

什么是GPU及其分类?GPU如何演化为通用计算平台?
描述
在前面文章中,我们交代了计算平台相关的一些基本概念以及为什么以GPU为代表的专门计算平台能够取代CPU成为大规模并行计算的主要力量。在接下来的文章中,我们会近距离从软硬件协同角度讨论GPU计算如何开展。跟先前的文章类似,笔者会采用自上而下,从抽象到具体的方式来论述。希望读者不只是对GPU计算能有所理解,而且能够从中了解可以迁移到其它计算平台的知识,此是笔者之愿景,能否实现一二,还恳请各位看官不断反馈指正,欢迎大家在后台留言交流。在本文中,我们首先介绍下GPU及其分类,并简单回顾下GPU绘制流水线的运作,最后又如何演化为通用计算平台。
一,什么是GPU及其分类
按维基百科定义,GPU(Graphics Processing Unit,图形处理器)是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上运行绘图运算工作的微处理器。为了以后讨论方便,这里先给市面的GPU按配置大致做个分类,分类之间界限比较模糊,不一定完全准确。
独立GPU(Discrete GPU),或者独立显卡。是指GPU通过PCI Express或者早期的AGP、PCI等扩展接口与主板连接。所谓的“独立”即是指显卡内的RAM只会被该GPU专用,而不是指显卡是否可从主板上移除。由于尺寸和重量的限制,供笔记本电脑使用的独立GPU通常会通过非标准的接口作连接,然而由于逻辑接口相同,这些接口仍会被视为PCIE,即使在物理上它们是不可与其他显卡互换。一些专门的GPU互联技术,如NVIDIA的SLI、NVLink和AMD的CrossFire等允许多个独立GPU协同工作,可显著增强设备的图形处理能力。独立GPU价格高,体积大,功耗高,但性能更强劲,而且因为自带显存,消耗的系统资源也更少。
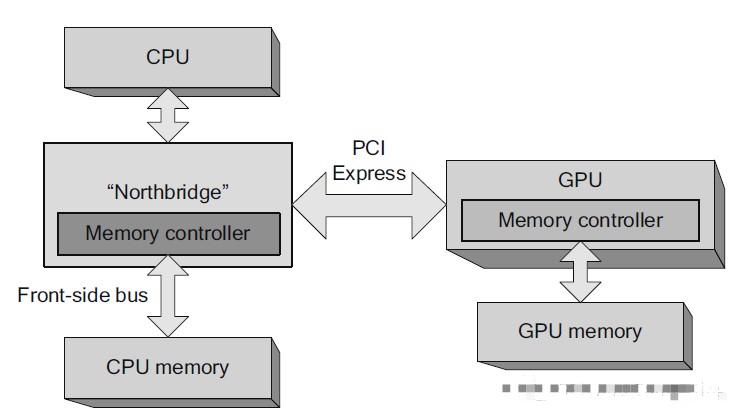
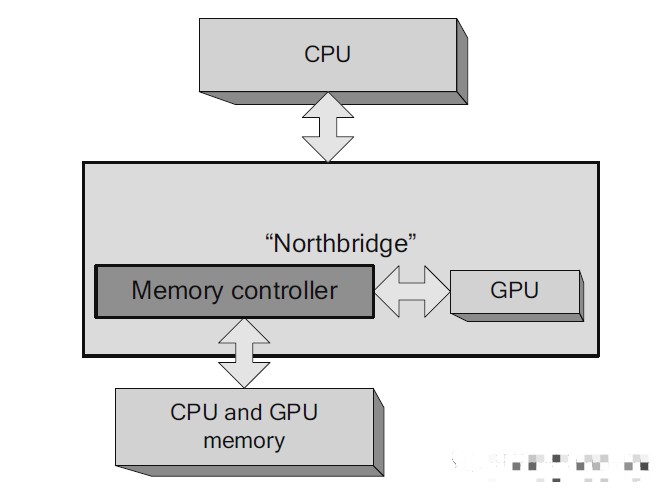
集成GPU(Integrated GPU), 或者集成显卡。是集成在主板或CPU上的GPU,运行时会占用部分的系统内存,相比起使用独立显卡的方案,这种方案较为便宜,但性能也相对较低。从2009年开始,集成GPU已经从主板移至CPU了,Intel将之称为HD Graphics(核芯显卡),AMD也推出了集成了CPU和GPU的APU。将GPU集成至处理器的好处是可以降低功耗,提升性能。随着技术的成熟,目前的集成GPU已经足够应付基本3D的需求,不过由于仍然依赖主板本身的RAM,相比独立显卡,访存带宽始终是个不小的限制。
移动GPU(Mobile GPU)。在移动设备领域,随着手机以及平板电脑等设备对图形处理能力的需求越来越高,GPU也成为移动处理器(SoC)的标配,高通、Imagination和ARM等等都在这个领域大显身手。我们在以前的文章提到过,苹果抛弃Imagination的PowerVR IP,在新近的产品采用自研GPU,也成为一股不可忽视的力量。因为移动设备散热和电
池供电的限制,功耗是GPU设计首要考虑的问题,所以移动GPU相比其它GPU架构方面会有不小差异。
以后谈到GPU计算的时候,我们主要还是以高性能为诉求。所以如果上下文没有特别说明,我们一般都是针对独立GPU。
二,GPU绘制流水线
在这节我们会简单的介绍GPU的绘制流水线(Rendering Pipeline),GPU就是为图形绘制加速而生,知道它的来龙去脉,有助于我们理解在其基础之上衍生的GPGPU。GPU绘制的过程,类似我们生活中拍照和写生,是有关如何把三维空间的场景在二维的屏幕上能尽量真实的呈现出来。我们以写生来做譬喻,针对特定场景输入,择一视点,取景构图,按照透视比例通过点线面勾勒出物体的边界和轮廓,确定明暗色调,注意远近关系多层次描绘。
与采用画笔、相机等工具不同,3D图形程序通过调用OpenGL(ES)、Direct3D或者Vulcan API的接口函数来同GPU硬件交互。为方便论述又不失代表性,下图是一个相对目前GPU简化的绘制管线,基本上相当于OpenGL(ES) 2.0或者Direct3D 9.0的规格,绘制管线主要有以下步骤构成。值得注意的是,管线分为可编程单元以及固定功能(fixed function)单元,后者优化处理管线中不容易并行化的工作,显然各种Shader都在可编程单元执行。
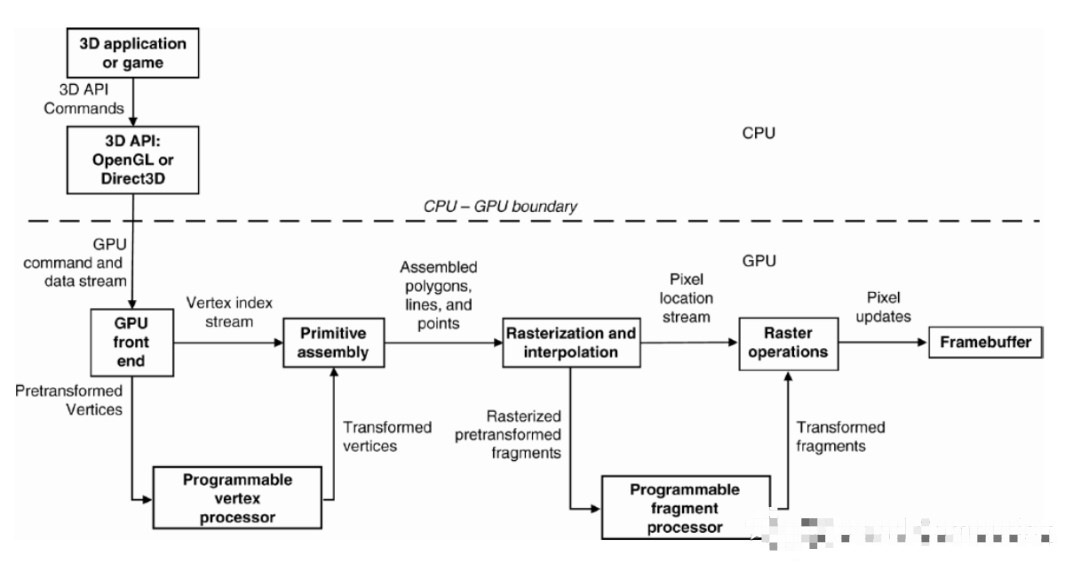
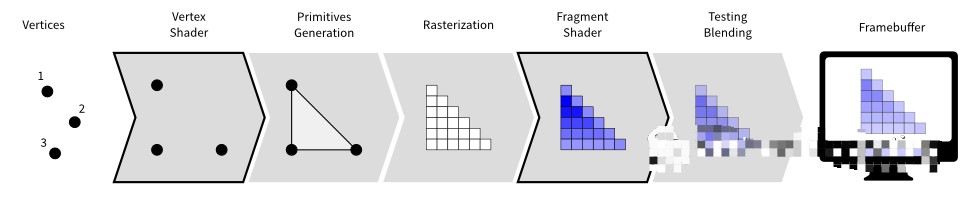
顶点数据输入。3D程序需要的三维场景可以通过3ds Max、Maya等专业软件来建模,生成的模型可以有成千上万个三角面片网格构成,其中不仅规定顶点的位置、颜色、纹理坐标和法向量等等属性也包括它们之间的连接信息。模型导入3D程序以后,就可以成为3D程序的顶点数据流,顶点数据为为后面的Vertex Shader等阶段提供待处理的数据。
Vertex Shader(顶点着色器)。Vertex Shader的主要功能是对顶点属性进行变换,包括顶点位置的坐标转换,从局部坐标统一到世界坐标并切换到视点坐标以至裁剪坐标。以前也在Vertex Shader进行光照颜色计算,但是由于不够真实,目前一般移到Fragment Shader阶段才发生。Vertex Shader的输入输出都是顶点。
Primitive Setup(图元装配)和Rasterization(光栅化)。图元装配是将变换后的的顶点根据连接信息组装成指定的图元。图元装配阶段会进行裁剪(clip)和背面剔除(backface culling)相关的优化,可以减少不必要的工作量。另外还需要透视除法(Perspective Division)达到透视效果,然后通过视口变化(Viewport Transformation)最终得到顶点的屏幕坐标。在光栅化阶段,基本图元被转换为一组二维的片元(fragment),片元表示将来可以被渲染到屏幕上的像素,它包含有位置,颜色,纹理坐标等信息,这些属性是由图元的相关顶点信息进行插值计算得到的。这些片元接着被送到Fragment Shader处理。
Fragment Shader(片元着色器)。片元着色器用来决定屏幕上潜在像素的最终颜色。在这个阶段会依据纹理坐标进行纹理采样、计算光照以及处理阴影等等,是绘制管线产生高级效果所在。
测试合成。测试合成是绘制管线的最后一个步骤。主要测试有裁剪测试(Scissor Test)、模板测试(Stencil Test)以及深度测试(Depth Test),深度测试就是确认进入的片元有没有被Framebuffer(帧缓存)同样位置的像素遮挡。通过最终测试的片元会进入合成阶段,就是进入的片元和Framebuffer已有的像素进行混合,根据颜色的Alpha值取代现有像素或混合产生半透明的效果。Alpha表示的是物体的透明度。测试合成阶段不是可编程的,但是我们依旧可以通过3D API提供的接口函数进行动态配置,并进一步定制测试和混合的方式。
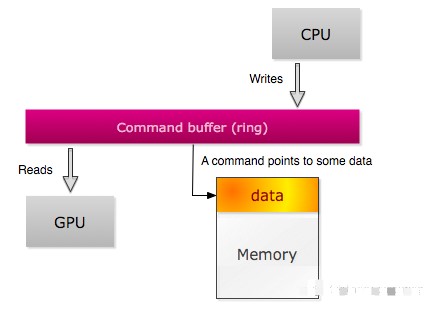
上面的步骤针对接口函数其中一个绘制命令,而一帧画面一般需要很多个绘制命令才能完成,等一帧内容结束以后,该Framebuffer就会作为新的Front Buffer交由显示设备显示,而先前显示的Front Buffer会变成Back Buffer又开始下一帧的绘制之旅。这就是GPU的双缓存(Double Buffering)策略。在上层应用程序可以通过3D API的接口函数调用GPU功能,在底层GPU驱动将这些接口函数转化为各种GPU私有的命令执行,它们可以完成绘制,状态寄存器设置以及同步等任务。CPU和GPU通过Ring Buffer(环形缓存)来传递和接受这些命令,CPU承担Ring Buffer生产者的角色,而GPU扮演消费者的角色,因为Ring Buffer大小有限,CPU和GPU需要同步。如果CPU老是要等GPU,我们说这个程序是GPU Bound,我们可能需要去优化Shader程序,减少三角面片数量来提高性能。相反如果GPU老是要等CPU,我们就认定这个程序是CPU Bound, 应用程序可以考虑把一些CPU预处理移交给GPU解决,比如利用GPU绘制管线支持的Geometry Shader(几何着色器)和Tessellation Shaders(细分曲面着色器)来生成额外顶点和图元,而不是等待CPU输入等等。
三,GPU计算的演进之旅
随着真实感绘制进一步发展,对图形性能要求愈来愈高,GPU发展出前所未有的浮点计算能力以及可编程性。这种远超CPU的计算吞吐和内存带宽使得GPU不只是在图形领域独领风骚,也开始涉足其它非图形并行计算应用。最早通过使用3D API OpenGL或者DirectX接口函数,很多数据并行算法被移植到GPU,性能也获得很好提升,但是这种利用模式面临不少问题,下面具体看看一步步是如何解决的。
CUDA的发明。之前的GPGPU实现需要并行算法程序员很熟悉图形API和GPU硬件,算法输入输出需要定义为图形绘制的元素,比如顶点坐标,纹理,帧缓存等,而实际算法又必须着用着色程序(Shader Program)来表达,极大增加了通用并行算法在GPU上移植开发的复杂度,另外受限图形API的表达能力,很多并行问题没办法有效发挥GPU的潜力。2006年,Nvidia破天荒地推出CUDA,作为GPU通用计算的软件平台和编程模型,它将GPU视为一个数据并行计算的设备,可以对所进行的计算分配和管理。在CUDA框架中,这些计算不像过去那样必须映射到图形API,因此对于开发者来说,基于CUDA的开发门槛大大降低了。CUDA编程语言基于标准的C语言,一般用户也很容易上手开发CUDA的应用程序。
统一可编程单元。早些时候的GPU绘制管线都是固定功能的,不存在可编程部分。后来出现了可编程的Vertex和Fragment处理,极大地丰富了绘制效果,但是Vetex和Fragment的处理单元还是分离的,很容易造成负载不均衡,性能的伸缩性也不好。伴随着Direct3D 10(Shader Model 4.0)出现,GPU开始用统一的处理单元运行Vertex、Fragment以及Geomerty Shader。对通用并行计算而言,配合CUDA框架,只要增加GPU可编程处理器数量配置,这种统一处理方式就能够最大限度地扩展性能,影响非常深远。
浮点计算的标准化。GPU的可编程处理单元是面向浮点运算,但是浮点数的支持之前几乎每个GPU厂商都有自己的解决方案,精度、舍入的处理都不一致,导致计算的准确度存在明显差异。比如绘制管线倾向于把溢出(overflow),下溢(underflow)和非规格化浮点数(denorms)截断为可表示有意义的最大值或者最小值。现在GPU增加了对特殊数值(Special Values)Infinity和NaN的支持,计算过程的精度和准确度也向IEEE 754标准要求靠拢,比如下图演示的FMA。浮点计算除支持半精度和单精度以外,双精度的支持也不可或缺。另外除了浮点数,GPU也开始支持各种各样的整形运算。这些数据类型的支持对GPU通用计算的重要意义不言而喻。
随机存取数据。传统的GPU架构只有非常有限的寻址能力,如通过提供纹理坐标给纹理处理单元读取纹理数据,Fragment Shader把像素最终的颜色值输出到对应的帧缓存位置,这些读写过程用户没有办法显式控制,非常限制通用计算的数据交互能力。现在的的GPU增加了额外的存取单元,在指令集中增加统一寻址存取指令,很大程度拓展了GPU通用计算应用空间。
存储支持ECC。随着制程工艺不断进步,器件尺寸缩小,DRAM和SRAM的永久性故障(Hard Error)和瞬时间失效(Soft Error)错误都会增加,尤其后者在电容储存电荷量较小的情况下,问题会越来越严重。GPU当然也不能幸免,从显存,到多级cache以至寄存器文件(Register File)都暴露在这一风险之下。对图形应用来说,这一问题并不需要太多担心,人们根本意识不到屏幕上几百万个像素中个别颜色值中一位或几位bit出现了翻转,哪怕发生更严重的错误,人类的视觉机制都有机会自我补偿纠正。但在高性能计算领域,差之毫厘,谬以千里,这些存储失效的问题都是不能承受之重。所以现在GPU厂商至少会针对HPC产品在整个存储器层次结构添加ECC(Error Correcting Code)支持,数据中心和服务器的客户也才敢放心购买使用。
有了以上一些改进和其他措施,终于GPU作为通用计算平台慢慢脱离原始阶段,开始成熟起来,成为大规模并行计算市场的主力军。
责任编辑:lq6
-
谈GPU的作用、原理及与CPU、DSP的区别2015-11-04 5560
-
GPU2016-01-16 5120
-
CPU和GPU擅长和不擅长的地方2017-12-03 3007
-
AM5728 可以调用GPU用于通用数学计算吗?2018-06-01 2800
-
ARM Mali-T600系列GPU OpenCL开发人员指南2023-08-24 786
-
GPU高性能运算之CUDA2010-08-16 879
-
基于GPU的并行APSP问题的研究2012-09-12 1122
-
对比CPU,GPU才是摩尔定律的宠儿?2017-03-14 3714
-
Javascript如何实现GPU加速?2018-09-06 1139
-
龙芯入局显卡市场,已完成通用计算GPU相关IP设计2023-06-26 1483
-
GPU和FPGA的工作原理及其区别2023-08-06 3896
-
GPU加速计算平台是什么2024-10-25 1450
-
澎峰科技计算软件栈与沐曦GPU完成适配和互认证2025-01-21 1756
-
GPU加速计算平台的优势2025-02-23 1288
-
GPU架构深度解析2025-05-30 2196
全部0条评论

快来发表一下你的评论吧 !
