多,而SELECT的时候只需要选取个别列,查询出的结果也没必要封装成Java实体类对象时(只查部分列时,封装成实体后,实体对象中的很多属性会是null),则可以用selectMaps,获取到指定的列后,再自行进行处理即可
比如
@Test
public void test3() {
QueryWrapper《User》 wrapper = new QueryWrapper《》();
wrapper.select(“id”,“name”,“email”).likeRight(“name”,“黄”);
List《Map《String, Object》》 maps = userMapper.selectMaps(wrapper);
maps.forEach(System.out::println);
}
进行数据统计
比如
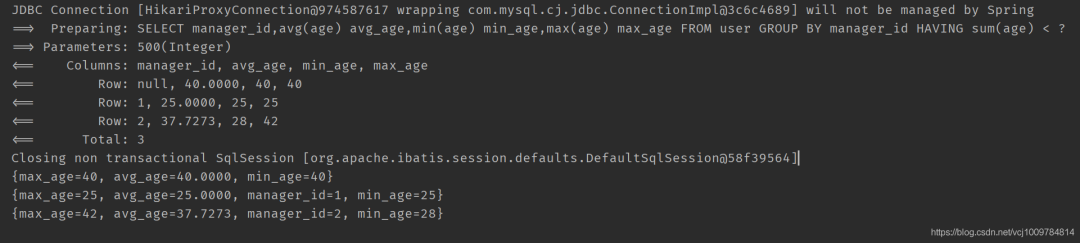
// 按照直属上级进行分组,查询每组的平均年龄,最大年龄,最小年龄
/**
select avg(age) avg_age ,min(age) min_age, max(age) max_age from user group by manager_id having sum(age) 《 500;
**/
@Test
public void test3() {
QueryWrapper《User》 wrapper = new QueryWrapper《》();
wrapper.select(“manager_id”, “avg(age) avg_age”, “min(age) min_age”, “max(age) max_age”)
.groupBy(“manager_id”).having(“sum(age) 《 {0}”, 500);
List《Map《String, Object》》 maps = userMapper.selectMaps(wrapper);
maps.forEach(System.out::println);
}
selectObjs
只会返回第一个字段(第一列)的值,其他字段会被舍弃
比如
@Test
public void test3() {
QueryWrapper《User》 wrapper = new QueryWrapper《》();
wrapper.select(“id”, “name”).like(“name”, “黄”);
List《Object》 objects = userMapper.selectObjs(wrapper);
objects.forEach(System.out::println);
}
得到的结果,只封装了第一列的id
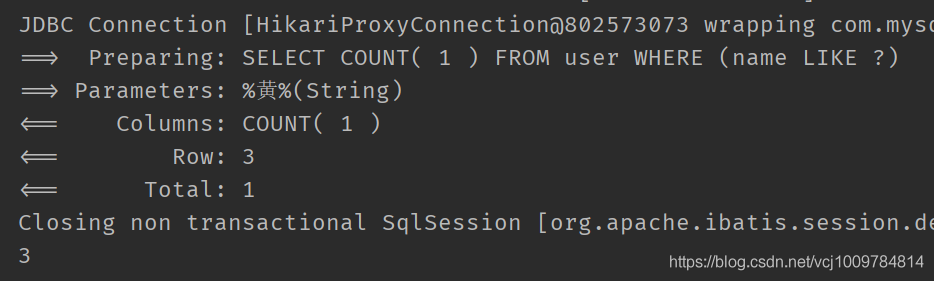
selectCount
查询满足条件的总数,注意,使用这个方法,不能调用QueryWrapper的select方法设置要查询的列了。这个方法会自动添加select count(1)
比如
@Test
public void test3() {
QueryWrapper《User》 wrapper = new QueryWrapper《》();
wrapper.like(“name”, “黄”);
Integer count = userMapper.selectCount(wrapper);
System.out.println(count);
}
Service CRUD 接口
另外一套CRUD是Service层的,只需要编写一个接口,继承IService,并创建一个接口实现类,即可食用。(这个接口提供的CRUD方法,和Mapper接口提供的功能大同小异,比较明显的区别在于IService支持了更多的批量化操作,如saveBatch,saveOrUpdateBatch等方法。
食用示例如下
1.首先,新建一个接口,继承IService
package com.example.mp.service;
import com.baomidou.mybatisplus.extension.service.IService;
import com.example.mp.po.User;
public interface UserService extends IService《User》 {
}
2.创建这个接口的实现类,并继承ServiceImpl,最后打上@Service注解,注册到Spring容器中,即可食用
package com.example.mp.service.impl;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.example.mp.mappers.UserMapper;
import com.example.mp.po.User;
import com.example.mp.service.UserService;
import org.springframework.stereotype.Service;
@Service
public class UserServiceImpl extends ServiceImpl《UserMapper, User》 implements UserService { }
3.测试代码
package com.example.mp;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.example.mp.po.User;
import com.example.mp.service.UserService;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
@RunWith(SpringRunner.class)
@SpringBootTest
public class ServiceTest {
@Autowired
private UserService userService;
@Test
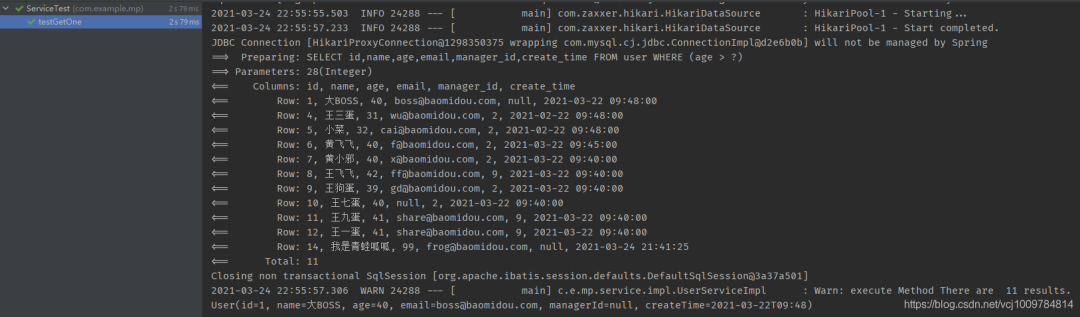
public void testGetOne() {
LambdaQueryWrapper《User》 wrapper = Wrappers.《User》lambdaQuery();
wrapper.gt(User::getAge, 28);
User one = userService.getOne(wrapper, false); // 第二参数指定为false,使得在查到了多行记录时,不抛出异常,而返回第一条记录
System.out.println(one);
}
}
4.结果
另,IService也支持链式调用,代码写起来非常简洁,查询示例如下
@Test
public void testChain() {
List《User》 list = userService.lambdaQuery()
.gt(User::getAge, 39)
.likeRight(User::getName, “王”)
.list();
list.forEach(System.out::println);
}
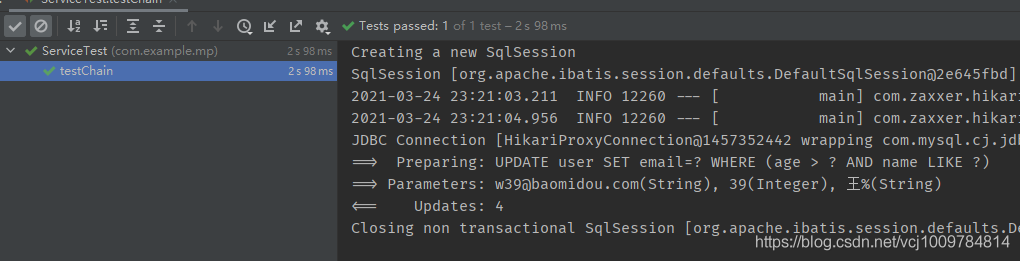
更新示例如下
@Test
public void testChain() {
userService.lambdaUpdate()
.gt(User::getAge, 39)
.likeRight(User::getName, “王”)
.set(User::getEmail, “w39@baomidou.com”)
.update();
}
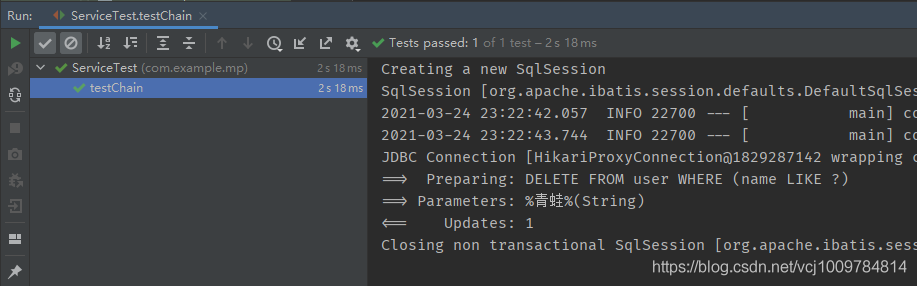
删除示例如下
@Test
public void testChain() {
userService.lambdaUpdate()
.like(User::getName, “青蛙”)
.remove();
}
条件构造器
mp让我觉得极其方便的一点在于其提供了强大的条件构造器Wrapper,可以非常方便的构造WHERE条件。条件构造器主要涉及到3个类,AbstractWrapper。QueryWrapper,UpdateWrapper,它们的类关系如下
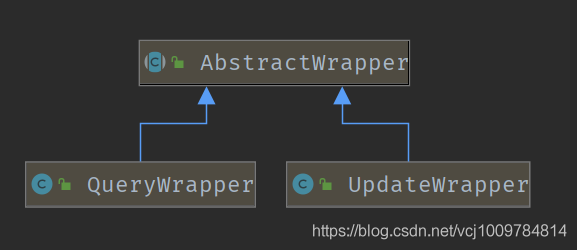
在AbstractWrapper中提供了非常多的方法用于构建WHERE条件,而QueryWrapper针对SELECT语句,提供了select()方法,可自定义需要查询的列,而UpdateWrapper针对UPDATE语句,提供了set()方法,用于构造set语句。条件构造器也支持lambda表达式,写起来非常舒爽。
下面对AbstractWrapper中用于构建SQL语句中的WHERE条件的方法进行部分列举
eq:equals,等于
allEq:all equals,全等于
ne:not equals,不等于
gt:greater than ,大于 》
ge:greater than or equals,大于等于≥
lt:less than,小于《
le:less than or equals,小于等于≤
between:相当于SQL中的BETWEEN
notBetween
like:模糊匹配。like(“name”,“黄”),相当于SQL的name like ‘%黄%’
likeRight:模糊匹配右半边。likeRight(“name”,“黄”),相当于SQL的name like ‘黄%’
likeLeft:模糊匹配左半边。likeLeft(“name”,“黄”),相当于SQL的name like ‘%黄’
notLike:notLike(“name”,“黄”),相当于SQL的name not like ‘%黄%’
isNull
isNotNull
in
and:SQL连接符AND
or:SQL连接符OR
apply:用于拼接SQL,该方法可用于数据库函数,并可以动态传参
。。。。。。。
使用示例
下面通过一些具体的案例来练习条件构造器的使用。(使用前文创建的user表)
// 案例先展示需要完成的SQL语句,后展示Wrapper的写法
// 1. 名字中包含佳,且年龄小于25
// SELECT * FROM user WHERE name like ‘%佳%’ AND age 《 25
QueryWrapper《User》 wrapper = new QueryWrapper《》();
wrapper.like(“name”, “佳”).lt(“age”, 25);
List《User》 users = userMapper.selectList(wrapper);
// 下面展示SQL时,仅展示WHERE条件;展示代码时, 仅展示Wrapper构建部分
// 2. 姓名为黄姓,且年龄大于等于20,小于等于40,且email字段不为空
// name like ‘黄%’ AND age BETWEEN 20 AND 40 AND email is not null
wrapper.likeRight(“name”,“黄”).between(“age”, 20, 40).isNotNull(“email”);
// 3. 姓名为黄姓,或者年龄大于等于40,按照年龄降序排列,年龄相同则按照id升序排列
// name like ‘黄%’ OR age 》= 40 order by age desc, id asc
wrapper.likeRight(“name”,“黄”).or().ge(“age”,40).orderByDesc(“age”).orderByAsc(“id”);
// 4.创建日期为2021年3月22日,并且直属上级的名字为李姓
// date_format(create_time,‘%Y-%m-%d’) = ‘2021-03-22’ AND manager_id IN (SELECT id FROM user WHERE name like ‘李%’)
wrapper.apply(“date_format(create_time, ‘%Y-%m-%d’) = {0}”, “2021-03-22”) // 建议采用{index}这种方式动态传参, 可防止SQL注入
.inSql(“manager_id”, “SELECT id FROM user WHERE name like ‘李%’”);
// 上面的apply, 也可以直接使用下面这种方式做字符串拼接,但当这个日期是一个外部参数时,这种方式有SQL注入的风险
wrapper.apply(“date_format(create_time, ‘%Y-%m-%d’) = ‘2021-03-22’”);
// 5. 名字为王姓,并且(年龄小于40,或者邮箱不为空)
// name like ‘王%’ AND (age 《 40 OR email is not null)
wrapper.likeRight(“name”, “王”).and(q -》 q.lt(“age”, 40).or().isNotNull(“email”));
// 6. 名字为王姓,或者(年龄小于40并且年龄大于20并且邮箱不为空)
// name like ‘王%’ OR (age 《 40 AND age 》 20 AND email is not null)
wrapper.likeRight(“name”, “王”).or(
q -》 q.lt(“age”,40)
.gt(“age”,20)
.isNotNull(“email”)
);
// 7. (年龄小于40或者邮箱不为空) 并且名字为王姓
// (age 《 40 OR email is not null) AND name like ‘王%’
wrapper.nested(q -》 q.lt(“age”, 40).or().isNotNull(“email”))
.likeRight(“name”, “王”);
// 8. 年龄为30,31,34,35
// age IN (30,31,34,35)
wrapper.in(“age”, Arrays.asList(30,31,34,35));
// 或
wrapper.inSql(“age”,“30,31,34,35”);
// 9. 年龄为30,31,34,35, 返回满足条件的第一条记录
// age IN (30,31,34,35) LIMIT 1
wrapper.in(“age”, Arrays.asList(30,31,34,35)).last(“LIMIT 1”);
// 10. 只选出id, name 列 (QueryWrapper 特有)
// SELECT id, name FROM user;
wrapper.select(“id”, “name”);
// 11. 选出id, name, age, email, 等同于排除 manager_id 和 create_time
// 当列特别多, 而只需要排除个别列时, 采用上面的方式可能需要写很多个列, 可以采用重载的select方法,指定需要排除的列
wrapper.select(User.class, info -》 {
String columnName = info.getColumn();
return !“create_time”.equals(columnName) && !“manager_id”.equals(columnName);
});
Condition
条件构造器的诸多方法中,均可以指定一个boolean类型的参数condition,用来决定该条件是否加入最后生成的WHERE语句中,比如
String name = “黄”; // 假设name变量是一个外部传入的参数
QueryWrapper《User》 wrapper = new QueryWrapper《》();
wrapper.like(StringUtils.hasText(name), “name”, name);
// 仅当 StringUtils.hasText(name) 为 true 时, 会拼接这个like语句到WHERE中
// 其实就是对下面代码的简化
if (StringUtils.hasText(name)) {
wrapper.like(“name”, name);
}
实体对象作为条件
调用构造函数创建一个Wrapper对象时,可以传入一个实体对象。后续使用这个Wrapper时,会以实体对象中的非空属性,构建WHERE条件(默认构建等值匹配的WHERE条件,这个行为可以通过实体类里各个字段上的@TableField注解中的condition属性进行改变)
示例如下
@Test
public void test3() {
User user = new User();
user.setName(“黄主管”);
user.setAge(28);
QueryWrapper《User》 wrapper = new QueryWrapper《》(user);
List《User》 users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
执行结果如下。可以看到,是根据实体对象中的非空属性,进行了等值匹配查询。
若希望针对某些属性,改变等值匹配的行为,则可以在实体类中用@TableField注解进行配置,示例如下
package com.example.mp.po;
import com.baomidou.mybatisplus.annotation.SqlCondition;
import com.baomidou.mybatisplus.annotation.TableField;
import lombok.Data;
import java.time.LocalDateTime;
@Data
public class User {
private Long id;
@TableField(condition = SqlCondition.LIKE) // 配置该字段使用like进行拼接
private String name;
private Integer age;
private String email;
private Long managerId;
private LocalDateTime createTime;
}
运行下面的测试代码
@Test
public void test3() {
User user = new User();
user.setName(“黄”);
QueryWrapper《User》 wrapper = new QueryWrapper《》(user);
List《User》 users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
从下图得到的结果来看,对于实体对象中的name字段,采用了like进行拼接

@TableField中配置的condition属性实则是一个字符串,SqlCondition类中预定义了一些字符串以供选择
package com.baomidou.mybatisplus.annotation;
public class SqlCondition {
//下面的字符串中, %s 是占位符, 第一个 %s 是列名, 第二个 %s 是列的值
public static final String EQUAL = “%s=#{%s}”;
public static final String NOT_EQUAL = “%s《》#{%s}”;
public static final String LIKE = “%s LIKE CONCAT(‘%%’,#{%s},‘%%’)”;
public static final String LIKE_LEFT = “%s LIKE CONCAT(‘%%’,#{%s})”;
public static final String LIKE_RIGHT = “%s LIKE CONCAT(#{%s},‘%%’)”;
}
SqlCondition中提供的配置比较有限,当我们需要《或》等拼接方式,则需要自己定义。比如
package com.example.mp.po;
import com.baomidou.mybatisplus.annotation.SqlCondition;
import com.baomidou.mybatisplus.annotation.TableField;
import lombok.Data;
import java.time.LocalDateTime;
@Data
public class User {
private Long id;
@TableField(condition = SqlCondition.LIKE)
private String name;
@TableField(condition = “%s 》 #{%s}”) // 这里相当于大于, 其中 》 是字符实体
private Integer age;
private String email;
private Long managerId;
private LocalDateTime createTime;
}
测试如下
@Test
public void test3() {
User user = new User();
user.setName(“黄”);
user.setAge(30);
QueryWrapper《User》 wrapper = new QueryWrapper《》(user);
List《User》 users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
从下图得到的结果,可以看出,name属性是用like拼接的,而age属性是用》拼接的

allEq方法
allEq方法传入一个map,用来做等值匹配
@Test
public void test3() {
QueryWrapper《User》 wrapper = new QueryWrapper《》();
Map《String, Object》 param = new HashMap《》();
param.put(“age”, 40);
param.put(“name”, “黄飞飞”);
wrapper.allEq(param);
List《User》 users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}

当allEq方法传入的Map中有value为null的元素时,默认会设置为is null
@Test
public void test3() {
QueryWrapper《User》 wrapper = new QueryWrapper《》();
Map《String, Object》 param = new HashMap《》();
param.put(“age”, 40);
param.put(“name”, null);
wrapper.allEq(param);
List《User》 users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
若想忽略map中value为null的元素,可以在调用allEq时,设置参数boolean null2IsNull为false
@Test
public void test3() {
QueryWrapper《User》 wrapper = new QueryWrapper《》();
Map《String, Object》 param = new HashMap《》();
param.put(“age”, 40);
param.put(“name”, null);
wrapper.allEq(param, false);
List《User》 users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
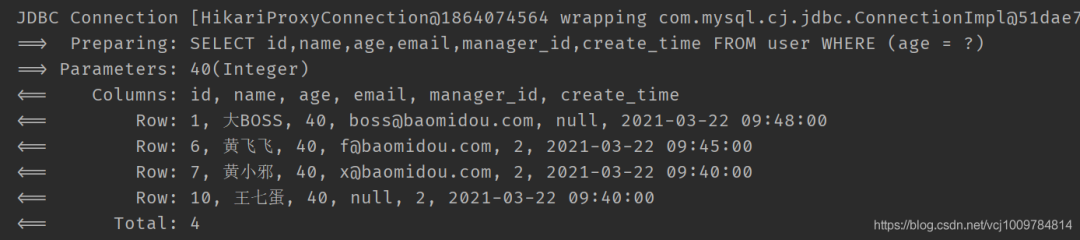
若想要在执行allEq时,过滤掉Map中的某些元素,可以调用allEq的重载方法allEq(BiPredicate《R, V》 filter, Map《R, V》 params)
@Test
public void test3() {
QueryWrapper《User》 wrapper = new QueryWrapper《》();
Map《String, Object》 param = new HashMap《》();
param.put(“age”, 40);
param.put(“name”, “黄飞飞”);
wrapper.allEq((k,v) -》 !“name”.equals(k), param); // 过滤掉map中key为name的元素
List《User》 users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
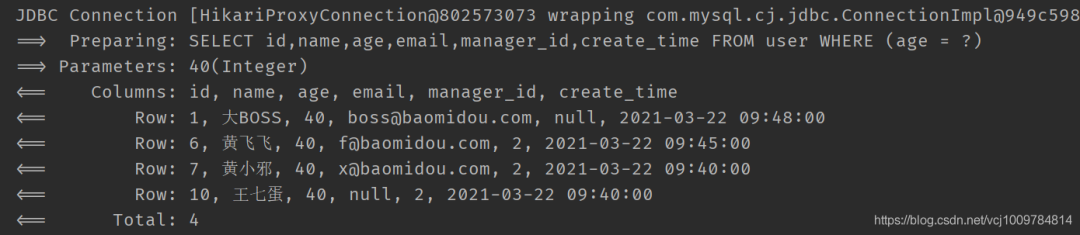
lambda条件构造器
lambda条件构造器,支持lambda表达式,可以不必像普通条件构造器一样,以字符串形式指定列名,它可以直接以实体类的方法引用来指定列。示例如下
@Test
public void testLambda() {
LambdaQueryWrapper《User》 wrapper = new LambdaQueryWrapper《》();
wrapper.like(User::getName, “黄”).lt(User::getAge, 30);
List《User》 users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
像普通的条件构造器,列名是用字符串的形式指定,无法在编译期进行列名合法性的检查,这就不如lambda条件构造器来的优雅。
另外,还有个链式lambda条件构造器,使用示例如下
@Test
public void testLambda() {
LambdaQueryChainWrapper《User》 chainWrapper = new LambdaQueryChainWrapper《》(userMapper);
List《User》 users = chainWrapper.like(User::getName, “黄”).gt(User::getAge, 30).list();
users.forEach(System.out::println);
}
更新操作
上面介绍的都是查询操作,现在来讲更新和删除操作。
BaseMapper中提供了2个更新方法
updateById(T entity)
根据入参entity的id(主键)进行更新,对于entity中非空的属性,会出现在UPDATE语句的SET后面,即entity中非空的属性,会被更新到数据库,示例如下
@RunWith(SpringRunner.class)
@SpringBootTest
public class UpdateTest {
@Autowired
private UserMapper userMapper;
@Test
public void testUpdate() {
User user = new User();
user.setId(2L);
user.setAge(18);
userMapper.updateById(user);
}
}
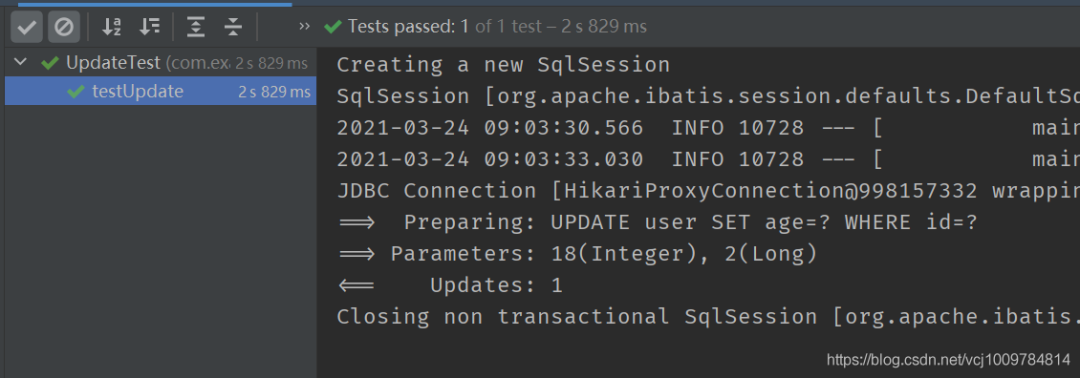
update(T entity, Wrapper《T》 wrapper)
根据实体entity和条件构造器wrapper进行更新,示例如下
@Test
public void testUpdate2() {
User user = new User();
user.setName(“王三蛋”);
LambdaUpdateWrapper《User》 wrapper = new LambdaUpdateWrapper《》();
wrapper.between(User::getAge, 26,31).likeRight(User::getName,“吴”);
userMapper.update(user, wrapper);
}
额外演示一下,把实体对象传入Wrapper,即用实体对象构造WHERE条件的案例
@Test
public void testUpdate3() {
User whereUser = new User();
whereUser.setAge(40);
whereUser.setName(“王”);
LambdaUpdateWrapper《User》 wrapper = new LambdaUpdateWrapper《》(whereUser);
User user = new User();
user.setEmail(“share@baomidou.com”);
user.setManagerId(10L);
userMapper.update(user, wrapper);
}
注意到我们的User类中,对name属性和age属性进行了如下的设置
@Data
public class User {
private Long id;
@TableField(condition = SqlCondition.LIKE)
private String name;
@TableField(condition = “%s 》 #{%s}”)
private Integer age;
private String email;
private Long managerId;
private LocalDateTime createTime;
}
执行结果
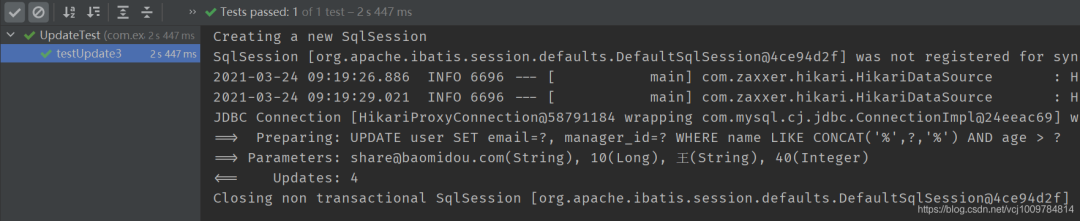
再额外演示一下,链式lambda条件构造器的使用
@Test
public void testUpdate5() {
LambdaUpdateChainWrapper《User》 wrapper = new LambdaUpdateChainWrapper《》(userMapper);
wrapper.likeRight(User::getEmail, “share”)
.like(User::getName, “飞飞”)
.set(User::getEmail, “ff@baomidou.com”)
.update();
}
反思
由于BaseMapper提供的2个更新方法都是传入一个实体对象去执行更新,这在需要更新的列比较多时还好,若想要更新的只有那么一列,或者两列,则创建一个实体对象就显得有点麻烦。针对这种情况,UpdateWrapper提供有set方法,可以手动拼接SQL中的SET语句,此时可以不必传入实体对象,示例如下
@Test
public void testUpdate4() {
LambdaUpdateWrapper《User》 wrapper = new LambdaUpdateWrapper《》();
wrapper.likeRight(User::getEmail, “share”).set(User::getManagerId, 9L);
userMapper.update(null, wrapper);
}
删除操作
BaseMapper一共提供了如下几个用于删除的方法
deleteById 根据主键id进行删除
deleteBatchIds 根据主键id进行批量删除
deleteByMap 根据Map进行删除(Map中的key为列名,value为值,根据列和值进行等值匹配)
delete(Wrapper《T》 wrapper) 根据条件构造器Wrapper进行删除
与前面查询和更新的操作大同小异,不做赘述
自定义SQL
当mp提供的方法还不能满足需求时,则可以自定义SQL。
原生mybatis
示例如下
注解方式
package com.example.mp.mappers;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.example.mp.po.User;
import org.apache.ibatis.annotations.Select;
import java.util.List;
/**
* @Author yogurtzzz
* @Date 2021/3/18 11:21
**/
public interface UserMapper extends BaseMapper《User》 {
@Select(“select * from user”)
List《User》 selectRaw();
}
xml方式
《?xml version=“1.0” encoding=“UTF-8”?》
《!DOCTYPE mapper PUBLIC “-//mybatis.org//DTD Mapper 3.0//EN” “http://mybatis.org/dtd/mybatis-3-mapper.dtd”》
《mapper namespace=“com.example.mp.mappers.UserMapper”》
《select id=“selectRaw” resultType=“com.example.mp.po.User”》
SELECT * FROM user
《/select》
《/mapper》
package com.example.mp.mappers;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.example.mp.po.User;
import org.apache.ibatis.annotations.Select;
import java.util.List;
public interface UserMapper extends BaseMapper《User》 {
List《User》 selectRaw();
}
使用xml时,若xml文件与mapper接口文件不在同一目录下,则需要在application.yml中配置mapper.xml的存放路径
mybatis-plus:
mapper-locations: /mappers/*
若有多个地方存放mapper,则用数组形式进行配置
mybatis-plus:
mapper-locations:
- /mappers/*
- /com/example/mp/*
测试代码如下
@Test
public void testCustomRawSql() {
List《User》 users = userMapper.selectRaw();
users.forEach(System.out::println);
}
结果
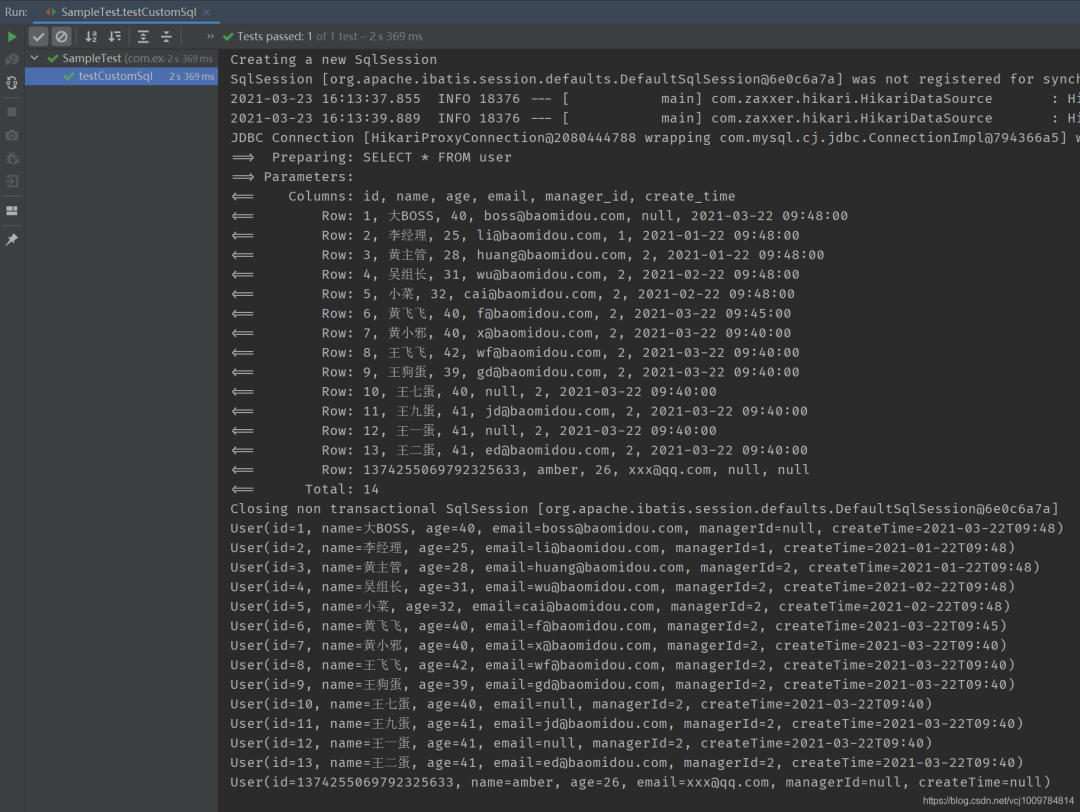
mybatis-plus
也可以使用mp提供的Wrapper条件构造器,来自定义SQL
示例如下
注解方式
package com.example.mp.mappers;
import com.baomidou.mybatisplus.core.conditions.Wrapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.baomidou.mybatisplus.core.toolkit.Constants;
import com.example.mp.po.User;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import java.util.List;
public interface UserMapper extends BaseMapper《User》 {
// SQL中不写WHERE关键字,且固定使用${ew.customSqlSegment}
@Select(“select * from user ${ew.customSqlSegment}”)
List《User》 findAll(@Param(Constants.WRAPPER)Wrapper《User》 wrapper);
}
xml方式
package com.example.mp.mappers;
import com.baomidou.mybatisplus.core.conditions.Wrapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.example.mp.po.User;
import java.util.List;
public interface UserMapper extends BaseMapper《User》 {
List《User》 findAll(Wrapper《User》 wrapper);
}
《?xml version=“1.0” encoding=“UTF-8”?》
《!DOCTYPE mapper PUBLIC “-//mybatis.org//DTD Mapper 3.0//EN” “http://mybatis.org/dtd/mybatis-3-mapper.dtd”》
《mapper namespace=“com.example.mp.mappers.UserMapper”》
《select id=“findAll” resultType=“com.example.mp.po.User”》
SELECT * FROM user ${ew.customSqlSegment}
《/select》
《/mapper》
分页查询
BaseMapper中提供了2个方法进行分页查询,分别是selectPage和selectMapsPage,前者会将查询的结果封装成Java实体对象,后者会封装成Map《String,Object》。分页查询的食用示例如下
1. 创建mp的分页拦截器,注册到Spring容器中
package com.example.mp.config;
import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MybatisPlusConfig {
/** 新版mp **/
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
/** 旧版mp 用 PaginationInterceptor **/
}
2. 执行分页查询
@Test
public void testPage() {
LambdaQueryWrapper《User》 wrapper = new LambdaQueryWrapper《》();
wrapper.ge(User::getAge, 28);
// 设置分页信息, 查第3页, 每页2条数据
Page《User》 page = new Page《》(3, 2);
// 执行分页查询
Page《User》 userPage = userMapper.selectPage(page, wrapper);
System.out.println(“总记录数 = ” + userPage.getTotal());
System.out.println(“总页数 = ” + userPage.getPages());
System.out.println(“当前页码 = ” + userPage.getCurrent());
// 获取分页查询结果
List《User》 records = userPage.getRecords();
records.forEach(System.out::println);
}
3. 结果
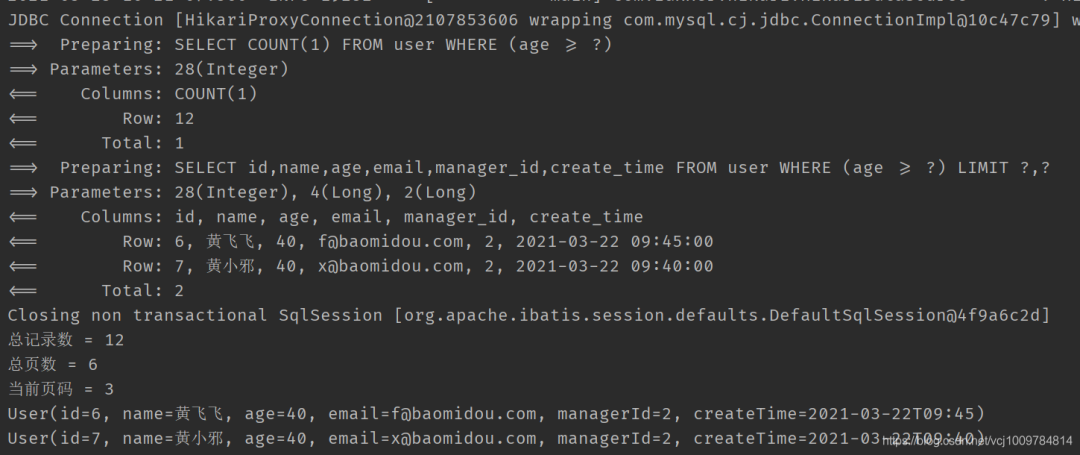
4. 其他
注意到,分页查询总共发出了2次SQL,一次查总记录数,一次查具体数据。若希望不查总记录数,仅查分页结果。可以通过Page的重载构造函数,指定isSearchCount为false即可
public Page(long current, long size, boolean isSearchCount)
在实际开发中,可能遇到多表联查的场景,此时BaseMapper中提供的单表分页查询的方法无法满足需求,需要自定义SQL,示例如下(使用单表查询的SQL进行演示,实际进行多表联查时,修改SQL语句即可)
1. 在mapper接口中定义一个函数,接收一个Page对象为参数,并编写自定义SQL
// 这里采用纯注解方式。当然,若SQL比较复杂,建议还是采用XML的方式
@Select(“SELECT * FROM user ${ew.customSqlSegment}”)
Page《User》 selectUserPage(Page《User》 page, @Param(Constants.WRAPPER) Wrapper《User》 wrapper);
2. 执行查询
@Test
public void testPage2() {
LambdaQueryWrapper《User》 wrapper = new LambdaQueryWrapper《》();
wrapper.ge(User::getAge, 28).likeRight(User::getName, “王”);
Page《User》 page = new Page《》(3,2);
Page《User》 userPage = userMapper.selectUserPage(page, wrapper);
System.out.println(“总记录数 = ” + userPage.getTotal());
System.out.println(“总页数 = ” + userPage.getPages());
userPage.getRecords().forEach(System.out::println);
}
3. 结果
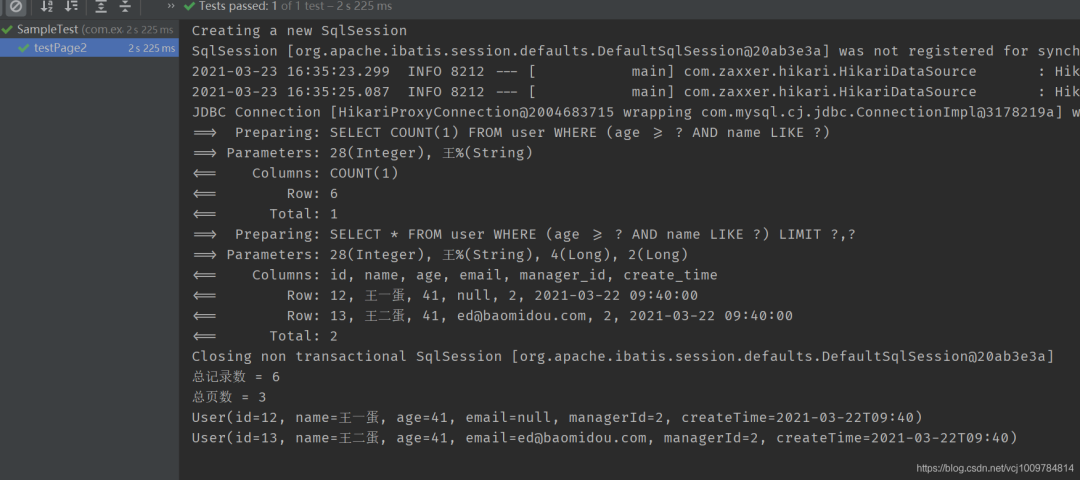
AR模式
ActiveRecord模式,通过操作实体对象,直接操作数据库表。与ORM有点类似。
示例如下
让实体类User继承自Model
package com.example.mp.po;
import com.baomidou.mybatisplus.annotation.SqlCondition;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.extension.activerecord.Model;
import lombok.Data;
import lombok.EqualsAndHashCode;
import java.time.LocalDateTime;
@EqualsAndHashCode(callSuper = false)
@Data
public class User extends Model《User》 {
private Long id;
@TableField(condition = SqlCondition.LIKE)
private String name;
@TableField(condition = “%s 》 #{%s}”)
private Integer age;
private String email;
private Long managerId;
private LocalDateTime createTime;
}
直接调用实体对象上的方法
@Test
public void insertAr() {
User user = new User();
user.setId(15L);
user.setName(“我是AR猪”);
user.setAge(1);
user.setEmail(“ar@baomidou.com”);
user.setManagerId(1L);
boolean success = user.insert(); // 插入
System.out.println(success);
}
结果
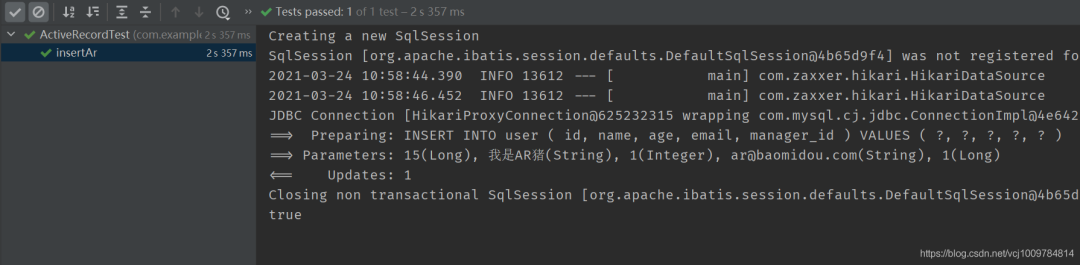
其他示例
// 查询
@Test
public void selectAr() {
User user = new User();
user.setId(15L);
User result = user.selectById();
System.out.println(result);
}
// 更新
@Test
public void updateAr() {
User user = new User();
user.setId(15L);
user.setName(“王全蛋”);
user.updateById();
}
//删除
@Test
public void deleteAr() {
User user = new User();
user.setId(15L);
user.deleteById();
}
主键策略
在定义实体类时,用@TableId指定主键,而其type属性,可以指定主键策略。
mp支持多种主键策略,默认的策略是基于雪花算法的自增id。全部主键策略定义在了枚举类IdType中,IdType有如下的取值
AUTO
数据库ID自增,依赖于数据库。在插入操作生成SQL语句时,不会插入主键这一列
NONE
未设置主键类型。若在代码中没有手动设置主键,则会根据主键的全局策略自动生成(默认的主键全局策略是基于雪花算法的自增ID)
INPUT
需要手动设置主键,若不设置。插入操作生成SQL语句时,主键这一列的值会是null。oracle的序列主键需要使用这种方式
ASSIGN_ID
当没有手动设置主键,即实体类中的主键属性为空时,才会自动填充,使用雪花算法
ASSIGN_UUID
当实体类的主键属性为空时,才会自动填充,使用UUID
。。。。(还有几种是已过时的,就不再列举)
可以针对每个实体类,使用@TableId注解指定该实体类的主键策略,这可以理解为局部策略。若希望对所有的实体类,都采用同一种主键策略,挨个在每个实体类上进行配置,则太麻烦了,此时可以用主键的全局策略。只需要在application.yml进行配置即可。比如,配置了全局采用自增主键策略
# application.yml
mybatis-plus:
global-config:
db-config:
id-type: auto
下面对不同主键策略的行为进行演示
AUTO
在User上对id属性加上注解,然后将MYSQL的user表修改其主键为自增。
@EqualsAndHashCode(callSuper = false)
@Data
public class User extends Model《User》 {
@TableId(type = IdType.AUTO)
private Long id;
@TableField(condition = SqlCondition.LIKE)
private String name;
@TableField(condition = “%s 》 #{%s}”)
private Integer age;
private String email;
private Long managerId;
private LocalDateTime createTime;
}
测试
@Test
public void testAuto() {
User user = new User();
user.setName(“我是青蛙呱呱”);
user.setAge(99);
user.setEmail(“frog@baomidou.com”);
user.setCreateTime(LocalDateTime.now());
userMapper.insert(user);
System.out.println(user.getId());
}
结果
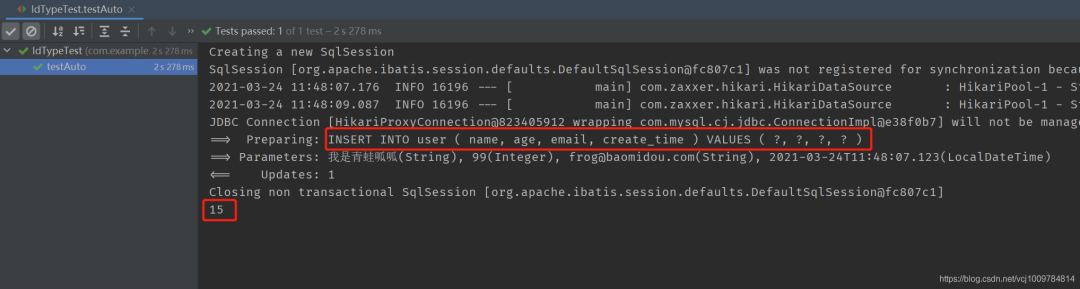
可以看到,代码中没有设置主键ID,发出的SQL语句中也没有设置主键ID,并且插入结束后,主键ID会被写回到实体对象。
NONE
在MYSQL的user表中,去掉主键自增。然后修改User类(若不配置@TableId注解,默认主键策略也是NONE)
@TableId(type = IdType.NONE)
private Long id;
插入时,若实体类的主键ID有值,则使用之;若主键ID为空,则使用主键全局策略,来生成一个ID。
其余的策略类似,不赘述
小结
AUTO依赖于数据库的自增主键,插入时,实体对象无需设置主键,插入成功后,主键会被写回实体对象。
INPUT完全依赖于用户输入。实体对象中主键ID是什么,插入到数据库时就设置什么。若有值便设置值,若为null则设置null
其余的几个策略,都是在实体对象中主键ID为空时,才会自动生成。
NONE会跟随全局策略,ASSIGN_ID采用雪花算法,ASSIGN_UUID采用UUID
全局配置,在application.yml中进行即可;针对单个实体类的局部配置,使用@TableId即可。对于某个实体类,若它有局部主键策略,则采用之,否则,跟随全局策略。
配置
mybatis plus有许多可配置项,可在application.yml中进行配置,如上面的全局主键策略。下面列举部分配置项
基本配置
configLocation:若有单独的mybatis配置,用这个注解指定mybatis的配置文件(mybatis的全局配置文件)
mapperLocations:mybatis mapper所对应的xml文件的位置
typeAliasesPackage:mybatis的别名包扫描路径
。。。。。
进阶配置
mapUnderscoreToCamelCase:是否开启自动驼峰命名规则映射。(默认开启)
dbTpe:数据库类型。一般不用配,会根据数据库连接url自动识别
fieldStrategy:(已过时)字段验证策略。该配置项在最新版的mp文档中已经找不到了,被细分成了insertStrategy,updateStrategy,selectStrategy。默认值是NOT_NULL,即对于实体对象中非空的字段,才会组装到最终的SQL语句中。
有如下几种可选配置
这个配置项,可在application.yml中进行全局配置,也可以在某一实体类中,对某一字段用@TableField注解进行局部配置
这个字段验证策略有什么用呢?在UPDATE操作中能够体现出来,若用一个User对象执行UPDATE操作,我们希望只对User对象中非空的属性,更新到数据库中,其他属性不做更新,则NOT_NULL可以满足需求。
而若updateStrategy配置为IGNORED,则不会进行非空判断,会将实体对象中的全部属性如实组装到SQL中,这样,执行UPDATE时,可能就将一些不想更新的字段,设置为了NULL。
IGNORED:忽略校验。即,不做校验。实体对象中的全部字段,无论值是什么,都如实地被组装到SQL语句中(为NULL的字段在SQL语句中就组装为NULL)。
NOT_NULL:非NULL校验。只会将非NULL的字段组装到SQL语句中
NOT_EMPTY:非空校验。当有字段是字符串类型时,只组装非空字符串;对其他类型的字段,等同于NOT_NULL
NEVER:不加入SQL。所有字段不加入到SQL语句
tablePrefix:添加表名前缀
比如
mybatis-plus:
global-config:
db-config:
table-prefix: xx_
然后将MYSQL中的表做一下修改。但Java实体类保持不变(仍然为User)。
测试
@Test
public void test3() {
QueryWrapper《User》 wrapper = new QueryWrapper《》();
wrapper.like(“name”, “黄”);
Integer count = userMapper.selectCount(wrapper);
System.out.println(count);
}
可以看到拼接出来的SQL,在表名前面添加了前缀
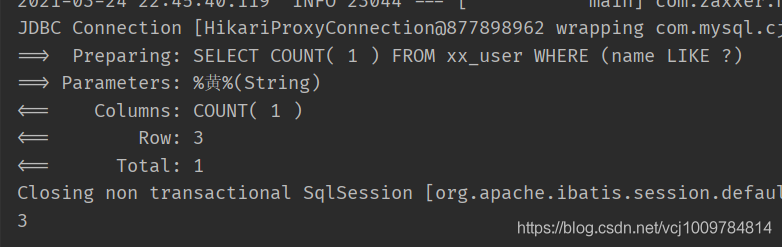
代码生成器
mp提供一个生成器,可快速生成Entity实体类,Mapper接口,Service,Controller等全套代码。代码生成的开源项目:一键生成前后端代码!
示例如下
public class GeneratorTest {
@Test
public void generate() {
AutoGenerator generator = new AutoGenerator();
// 全局配置
GlobalConfig config = new GlobalConfig();
String projectPath = System.getProperty(“user.dir”);
// 设置输出到的目录
config.setOutputDir(projectPath + “/src/main/java”);
config.setAuthor(“yogurt”);
// 生成结束后是否打开文件夹
config.setOpen(false);
// 全局配置添加到 generator 上
generator.setGlobalConfig(config);
// 数据源配置
DataSourceConfig dataSourceConfig = new DataSourceConfig();
dataSourceConfig.setUrl(“jdbc//localhost:3306/yogurt?serverTimezone=Asia/Shanghai”);
dataSourceConfig.setDriverName(“com.mysql.cj.jdbc.Driver”);
dataSourceConfig.setUsername(“root”);
dataSourceConfig.setPassword(“root”);
// 数据源配置添加到 generator
generator.setDataSource(dataSourceConfig);
// 包配置, 生成的代码放在哪个包下
PackageConfig packageConfig = new PackageConfig();
packageConfig.setParent(“com.example.mp.generator”);
// 包配置添加到 generator
generator.setPackageInfo(packageConfig);
// 策略配置
StrategyConfig strategyConfig = new StrategyConfig();
// 下划线驼峰命名转换
strategyConfig.setNaming(NamingStrategy.underline_to_camel);
strategyConfig.setColumnNaming(NamingStrategy.underline_to_camel);
// 开启lombok
strategyConfig.setEntityLombokModel(true);
// 开启RestController
strategyConfig.setRestControllerStyle(true);
generator.setStrategy(strategyConfig);
generator.setTemplateEngine(new FreemarkerTemplateEngine());
// 开始生成
generator.execute();
}
}
运行后,可以看到生成了如下图所示的全套代码
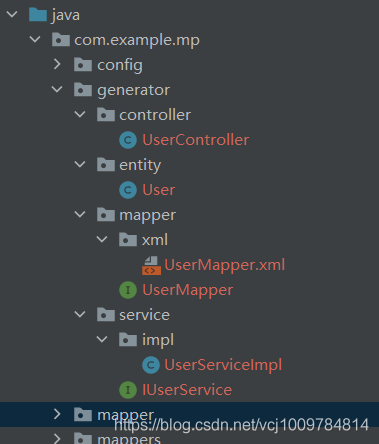
高级功能
高级功能的演示需要用到一张新的表user2
DROP TABLE IF EXISTS user2;
CREATE TABLE user2 (
id BIGINT(20) PRIMARY KEY NOT NULL COMMENT ‘主键id’,
name VARCHAR(30) DEFAULT NULL COMMENT ‘姓名’,
age INT(11) DEFAULT NULL COMMENT ‘年龄’,
email VARCHAR(50) DEFAULT NULL COMMENT ‘邮箱’,
manager_id BIGINT(20) DEFAULT NULL COMMENT ‘直属上级id’,
create_time DATETIME DEFAULT NULL COMMENT ‘创建时间’,
update_time DATETIME DEFAULT NULL COMMENT ‘修改时间’,
version INT(11) DEFAULT ‘1’ COMMENT ‘版本’,
deleted INT(1) DEFAULT ‘0’ COMMENT ‘逻辑删除标识,0-未删除,1-已删除’,
CONSTRAINT manager_fk FOREIGN KEY(manager_id) REFERENCES user2(id)
) ENGINE = INNODB CHARSET=UTF8;
INSERT INTO user2(id, name, age, email, manager_id, create_time)
VALUES
(1, ‘老板’, 40 ,‘boss@baomidou.com’ ,NULL, ‘2021-03-28 1340’),
(2, ‘王狗蛋’, 40 ,‘gd@baomidou.com’ ,1, ‘2021-03-28 1340’),
(3, ‘王鸡蛋’, 40 ,‘jd@baomidou.com’ ,2, ‘2021-03-28 1340’),
(4, ‘王鸭蛋’, 40 ,‘yd@baomidou.com’ ,2, ‘2021-03-28 1340’),
(5, ‘王猪蛋’, 40 ,‘zd@baomidou.com’ ,2, ‘2021-03-28 1340’),
(6, ‘王软蛋’, 40 ,‘rd@baomidou.com’ ,2, ‘2021-03-28 1340’),
(7, ‘王铁蛋’, 40 ,‘td@baomidou.com’ ,2, ‘2021-03-28 1340’)
并创建对应的实体类User2
package com.example.mp.po;
import lombok.Data;
import java.time.LocalDateTime;
@Data
public class User2 {
private Long id;
private String name;
private Integer age;
private String email;
private Long managerId;
private LocalDateTime createTime;
private LocalDateTime updateTime;
private Integer version;
private Integer deleted;
}
以及Mapper接口
package com.example.mp.mappers;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.example.mp.po.User2;
public interface User2Mapper extends BaseMapper《User2》 { }
逻辑删除
首先,为什么要有逻辑删除呢?直接删掉不行吗?当然可以,但日后若想要恢复,或者需要查看这些数据,就做不到了。逻辑删除是为了方便数据恢复,和保护数据本身价值的一种方案。
日常中,我们在电脑中删除一个文件后,也仅仅是把该文件放入了回收站,日后若有需要还能进行查看或恢复。当我们确定不再需要某个文件,可以将其从回收站中彻底删除。这也是类似的道理。
mp提供的逻辑删除实现起来非常简单
只需要在application.yml中进行逻辑删除的相关配置即可
mybatis-plus:
global-config:
db-config:
logic-delete-field: deleted # 全局逻辑删除的实体字段名
logic-delete-value: 1 # 逻辑已删除值(默认为1)
logic-not-delete-value: 0 # 逻辑未删除值(默认为0)
# 若逻辑已删除和未删除的值和默认值一样,则可以不配置这2项
测试代码
package com.example.mp;
import com.example.mp.mappers.User2Mapper;
import com.example.mp.po.User2;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.List;
@RunWith(SpringRunner.class)
@SpringBootTest
public class LogicDeleteTest {
@Autowired
private User2Mapper mapper;
@Test
public void testLogicDel() {
int i = mapper.deleteById(6);
System.out.println(“rowAffected = ” + i);
}
}
结果
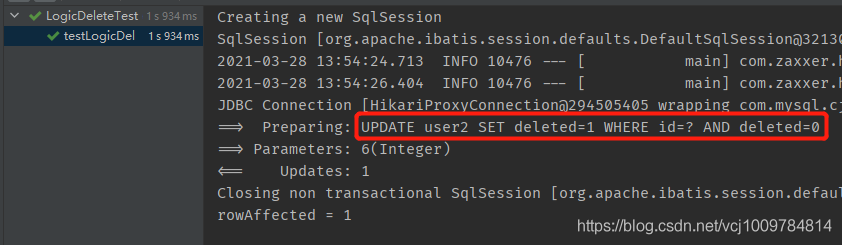
可以看到,发出的SQL不再是DELETE,而是UPDATE
此时我们再执行一次SELECT
@Test
public void testSelect() {
List《User2》 users = mapper.selectList(null);
}
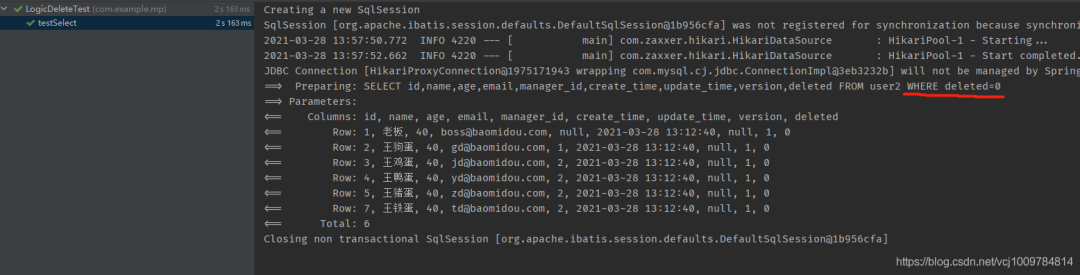
可以看到,发出的SQL语句,会自动在WHERE后面拼接逻辑未删除的条件。查询出来的结果中,没有了id为6的王软蛋。
若想要SELECT的列,不包括逻辑删除的那一列,则可以在实体类中通过@TableField进行配置
@TableField(select = false)
private Integer deleted;
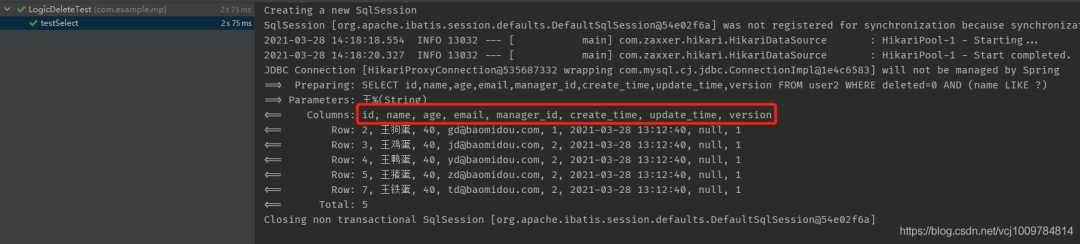
可以看到下图的执行结果中,SELECT中已经不包含deleted这一列了
前面在application.yml中做的配置,是全局的。通常来说,对于多个表,我们也会统一逻辑删除字段的名称,统一逻辑已删除和未删除的值,所以全局配置即可。当然,若要对某些表进行单独配置,在实体类的对应字段上使用@TableLogic即可
@TableLogic(value = “0”, delval = “1”)
private Integer deleted;
小结
开启mp的逻辑删除后,会对SQL产生如下的影响
INSERT语句:没有影响
SELECT语句:追加WHERE条件,过滤掉已删除的数据
UPDATE语句:追加WHERE条件,防止更新到已删除的数据
DELETE语句:转变为UPDATE语句
注意,上述的影响,只针对mp自动注入的SQL生效。如果是自己手动添加的自定义SQL,则不会生效。比如
public interface User2Mapper extends BaseMapper《User2》 {
@Select(“select * from user2”)
List《User2》 selectRaw();
}
调用这个selectRaw,则mp的逻辑删除不会生效。
另,逻辑删除可在application.yml中进行全局配置,也可在实体类中用@TableLogic进行局部配置。
自动填充
表中常常会有“新增时间”,“修改时间”,“操作人” 等字段。比较原始的方式,是每次插入或更新时,手动进行设置。mp可以通过配置,对某些字段进行自动填充,食用示例如下
1. 在实体类中的某些字段上,通过@TableField设置自动填充
public class User2 {
private Long id;
private String name;
private Integer age;
private String email;
private Long managerId;
@TableField(fill = FieldFill.INSERT) // 插入时自动填充
private LocalDateTime createTime;
@TableField(fill = FieldFill.UPDATE) // 更新时自动填充
private LocalDateTime updateTime;
private Integer version;
private Integer deleted;
}
2. 实现自动填充处理器
package com.example.mp.component;
import com.baomidou.mybatisplus.core.handlers.MetaObjectHandler;
import org.apache.ibatis.reflection.MetaObject;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
@Component //需要注册到Spring容器中
public class MyMetaObjectHandler implements MetaObjectHandler {
@Override
public void insertFill(MetaObject metaObject) {
// 插入时自动填充
// 注意第二个参数要填写实体类中的字段名称,而不是表的列名称
strictFillStrategy(metaObject, “createTime”, LocalDateTime::now);
}
@Override
public void updateFill(MetaObject metaObject) {
// 更新时自动填充
strictFillStrategy(metaObject, “updateTime”, LocalDateTime::now);
}
}
测试
@Test
public void test() {
User2 user = new User2();
user.setId(8L);
user.setName(“王一蛋”);
user.setAge(29);
user.setEmail(“yd@baomidou.com”);
user.setManagerId(2L);
mapper.insert(user);
}
根据下图结果,可以看到对createTime进行了自动填充
注意,自动填充仅在该字段为空时会生效,若该字段不为空,则直接使用已有的值。如下
@Test
public void test() {
User2 user = new User2();
user.setId(8L);
user.setName(“王一蛋”);
user.setAge(29);
user.setEmail(“yd@baomidou.com”);
user.setManagerId(2L);
user.setCreateTime(LocalDateTime.of(2000,1,1,8,0,0));
mapper.insert(user);
}

更新时的自动填充,测试如下
@Test
public void test() {
User2 user = new User2();
user.setId(8L);
user.setName(“王一蛋”);
user.setAge(99);
mapper.updateById(user);
}

乐观锁插件
当出现并发操作时,需要确保各个用户对数据的操作不产生冲突,此时需要一种并发控制手段。悲观锁的方法是,在对数据库的一条记录进行修改时,先直接加锁(数据库的锁机制),锁定这条数据,然后再进行操作;而乐观锁,正如其名,它先假设不存在冲突情况,而在实际进行数据操作时,再检查是否冲突。乐观锁的一种通常实现是版本号,在MySQL中也有名为MVCC的基于版本号的并发事务控制。
在读多写少的场景下,乐观锁比较适用,能够减少加锁操作导致的性能开销,提高系统吞吐量。
在写多读少的场景下,悲观锁比较使用,否则会因为乐观锁不断失败重试,反而导致性能下降。
乐观锁的实现如下:
取出记录时,获取当前version
更新时,带上这个version
执行更新时, set version = newVersion where version = oldVersion
如果oldVersion与数据库中的version不一致,就更新失败
这种思想和CAS(Compare And Swap)非常相似。
乐观锁的实现步骤如下
1. 配置乐观锁插件
package com.example.mp.config;
import com.baomidou.mybatisplus.extension.plugins.inner.OptimisticLockerInnerInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MybatisPlusConfig {
/** 3.4.0以后的mp版本,推荐用如下的配置方式 **/
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor());
return interceptor;
}
/** 旧版mp可以采用如下方式。注意新旧版本中,新版的类,名称带有Inner, 旧版的不带, 不要配错了 **/
/*
@Bean
public OptimisticLockerInterceptor opLocker() {
return new OptimisticLockerInterceptor();
}
*/
}
2. 在实体类中表示版本的字段上添加注解@Version
@Data
public class User2 {
private Long id;
private String name;
private Integer age;
private String email;
private Long managerId;
private LocalDateTime createTime;
private LocalDateTime updateTime;
@Version
private Integer version;
private Integer deleted;
}
测试代码
@Test
public void testOpLocker() {
int version = 1; // 假设这个version是先前查询时获得的
User2 user = new User2();
user.setId(8L);
user.setEmail(“version@baomidou.com”);
user.setVersion(version);
int i = mapper.updateById(user);
}
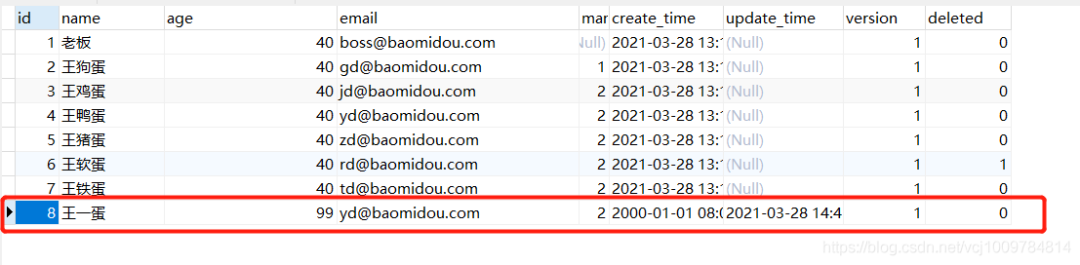
执行之前先看一下数据库的情况
根据下图执行结果,可以看到SQL语句中添加了version相关的操作
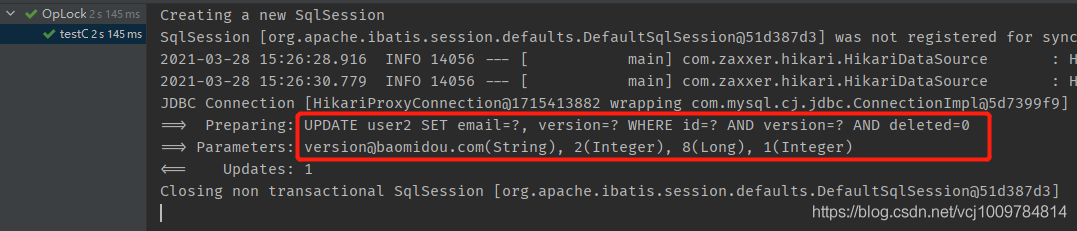
当UPDATE返回了1,表示影响行数为1,则更新成功。反之,由于WHERE后面的version与数据库中的不一致,匹配不到任何记录,则影响行数为0,表示更新失败。更新成功后,新的version会被封装回实体对象中。
实体类中version字段,类型只支持int,long,Date,Timestamp,LocalDateTime
注意,乐观锁插件仅支持**updateById(id)与update(entity, wrapper)方法**
注意:如果使用wrapper,则wrapper不能复用!示例如下
@Test
public void testOpLocker() {
User2 user = new User2();
user.setId(8L);
user.setVersion(1);
user.setAge(2);
// 第一次使用
LambdaQueryWrapper《User2》 wrapper = new LambdaQueryWrapper《》();
wrapper.eq(User2::getName, “王一蛋”);
mapper.update(user, wrapper);
// 第二次复用
user.setAge(3);
mapper.update(user, wrapper);
}
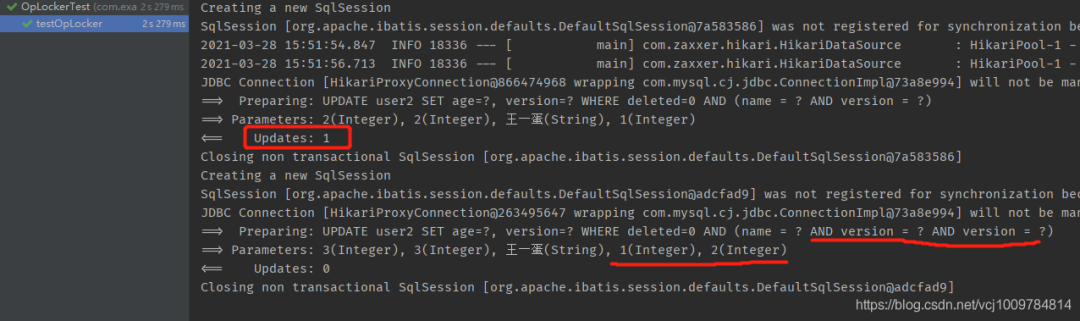
可以看到在第二次复用wrapper时,拼接出的SQL中,后面WHERE语句中出现了2次version,是有问题的。
性能分析插件
该插件会输出SQL语句的执行时间,以便做SQL语句的性能分析和调优。
注:3.2.0版本之后,mp自带的性能分析插件被官方移除了,而推荐食用第三方性能分析插件
食用步骤
1. 引入maven依赖
《dependency》
《groupId》p6spy《/groupId》
《artifactId》p6spy《/artifactId》
《version》3.9.1《/version》
《/dependency》
2. 修改application.yml
spring:
datasource:
driver-class-name: com.p6spy.engine.spy.P6SpyDriver #换成p6spy的驱动
url: jdbcmysql://localhost:3306/yogurt?serverTimezone=Asia/Shanghai #url修改
username: root
password: root
3. 在src/main/resources资源目录下添加spy.properties
#spy.properties
#3.2.1以上使用
modulelist=com.baomidou.mybatisplus.extension.p6spy.MybatisPlusLogFactory,com.p6spy.engine.outage.P6OutageFactory
# 真实JDBC driver , 多个以逗号分割,默认为空。由于上面设置了modulelist, 这里可以不用设置driverlist
#driverlist=com.mysql.cj.jdbc.Driver
# 自定义日志打印
logMessageFormat=com.baomidou.mybatisplus.extension.p6spy.P6SpyLogger
#日志输出到控制台
appender=com.baomidou.mybatisplus.extension.p6spy.StdoutLogger
#若要日志输出到文件, 把上面的appnder注释掉, 或者采用下面的appender, 再添加logfile配置
#不配置appender时, 默认是往文件进行输出的
#appender=com.p6spy.engine.spy.appender.FileLogger
#logfile=log.log
# 设置 p6spy driver 代理
deregisterdrivers=true
# 取消JDBC URL前缀
useprefix=true
# 配置记录 Log 例外,可去掉的结果集有error,info,batch,debug,statement,commit,rollback,result,resultset.
excludecategories=info,debug,result,commit,resultset
# 日期格式
dateformat=yyyy-MM-dd HHss
# 是否开启慢SQL记录
outagedetection=true
# 慢SQL记录标准 2 秒
outagedetectioninterval=2
# 执行时间设置, 只有超过这个执行时间的才进行记录, 默认值0, 单位毫秒
executionThreshold=10
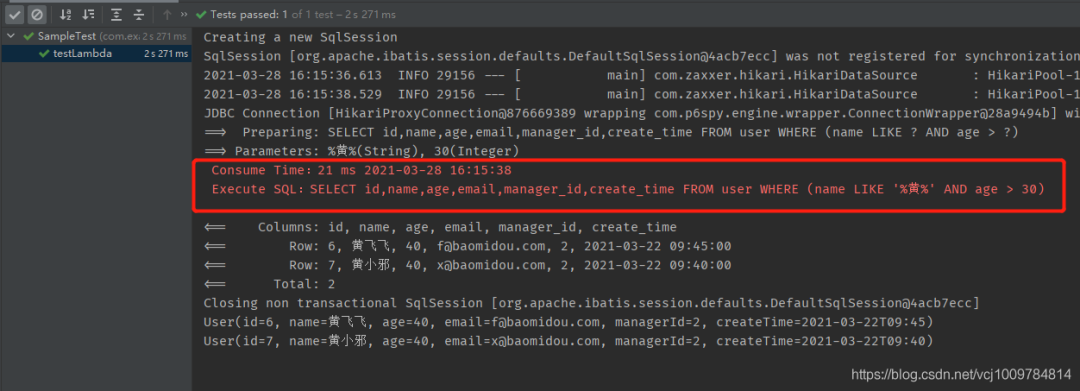
随便运行一个测试用例,可以看到该SQL的执行时长被记录了下来
多租户SQL解析器
多租户的概念:多个用户共用一套系统,但他们的数据有需要相对的独立,保持一定的隔离性。
多租户的数据隔离一般有如下的方式:
不同租户使用不同的数据库服务器
优点是:不同租户有不同的独立数据库,有助于扩展,以及对不同租户提供更好的个性化,出现故障时恢复数据较为简单。
缺点是:增加了数据库数量,购置成本,维护成本更高
不同租户使用相同的数据库服务器,但使用不同的数据库(不同的schema)
优点是购置和维护成本低了一些,缺点是数据恢复较为困难,因为不同租户的数据都放在了一起
不同租户使用相同的数据库服务器,使用相同的数据库,共享数据表,在表中增加租户id来做区分
优点是,购置和维护成本最低,支持用户最多,缺点是隔离性最低,安全性最低
食用实例如下
添加多租户拦截器配置。添加配置后,在执行CRUD的时候,会自动在SQL语句最后拼接租户id的条件
package com.example.mp.config;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.handler.TenantLineHandler;
import com.baomidou.mybatisplus.extension.plugins.inner.TenantLineInnerInterceptor;
import net.sf.jsqlparser.expression.Expression;
import net.sf.jsqlparser.expression.LongValue;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new TenantLineInnerInterceptor(new TenantLineHandler() {
@Override
public Expression getTenantId() {
// 返回租户id的值, 这里固定写死为1
// 一般是从当前上下文中取出一个 租户id
return new LongValue(1);
}
/**
** 通常会将表示租户id的列名,需要排除租户id的表等信息,封装到一个配置类中(如TenantConfig)
**/
@Override
public String getTenantIdColumn() {
// 返回表中的表示租户id的列名
return “manager_id”;
}
@Override
public boolean ignoreTable(String tableName) {
// 表名不为 user2 的表, 不拼接多租户条件
return !“user2”.equals(tableName);
}
}));
// 如果用了分页插件注意先 add TenantLineInnerInterceptor 再 add PaginationInnerInterceptor
// 用了分页插件必须设置 MybatisConfiguration#useDeprecatedExecutor = false
return interceptor;
}
}
测试代码
@Test
public void testTenant() {
LambdaQueryWrapper《User2》 wrapper = new LambdaQueryWrapper《》();
wrapper.likeRight(User2::getName, “王”)
.select(User2::getName, User2::getAge, User2::getEmail, User2::getManagerId);
user2Mapper.selectList(wrapper);
}
动态表名SQL解析器
当数据量特别大的时候,我们通常会采用分库分表。这时,可能就会有多张表,其表结构相同,但表名不同。例如order_1,order_2,order_3,查询时,我们可能需要动态设置要查的表名。mp提供了动态表名SQL解析器,食用示例如下
先在mysql中拷贝一下user2表
配置动态表名拦截器
package com.example.mp.config;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.handler.TableNameHandler;
import com.baomidou.mybatisplus.extension.plugins.inner.DynamicTableNameInnerInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.HashMap;
import java.util.Random;
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
DynamicTableNameInnerInterceptor dynamicTableNameInnerInterceptor = new DynamicTableNameInnerInterceptor();
HashMap《String, TableNameHandler》 map = new HashMap《》();
// 对于user2表,进行动态表名设置
map.put(“user2”, (sql, tableName) -》 {
String _ = “_”;
int random = new Random().nextInt(2) + 1;
return tableName + _ + random; // 若返回null, 则不会进行动态表名替换, 还是会使用user2
});
dynamicTableNameInnerInterceptor.setTableNameHandlerMap(map);
interceptor.addInnerInterceptor(dynamicTableNameInnerInterceptor);
return interceptor;
}
}
测试
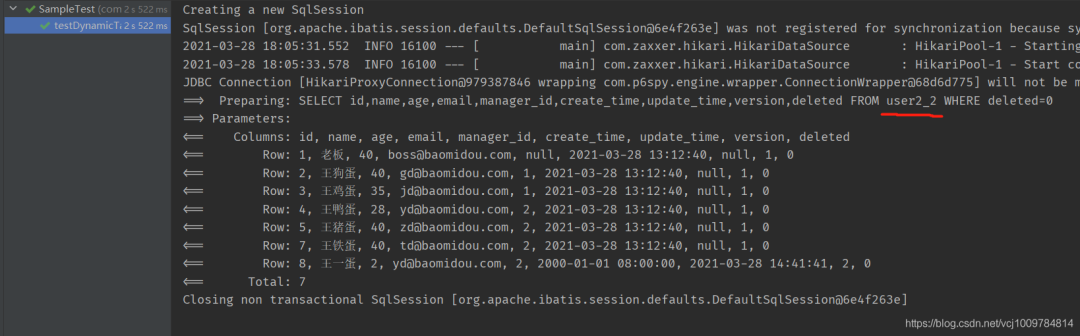
@Test
public void testDynamicTable() {
user2Mapper.selectList(null);
}
总结
条件构造器AbstractWrapper中提供了多个方法用于构造SQL语句中的WHERE条件,而其子类QueryWrapper额外提供了select方法,可以只选取特定的列,子类UpdateWrapper额外提供了set方法,用于设置SQL中的SET语句。
除了普通的Wrapper,还有基于lambda表达式的Wrapper,如LambdaQueryWrapper,LambdaUpdateWrapper,它们在构造WHERE条件时,直接以方法引用来指定WHERE条件中的列,比普通Wrapper通过字符串来指定要更加优雅。另,还有链式Wrapper,如LambdaQueryChainWrapper,它封装了BaseMapper,可以更方便地获取结果。
条件构造器采用链式调用来拼接多个条件,条件之间默认以AND连接
当AND或OR后面的条件需要被括号包裹时,将括号中的条件以lambda表达式形式,作为参数传入and()或or()
特别的,当()需要放在WHERE语句的最开头时,可以使用nested()方法
条件表达式时当需要传入自定义的SQL语句,或者需要调用数据库函数时,可用apply()方法进行SQL拼接
条件构造器中的各个方法可以通过一个boolean类型的变量condition,来根据需要灵活拼接WHERE条件(仅当condition为true时会拼接SQL语句)
使用lambda条件构造器,可以通过lambda表达式,直接使用实体类中的属性进行条件构造,比普通的条件构造器更加优雅
若mp提供的方法不够用,可以通过自定义SQL(原生mybatis)的形式进行扩展开发
使用mp进行分页查询时,需要创建一个分页拦截器(Interceptor),注册到Spring容器中,随后查询时,通过传入一个分页对象(Page对象)进行查询即可。单表查询时,可以使用BaseMapper提供的selectPage或selectMapsPage方法。复杂场景下(如多表联查),使用自定义SQL。
AR模式可以直接通过操作实体类来操作数据库。让实体类继承自Model即可
编辑:jq
-
一段话教会你熟练掌握单片机2017-05-09 3708
-
《工业机器人技术及应用》让人从认识到熟练掌握工业机器人2017-12-21 7323
-
教你如何轻松熟练的掌握PLC!2018-08-24 4557
-
教你熟练掌握PLC中的三大量2018-09-18 5397
-
如何快速熟练掌握嵌入式开发嵌入式开发工程师需要做哪些事情2019-05-09 1791
-
如何才能熟练掌握关于for循环2021-08-14 2499
-
Mybatis-Plus Mybatis增强工具包2022-06-13 818
-
熟练掌握常用的排序算法2022-08-20 3068
-
MyBatis-Plus的使用与测试2022-08-22 2331
-
Fluent Mybatis、原生Mybatis和Mybatis Plus对比2022-09-15 2318
-
MyBatis-Plus为什么不支持联表2023-02-28 4142
-
介绍一款基于Mybatis-Plus的代码自助生成器2023-05-23 2236
-
如何调优MyBatis 25倍性能2023-05-30 1610
-
你还在手写join联表查询?MyBatis-Plus这样写太香了!2023-07-07 5601
全部0条评论

快来发表一下你的评论吧 !
