

基于CPX8000系列工控机和CPCI总线实现双机通信系统的设计
描述
作者:尚长兴,俞定玖,季新生
在电信、电力、国防等应用领域中,经常要求其所用设备有极高的实时性。当需要在各个设备间进行大容量的信息交换时,传统的网络包交换模式已不能很好地满足实时性的要求。而借助于CPCI总线,两个设备可以互访对方的内存,具有传输速度快、传输容量大和高可靠性等特点,非常适合大容量的信息传递。国家数字交换系统工程技术研究中心承担的国家863计划项目——“中国第三代移动通信系统”CDMA2000系统集成就选择基于CPCI总线的多SBC平台。各个SBC间的通信效率直接决定了整个系统性能的高低。
目前常用的实时操作系统如VxWorks、Lynx等,都针对CPCI总线实现了消息队列,可用于SBC间的消息通信。但VxWorks、Lynx中消息传递的实现方式很不灵活,一般是通过在一个特定的SBC(通常为system board)中开启一块共享内存,其他各个SBC(通常为non system board)通过对共享内存的读写交换信息;每完成一次两个non system SBC间的信息交换,都要进行一次PCI读写操作,效率不高。另外VxWorks、Lynx中的消息长度都有一个最大值,当要进行大数据量(如1GB的内存数据库)的信息传输时,操作系统提供消息传递机制也无能为力。而以上这些问题,都可以通过任意两个SBC间的直接内存访问得到解决。本文首先介绍了PCI Bridge的工作原理;然后以Motorola公司提供的CPX8000系列工控机为例,讨论了两个SBC是如何基于背板(Backplane)上的CPCI总线,并利用PCI Bridge的地址映射机制,通过互访内存的方式最终实现双机通信;最后介绍了实际应用时应注意的性能优化问题。
1 PCI Bridge的工作原理
在简单的计算机系统中,其拥有的外部设备较少,单级总线结构便能满足系统的需要。但是由于单个 PCI总线可支持的 PCI 设备数量有电气限制,对拥有大量外设的计算机系统而言,单级总线结构已不能满足系统的要求,因此便产生了桥接设备。通过PCI-to-PCI Bridge可扩展出新的PCI总线,通过PCI-to-ISA Bridge可扩展出ISA总线。借助PCI Bridge这些特殊的PCI设备,系统中各级总线被粘和在一起,使整个系统成为一个有机整体。
每个PCI设备都有自己的PCI I/O空间、PCI内存空间和PCI配置空间(configuration space)。PCI设备的设备驱动程序对PCI配置空间进行初始化设置后,各个智能控制器如CPU、DMA控制器等,可以对PCI设备的PCI I/O空间、PCI内存空间进行访问。在图1中,CPU若要访问网卡,首先会在PCI Bus0上生成一个物理地址,这个地址经PCI-to-PCI Bridge的过滤及转换后,在PCI Bus1上产生一PCI Bus地址,网卡通过地址译码,响应对这个地址的访问。
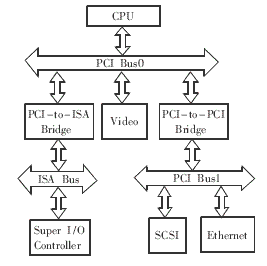
图1 基于PCI的系统
从这个过程可以了解到,PCI-to-PCI Bridge有两种基本的功能:
(1)地址映射功能。虽然同是对网卡进行访问,但PCI Bus0与PCI Bus1上的地址意义是不同的。两个地址分属各自的地址空间,通过PCI-to-PCI Bridge实现两个地址的映射。根据这两个地址是否相同,可将PCI-to-PCI Bridge区分为两种类型:
·PCI-to-PCI Transparent Bridge。PCI Bridge不对PCI Bus0上的地址进行转换,直接将其映射到PCI Bus1上。PCI Bus0与PCI Bus1上的地址是相同的。
·PCI-to-PCI Non Transparent Bridge。PCI Bus0上的地址必须经过PCI Bridge的转换,才能映射到PCI Bus1上。PCI Bus0与PCI Bus1上的地址是不同的。
(2)地址过滤功能。PCI Bridge在把PCI Bus0上的地址向下游总线(ISA Bus、PCI Bus1)传递时,具有选择性。在图1中,CPU在PCI Bus0上所产生的地址,只有对SCSI和Ethernet的访问,PCI-to-PCI Bridge才予以接收;而对于PCI Bus0的其他地址,PCI-to-PCI Bridge均不予响应。每一个PCI Bridge所响应的地址范围,可形象地称其为此PCI Bridge的地址窗口,只有当上游总线的地址落进PCI Bridge的地址窗口中,PCI Bridge才响应此地址并向下游总线传递。
2 双机通信的具体实现
本节以Motorola公司提供的CPX8000系列工控机为例,介绍了如何通过CPCI总线实现双机间的通信。如图2所示,两个SBC通过背板上的CPCI总线实现了物理上的连接。如果两个SBC能够互相访问对方的内存,就可实现两者间的数据交流。以系统处理机板(System Processor Board,又称主机板)访问非系统处理机板(Non-system Processor Board, 又称子机板)内存为例,介绍双机通信的具体实现。本方案已在Lynx及VxWorks实时操作系统上实现。
在图2中,主机板CPU若要访问子机板中的1MB内存单元,必须将这块内存映射到主机板CPU的虚拟地址空间中,可以通过对主机板、子机板、主机板与子机板的接口配置来达到目的。此1MB的内存单元可被映射到不同的地址空间(如CPU虚拟地址空间、物理地址空间、本地PCI地址空间、系统CPCI地址空间等),映射地址也各不相同。在图2中,对于此1MB内存的起始单元在不同地址空间中的映射地址,分别用符号A1、A2、…A7表示。
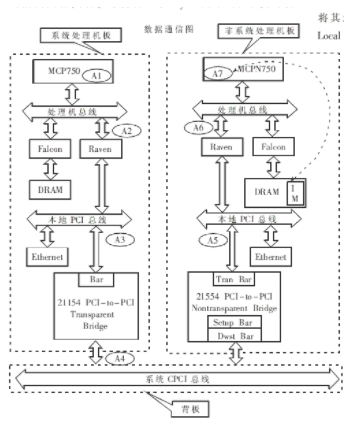
图2 数据通信原理图
2.1 子机板的配置
(1)调用内核内存分配函数申请1MB的内核虚拟地址空间,得到申请空间的开始地址A7。
(2)根据操作系统的内存映射关系,得到虚拟地址A7的物理映射地址A6。
(3)Raven ASIC是一个Host-to-PCI Bridge,因为Processor Bus不是一个标准总线,所以通过Raven将其转换为PCI总线,以挂接各类PCI设备。CPU和Raven一起构成了一组套片(chipset),配合使用。根据Raven的设置,获得物理地址A6在Local PCI Bus的映射地址A5。
(4)21554是一PCI-to-PCI Non Transparent Bridge,并可进行双向数据传递。通过其内部的两个配置寄存器,将其地址窗口的大小设为1MB;地址窗口的起始地址在Local PCI Bus端设为A5。
2.2 主机板的配置
(1)申请大小1MB的内核虚拟地址空间,得到其开始地址A1。
(2)根据操作系统的内存映射关系,得到虚拟地址A1的物理映射地址A2。
(3)根据Raven的设置,得到物理地址A2在Local PCI Bus上的映射地址A3。
(4)21154是一PCI-to-PCI Transparent Bridge,它也可以在两个方向上进行数据访问。设置其内部的两个配置寄存器,将其地址窗口的大小设为1MB;地址窗口的起始地址设置为A3。由于21154的透明性,地址A3与其在System CPCI Bus端的映射地址A4的值是相同的。
2.3 主机板与子机板的接口配置
在主机板端对子机板进行配置,设置21554的配置寄存器,将其在System CPCI Bus端的地址窗口开始地址设为A4。由于在Local PCI Bus端的地址窗口起始地址已设为A5,所以将地址A4映射到了地址A5。可以看到,由于21554的非透明性,使主机板与子机板的地址空间相互隔离,各自可独立分配,并在System CPCI Bus级实现了对接。在主机板CPU看来,整个子机板与主机板网卡一样,都是挂在主机板Local PCI Bus下的一个外设。对子机板的访问与对主机板网卡的访问方式是一样的,没有什么不同。
2.4 地址转换流程
当所有的配置完成后,主机板CPU只对地址A1进行读写操作,便可实现对子机板1MB内存起始单元的访问;对1MB内存中其他单元的访问,只要将地址A1加上相应的偏移量即可。通过下面的地址转换流程,可以清楚地看到各级地址是如何通过一级级映射,最终命中指定单元的。
主机板CPU给出虚拟内存访问地址A1→主机板物理地址A2→主机板Local PCI Bus地址A3→System CPCI Bus地址A4→子机板Local PCI Bus地址A5→子机板物理地址A6→经Falcon Memory Controller译码后,选中所申请的1MB内存的起始单元。
从上述介绍可以看出,要想实现双机的内存互访,关键是要进行正确的地址映射。当要实现多个SBC间的相互访问时,地址的映射会更复杂,需要对操作系统的地址空间分配、各个SBC的PCI-to-PCI Bridge设置、System CPCI Bus地址空间分配等进行通盘考虑。
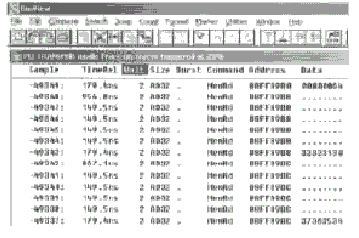
?图3 在两SBC间进行读操作时的时间图
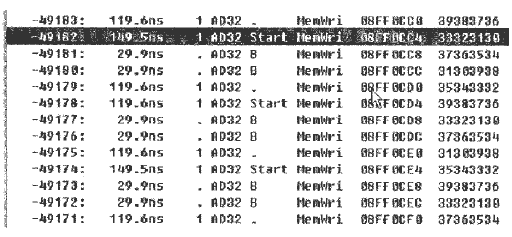
图4 在两SBC间进行写操作时的时间图
3 性能优化
图3、图4是用VMETRO的总线分析仪截获的数据。分别是在两个SBC间进行读写访问时,连续进行100 Byte传输的时间图。
从图3可以看出,每进行一次4Byte的读操作,要花费956.8+4×149.5+179.4=1734.2ns,这相当于1734.2ns/29.9ns=58 PCI clock cycles。
从图4可以看到,第一个4Byte的写操作花费了159.5ns,接着是两次猝发传送,随后一个4Byte写操作花费了119.6ns。进行一次4Byte的写操作平均花费(159.5ns+2×29.9ns+119.6ns)/(4×29.9ns)=11 PCI clock cycles。
对比读写两种访问方式可以看出,写操作比读操作的效率要高得多。这主要有以下一些原因:
(1)当PCI上的一个主设备发起对一个目标设备的访问时,读和写操作的完成时间差别很大。目前的PCI设备中一般都有一个用于存储器写的转发(post)缓冲器。若要进行写操作(如图2中主机板对子机板的写操作),主设备只需将其写缓冲区数据复制到目标设备的转发缓冲器中,便认为操作完成。例如在图2中,主机板的Raven只要将数据发给21154,便认为写操作完成,后续的数据传输由21154驱动完成。可以看到,写操作在目的总线上(子机板的Process Bus)完成之前可以先在源总线上(主机板的Local PCI Bus)完成,实际上是寄存器对寄存器的操作。而要实现一个读操作,则必须经过存储器本身的访问和各级PCI接口的逻辑延迟才可完成。与写操作相比,读操作在源总线上完成之前必须先在目的总线上完成,这导致了读操作的效率很低。(2)从图3、图4中可以看到,PCI设备还可进行写操作的猝发操作,但读操作则无法进行。这是由于猝发操作只有在前一事务是写事务时才能实现。猝发传送取消了FRAME#、AD、C/BE#、IRDY#、TRDY#、DEVSEL#等总线信号的周转周期,实现了每一个PCI clock cycle进行一次数据传送。 (3)猝发传送操作不可能无限制地进行下去。连续进行猝发传送的次数与转发缓冲器的大小、Latency Timer的取值、总线的繁忙状况都有关系。
由于以上原因,在两个SBC间进行数据传送时,应该采用如下方式: (1)提供数据的SBC应将数据直接写到消费数据的SBC内存中;而不是提供者将数据放在本地内存,再由消费者经过PCI读操作来实现。也就是说,总是进行PCI写操作。(2)当需要在多个SBC间进行数据互传时,要合理地设置Latency Timer的取值,以使各SBC公平使用PCI总线资源。考虑两个子机板间的通信实现。若采用操作系统提供的消息传递机制,数据提供者必须先将数据写到主机板,数据消费者再从主机板读取数据。对一个4 Byte的数据传输来说,平均要花费58+11=69 PCI clock cycles。若采用本文提供的方法,提供数据的SBC将数据直接写到消费数据的(接上页) SBC内存中,则传输一个4 Byte的数据,平均只需11 PCI clock cycles。可知,后者比前者快了69/11≈6.3倍,极大提高了传输效率。
责任编辑:Gt
-
坦克系列基础款工控机介绍2025-09-08 891
-
工控机怎么编程?工控机是如何控制设备的?2024-10-31 2849
-
如何怎样选择CPCI工控机2024-09-18 1536
-
工控机的组成部件有哪些?常用的工控机类型和组成部件介绍2024-08-01 2364
-
工控机怎样度 CAN 总线2024-06-18 1519
-
工控机的技术要求 工控机的系统有哪些2023-03-15 3454
-
工控机高速背板2023-01-04 9503
-
工控机的软件系统有哪些2021-08-18 5146
-
工控机如何实现多屏显示2021-07-09 6630
-
请问一下双机通信在CPCI总线上怎么实现?2021-06-03 1702
-
工控机的作用与特点2020-05-13 15646
-
工控机总线连接2017-10-20 1439
-
嵌入式工控机PC/104在CAN现场总线通信中应用2009-08-05 710
全部0条评论

快来发表一下你的评论吧 !
