

perf_counter在测量系统的性能中有何作用?
描述
不知不觉中,perf_counter已经经历了大大小小7个版本:
提高了delay_us()的精度
增加了对GCC、IAR的支持
改进了__cycleof__()宏,使其支持嵌套、并不再强制绑定 printf()
如果你使用的是Arm Compiler5(armcc)或是Arm Compiler 6(armclang),移植就特别简单。你可以按照这篇文章的手把手教程在5分钟内完成部署。
对于GCC和IAR来说,由于它们都不支持 Arm Compiler 5/6 所特有的 Linker语法——$Sub$$ 和 $Super$$,因此无法直接通过 Lib 的方式实现对已有SysTick应用的 “寄居”——这里就只能忍痛割爱了。 这并不影响我们以源代码的形式将它们加入已有的 GCC 或是 IAR 工程。大体步骤如下: 第一步:将perf_counter.c和perf_counter.h 拷贝到你的工程目录下,并将perf_counter.c 加入到编译列表中; 第二步:将perf_counter.h所在的路径加入到编译器的头文件搜索路径中;
第三步:perf_counter.c依赖 CMSIS 5.4.0及其以上版本,确保你的工程中正确的包含了对CMSIS的支持。(这里就不再赘述)。
第四步:在需要用到perf_counter功能的C源文件中加入对头文件的包含:
#include "perf_counter.h"
第五步:一般来说,用户会在某一个地方,比如main()函数内完成对CPU工作频率的配置,我们应该在完成这一工作之后确保全局变量SystemCoreClock 被正确的更新——保存当前CPU的工作频率,比如:
extern uint32_t SystemCoreClock;void main(void){ system_clock_update(); //! 更新CPU工作频率 SystemCoreClock = 72000000ul //! 假设更新后的系统频率是 72MHz ...}
一般来说,你的芯片工程如果本身都是基于较新的CMSIS框架而创建的,你的启动文件中已经为你定义好了全局变量SystemCoreClock——当然,凡事都有例外,如果你在编译的时候报告找不到变量SystemCoreClock或者说“Undefined symbol __SystemCoreClock” 之类的,你自己定义一下就好了,比如:
uint32_t SystemCoreClock;void main(void){ system_clock_update(); //! 更新CPU工作频率 SystemCoreClock = 72000000ul //! 假设更新后的系统频率是 72MHz ...}
在这以后,我们需要对perf_counter库进行初始化。这里分两种情况:
1、用户自己的应用里完全没有使用SysTick。对于这种情况,我们要在 main.c (或者别的什么源文件里)添加一个SysTick中断处理程序:
#include "perf_counter.h"... __attribute__((used)) //!< 避免下面的处理程序被编译器优化掉void SysTick_Handler(void){ //! 这个函数来自于 perf_counter.h user_code_insert_to_systick_handler();}
然后我们在main()函数里初始化perf_counter服务:
#include
需要特别注意的是:由于用户并没有自己初始化SysTick,因此我们需要将这一情况告知perf_counter库——由它来完成对SysTick的初始化——这里传递false 给函数init_cycle_counter()就是这个功能。如果由perf_counter 库自己来初始化SysTick,它会为了自己功能更可靠将 SysTick的溢出值(LOAD寄存器)设置为最大值(0x00FFFFFF)。
2、用户自己的应用里使用了SysTick,拥有自己的初始化过程。对于这种情况,我们需要确保一件事情:即,SysTick的CTRL寄存器的 BIT2(SysTick_CTRL_CLKSOURCE_Msk)是否被置位了——如果其值是1,说明SysTick使用了跟CPU一样的工作频率,那么SysTick的测量结果就是CPU的周期数;如果其值是0,说明SysTick使用了来自于别处的时钟源,这个时钟源具体频率是多少就只能看芯片手册了(比如STM32就喜欢将系统频率做 1/8 分频后提供给SysTick作为时钟源),此时SysTick测量出来的结果就不是CPU的周期数。
在确保了 CTRL寄存器的BIT2被正确置位,并且SysTick中断被使能(置位BIT1,SysTick_CTRL_TICKINT_Msk )后,我们可以简单的通过init_cycle_counter()函数告诉perf_counter模块:SysTick被用户占用了——这里传递 true 就实现这一功能。
#include
当然,不要忘记向已经存在的SysTick_Handler()内加入perf_counter()的插入函数:
#include "perf_counter.h"... __attribute__((used)) //!< 避免下面的处理程序被编译器优化掉void SysTick_Handler(void){ ... //! 这个函数来自于 perf_counter.h user_code_insert_to_systick_handler(); ...}
至此,我们就完成了perf_counter模块在GCC和IAR中的部署。
如何测量代码片断占用了多少CPU资源?
很多时候,我们会关心某一段代码或者函数究竟用了多少CPU周期,比如,我们写了一个算法,你很担心“这个算法究竟使用了多少CPU资源”,为了解决这个问题,我们需要用到如下的公式: CPU资源占用(百分比) = (函数运行所需的时间) (算法运行间隔的最小值) 100% 对于【函数运行所需的时间】和【算法运行间隔的最小值】来说,虽然它们都是时间单位,但考虑到CPU的频率是给定的(不变的),因此,这里的时间单位在乘以CPU的工作频率后都可以被换算为CPU的周期数。举例来说,假如【算法运行间隔的最小值】是 20ms、CPU的频率是72MHz,那么对应的周期数就是 72000000 * (20ms / 1000ms) = 1440000 个周期。看来上述公式中唯一需要我们实际测量的就是【函数运行所需的周期数】了。
perf_counter提供了一个非常简单的运算符:__cycleof__()。假设我们要测量的代码片断如下:
...my_algorithm_step_a();my_algorithm_step_b();...my_algorithm_step_c();...则我们可以轻松的通过__cycleof__()运算来测量结果:
...__cycleof__("my algorithm") { my_algorithm_step_a(); my_algorithm_step_b(); ... my_algorithm_step_c();}...如果你的系统支持printf(),则可以看到类似如下的输出结果:

带入上述公式:525139 / 14400000 * 100% ≈ 36.5% 就计算出这个算法占用了大约 36.5% 的CPU资源,值得说明的是,从原理上看,这一方式对裸机和RTOS同样有效哦。
有的小伙伴很快会说,我的系统并不允许我调用printf,那我还可以使用 __cycleof__() 么?当然了!就继续以上述代码为例子:
int32_t nCycleUsed = 0; ...__cycleof__("my algorithm", { nCycleUsed = _; }) { my_algorithm_step_a(); my_algorithm_step_b(); ... my_algorithm_step_c();}...这里的代码所实现的功能是:
测量了用户函数 my_algorithm_step_xxx()所使用的周期数:
测量的结果被转存到了一个叫做 nCycleUsed的变量中;
__cycleof__()将不会调用printf()进行任何内容输出。
我相信很多小伙伴会揉了揉眼睛、仔细看了又看,然后回过头来满头问号:
这是C语言? 这是什么语法? 不要怀疑,这就是C语言,只不过使用了一点GCC的语法扩展(感兴趣的小伙伴可以复制这里的连接https://gcc.gnu.org/onlinedocs/gcc/Statement-Exprs.html#Statement-Exprs),考虑到本文只介绍perf_counter如何使用,而对其如何实现的并不关心,我们不妨略过GCC扩展语法的部分,专门来看看上述代码的使用细节:
首先,为了方便大家观察,我们先忽略圆括号内的部分:
...__cycleof__(...) { my_algorithm_step_a(); my_algorithm_step_b(); ... my_algorithm_step_c();}...可以发现,这里跟此前并没有什么不同:花括号包围的部分就是我们要测量的代码片断;
接下来,我们专门来看__cycleof__()圆括号中的部分:
int32_t nCycleUsed = 0; ...__cycleof__("my algorithm", { nCycleUsed = _; }){...}...容易发现,如果以“,” 为分隔符,那么实际传递给__cycleof__()的是两个部分: 1、标注测量名称的字符串
"my algorithm"2、一段用花括号括起来的代码片断:
{nCycleUsed = _;}其中,nCycleUsed是一个事先已经初始化好的变量。 这里,对于表示测量名称的字符串"my algorithm",在这一用法下在最终的编译结果里并不会占用任何RAM或者是ROM,但作为语法结构是必须的。 对于花括号所囊括的代码片段来说,实际上在这个花括号里,你几乎可以为所欲为:
你可以写任意数量的代码
你可以调用函数
你可以定义变量(当然这里定义变量肯定就是局部变量了)
但我们一般要做的事情其实是通过__cycleof__()所定义的一个局部变量"_"来获取测量结果——这也是下面代码的本意:
nCycleUsed = _;需要说明的是,这个局部变量"_"生命周期仅限于这个花括号中,因此不会影响 __cycleof__() 整个结构之外的部分——或者说,下述代码是没有意义的:
int32_t nCycleUsed = 0; ...__cycleof__("my algorithm", { nCycleUsed = _; }) { my_algorithm_step_a(); my_algorithm_step_b(); ... my_algorithm_step_c();} printf("Cycle Used %d", _);编译器会毫不客气的告诉你 "_" 是一个未定义的变量,反之如果你这么做:
int32_t nCycleUsed = 0; ...__cycleof__("my algorithm", { nCycleUsed = _; printf("Cycle Used %d", _); }) { my_algorithm_step_a(); my_algorithm_step_b(); ... my_algorithm_step_c();}
则会看到你心怡的输出结果:
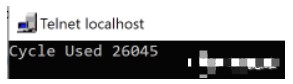
没有什么黑魔法
如果你对上述例子的等效形式(展开形式)感到非常好奇,其实大可不必,上述代码在“逻辑上等效”于如下的形式:
int32_t nCycleUsed = 0; ...do { int64_t _ = get_system_ticks(); { my_algorithm_step_a(); my_algorithm_step_b(); ... my_algorithm_step_c(); } _ = get_system_ticks() - _; //! 我们添加的代码 nCycleUsed = _; printf("Cycle Used %d", _);} while(0);是不是突然就没有那么神秘了?通过“逻辑等效”的形式展开,我们很容易发现一些有趣的内容:
起核心作用的是一个叫做 get_system_ticks() 的函数。实际上它返回的是从复位后 SysTick被使能至今所经历的 CPU 周期数——由于它是int64_t 的类型,因此不用担心超过 SysTick 24位计数器的量程,也不用担心人类历史范围内会发生溢出的可能。 知道这一点后,聪明的小伙伴就可以自己整活儿了。
由于 "_" 是一个局部变量,因此可以判断 __cycleof__() 是支持嵌套的。
需要特别说明的是,get_system_tick()函数自己也是有CPU时钟开销的,所以如果要获得较为精确的结果,推荐通过下面的方法来获取校准值:
static int64_t s_lPerfCalib; void calib_perf_counter(void) { int64_t lTemp = get_system_tick(); s_lPerfCalib = get_system_tick() - lTemp;} int64_t get_perf_counter_calib(void){ return s_lPerfCalib;}具体如何使用,这里就不再赘述了。 说在后面的话。
perf_counter仍然在不停的演化中,这多亏了开源社区不断的使用和反馈。perf_counter的应用场景实际上非常广泛,包括但不限于:
为裸机或者RTOS提供Cycle级别的性能测量;
评估代码片段的CPU占用;
算法精细优化时用于测量和观察优化的效果;
测量中断的响应时间;
测量中断的发生间隔(查找最短时间间隔);
评估GUI的帧率或者刷新率;
与SystemCoreClock计算后,获得一个系统时间戳(Timestamp);
当做Realtime Clock的基准;
作为随机数种子
……
实际上perf_counter在我参与的另外一个开源项目arm-2d里也被悄悄的藏在了platform_utilities.lib中用来为例子代码提供帧率的测量服务。
责任编辑:lq6
-
Linux perf 简要介绍2023-11-09 1975
-
如何使用perf性能分析工具2023-11-08 3041
-
Linux perf性能、实际应用与案例2023-07-03 1451
-
RTOS多任务性能分析实现经验分享2022-04-15 7898
-
Parameter文件在Rockchip android系统中有何作用2022-03-04 1472
-
FFT算法在STM32测试程序设计中有何作用2021-11-19 1916
-
换向器在发电机中有何作用2021-11-11 3217
-
Python在实时嵌入式系统开发中有何作用2021-11-10 1586
-
DCS系统在火电厂主控系统中有何应用2021-10-26 2426
-
信号继电器在继电保护中有何作用2021-09-27 2052
-
芯片组在主板中有何作用2021-09-22 5317
-
限流驱动在电动车无刷电机控制器中有何作用2021-08-06 3687
-
RFID技术在资产管理中有何作用?2021-05-18 1676
全部0条评论

快来发表一下你的评论吧 !
