

计算机视觉中主要的五大技术
描述
摘要: 本文主要介绍计算机视觉中主要的五大技术,分别为图像分类、目标检测、目标跟踪、语义分割以及实例分割。针对每项技术都给出了基本概念及相应的典型方法,简单通俗、适合阅读。
计算机视觉是当前最热门的研究之一,是一门多学科交叉的研究,涵盖计算机科学(图形学、算法、理论研究等)、数学(信息检索、机器学习)、工程(机器人、NLP等)、生物学(神经系统科学)和心理学(认知科学)。由于计算机视觉表示对视觉环境及背景的相对理解,很多科学家相信,这一领域的研究将为人工智能行业的发展奠定基础。
那么,什么是计算机视觉呢?下面是一些公认的定义:
1.从图像中清晰地、有意义地描述物理对象的结构(Ballard & Brown,1982);
2.由一个或多个数字图像计算立体世界的性质(Trucco & Verri,1998);
3.基于遥感图像对真实物体和场景做出有用的决定(Sockman & Shapiro,2001);
那么,为什么研究计算机视觉呢?答案很明显,从该领域可以衍生出一系列的应用程序,比如:
1.人脸识别:人脸检测算法,能够从照片中认出某人的身份;
2.图像检索:类似于谷歌图像使用基于内容的查询来搜索相关图像,算法返回与3.查询内容最佳匹配的图像。
4.游戏和控制:体感游戏;
5.监控:公共场所随处可见的监控摄像机,用来监视可疑行为;
6.生物识别技术:指纹、虹膜和人脸匹配是生物特征识别中常用的方法;
7.智能汽车:视觉仍然是观察交通标志、信号灯及其它视觉特征的主要信息来源;
正如斯坦福大学公开课CS231所言,计算机视觉任务大多是基于卷积神经网络完成。比如图像分类、定位和检测等。那么,对于计算机视觉而言,有哪些任务是占据主要地位并对世界有所影响的呢?本篇文章将分享给读者5种重要的计算机视觉技术,以及其相关的深度学习模型和应用程序。相信这5种技术能够改变你对世界的看法。
1.图像分类
图像分类这一任务在我们的日常生活中经常发生,我们习惯了于此便不以为然。每天早上洗漱刷牙需要拿牙刷、毛巾等生活用品,如何准确的拿到这些用品便是一个图像分类任务。官方定义为:给定一组图像集,其中每张图像都被标记了对应的类别。之后为一组新的测试图像集预测其标签类别,并测量预测准确性。
如何编写一个可以将图像分类的算法呢?计算机视觉研究人员已经提出了一种数据驱动的方法来解决这个问题。研究人员在代码中不再关心图像如何表达,而是为计算机提供许多很多图像(包含每个类别),之后开发学习算法,让计算机自己学习这些图像的特征,之后根据学到的特征对图像进行分类。
鉴于此,完整的图像分类步骤一般形式如下:
1.首先,输入一组训练图像数据集;
2.然后,使用该训练集训练一个分类器,该分类器能够学习每个类别的特征;
3.最后,使用测试集来评估分类器的性能,即将预测出的结果与真实类别标记进行比较;
对于图像分类而言,最受欢迎的方法是卷积神经网络(CNN)。CNN是深度学习中的一种常用方法,其性能远超一般的机器学习算法。CNN网络结构基本是由卷积层、池化层以及全连接层组成,其中,卷积层被认为是提取图像特征的主要部件,它类似于一个“扫描仪”,通过卷积核与图像像素矩阵进行卷积运算,每次只“扫描”卷积核大小的尺寸,之后滑动到下一个区域进行相关的运算,这种计算叫作滑动窗口。
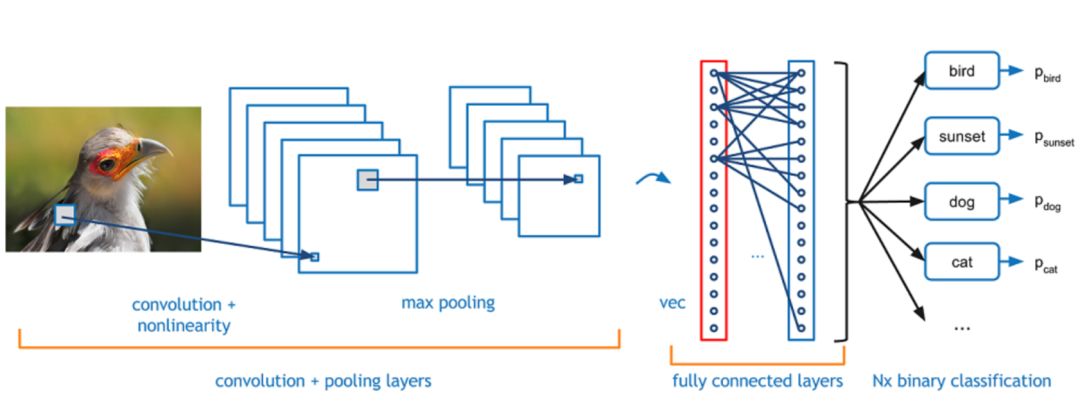
从图中可以看到,输入图像送入卷积神经网络中,通过卷积层进行特征提取,之后通过池化层过滤细节(一般采用最大值池化、平均池化),最后在全连接层进行特征展开,送入相应的分类器得到其分类结果。
大多数图像分类算法都是在ImageNet数据集上训练的,该数据集由120万张的图像组成,涵盖1000个类别,该数据集也可以称作改变人工智能和世界的数据集。ImagNet 数据集让人们意识到,构建优良数据集的工作是 AI 研究的核心,数据和算法一样至关重要。为此,世界组织也举办了针对该数据集的挑战赛——ImageNet挑战赛。
第一届ImageNet挑战赛的第一名是由Alex Krizhevsky(NIPS 2012)获得,采用的方法是深层卷积神经网络,网络结构如下图所示。在该模型中,采用了一些技巧,比如最大值池化、线性修正单元激活函数ReLU以及使用GPU仿真计算等,AlexNet模型拉开了深度学习研究的序幕。
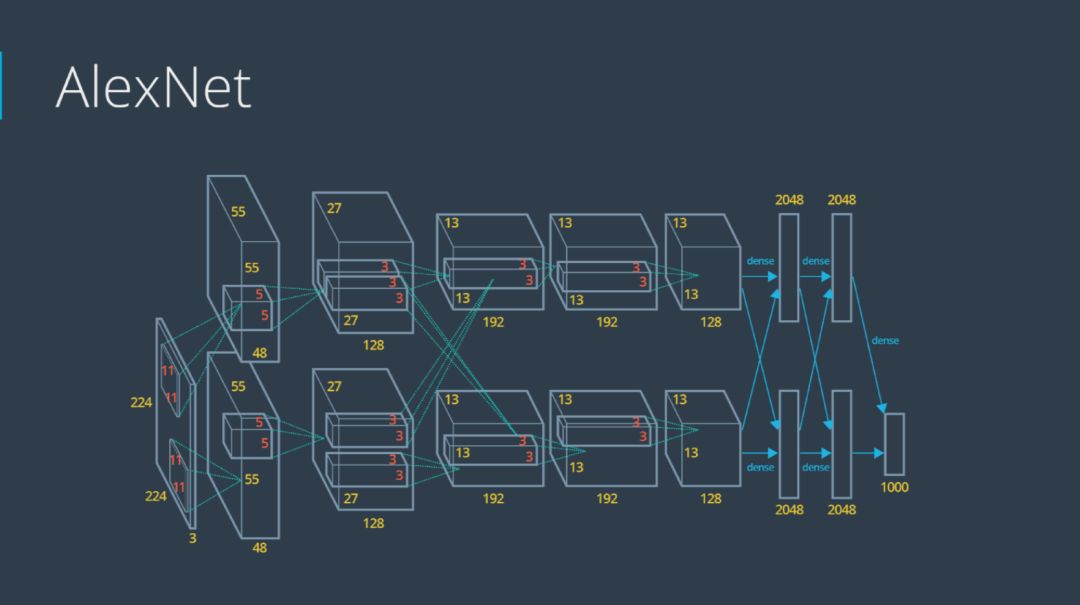
自从AlexNet网络模型赢得比赛之后,有很多基于CNN的算法也在ImageNet上取得了特别好的成绩,比如ZFNet(2013)、GoogleNet(2014)、VGGNet(2014)、ResNet(2015)以及DenseNet(2016)等。
2.目标检测
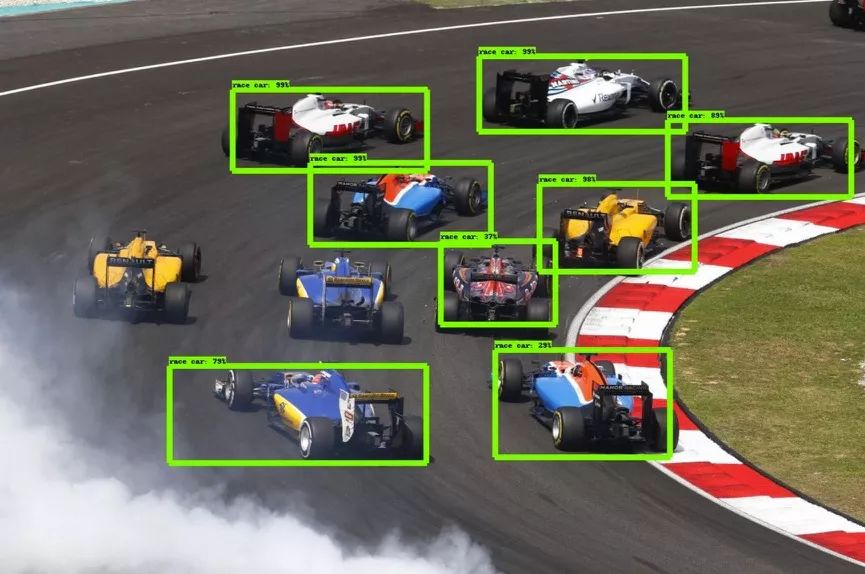
目标检测通常是从图像中输出单个目标的Bounding Box(边框)以及标签。比如,在汽车检测中,必须使用边框检测出给定图像中的所有车辆。
之前在图像分类任务中大放光彩的CNN同样也可以应用于此。第一个高效模型是R-CNN(基于区域的卷积神经网络),如下图所示。在该网络中,首先扫描图像并使用搜索算法生成可能区域,之后对每个可能区域运行CNN,最后将每个CNN网络的输出送入SVM分类器中来对区域进行分类和线性回归,并用边框标注目标。
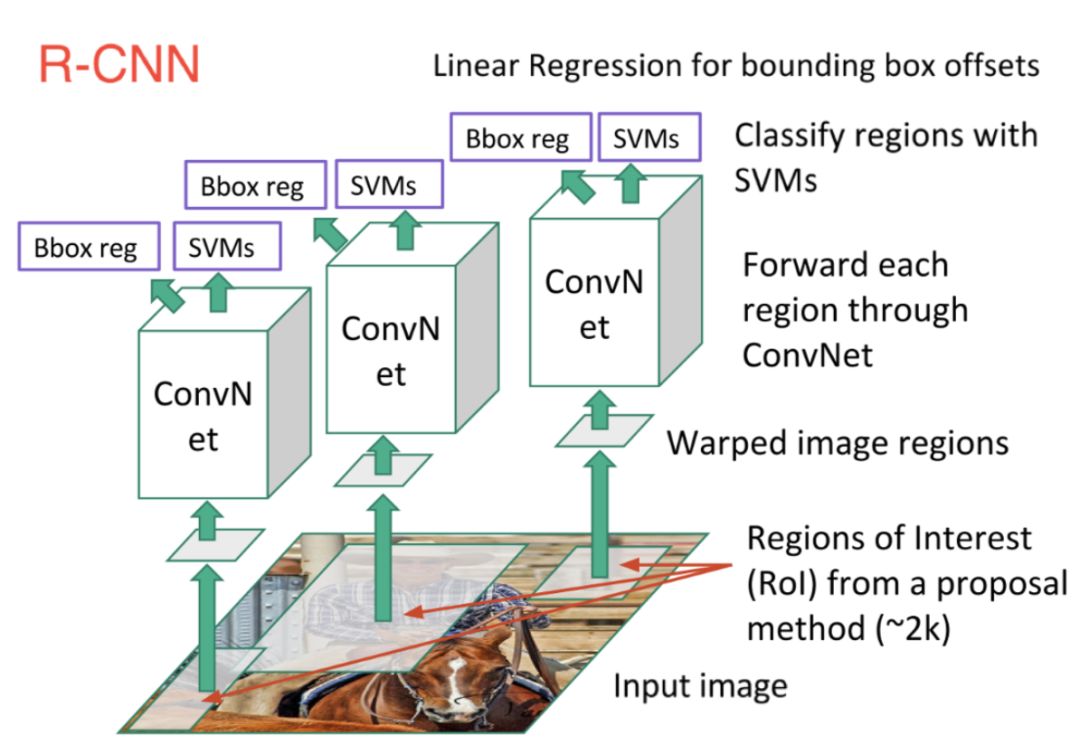
本质上,是将物体检测转换成图像分类问题。但该方法存在一些问题,比如训练速度慢,耗费内存、预测时间长等。
为了解决上述这些问题,Ross Girshickyou提出Fast R-CNN算法,从两个方面提升了检测速度:
1)在给出建议区域之前执行特征提取,从而只需在整幅图像上运行一次CNN;2)使用Softmax分类器代替SVM分类器;
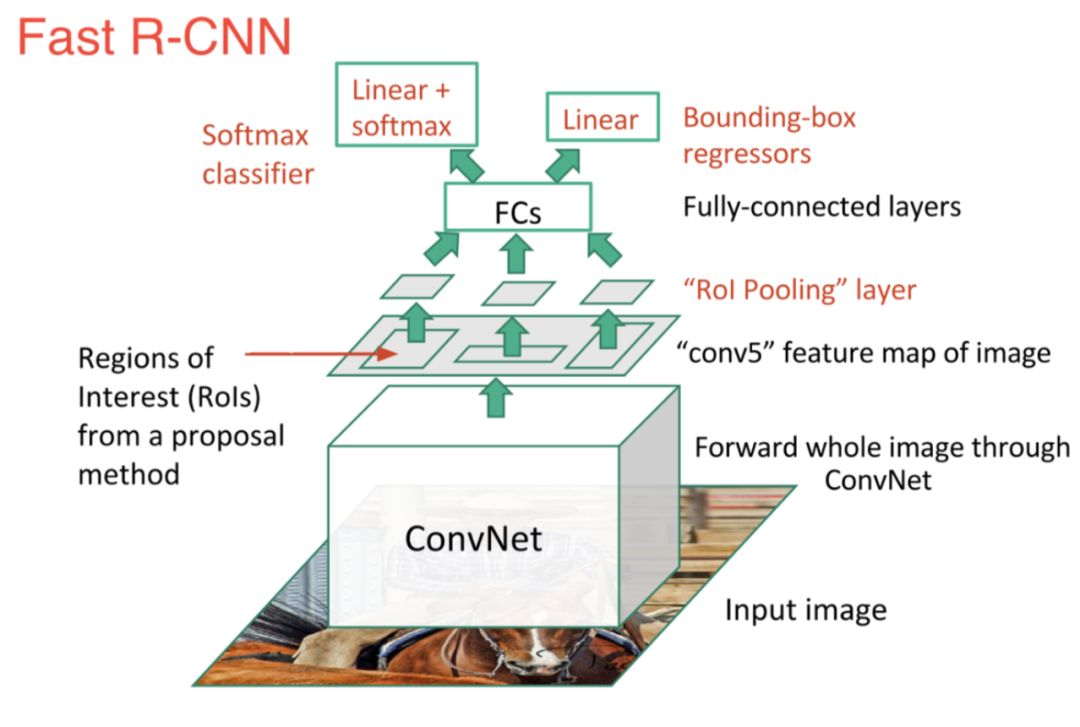
虽然Fast R-CNN在速度方面有所提升,然而,选择搜索算法仍然需要大量的时间来生成建议区域。为此又提出了Faster R-CNN算法,该模型提出了候选区域生成网络(RPN),用来代替选择搜索算法,将所有内容整合在一个网络中,大大提高了检测速度和精度。
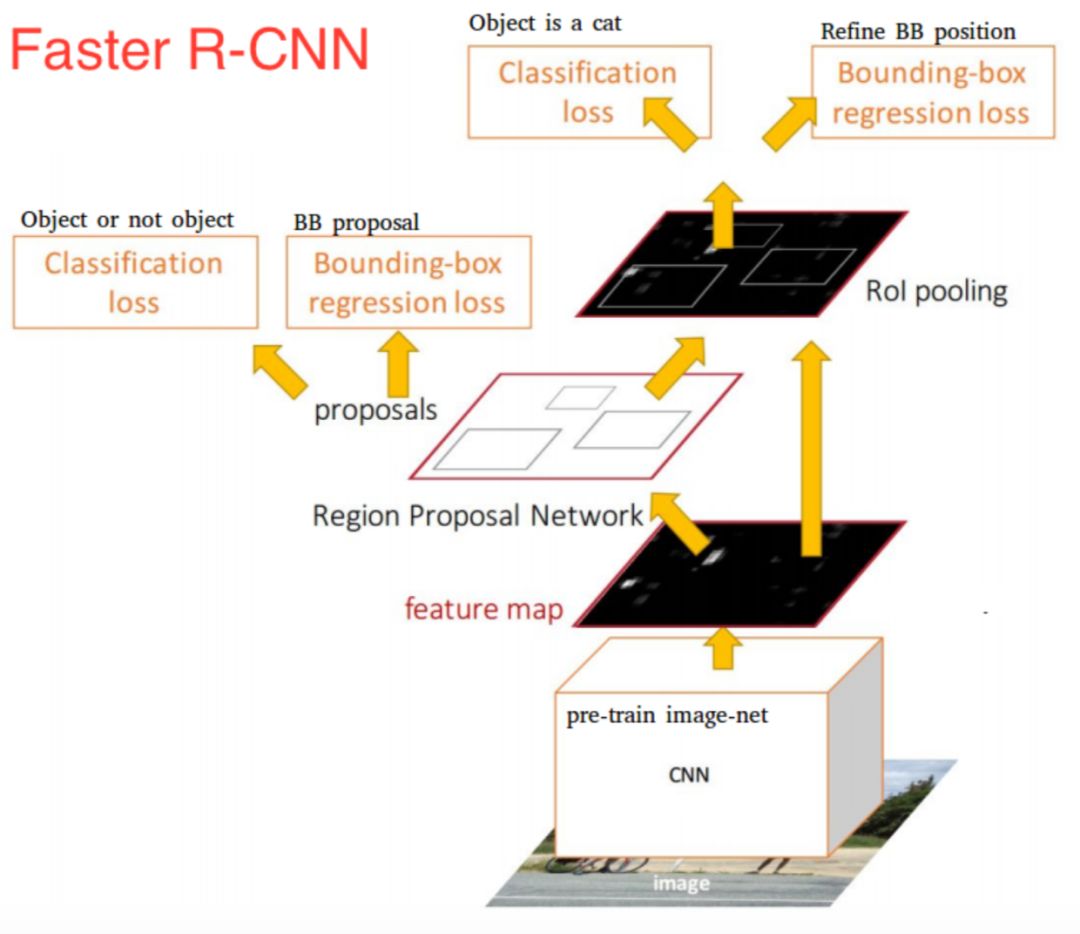
近年来,目标检测研究趋势主要向更快、更有效的检测系统发展。目前已经有一些其它的方法可供使用,比如YOLO、SSD以及R-FCN等。
3.目标跟踪
目标跟踪是指在给定场景中跟踪感兴趣的具体对象或多个对象的过程。简单来说,给出目标在跟踪视频第一帧中的初始状态(如位置、尺寸),自动估计目标物体在后续帧中的状态。该技术对自动驾驶汽车等领域显得至关重要。
根据观察模型,目标跟踪可以分为两类:产生式(generative method)和判别式(discriminative method)。其中,产生式方法主要运用生成模型描述目标的表观特征,之后通过搜索候选目标来最小化重构误差。常用的算法有稀疏编码(sparse coding)、主成分分析(PCA)等。与之相对的,判别式方法通过训练分类器来区分目标和背景,其性能更为稳定,逐渐成为目标跟踪这一领域的主要研究方法。常用的算法有堆栈自动编码器(SAE)、卷积神经网络(CNN)等。
使用SAE方法进行目标跟踪的最经典深层网络是Deep Learning Tracker(DLT),提出了离线预训练和在线微调。该方法的主要步骤如下:
1.先使用栈式自动编码器(SDAE)在大规模自然图像数据集上进行无监督离线预训练来获得通用的物体表征能力。
2.将预训练网络的编码部分与分类器相结合组成分类网络,然后利用从初始帧获得的正、负样本对网络进行微调,使其可以区分当前对象和背景。在跟踪过程中,选择分类网络输出得分最大的patch作为最终预测目标。
3.模型更新策略采用限定阈值的方法。
基于CNN完成目标跟踪的典型算法是FCNT和MD Net。
FCNT的亮点之一在于对ImageNet上预训练得到的CNN特征在目标跟踪任务上的性能做了深入的分析:
1.CNN的特征图可以用来做跟踪目标的定位;
2.CNN的许多特征图存在噪声或者和物体跟踪区分目标和背景的任务关联较小;
3.CNN不同层提取的特征不一样。高层特征更加抽象,擅长区分不同类别的物体,而低层特征更加关注目标的局部细节。
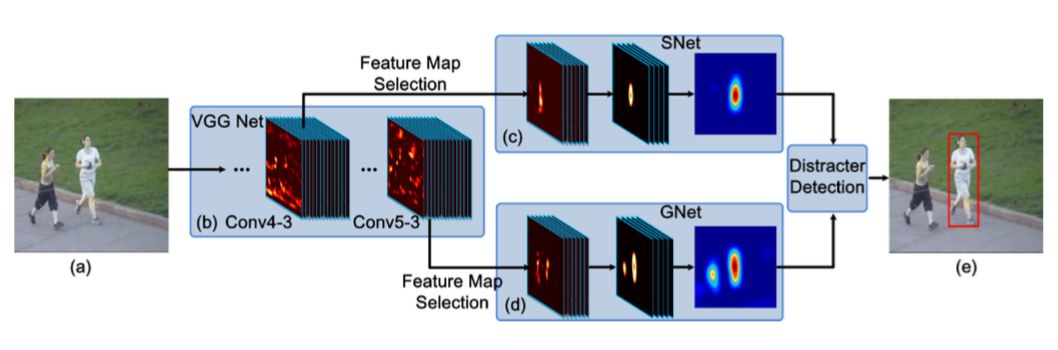
基于以上观察,FCNT最终提出了如下图所示的模型结构:
1.对于Conv4-3和Con5-3采用VGG网络的结构,选出和当前跟踪目标最相关的特征图通道;
2.为了避免过拟合,对筛选出的Conv5-3和Conv4-3特征分别构建捕捉类别信息GNet和SNet;
3.在第一帧中使用给出的边框生成热度图(heap map)回归训练SNet和GNet;
4.对于每一帧,其预测结果为中心裁剪区域,将其分别输入GNet和SNet中,得到两个预测的热图,并根据是否有干扰来决定使用哪个热图。
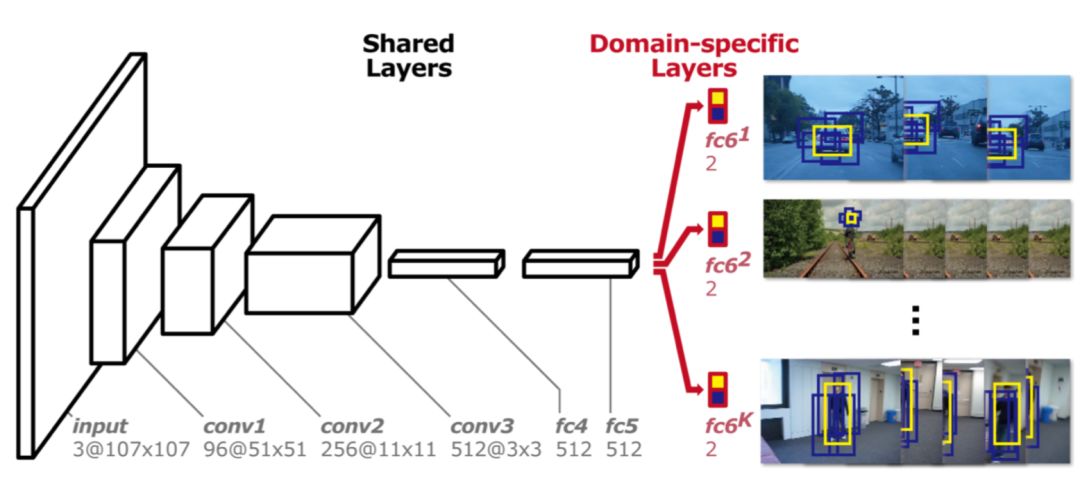
区别与FCNT,MD Net使用视频中所有序列来跟踪它们的运动。但序列训练也存在问题,即不同跟踪序列与跟踪目标完全不一样。最终MD Net提出多域的训练思想,网络结构如下图所示,该网络分为两个部分:共享层和分类层。网络结构部分用于提取特征,最后分类层区分不同的类别。
4.语义分割

计算机视觉的核心是分割过程,它将整个图像分成像素组,然后对其进行标记和分类。语言分割试图在语义上理解图像中每个像素的角色(例如,汽车、摩托车等)。
CNN同样在此项任务中展现了其优异的性能。典型的方法是FCN,结构如下图所示。FCN模型输入一幅图像后直接在输出端得到密度预测,即每个像素所属的类别,从而得到一个端到端的方法来实现图像语义分割。
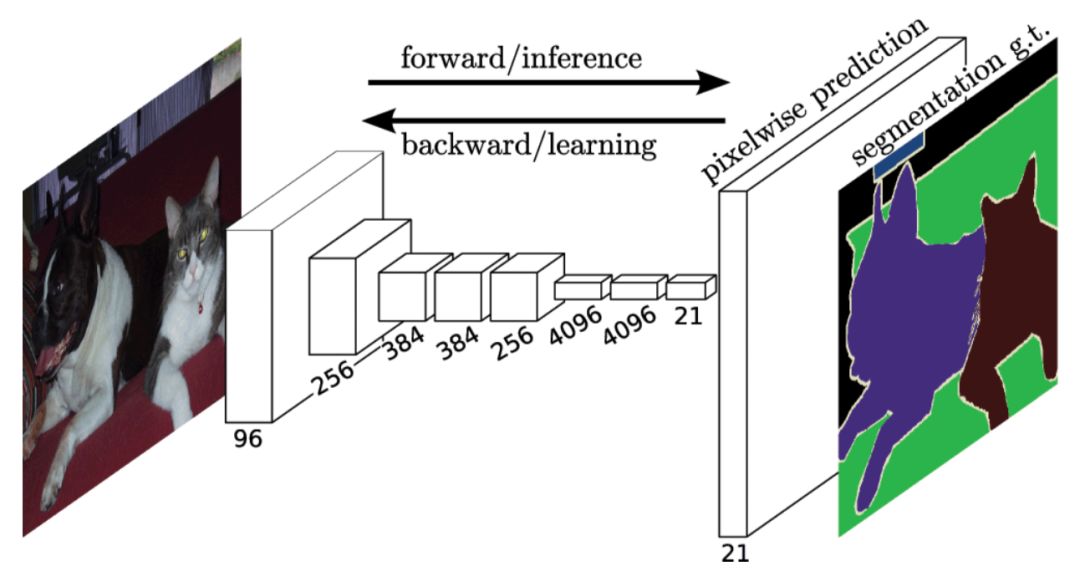
与FCN上采样不同,SegNet将最大池化转移至解码器中,改善了分割分辨率。提升了内存的使用效率。
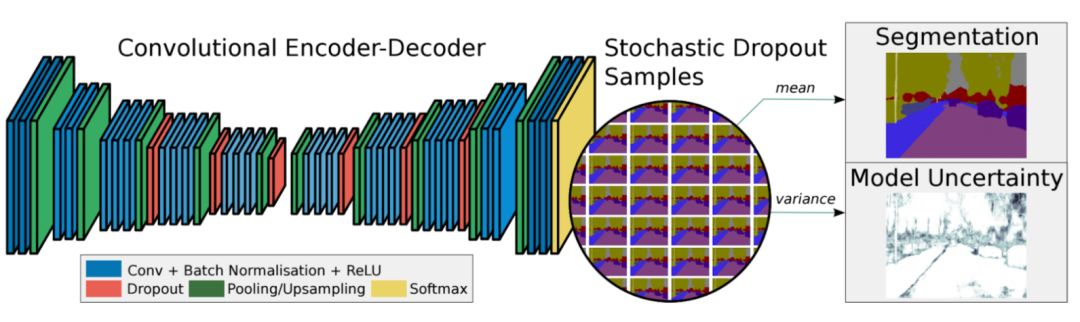
还有一些其他的方法,比如全卷积网络、扩展卷积,DeepLab以及RefineNet等。
5.实例分割

除了语义分割之外,实例分割还分割了不同的类实例,例如用5种不同颜色标记5辆汽车。在分类中,通常有一个以一个物体为焦点的图像,任务是说出这个图像是什么。但是为了分割实例,我们需要执行更复杂的任务。我们看到复杂的景象,有多个重叠的物体和日常背景,我们不仅对这些日常物体进行分类,而且还确定它们的边界、差异和彼此之间的关系。
到目前为止,我们已经看到了如何以许多有趣的方式使用CNN功能来在带有边界框的图像中有效地定位日常用品。我们可以扩展这些技术来定位每个对象的精确像素,而不仅仅是边界框吗?
CNN在此项任务中同样表现优异,典型算法是Mask R-CNN。Mask R-CNN在Faster R-CNN的基础上添加了一个分支以输出二元掩膜。该分支与现有的分类和边框回归并行,如下图所示:
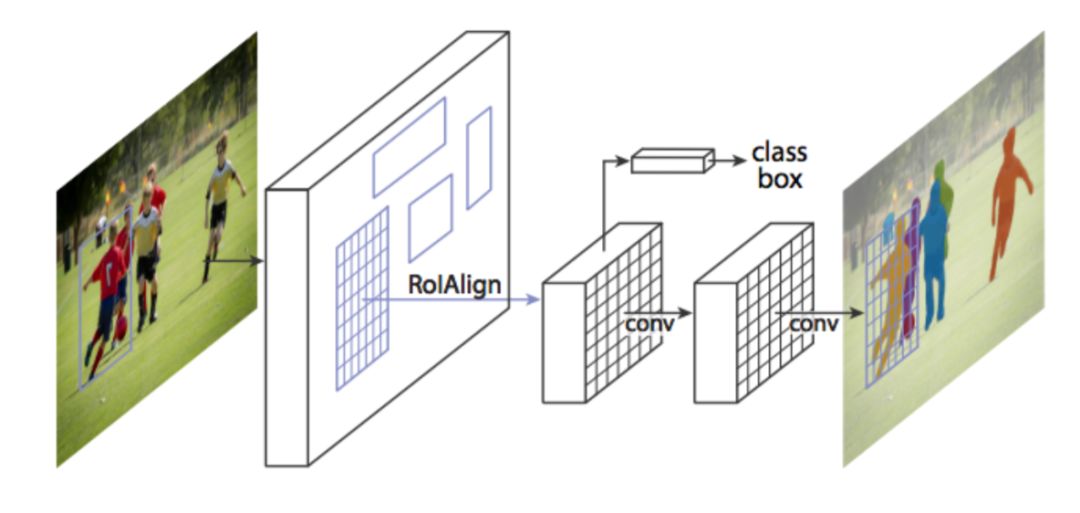
Faster-RCNN在实例分割任务中表现不好,为了修正其缺点,Mask R-CNN提出了RolAlign层,通过调整Rolpool来提升精度。从本质上讲,RolAlign使用双线性插值避免了取整误差,该误差导致检测和分割不准确。
一旦掩膜被生成,Mask R-CNN结合分类器和边框就能产生非常精准的分割:

结论
以上五种计算机视觉技术可以帮助计算机从单个或一系列图像中提取、分析和理解有用信息。此外,还有很多其它的先进技术等待我们的探索,比如风格转换、动作识别等。希望本文能够引导你改变看待这个世界的方式。
责任编辑:lq
-
2026计算机视觉五大技术热点全景解读2026-07-02 565
-
计算机视觉的五大技术2024-07-10 3791
-
计算机视觉的主要研究方向2024-06-06 3416
-
计算机视觉六大主要技术介绍2023-07-11 2117
-
计算机视觉的工作流程与主要应用2021-01-08 6798
-
计算机视觉在智慧城市中的主要应用有哪些2020-12-01 5041
-
计算机视觉中的重要研究方向2020-11-19 13012
-
现代企业计算机视觉发展的主要趋势是什么2020-09-30 3590
-
计算机视觉的发展历史_计算机视觉的应用方向2020-07-30 9434
-
深度学习改变的五大计算机视觉技术2019-07-05 4556
-
计算机视觉与机器视觉区别2018-12-08 14481
-
新计算机架构/机器人等五大技术将改变我们的生活2016-08-15 1503
-
机器视觉与计算机视觉的关系简述2014-05-13 3308
-
基于OpenCV的计算机视觉技术实现2009-11-23 2069
全部0条评论

快来发表一下你的评论吧 !
