

在目前深度学习中比较普及的“物件检测”应用
描述
接下来的重点,就是在目前深度学习中比较普及的“物件检测”应用,重点主要有以下三部分:
1. 简单说明“物件检测”的内容。
2. 使用本项目的 detecnet 物件分类指令,进行多样化的推理识别测试。
3. 深入说明 jetson.inference 模块的 detectNet() 以及相关的函数用法。
如此让大家能快速掌握这项物件检测功能,以及开发代码的重点。
物件检测(object detection)简单说明
这是比图像分类更进一步的应用,因为日常生活中,在绝大部分可看到的画面中,不会只存在一个物体,通常是多种类别的多个物体,左图识别出有“四个人”、右图识别出“一个人与一匹马”,当然真的要细部再探索的话,还有其他类别的物体也可以被识别,这是视觉类深度学习中使用频率最高的一种应用。
在物件检测的识别中,还只是比较“概略性”地将物体用“矩形框”的方式来标识,那能不能将物体的“实际形状”更细腻地标识出来呢?当然可以,这就是更高阶的“语义分割”应用,留在下一篇文章里面说明。
前面的图像分类是以“一张图像”为单位,这里的物件检测则是以“物件框”为单位,因此所需要的数据集就不仅仅是图像了,还要将图像中所需要的类别加以标注,然后存成特定格式之后,提供给训练框架去进行模型训练,这是相当耗费人力的一个过程,而且标注的细腻程度也会对最终的精确度产生影响。
关于这个模型的训练过程,会在后面的文章中带着大家动手做一次,这也是整个 Hello AI World 项目中的一部分,而且也提供非常好用的工具,协助大家采集数据、标注物件框、进行模型训练等。
以上就是物件检测的简单说明,接下去直接使用项目提供的 detectnet 指令来进行实验。
detectnet 指令的使用
与 imagenet 的调用逻辑是一样的,当系统编译好之后,就生成 detectnet 指令,可以在 Jetson 设备中任何地方调用。同样的,项目也为 detectnet 准备了几个预训练好的网络模型,可以非常轻松地调用,预训练模型。
系统预设的神经网络是 “SSD-Mobilenet-v2”,基于 91 种分类的 COCO 数据集进行模型训练,详细的类别内容可以参考 ~/jetson-inference/data/networks 目录下的ssd_coco_labels.txt,事实上能识别的物件有 90 种,另外加一个 “unlabeled” 种类。
detectnet 的参数调用与 imagenet 几乎一致,输入源与输出标的的支持方式完全相同,因此我们可以执行下面指令,直接看看得到怎样的效果:

在执行过程中,会看到命令终端不断出现类似下图的信息,里面显示一些重要的信息,包括“使用的网络模型文件”、“4 个执行阶段占用时间”、“检测到满足阈值的物件数”、“物件类别/置信度”,以及“物件位置”等信息。
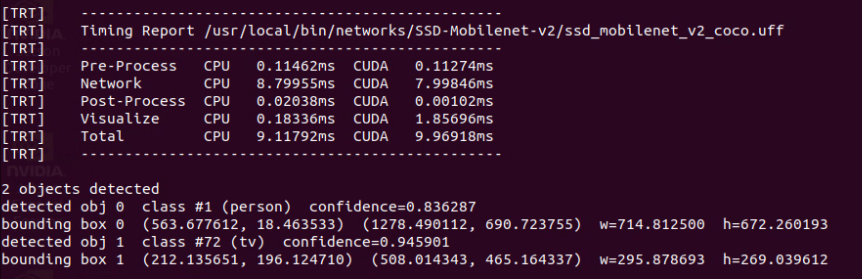
detectnet 也能导出 RTP 视频流到指定的电脑,详细用法请参考前面 “Utils的videoOutput 工具”一文中有详细说明,这个用法的实用度非常高,可以让你将 Jetson Nano 2GB 设备放置在任何能接网络的角落,不断读取摄像头内容在 Jetson 上执行物件识别,然后将结果传输到你的桌面电脑或笔记本上,这样你就可以非常轻松地进行监控。
输入 “detectnet --help” 可以得到完整的帮助信息,由于内容太多,我们在这里不占用篇幅去说明,多尝试一些指令的组合,会让你进一步掌握这个指令的重点。
接下来看看如何在 Python 代码中,调用这个项目的物件检测函数,来开发自己的物件检测应用。
detectNet()函数的用法
与前面图像分类的逻辑一样,作者虽然在 ~/jetson-inference/python/examples 下面提供了一个 my-detection.py 范例,这个就是我们一开始所示范的“ 10 行代码威力”的内容,这个范例的好处是“代码量最少”,但对应的缺点就是“弹性小、完整度不够”,因此从务实的角度,我们还是推荐以 /usr/local/bin/detect.py 这只代码为主,这只代码能执行的功能,与 detectnet 指令几乎一致。
与 imagenet.py 代码相同的,一开始有一段“参数解析”的指令,如下截图:
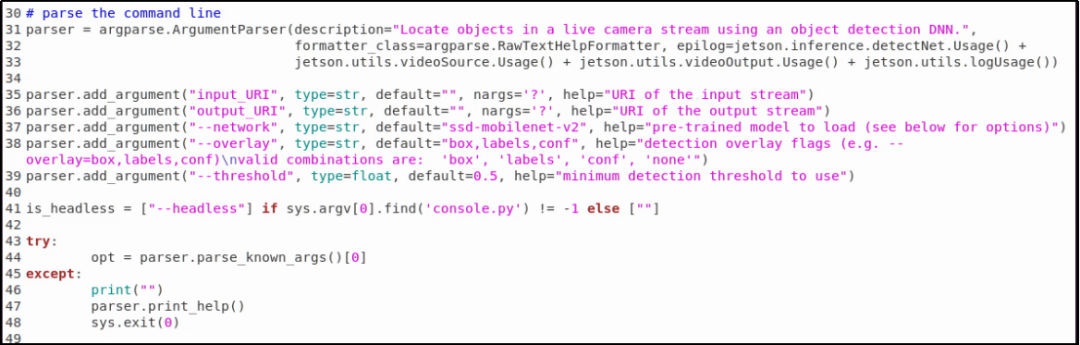
这部分同样请参考先前的“参数解析功能”文章,在这里不重复赘述。接下来我们将与物件检测有关的指令挑出来说明,这样可以让读者更加容易将焦点集中在有关的部分:
51 行:net = jetson.inference.detectNet(opt.network, sys.argv, opt.threshold)
用 jetson.inferene.detectNet() 函数建立 net 这个物件检测对象,与前面的 imageNet() 的逻辑是一样的,不过这里所输入的参数,除了 network(网络模型类别)之外,还多了一个 threshold(阈值)。因为物件检测的功能,是要在图像中识别出“所有可能”的物件,如果没有一个“最低门槛”的限制,就会满屏都是物件。
系统已经给这两个参数都提供预设值,network 预设为 “SSD-Mobilenet-v2”、threshold 预设值为 0.5。
如果要在代码外部利用参数去改变设定,就可以如以下方式:
--network=multiped,表示要使用“Multiped-500”这个网络模型
--threshold=0.3,表示将阈值改成0.3
这样 net 对象就具备了执行物件检测的相关功能,然后再继续以下的步骤。
63 行:detections = net.Detect(img, overlay=opt.overlay)
这道指令,就是将 input.Capture() 获取的一帧图形,传入 net.Detect() 函数去执行物件检测的推理识别计算,另一个参数 “overlay” 的功能是“检测覆盖”的一个标识,只影响显示输出的方式,与检测结果并没有关系,大部分时候都不需要去改变。
这里最重要的是 detections 这个数组变量,由于每帧图像所检测出来物件数量是不固定的,数组的结构在说明文件中并未完整表达,因此需要从执行的代码中去找到蛛丝马迹,这个部分在下一道指令中可以找到答案。
66~69 行:
print(“detected {:d} objects in image”.format(len(detections)))
for detection in detections:
print(detection)
这部分执行完之后,会在命令终端上显示两个很重要的信息:
本帧图像所找到满足阈值的物件数量。
前面变量detections的数据结构。
在命令终端执行以下指令,
看看所显示的信息,如下截屏:
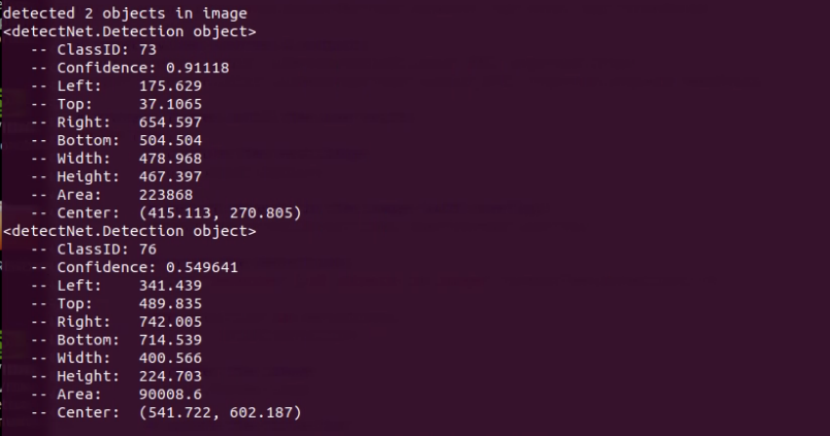
这里可以看到,代码最后面 “len(detections)” 的值,就是本帧图像所检测到的物件数量,而 detections 的数据结构就是:
ClassID:类别编号
Confidence:置信度
Left:标框左坐标
Top:标框上坐标
Right:标框右坐标
Bottom:标框下坐标
Width:框的宽度 = Right - Left
Height:框的高度 = Bottom - Top
Area:面积 = Width x Height
Center:中心点坐标 = ( (Left+Right)/2, (Top+Bottom)/2 )
确认了 net.Detect() 返回值之后,就能很轻易地以这些数据去开发满足特定要求的应用。
至于后面的 output.Render(img)、output.Status() 这些函数,在前面的文章里面都讲解的很清楚,这里不再重复。
到这里,要利用 Hello AI World 这个项目所提供的库资源,去开发自己的应用程序,就显得非常简单了。
编辑:jq
-
基于深度学习的小目标检测2024-07-04 2642
-
TensorFlow与PyTorch深度学习框架的比较与选择2024-07-02 2438
-
目前主流的深度学习算法模型和应用案例2024-01-03 3401
-
深度学习在工业缺陷检测中的应用2023-10-24 4238
-
如何在OpenCV中使用基于深度学习的边缘检测?2023-05-19 2803
-
深度学习在目标检测中的应用2022-10-31 2647
-
物件检测的模型训练与优化2022-04-27 1461
-
深度学习在预测和健康管理中的应用2021-07-12 1890
-
OpenCV使用深度学习做边缘检测的流程2021-05-08 2858
-
深度学习在计算机视觉上的四大应用2020-08-24 5635
-
主流深度学习框架比较2018-12-26 3219
-
如何使用深度学习进行视频行人目标检测2018-11-19 1740
-
深度学习和机器学习深度的不同之处 浅谈深度学习的训练和调参2018-05-02 4654
全部0条评论

快来发表一下你的评论吧 !
