

基于Keystone SoC实现LTE基站的应用开发
描述
作者:TI公司 Adam Yao
LTE层2处理的特点
层2在LTE中位于层1(物理层)和层3(RRC, RRM, S1-AP等协议)之间,它的作用是屏蔽层1的细节,向层3提供可用的服务接入点(SAP)。LTE中的层2在下行方向上依次通过PDCP, RLC和MAC 3个子层(如图1)。每个子层处理之前的数据叫做服务数据单元(SDU),处理之后的数据叫做协议数据单元(PDU) ,PDU是对SDU的数据加以一些特殊的处理,同时添加一个本子层特定的协议头所形成的。上行方向处理与下行类似,只是3 个子层通过的顺序相反。PDCP层主要完成数据包头的压缩与解压缩(ROHC),数据内容的加密与解密,以及向上层PDU的顺序递交。RLC层根据MAC层的调度结果对PDCP的PDU进行拆分和重组,同时实现ARQ的功能。MAC层主要实现与调度和HARQ相关的功能,包括逻辑信道向传输信道的映射,对RLCPDU的复用与解复用,HARQ纠错与重传等。
从实现的角度看,一般将MAC层中的调度和优先级管理作为一个单独的模块,称为调度器(Scheduler)。调度器要根据空口的状态和网络当前要发送的数据量以及优先级,对空口资源进行实时的分配,是一个计算密集型的模块。将PDCP,RLC和MAC层中的复用组包功能定义为另一个模块,称为用户面,这部分主要根据协议的规定完成加头,去头,合并,拆分,加密,解密等处理,是一个数据吞吐密集型的模块。因为LTE采用全IP的网络架构,所有用户面处理的包都是TCP/IP的包,本文所介绍的Pktlib就是针对这种包类型,结合TI公司Keystone SoC中的硬件队列管理器(QMSS)所开发的一个软件包,它能提高层2用户面的处理效率,实现基于硬件队列的内存管理和真正的数据零拷贝,同时接口简单,便于用户移植。
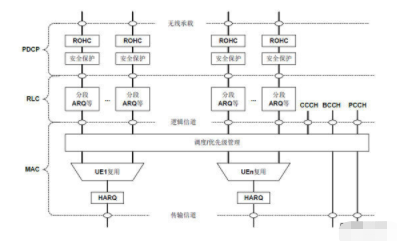
图1:LTE层2下行结构
2. QMSS和Pktlib
QMSS是Keystone上集成的硬件队列管理器。每一个硬件队列都由一组特定的寄存器控制,用户通过读写寄存器完成包的入队和出队。队列中的包要满足QMSS特定的格式要求。一个包由包描述符(PD)和对应的缓存组成,包的所有属性信息都保存在PD中,包中的缓存可以分片,不同的分片之间地址可以不连续,每一个分片的属性保存在对应的缓存描述符(BD)中。满足这种格式的包可以压入硬件队列,同一个队列中包的前后链接关系由硬件维护。图2画出了硬件队列和其中的包的结构。在Keystone上,这种格式的包可以直接压入硬件加速器和外设(如以太网和SRIO)的发送队列(这些发送队列也属于QMSS所管理的硬件队列),进行硬件加速处理或数据发送。

图2:硬件队列和包格式图
Pktlib是TI基于QMSS封装的一个软件开发包,它采用QMSS的包作为基本的内存管理单元,将硬件队列虚拟为内存申请的堆,通过包的指针操作替代了内存的拷贝,拼接和分割。Pktlib的主要函数接口和功能如下表。
表1: Pktlib主要函数和功能

3. 基于Pktlib的层2内存管理
层2是一个基于包处理的模块,在处理中需要临时申请大量的内存,内存管理的效率是影响层2处理性能的关键因素。传统的层2处理一般直接采用操作系统的内存管理模块,完全通过软件来管理内存,这种处理方法在软件处理和加速器处理接口的地方必须做一次数据拷贝,把加速器处理完的数据从加速器的缓存区中拷贝到软件的缓存中。这种拷贝在大量的包处理中极大地影响了效率。同时传统的内存管理方法因为无法通过软件直接保证多核互斥,在多核共享内存的管理上效率很低。
基于Pktlib的内存管理能解决传统内存管理的问题。以LTE下行处理为例,在Keystone上PDCP层的空口安全保护在安全加速器(SA)中完成,其后需要用软件完成RLC和MAC层的处理,然后将处理完的包交给物理层进行编码。层2和物理层的接口根据芯片功能划分有两种选择:物理层可以在其他芯片上完成(这时需要将层2处理完的数据打包通过以太网或SRIO 发送出去),也可以在本芯片上完成(这时可以将层2处理完的数据直接发送给物理层的加速器BCP)。层2软件和SA,BCP,SRIO,EMAC这些加速器或外设的接口都符合QMSS的包格式,并可以通过硬件队列来完成数据的传输。
图3画出了一个基于Pktlib的层2下行的内存管理架构。它的基本思想是在创建堆的时候将通过操作系统申请的固定长度的内存块直接挂接到PD上,然后压入专用的硬件队列(图2的Mem FreeQ),这个硬件队列就相当于一个堆。应用在初始化完Pktlib的Mem FreeQ以后,通过调用Pktlib_allocPacket函数从堆上申请(出队)内存包并将它压入SA的接收空闲队列(Rx FreeQ)。当SA处理完一个PDCP包的空口加密工作后会把数据通过接收侧包DMA(Rx Pkt DMA)写入Rx FreeQ中包指向的内存,然后将包从Rx FreeQ出队,压入接收队列(RxQ)。RLC和MAC层软件接收到调度器的调度请求后,从SA的RxQ出队对应的包并进行RLC和MAC的组包工作。在这个处理过程中,因为涉及到包的分割,合并,添加包头的工作,RLC和MAC模块会动态地申请新的内存,这时同样通过调用Pktlib_allocPacket函数从Mem FreeQ中申请包。
RLC和MAC层处理完成后,软件可以将处理完的包直接压入和物理层接口的发送队列(TxQ)中,后面可以是通过加速器直接做物理层编码,也可以是通过接口发送数据。发送侧包DMA(Tx Pkt DMA)读入包之后,可以自动将包返回一个队列(Tx ReturnQ)。Tx ReturnQ 的选择有两种情况需要分开考虑。对于可以立即释放的包(这个包中PD/BD所指向的缓存没有被其他的PD/BD指向),可以通过QMSS直接回收到Mem FreeQ. 还有一类包不能立即释放,这个包中内存同时还被另一个PD指向(这在包的拷贝,分割中经常出现)。对第二种类型的包,我们需要先让QMSS把包回收到一个临时的回收队列(Tx ReturnQ)中,然后调用Pktlib_freePacket接口,Pktlib会根据这个包的属性以及是否进行过拷贝,切割这些信息,决定是马上将包回收到Mem FreeQ,还是等到所有指向同一个缓存的PD都使用完这个缓存后,再将包回收到Mem FreeQ。从上面的描述我们可以看到,层2下行软件和处理流程前后的两个加速器/外设接口发生了数据交互,但是中间没有任何的数据拷贝,处理效率大大优于传统的方案。
Keystone中的硬件队列可以自动完成多核访问的互斥,由此带来的好处是多核可以同时使用一个Pktlib创建好的堆,同时不需要加入效率较低的互斥锁保护。对于多核同时进行层2处理的方案,这一点也能在一定程度上节省软件的开销。

图3:基于Pktlib的层2下行内存管理
4 基于Pktlib的层2零拷贝数据处理
层2处理中经过PDCP层处理的包保存在硬件队列中,RLC和MAC模块需要根据调度器提供的调度结果对PDCP处理的包进行重新封装,在这个过程中需要添加RLC协议头,MAC协议头,还需要对PDCP包进行切割,重组(因为调度结果是根据当前空口状态产生的,跟PDCP的包长不可能匹配)。传统的做法是采用内存拷贝,软件开销比较大。采用Pktlib可以通过相应的函数实现零拷贝,提高层2处理效率。
包的合并
层2处理中有很多包的合并操作,常见的场景有:
(1) 在处理PDCP,RLC,MAC 层协议的时候添加对应的协议头。
(2) RLC收到调度结果后需要将两个或多个PDCP的PDU打包为一个RLC的PDU
(3) MAC复用需要将多个RLC的PDU打包为一个MAC的PDU如图4 所示,通过调用Pktlib_packetMerge函数可以将输入的两个QMSS格式的包合并为一个新的包。这一操作实际上是将包1的Next指针置为包2的P地值,在合并的过程中没有任何的内存拷贝。

图4:包的合并
包的拷贝
层2处理中包的拷贝主要发生的RLC包进入重传缓冲区,RLC协议在AM模式下对处理完成的包在提交给MAC进行处理的同时,还必须拷贝一份放入重传缓冲区。如果接收端发出了重传请求,下一次RLC会从重传缓冲区取出数据重发。只有在收到接收端的确认后,RLC才能释放重传缓存区中的包。
如图5所示,Pktlib在做包的拷贝时不是通过内存拷贝来实现的,而是通过将传入的一组空的PD按照原始包的结构重新链接一次。拷贝后,包1和包2的PD/BD不同,但是PD/BD所指向的内存是同一块。这种包的拷贝(其实包的切割也会出现相同的问题)要求在包的释放时只有在确认同一块内存所关联的所有包都被使用完了之后,才能进行内存的释放。在Pktlib_freePacket函数中会查找当前包下所有PD/BD所指向内存所关联的所有PD/BD的当前情况,如果还有PD/BD在使用这块内存就不立即释放,只有在所有PD/BD都不使用这块内存了,才会将它释放。

图5: 包的拷贝
包的分割
层2处理中包的分割操作,主要有下面两个场景:
(1) RLC收到调度结果后需要将一个PDCP的PDU分割为两个或多个RLC的PDU
(2) MAC复用需要一个RLC 的PDU分割为两个或多个MAC的PDU如图6所示,Pktlib在做包的分割时是通过传入一个空的PD,然后用这个PD指向切割的字节位置构造出新的包。从图中可以看到切割后包1缓存2和包2缓存1在同一个内存块上,只有当这两个包都不在使用这块内存之后,这个内存块才能得到释放。

图6: 包的分割
Pktlib的性能
使用Pktlib的API能够完全替换传统的基于OS的内存管理,并且能实现零拷贝的包合并,复制和分割,在内存处理的效率上大大优于传统方案。下表列出了在TI公司TMS320C6614 芯片上测试得到的函数性能。
表2: Pktlib主要函数的性能

总结
TI在Keystone上提供的Pktlib能够实现硬件和软件内存管理的统一,实现基于包的数据合并,拷贝,分割,以及软件与硬件加速器之间完全的零拷贝数据传递。这些特点正好适应了LTE层2中大批量包数据处理的要求。结合Pktlib进行LTE基站层2软件的开发,能极大地提高包的处理效率,在硬件规格不变的情况下提供更高的系统吞吐率。本方案为基于Keystone SoC的LTE基站开发提供了一个有益的参考。
责任编辑:gt
-
一种面向LTE基站的SOC平台软件解决方案2018-02-05 3294
-
以全新的多核SoC架构进行LTE开发2011-07-14 3321
-
LTE基站天线解决方案2019-07-17 2528
-
如何对TD-LTE基站进行性能测试?2021-04-30 1598
-
小蜂窝基站在LTE网络中有什么作用?2021-05-21 1299
-
如何利用WiMAX SoC去设计多扇区基站?2021-05-28 1621
-
中国TD系统如何实现向TD-LTE发展?2021-06-01 1505
-
小型蜂窝基站面临的挑战2022-11-17 728
-
TI扩展其KeyStone多核架构2011-12-08 835
-
TI基于KeyStone的SoC系统助力PureWave高性能小型蜂窝户外基站2012-05-28 1031
-
基于Keystone SoC的LTE基站开发2017-09-15 945
-
KeyStone多核SoC工具套件2017-10-27 996
-
基于BSC9132开发LTE小基站设计2017-11-06 1665
-
SK电讯开发家庭基站干涉控制技术 提升了LTE网络的客户体验2019-03-20 842
-
KeyStone I器件的SerDes实现指南2024-10-12 487
全部0条评论

快来发表一下你的评论吧 !
