

深度学习中动作识别网络学习
描述
动作识别网络
深度学习在人体动作识别领域有两类主要的网络,一类是基于姿态评估,基于关键点实现的动作识别网络;另外一类是直接预测的动作识别网络。关于姿态评估相关的网络模型应用,我们在前面的文章中已经介绍过了。OpenVINO2021.2版本中支持的动作识别网络都不是基于关键点输出的,而是基于Box直接预测,当前支持动作识别的预训练模型与识别的动作数目支持列表如下:
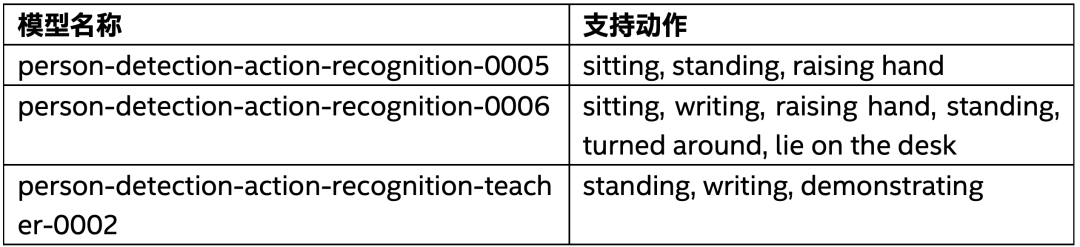
表-1
这些网络的输出都是基于SSD检测头实现对象检测与动作预测。
输入与输出格式
以person-detection-action-recognition-0005模型为例说明它们的输入与输出数据格式支持,我也不知道什么原因(个人猜测因为Caffe框架的原因),网络的输出居然都是SSD原始检测头,怎么解析,我有妙招,稍后送上!先看一下输入与输出格式说明:
输入格式:
格式 NCHW=[1x3x400x680] ,Netron实际查看:
注意:OpenVINO2021.2安装之后的文档上格式说明是NHWC
输出格式:
输出有七个分支头的数据,它们的名称跟维度格式列表如下:
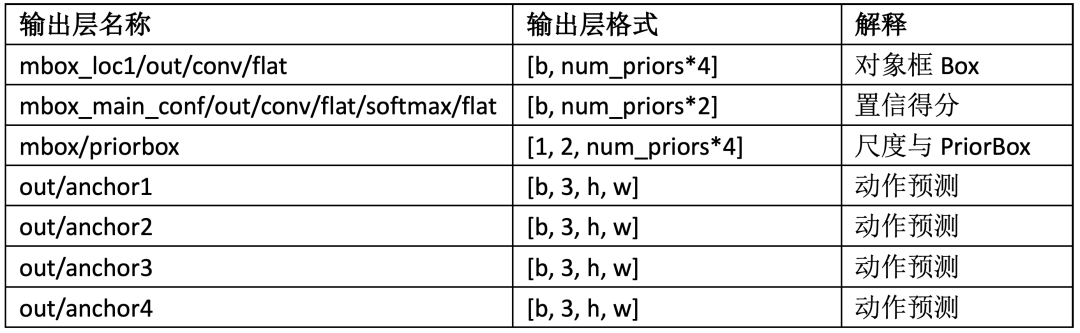
表-2
关于输出格式的解释,首先是num_priors值是多少,骨干网络到SSD输出头,是实现了16倍的降采样,最终输出的h x w=25x43然后每个特征点预测4个PriorBox, 每个特征点预测动作,总计有三类的动作,所以动作预测输出为: [b, 3, h, w] = [1x3x25x43],总计PriorBoxes数目为:num_priors=25x43x4=4300,这些都是SSD检测头的原始输出,没有非最大抑制,没有经过转换处理,所以想直接解析它们对开发应用的人来说是一个大麻烦!
输出数据解析与处理问题
person-detection-action-recognition-0005网络推理之后的输出数据解析跟后处理特别的复杂,怎么解析原始输出头是个技术活,我从示例代码中提取跟整理出来两个C++文件,它们是:
action_detector.h
cnn.h
以及它们的实现文件:
action_detector.cpp
cnn.cpp
这个其中最重要的就是有个ActionDetection类,它有几个方法,分别是:
void enqueue(const cv::Mat &frame)
void submitRequest()
void wait()
DetectedActions fetchResults()
这几个方法的解释分别如下:
enqueue方法的就是实现了推理请求创建与图像数据的输入设置,它的代码实现如下:
if (!request) {
request = net_.CreateInferRequestPtr();
}
width_ = static_cast《float》(frame.cols);
height_ = static_cast《float》(frame.rows);
Blob::Ptr inputBlob = request-》GetBlob(input_name_);
matU8ToBlob《uint8_t》(frame, inputBlob);
enqueued_frames_ = 1;
submitRequest方法,就是执行推理,支持同步与异步推理执行模型,它的代码实现如下:
if (request == nullptr) return;
if (isAsync) {
request-》StartAsync();
}
else {
request-》Infer();
}
wait方法,当同步推理时候无需调用,异步推理调用
fetchResults方法,该方法是推理过程中最复杂的部分,负责解析输出的七个分支数据,生成Box与action标签预测。简单的说它的执行过程是这样,首先获取输出的七个输出数据,然后转换为基于Mat的数据,然后循环每个特征图的特征点预测Box与置信得分,大于阈值的置信得分对应的预测Box与PriorBox计算真实的BOX坐标,同时阈值化处理Action的置信得分,最终对结果完整非最大抑制之后输出,得到数据结构为:
struct DetectedAction {
/** @brief BBox of detection */
cv::Rect rect;
/** @brief Action label */
int label;
/** @brief Confidence of detection */
float detection_conf;
/** @brief Confidence of predicted action */
float action_conf;
这样就完成了对输出的数据解析。
这个就是上述四个相关依赖文件,我已经把其他不相关的或者非必要的依赖全部去掉,基于这四个相关文件,就可以实现对表-1中动作识别模型的推理与解析输出显示。
动作识别代码演示
动作识别代码演示基于person-detection-action-recognition-0005网络模型完成,该模型是基于室内场景数据训练生成的,适合于教育智慧教室应用场景。首先需要初始化动作检测类与初始化推理引擎加载,然后配置动作检测类的相关参数,这些参数主要包括以下:
- 模型的权重文件路径
- 推理引擎的计算设备支持
- 对象检测阈值
- 动作预测阈值
- 支持动作类别数目
- 是否支持异步推理
等等。
配置完成之后设置与初始化ActionDetection类,然后就可以直接调用上述提到几个类方法完成整个推理与输出,根据输出结果绘制与显示即可,这部分的代码如下:
cv::Mat frame = cv::imread(“D:/action_001.png”);
InferenceEngine::Core ie;
std::unique_ptr《AsyncDetection《DetectedAction》》 action_detector;
// Load action detector
ActionDetectorConfig action_config(model_xml);
action_config.deviceName = “CPU”;
action_config.ie = ie;
action_config.is_async = false;
action_config.detection_confidence_threshold = 0.1f;
action_config.action_confidence_threshold = 0.1f;
action_config.num_action_classes = 3;
action_detector.reset(new ActionDetection(action_config));
action_detector-》enqueue(frame);
action_detector-》submitRequest();
DetectedActions actions = action_detector-》fetchResults();
std::cout 《《 actions.size() 《《 std::endl;
for (int i = 0; i 《 actions.size(); i++) {
std::cout 《《 actions[i].rect 《《 std::endl;
std::cout 《《 actions[i].label 《《 std::endl;
cv::rectangle(frame, actions[i].rect, cv::Scalar(0, 0, 255), 2, 8, 0);
putText(frame, action_text_labels[actions[i].label], actions[i].rect.tl(), cv::FONT_HERSHEY_SIMPLEX, 0.75, cv::Scalar(0, 0, 255), 2, 8);
}
cv::imshow(“动作识别演示”, frame);
cv::waitKey(0);
return 0;
责任编辑:haq
- 相关推荐
- 热点推荐
- 深度学习
-
深度学习在汽车中的应用2019-03-13 4070
-
深度学习介绍2022-11-11 875
-
什么是深度学习?使用FPGA进行深度学习的好处?2023-02-17 2187
-
基于视频深度学习的时空双流人物动作识别模型2018-04-17 1952
-
图像识别中的深度学习2018-05-25 5746
-
什么是深度学习,深度学习能解决什么问题2020-11-05 5550
-
基于深度学习的人脸识别算法与其网络结构2021-03-12 4675
-
3小时学习神经网络与深度学习课件下载2021-04-19 1725
-
基于深度学习的行为识别算法及其应用2021-06-16 1185
-
什么是深度学习(Deep Learning)?深度学习的工作原理详解2022-04-01 13835
-
基于深度学习的车牌识别侦测网络模型2023-02-19 1542
-
什么是深度学习算法?深度学习算法的应用2023-08-17 3521
-
深度学习在语音识别中的应用及挑战2023-10-10 1917
-
深度学习与卷积神经网络的应用2024-07-02 2352
-
深度学习中的无监督学习方法综述2024-07-09 3330
全部0条评论

快来发表一下你的评论吧 !
