

数据库的中间件有啥用?
描述
Part1 数据库中间件有啥用
有一天,你去三亚玩耍,就想玩个冲浪,即时你不差钱,难道还要自己采买快艇、滑板等等装备来满足这为数不多的心血来潮么。租一个就行了嘛。这其实就是连接池的作用。
数据库中间件可以理解为是一种具有连接池功能,但比连接池更高级的、带很多附加功能的辅助组件,不仅可以租冲浪板,还可以提供地点推荐、上保险等等各类服务。
从网上的资料看,zdal应该算是半开源的,好像是之前开源过,但后续没有准备维护,然后就删除了,不过github被fork下来好多,随便一搜就是一片,当前,只是老的版本。目前蚂蚁内部的zdal好像已经更新到zdal5了吧,那咱可就看不到了。
越复杂的系统,数据库中间件的作用越大。就拿zdal来说,它提供分库分表,结果集合并,sql解析,数据库failover动态切换等数据访问层统一解决方案。下面就一起来看下,其内部实现是怎么样的。
Part2 架构剖析之高屋建瓴
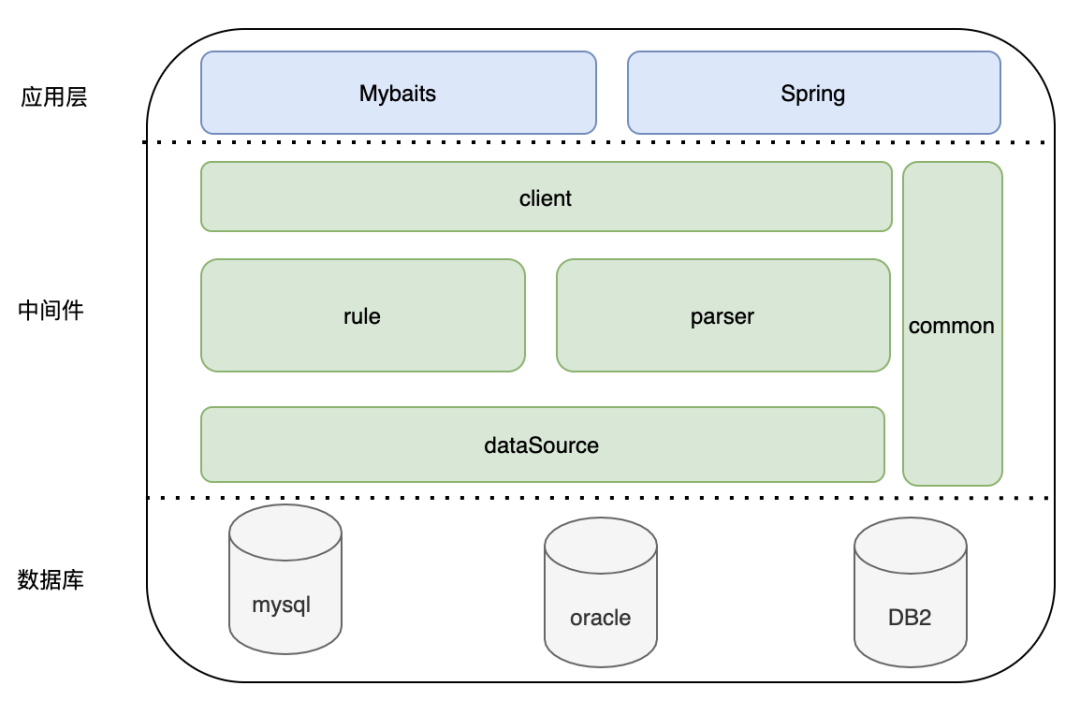
2.1 整体概述
如上图所示,zdal有四个重要的组成部分:
价值体现--客户端Client包。对外暴露基本操作接口,用于业务层简单黑盒的操作数据源;业务只和client交互,动态切换/路由等逻辑只需要进行规则配置,相关逻辑由zdal实现。
核心功能--连接管理datasource包。最核心的能力,提供多种类型数据库的连接管理;不管功能多花哨,最终目的还是为了解决数据库连接的问题。
关键能力--SQL解析parser包。基础SQL解析能力;解析sql类型、字段名称、数据库等等,配合规则进行路由
扩展能力--库表路由rule包。根据parser解析出的字段确定逻辑库表和物理库表。
2.2 组件图看架构
组件图对整体架构和各组件及相互联系的理解可以起到很好的帮助。一个简版的组件图画了好久,还有不少错,不过大概是这么个意思,哎,基本功要丢~
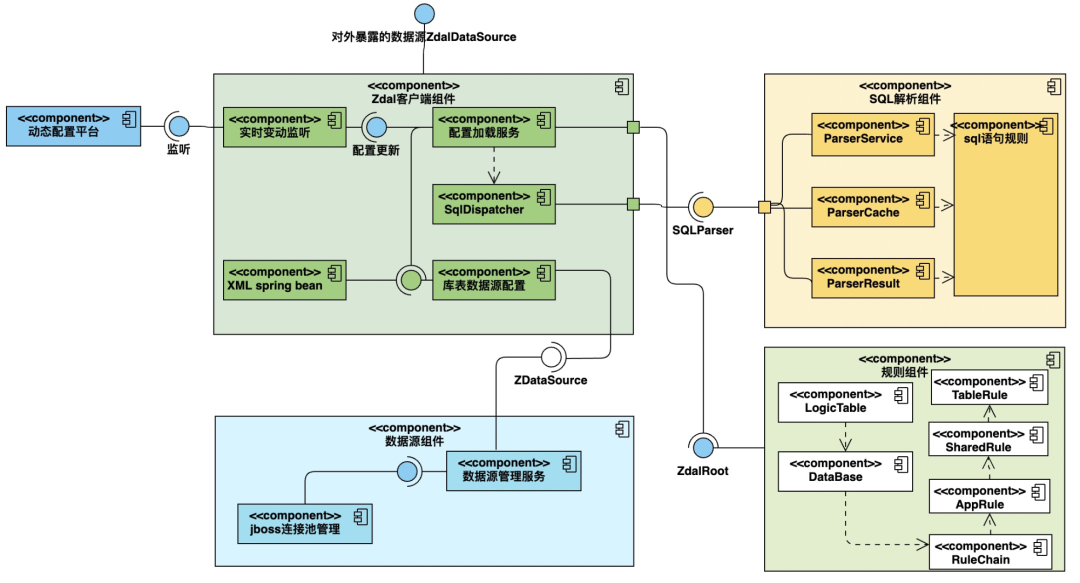
对照上图可以比较清晰的看到:
Client包对应用层暴露的数据源、负责监听配置动态变更的监听组件、负责加载组织各部分的配置组件、负责加载spring bean 和库表规则的配置组件;
Client中加载了规则组件,实现逻辑表和数据库的路由规则。
Client中的库表配置调用datasource中的数据源管理服务并构建连接池的连接池;
Client中的SqlDispatcher服务调用SQL解析组件实现SQL解析。
Part3 细节剖析之一叶知秋
3.1 配置加载和bean初始化
大部分情况下,我们使用如mybatis这样的ORM框架来进行数据库操作,其实不管是ORM还是其他方式,应用层都需要对数据源进行配置。
所以,client对外暴露了一个符合JDBC标准的datasource数据源,用来满足应用层ORM等框架配置数据源的要求--ZdalDataSource
//只提供了一个init方法,这也是spring启动时时,必须要调用的初始化方法,所有功能,都从这里开始
public class ZdalDataSource extends AbstractZdalDataSource implements DataSource{
public void init() {
try {
super.initZdalDataSource();
} catch (Exception e) {
CONFIG_LOGGER.error("...");
throw new ZdalClientException(e);
}
}
ZdalDataSource#init()方法即为配置加载的核心入口,init中负责加载spring配置,根据配置初始化数据源,并创建连接池,同时,将逻辑表和物理库的对应关系都维护起来供后续路由调用。
/*父类的init方法*/
protected void initZdalDataSource() {
/*用FileSystemXmlApplicationContext方式加载配置文件中的数据源和规则,转化成zdalConfig对象*/
this.zdalConfig = ZdalConfigurationLoader.getInstance().getZdalConfiguration(appName,dbmode, appDsName, configPath);
this.dbConfigType = zdalConfig.getDataSourceConfigType();
this.dbType = zdalConfig.getDbType();
//初始化数据源
this.initDataSources(zdalConfig);
this.inited.set(true);
}
}
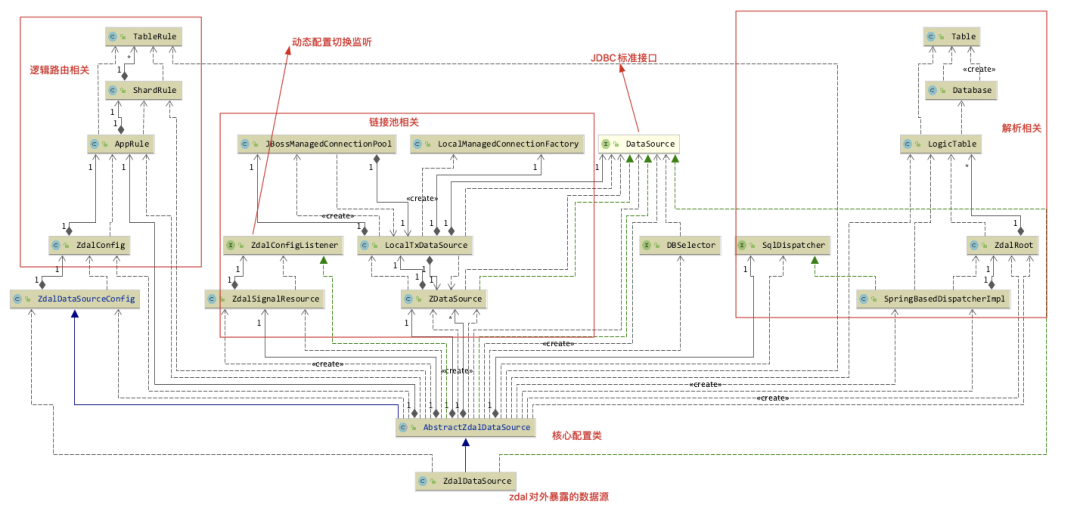
从上面的类图和这里的两个入口方法大概了解到zdal配置加载的启动流程。下面我们就来详细看一下,读写分离和分库分表的规则是怎么被加载,怎么起作用的。
3.2 细说读写分离
读写分离配置的加载
首先,我们需要有数据源的相关配置,如下图:

此XML配置会在init方法被调用时,被初始化,解析成ZdalConfig类的属性,ZdalConfig类的主要成员见下面代码:
public class ZdalConfig {
/** key=dsName;value=DataSourceParameter 所有物理数据源的配置项,比如用户名,密码,库名等 */
private Map dataSourceParameters = new ConcurrentHashMap();
/** 逻辑数据源和物理数据源的对应关系:key=logicDsName,value=physicDsName */
private Map logicPhysicsDsNames = new ConcurrentHashMap();
/** 数据源的读写规则,比如只读,或读写等配置*/
private Map groupRules = new ConcurrentHashMap();
/** 异常转移的数据源规则*/
private Map failoverRules = new ConcurrentHashMap();
//一份完整的读写分离和分库分表规则配置
private AppRule appRootRule;
可以看到,xml中的规则,被解析到xxxRules里。这里以groupRules为例,failover同理。
下一步则是通过解析得到的zdalConfig 来初始化数据源:
protected final void initDataSources(ZdalConfig zdalConfig) {
//DataSourceParameter中存的是数据源参数,如用户名密码,最大最小连接数等
for (Entry entry : zdalConfig.getDataSourceParameters().entrySet()) {
try {
//初始化连接池
ZDataSource zDataSource = new ZDataSource(/*设置最大最小连接数*/createDataSourceDO(entry.getValue(),zdalConfig.getDbType(), appDsName + "." + entry.getKey()));
this.dataSourcesMap.put(entry.getKey(), zDataSource);
} catch (Exception e) {
//...
}
}
//其他分支略,只看最简单的分组模式
if (dbConfigType.isGroup()) {
//读写配置赋值
this.rwDataSourcePoolConfig = zdalConfig.getGroupRules();
//初始化多份读库下的负载均衡
this.initForLoadBalance(zdalConfig.getDbType());
}
//注册监听:为了满足动态切换
this.initConfigListener();
}
initForLoadBalance的方法如下:
private void initForLoadBalance(DBType dbType) {
Map dsSelectors = this.buildRwDbSelectors(this.rwDataSourcePoolConfig);
this.runtimeConfigHolder.set(new ZdalRuntime(dsSelectors));
this.setDbTypeForDBSelector(dbType);
}
可以看到,首先构建出了DB选择器,然后赋值给了runtimeConfigHolder供运行时获取。而构建DB选择器的时候,其实是按读写两个维度,把所有数据源都构建了一遍,即group_r和group_w下都包含5个数据源,只不过各自的权重不一样:
//比如按上面的配置写库只有一个,但是也会包含全数据源
group_0_w_0 :< bean:read0DataSource , writeWeight:0>
group_0_w_1 :< bean:writeDataSource , writeWeight:10>
group_0_w_2 :< bean:read1DataSource , writeWeight:0>
group_0_w_3 :< bean:read2DataSource , writeWeight:0>
group_0_w_4 :< bean:read3DataSource , writeWeight:0>
//上述就是写相关的DBSelecter的内容。
读写分离怎么起作用
以delete为例,更新删除是要操作写库的
public void delete(ZdalDataSource dataSource) {
String deleteSql = "delete from test";
Connection conn = null;
PreparedStatement pst = null;
try {
conn = dataSource.getConnection();
pst = conn.prepareStatement(deleteSql);
pst.execute();
} catch (Exception e) {
//...
} finally {
//资源关闭
}
}
getConnection会从上文中提到的runtimeConfigHolder中获取DBSelecter,然后执行execute方法
public boolean execute() throws SQLException {
SqlType sqlType = getSqlType(sql);
// SELECT相关的就选择group_r对应的DBSelecter
if (sqlType == SqlType.SELECT || sqlType == SqlType.SELECT_FOR_UPDATE|| sqlType == SqlType.SELECT_FROM_DUAL) {
//略
return true;
//update/delete相关的就选择group_w对应的DBSelecter
} else if (sqlType == SqlType.INSERT || sqlType == SqlType.UPDATE|| sqlType == SqlType.DELETE) {
if (super.dbConfigType == DataSourceConfigType.GROUP) {
executeUpdate0();
} else {
executeUpdate();
}
return false;
}
}
如果是读取相关的,那就选_r的DBSelecter,如果是写相关的,那就选_W的DBSelecter。那么executeUpdate0中是怎么执行区分读写数据源的呢,其实就是把这一组的数据源根据权重筛选一遍。
// WeightRandom#select(int[], java.lang.String[])
private String select(int[] areaEnds, String[] keys) {
//这里的areaEnds数组,是一个累加范围值数据
//比如三个库权重 10 9 8
//那么areaEnds就是 10 19 27 是对每个权重的累加,最后一个值是总和
int sum = areaEnds[areaEnds.length - 1];
//这样随机出来的数,是符合权重分布的
int rand = random.nextInt(sum);
for (int i = 0; i < areaEnds.length; i++) {
if (rand < areaEnds[i]) {
return keys[i];
}
return null;
}
Part4 总结
本篇文章,把阿里数据库中间件相关的组件和加载流程进行了总结,就一个最基本的分组读写分离的流程,对内部实现进行了阐述。说是解析,其实是提供给大家一种阅读的思路,毕竟篇幅有限,如果对中间件感兴趣的同学,可以fork下代码,按上述逻辑自己阅读下。
看源码时,比如dubbo这些中间件其实是比较容易入手的,因为他们都依托于Spring进行JavaBean的装载,所有,对Spring容器暴露的那些init、load方法,就是很好的切入点。个人思路,希望对大家有所帮助。
责任编辑:lq6
,>,>,>,>,>,>,>,>,>,>-
oracle数据库中间件有哪些2023-12-05 4334
-
基于ARM的RFID中间件系统该怎么设计?2019-10-09 2206
-
面向云数据库的属性基加密和查询转换中间件2019-01-15 1179
-
谈分布式数据库中间件之分库分表2018-08-02 2415
-
基于ARM平台的RFID中间件系统设计2017-12-07 1090
-
常见的中间件有哪些?汇总解析2017-12-01 56127
-
基于.NET数据持久层中间件设计2017-11-08 1161
-
为什么要使用Keil MDK-ARM中间件库?2014-10-13 2940
-
基于ARM的RFID中间件系统设计2011-09-16 1252
-
基于JMS的RFID中间件设计与实现2010-10-19 899
-
中间件在产业链协同平台的应用和研究2010-01-09 855
-
基于嵌入式RFID中间件的标签数据处理2009-12-28 522
-
基于双层中间件的网格数据库访问与集成2009-12-16 837
-
基于ERP系统的消息中间件设计与实现2009-04-22 856
全部0条评论

快来发表一下你的评论吧 !
