

为什么传统的FPGA无法将智能传送到边缘
可编程逻辑
描述
无处不在的移动设备和遍在的连接已使世界“沉浸”在无线连接的汪洋大海,从不断增长的地面和非地面蜂窝基础设施,以及其所需的支持性光纤和无线回传网络,一直到通过最新开发的协议和SoC、将数十亿个传感器的数据发送到云端的大规模物联网生态系统。
预计在2025年以前,全球数据量(datasphere)每年将达到175ZB。而到2030年以前,相关连接设备的数量预计将达到500亿部(台)。但是,传统的分布式感测加云端集中处理数据的方案在安全性、功耗管理和延迟(端到端)方面都存在严重制限。5G标准中的超可靠低延迟通信,要求端对端(E2E)延迟不得高于数十毫秒。这就导致了将数据处理推到边缘端、避免将计算(和存储)资源进行汇聚,以减少在上下行链路的传输中产生的巨大开销。这么做,也同时提升了网络的敏捷性和可扩展性。
机器学习(ML)和人工智能深度神经网络(DNN)的发展,为推动边缘端的这一洞察视角带来了希望。但这些方案具有巨大的计算负荷,是传统软件和嵌入式处理器方法无法满足的。此外,随着工艺制程的推进,高昂的超专业化专用IC(ASIC)的开发和生产成本,是边缘设备无法承受的。而且, ASIC不具可重构性(reconfigurability),因而严重限制了任何潜在的系统升级可能。对于新一代边缘应用所需要的逻辑容量来说,传统的FPGA方案通常都过于昂贵和耗电。
边缘计算的细分市场要求设备具有极低的功耗、紧凑的外形尺寸、面对数据变化的敏捷响应、以及借助远程升级能力紧随AI的演进——所有这些都要以合理的价格实现。实际上,这是FPGA的天然优势,在灵活、硬件可定制的平台上加速计算密集型任务方面,FPGA是天生王者。但是,许多现成的FPGA都是面向数据中心应用的,而在数据中心整体功耗与成本核算里,是完全可以承受FPGA的那点“奢华”的。幸运的是,有一款解决方案:借助易灵思的 钛金系列FPGA系列,其先进的Quantum计算架构可直面近端数据(near-data)计算的需求,可灵活配置多达一百万个逻辑单元(LE),并且无论应用如何,都可轻松布线,实现超高的资源利用率。
边缘数据处理的刚需
就连接性而言,过去十年或多或少地致力于以下三件事:将世界用无线连接起来;提高无线连接的强度和完整性;并确保一切可连(从人到物) 的、都以某种方式连接起来。本质上讲,这是通过——下一代5G部署(强化基础蜂窝基础架构并开发更新的技术以优化数据吞吐量、容量、覆盖范围和延迟要求)以及物联网革命(其中物理目标配备了感知功能和/或标签)——实现的。这些技术发展已经产生了深远的社会影响,无线连接已成为日常生活中不可或缺的一部分。从家用电器到复杂的工业机械,使用传感器和执行器进行远程监视、跟踪甚至控制相关对象的能力几乎已成为了基本必须的能力。但是,设备密度的巨大提升也导致了某些非常明显的瓶颈。
以云为中心的物联网从公共/私有云的物联网节点中提取、累积和处理大量传感器数据,从而导致显著的延迟。回传访问的各种拓扑结构——从边缘设备到网关,再通过光纤或无线连接回到云——引入了三个主要瓶颈,它们是:
延迟
功耗预算
成本效益
传统物联网通常由严格控制功耗的终端设备定义,这些终端设备通过星型或网状拓扑以低到中等的吞吐量向互联网连接的网关发送少量有效载荷。这些多级架构无法满足从公共安全、医疗到工业自动化等许多时间敏感型的关键应用的低延迟要求。那些为低延迟、中等吞吐量、与时间同步的连接所定义的协议,例如WirelessHART、ISA 100.11a、IEEE802.11ac和LTE-M,其直接访问网关的往返延迟,可严苛到只允许有10毫秒;但是,典型的延迟却要几百毫秒。1这只是在IoT领域内——如果我们将重点转移到移动蜂窝网络,基于5G的高压配电网络中允许的最小E2E延迟则为5毫秒 ;对于离散自动化应用,会长一些、为10毫秒。2但是,硕果累累的先进制造技术利用了基于以太网的硬连线(如,EtherNet/IP、Profinet IO、Ethercat等)或基于现场总线(如,Profibus、Foundation Fieldbus,CAN等)的技术,这些时间敏感的组网技术必须要可靠地实现亚毫秒级的循环时间、亚微秒级的延迟以及极低的抖动(工厂运行要求)。3这些应用从感知到执行的闭环时间要求小于1 微秒,最大传输误码率率(transaction error rate)小于10–9,这是传统无线网络难以匹敌的指标。
无线连接需要异步或同步通信。为进行可靠的数据传输,传输必须有严格的时序安排。但这会消费不菲的功耗——理想的休眠或低功耗模式可延长电池续航时间,但设备无法在这样的模式下运行。此外,以智能地部署传感器节点,再通过网关和/或多级传输将数据带到云端,不仅会降低安全性、而且会增加硬件成本。可靠的数据传输是5G后(6G及更高)的移动通信时代的主要目标,而数据服务提供商大量收集用户信息的行为经常导致数据泄漏事件。4通过以去中心化的方式执行计算密集型任务,就可以实现数据的完全匿名化和不可追溯性。
边缘设备智能化的基本要求
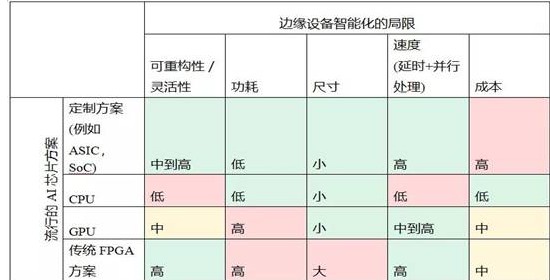
将计算基础架构从数据中心扩展到边缘这一主张,得到了越来越广泛的共识。诸如联邦学习之类的概念,通过共享的预测模型进行协作学习这种方式,将标准集中式机器学习(ML)方法从数据中心转移到手机——在将数据存储到云的需求中,消解了对可实现ML能力的要求。5而各种高级深度神经网络(DNN),每天都在发展、以更好地赋能基于边缘的处理功能。成功地将智能带到边缘设备也带来了与传统的AI不同的商机——例如:个性化购物,基于AI的助手;或在制造设施中进行预测分析。边缘/雾计算的应用,比如:车辆的自动驾驶;需要复杂反馈机制的机器人技术的远程控制;甚至是使用ML、可更好地管理可再生能源的智能电网终端设备;以及在电网中对本地电能使用进行预测分析。对于此类应用,成功实施AI的主要决定因素包括:
成本效益
低功耗
可重构性/灵活性
尺寸
IoT /边缘节点上流行AI芯片方案的比较
AI芯片方案市场一直在持续增长, 2020年的市场规模为76亿美元,到2026年有望增长至578亿美元。在各超专业方案之间,有着不同的6先进AI硬件,例如:
高度定制的ASIC和SoC
可编程FPGA方案
通用GPU和CPU
通用GPU和CPU通常遵循冯·诺依曼(von Neumann)架构,其中指令提取不能与数据操作同时发生,这样,指令只能被顺序执行。在矢量CPU和多核GPU等多处理器方案中,在某种程度上绕过了这种顺序性,但却需要更多的跨核数据共享而增加了延迟。这种由软件管理的并行机制必须在各处理单元之间最佳地分配工作量,否则可能会导致计算负载和通信不平衡——这种特性很难支撑自定义数据类型和特定的硬件优化。就延迟、功耗、并行处理和灵活/可重构性的效率而言,FPGA本质上优于GPU。首先, CPU和GPU必须以特定方式(如,SIMD、SIMT执行模型)处理数据,但FPGA和ASIC本质上直接在硬件中实现软件算法,逻辑单元可以简单地完成软件指令。此外,就完成相同质量的工作而言, FPGA功耗更低、可重构性更好——与硬件已固化的ASIC、SoC、GPU和CPU相比,人们可以在硬件层级来更改数据流的性质。
就流行的AI芯片方案而言,ASIC领先,FPGA随后。但是,就边缘智能计算的主要关注点而言,ASIC相形见绌。对于成本而言尤其如此:IoT的部署数量,可能在数十个到数十万个节点之间。众所周知,打造一款ASIC殊非易事,需要数年时间,而仅生产制造一项就需要数千万美元的巨额资本支出——通常,只有数百万至数十亿片的批量,此符合开发ASIC的成本效益。此外,人工智能的发展日新月异。仅在几个月内,数百种现有拓扑及其各自的神经网络就会有显着的改良。随着时间的流逝,会出现具有不同功能和层级的新模型,任何公司都会希望拥抱这些变化。这就吁求一种可快速原型化和部署的低成本、灵活、可重构的平台。
为什么传统的FPGA无法将智能传送到边缘
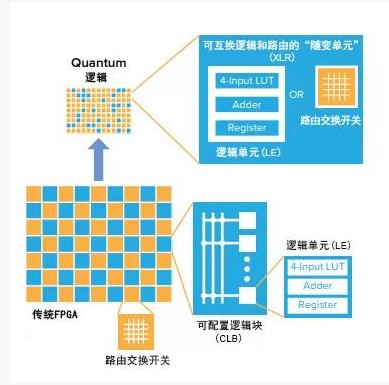
在传统以ASIC和GPU为主的AI芯片方案市场中,FPGA的竞争力与日俱增,这些平台主要用于ASIC的原型设计和开发,或用于公共和私有云中的网页搜索、图像分类和翻译等应用。要满足复杂AI运算的性能,通常需要价格昂贵、耗电且块头大的器件。FPGA的主要初衷是可编程性,其中硬件结构由可编程逻辑单元(LE)和配有交换开关模块的可编程路由电路组成。凭借这种结构,用户可通过可编程开关将任何LE连接到任一路由轨线上。如要扩大器件的容量,基本是通过增加LE的数量并确保路由交换电路与算法有能力支撑这些增长。这一艰苦卓绝且昂贵的过程一边需要工程师团队来优化FPGA的路由,一边让IC设计师尽量减小尺寸、才得以逐步提升器件容量;于此同时,FPGA被定位为只适合边缘之外的昂贵、耗电的应用。
约10年前易灵思的联合创始人张少逸先生和魏启杰先生就预测到这种情况,并以打造一种可以发挥FPGA的真正潜力来满足新兴边缘市场需求的FPGA技术——这一愿景创建了易灵思。如今,易灵思钛金系列器件在市场上独树一帜,在满足边缘AI的计算需求的同时,提供超小的功耗与尺寸,使其自然适用于哪怕是最苛刻的边缘应用。这在很大程度上要归功于其创新的Quantum计算架构,该架构由可重构的小块(tile)或可交换的逻辑和路由(XLR)单元组成,它消解了传统的路由方法,并允许LE变得更小、使用更灵活。集成了存储模块和高速DSP模块(乘法器模块)的器件的逻辑容量范围为3.6万至1百万个LE。与传统FPGA相比,无论最终应用为何,Quantum架构上的这种根本优势可以显著提高资源利用率。易灵思的FPGA技术迥异于传统的FPGA,它以小巧的器件封装实现了高密度、低功耗,同时又保持了FPGA随附的所有灵活性。总之,这些功能使该方案成为真正的颠覆者,在边缘/雾计算方面处于绝对领先地位。
Quantum内核架构与传统的FPGA架构[图片取自白皮书]
仔细观察:钛金系列 FPGA如何满足边缘计算的基本要求
成本效益、尺寸和功耗优势
16nm工艺使这款纤巧器件具有小至0.5mm间距、5.5×5.5mm BGA封装的器件尺寸可容易地集成进边缘节点。除尺寸方面的考虑外,与传统FPGA建构的分道扬镳,也降低了钛金系列FPGA的价格。反过来,与集中式基于云的处理相比,可享受边缘计算带来的额外成本降低的好处,且同时降低了使用FPGA做设计的门槛。
物联网节点也将不可避免地需要低能耗,并经常利用能量收集技术来最大程度地减少节点维护。因要尽可能多地完成数据处理,所以通常不会在边缘计算中看到在低功耗无线调制方案中经常用到的理想的休眠模式。但是,设计者可通过使用并行处理来降低内部时钟频率,以降低动态功耗,从而实现更具能效的电源方案。这与仅使用空间并行性的顺序处理器所遇到的瓶颈不同,在顺序处理器中,投入更多处理器内核的典型解决方案只会耗能——内存中数据的批处理无法为来自I/O通道的动态传入数据流提供一致的处理性能。FPGA同时提供空间和时间并行性,因此不仅采用数据并行,而且还实施任务和流水线并行。7这就使有效数据流有更多变化,从而减少了存储芯片对功耗的影响(例如,使用LE实现的空间和时间映射,通过重用FPGA内存的数据来减少片外存储芯片的访问)。
架构优势:灵活和可重构性
边缘应用的最终挑战是为特定应用找到合适的算法,并将其有效地映射到硬件。通常,网络(例如DNN、CNN等)很复杂,并且计算量、内存需求和耗电都非常高,因此它们需要访问具有优化内存的专用硬件加速器,才能在一致的数据流上执行算法 、且同时保持较小的功耗。通过将工作负荷映射到钛金系列 FPGA,用户可以利用其天生的小尺寸、低成本和高资源利用率的优势将智能传送到边缘。对于初涉该领域的新公司或想更新的老机构来说,这并不是一个复杂的过程。工程师们可以在钛金器件里使用RISC-V嵌入式处理器运行其算法的内核,并在Edge Vision SoC框架中进行快速创新。
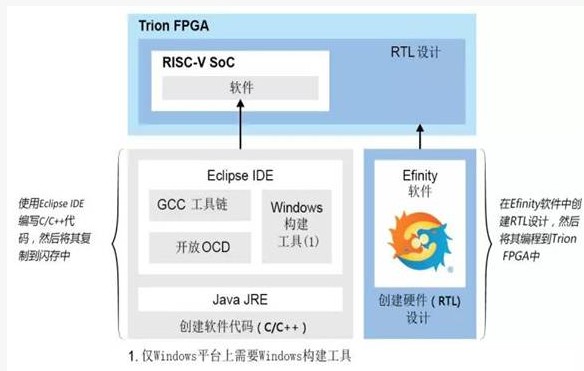
Edge Vision SoC设计流程
钛金系列中的RISC-V是“软”核,在需要时才在FPGA里例化,而不是被硬化到硅片中。这使它们保有灵活性,以便可以在应用开发期间根据需要对其进行定制。在编译过程中,Efinity软件动态决定是将XLR单元用作路由还是逻辑,并且针对每个设计的特性专门优化相关资源的使用。这样,工程师可为软件定义的硬件加速,放入任意所需数量的内核。
这是易灵思 Quantum加速器背后的基本概念:一些预先定义好了数据输入和输出的“插件(sockets)”,既可以被直接例化使用,也可以通过软件编程以标准的方式被调用。然后,软件工程师可以轻松地将代码中的热点作为他们想要加速的区域。更具体地说,在每个插件内,设计人员可以创建一小部分硬件以加速;例如,AI算法的卷积就可被放置在加速器框架中。算法的各个部分都可以在需要时移回RISC-V软件,或者在要求高性能时移入硬件加速器的“插件”。这种流畅的硬件/软件系统分区方法既快速又便宜。最终结果就是,对标准硬件加速器的标准调用:工程师可以通过调用那些优化了系统性能的小硬件加速器,来轻松编写和调试软件算法。这种方法既将设计概念保留在软件中,又可在其中对算法进行快速调试、调整和迭代。
钛金系列FPGA的Quantum架构还具有通过将可用作逻辑的随变单元(XLR)分配给路由来缓解拥堵的天然能力。所有这些因素与钛金系列 FPGA的成本效益相结合,可以使工程师快速地在最大的器件中进行原型的设计和调试,并在开发结束、量产时,切换到仍满足基本要求的最小器件,从而优化性能、功耗、尺寸和成本。
在边缘计算的早期阶段,与其它设备互连的能力是设计重用的重要系统级属性。使用钛金系列,用户可以利用FPGA固有的功能,通过丰富的I/O(146至268)连接到几乎任何设备。这些I/O引脚可配置为多种标准,来提升桥接的能力——这种灵活性是其它处理引擎或定制、专用标准部件很难实现的。
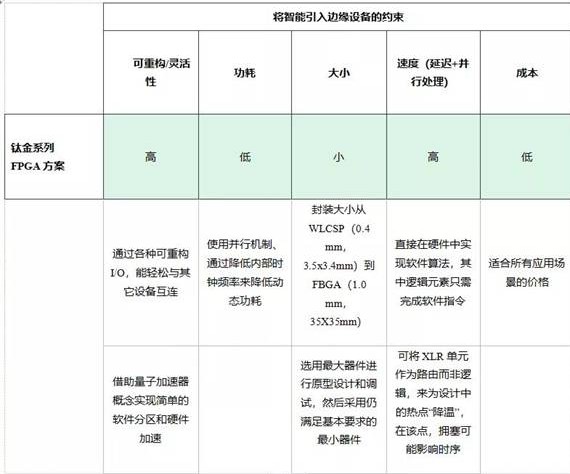
钛金系列 FPGA满足将智能迅速带到边缘的所有要求。
利用钛金系列在边缘服务嵌入式AI应用
从边缘处理中受益最大的物联网应用通常与需要可靠、低延迟通信的应用重叠。在保持相对低功耗的同时将复杂处理带到边缘的用例很多,随着时间的推移及该技术的成熟,将会涌现更多的应用。
机器人技术
在远程手术医疗应用中,外科医生/控制器和医疗设备之间的时间延迟必须极短。对于此应用,绝对需要同时具有云计算和边缘计算的共享网络架构,以便将机器人的机器学习算法应用于所有驱动工具或外科手术机器人,以提高人工操纵的末端执行器的灵巧性,以实现精确的触觉反馈。这属于机器人联网的范畴,其中对机器人进行编程的方法包括模仿学习或强化学习。尽管该复杂领域的许多部分将在云端执行,但由于外科医生遥远的地理位置,因此可将预先获取的电子病历和相关手术历史记录(例如以前记录的机器人动作)存储在本地。这样,当对要执行的任务信心不足时,基于边缘的AI引擎可以允许机器人查询其本地模型。模式识别算法还可以在本地处理3D视频和图像,并照亮相关特征(例如异常),还可以使用相关解剖数据对图像进行注释,同时最大程度地减少此类操作所消耗的数据带宽。
而工业应用中的机器人通常执行重复性任务,这些任务没多大差异和变化,动作基本千篇一律。但是,可以对这些机器人进行快速培训,使其成功执行任务并在出现细小偏差时更改动作,以帮助防范产线停机。此外,人机交互可以在不危及人类生命的情况下发生。结合了机器视觉和机器人技术的协作式机器人(例如用于工厂车间监控/维护的自动行走机器人和自动导引车),要求在实时的3D地图构建与机器人运动之间几乎没有延迟。这就要使用深度学习算法(如同步定位和地图构建SLAM),来防止在动态环境中发生磕碰。这两种应用都既需要高计算能力、又要求低功耗。
钛金系列FPGA系列具有满足这些应用以及更多应用的独特优势,用户可以一如既往正常地在处理器上开发代码,并通过灵活的XLR硬件加速来稳定地消除时序瓶颈,直到实现所需的贴近实时的系统性能为止。无论最终应用如何,基于钛金系列 FPGA的此类迭代改进可以优化性能、延迟和功耗等参数;而对于ASIC、GPU和CPU方案来说,这几乎是不可能的。
可穿戴设备
医疗可穿戴设备可以传输本地收集的患者数据的关键信息,该场景下,无需频繁传输。使用该技术,只能在现场进行快速有效的诊断。毋庸置疑,可穿戴设备将尺寸和功率限制发挥到极致。但在这里,钛金系列 Ti60在3.5×3.4mm WLCSP封装中以小巧的形态提供了高性能计算能力的独特组合:6.2万多LE;160个DSP模块;146个I/O。这款钛金系列 FPGA具有极低的工作和待机功耗,非常适合可穿戴应用严苛的尺寸和功耗要求。
机器视觉
用于过程自动化的机器视觉通常依赖于ML,而配备MIPI CSI-2传感器和强大存储器带宽的智能相机可用于执行基于视觉、像素或特征的检查。可通过合适的ML算法(例如决策树、朴素贝叶斯(Na?ve Bayes))训练分类器进行故障检测和分类,以确定缺陷(例如划痕)和粗糙度。通过运行基于经过训练的神经网络的推理引擎,FPGA可提供图像和音频处理。在此,钛金系列FPGA中的大量内存允许将大部分活动保留在芯片内,从而减少了耗时耗电的片外存储新品的访问。这些非常相同的特性可以应用于需要AI的视觉应用,例如提高视频会议的质量、对视频门铃的快速人体检测/面部识别,甚至自动驾驶应用中的行人/障碍物识别。
虚拟现实
从邮件/包裹递送到上述远程手术和工业机器人用例,可以在大量潜在应用中看到自动和远程控制的无人机和机器人。这些应用需要快速响应以识别并规避各种障碍。这些应用的其它重要考虑因素是知识共享、沉浸式培训以及通过AR/VR设备进行的远程控制/辅助。通常,AR/VR设备需要极低的功耗、大量的视频聚合以及计算能力。大多数钛金系列FPGA中的2.5Gb MIPI硬核IP有助于降低功耗,而嵌入式内存和DSP模块则可以为AR/VR系统累计并处理大量数据。
可最终服务于主流应用的FPGA
钛金系列FPGA系列在FPGA固有的灵活性、处理能力和性能优势的基础上,终于为各公司在功耗、尺寸和成本极为受限的边缘端,开辟了一条新道路。边缘给硬件加速带来了终极挑战,其中计算密集型算法必须在极低功耗的约束下实现最佳性能,同时还要满足面对不断变化的数据集和不断发展的AI能力以延长设备使用寿命的敏捷性需求。易灵思并没有盲目跟风其它FPGA公司进军数据中心的步伐;虽然在数据中心整体功耗与成本核算里,是完全可以承受“奢华”的FPGA的。而易灵思却通过钛金系列满足了所有边缘计算的要求。
本文综合整理自电子工程专辑 易灵思
责任编辑:pj
-
基于FPGA的实时边缘检测系统设计,Sobel图像边缘检测,FPGA图像处理2024-05-24 3470
-
如何通过蓝牙将51单片机的数据传送到手机2015-06-28 28591
-
磁耦合谐振无线电能传送2017-07-25 2946
-
请问zigbee能传送文件吗 ?就是txt类型的。2018-08-08 1889
-
怎么将图像发送到FPGA?2019-03-22 2483
-
请问传感器收集的数据通过wifi怎么传送到主机数据库?2019-07-09 4531
-
如何将数据从超级终端传送到PSoC并将其写入外部EEPROM?2019-08-07 1506
-
将uart数据读入dma时无法传送到缓冲器2019-09-26 1013
-
为什么需要边缘计算2020-06-23 2788
-
如何使用ECP5FPGA解决网络边缘应用设计挑战2020-10-21 1204
-
如何将音频数据传送到显示器?2021-05-27 1720
-
边缘智能市场要素:海量需求,物联网切分2022-08-23 2256
-
毫米波传感器实现边缘智能的方法2022-11-10 964
-
是否有可能自定义从esp设备传送到应用程序的数据?2023-05-15 487
-
脉冲光电耦合器电路图(能传送5000HZ时钟脉冲)2007-08-20 1225
全部0条评论

快来发表一下你的评论吧 !
