

串行RapidIO交换器的应用优势
MEMS/传感技术
描述
串行RapidIO交换器的应用优势
EMIF6? 是由 Texas Instruments 开发的一款专利接口,在业内应用多年,反响良好。但是,EMIF6? 现正用于从未尝试的 DSP 至 DSP 连接等应用。本文阐述了与以相同有效带宽运行的串行 RapidIO交换器相比,采用 FPGA 的八端口 EMIF6? 交换器具有的优缺点。
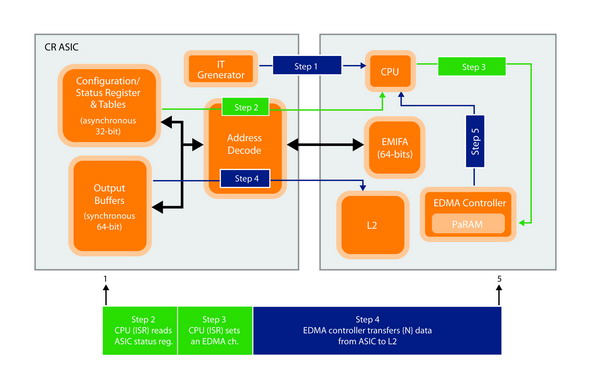
EMIF 标准是一种成熟、稳定的并行外部存储器接口,且已在许多应用中证明大有益处。但其能力仅限于主机,且需要昂贵的 CPU 中断服务程序,以便将系统内其他主机的数据传入设备。支持 EMIF 接口可能还需要庞大的软件开销(取决于数据传输的大小及频率)。图 1 所示的是传统的EMIF 应用示例,通过CPU 中断+ EDMA 方法从 CR ASIC 传至 DSP 的传输形式。
通过选择串行 RapidIO 等先进的系列接口,可实现诸多一般优点:
* 可配置性及性能 – RapidIO以 1.25、2.5 及 3.125Gb的速率支持每个链接,且可支持多达八个 4x链接或十六个 1x 链接。具有确定性及低延时的特点,且提供无阻塞交换矩阵架构。
* 控制 – RapidIO 具有可配置的 CPU 中断控制、支持错误管理及通过性能监控统计支持拥塞控制等特点。它还提供用于硬件错误恢复的 CRC 处理。
* 软件支持 – 纳入硬件终止端点从而实现较低的软件开支。另外,RapidIO 只要求低水平的配置及功能支持,同时提供高度抽象的信息传递 API。它还具有 CPU 开销无需由传输数据的大小决定(例如通过少量控制讯息)的优点。
 |
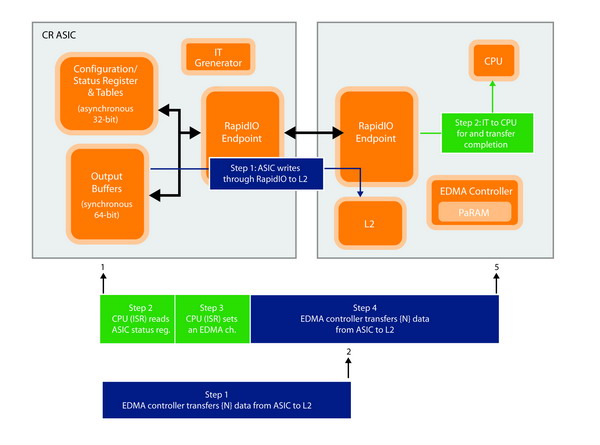 |
图2显示与图1相同的应用,而在实施时采用串行 RapidIO。采用此方法而不选择 EMIF6? 的具体优点可概述为以下几点:
* 灵活性 –EMIF6? 的局限性包括:它不是一个开放式标准接口,且其带宽限于 8Gb/s 半双工。另外,它并非可扩展的解决方案。相反,串行 RapidIO 具有开放式标准接口、带宽可扩展至高达 20Gb/s 及可扩展架构。
* 性能 – EMIF6? 属于损耗系统,不会存储和转发,也不会提供数据的优先次序。另外,通过交换器时还具有不可确定的延时。串行 RapidIO 是无损耗系统,可保证数据包传送具有四个优先次序等级。通过交换器时具有可确定的延时。
* 开发成本 – 当采用 EMIF6? 接口时,需要 FPGA 设计及确认资源。需承担的测试平台费用不可低估,且最后需要持续的产品支持。但是,采用串行 RapidIO,无需进行硅设计,且由于 EMIF6?的相对I/O 要求更高,因此执行本解决方案的成本较低。同时,PCB 的复杂性降低----单个 6? 位 EMIF 接口需要大约 97 只引脚,意味着八个端口的交换器只需要 776 只接口引脚----因此可降低成本。
* 其他优点 – 串行 RapidIO 提供 CRC 处理,可实现基于硬件的错误恢复,而EMIF6? 无错误检测/纠正。另外,后者不会提供状态或确认反馈,而串行 RapidIO 提供错误管理及报告功能。此外,较宽的并行接口比串行接口占用更多的 PCB 空间。
两种解决方案基本相同的一点是功率需求。使用相等的带宽配置时二者的端点功耗大致相同。当在6?位模式下以133MHz 工作频率运行时,EMIF 具有 8Gb/s 的半双工带宽。当在x4 模式下以1.25Gb/s 工作频率运行时,串行 RapidIO 具有4Gb/s 的全双工带宽。尽管交换器功耗取决于如何实施FPGA 及所包括的功能,但有关功耗大致相同。
图3显示Tundra Tsi578串行 RapidIO 交换器的组件示意图,该款交换器是 80Gb/s 全双工串行RapidIO 交换器,符合开放式标准及第1.3版(最新版本)串行 RapidIO 互连规范。适用于网状、矩阵架构与集成系统的高度可扩展解决方案 Tsi578,可为设计人员及架构工程师提供配置选项,以匹配各种网络、无线及视频基础架构应用的精确 I/O 带宽需求。它可配置高达八个 4x 链接或高达十六个1x 链接,且每个4x 链接可分解为两个 1x 链接。该款交换器支持 1.25、2.5 及 3.125Gb的速率,每个端口可配置为 1.25、2.5 或 3.125Gb/s。有关端口完全独立,且交换器支持混合的速度及带宽配置。
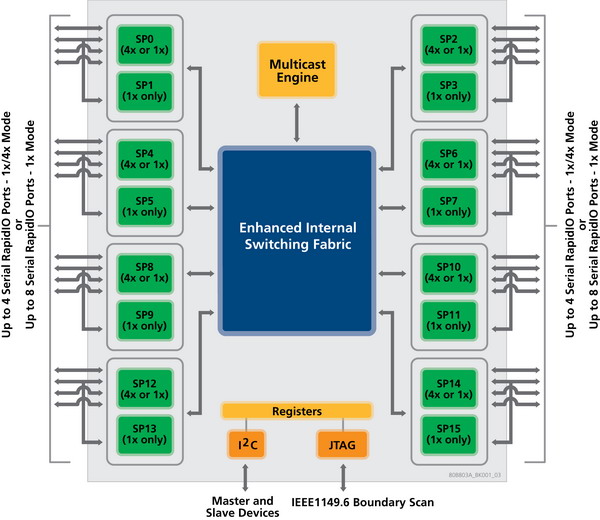 |
易用特点包括“热插拔”-带电插入或拔出现场可代替单元。在一般性能方面,该款交换器借助数据包直通功能实现低延时,并为线速终端和无阻塞交换矩阵架构提供全双工运行,并防止线路中枢发生堵塞。它还具有集成可编程的 XAUI SerDes功能。Tsi578 采用0.13um CMOS技术及27mmx27mm尺寸和675球栅的FCBGA封装,可向后兼容其上代产品 Tsi568A。
第三代 Tsi578 交换器采用创新的交换矩阵架构管理以提高下一代通信基础架构平台的数据吞吐量,包括ATCA及MicroATCA应用。这款交换器可向6?000多个端点发送数据包,并且具有独立的单播与多播路由机制及错误管理扩展功能,对于这些平台大有助益。
多播路由可以 80 Gb/S 的总带宽将支持串行 RapidIO 的处理器与外围设备同时互连。此外,广泛的无阻塞交换矩阵架构管理功能包括监控和管理通信量的矩阵架构监控、向矩阵架构控制器提供主动通知问题的错误管理、保证带宽的可编程缓存深度以及独立的单播与多播路由机制。通过明显良好的吞吐量、增强的性能监控统计及高级调度算法来提高通信量。
Tsi578的端口配置极为灵活性,同时采用低功耗、高速SerDes 以轻松地优化功耗。为了有助于简化信号通道路由,该款交换器还支持I/O 通道交换。此设备要求 1.2V 及 3.3V 电源轨,可在工业及商业额定温度范围内工作。该款交换器还支持高速互连的 ACGA 版 IEEE 1149.6 JTAG 标准。
结论
Tundra Tsi578 交换器与 Texas Instruments TMS320C6?55 结合可为采用 DSP 群集的任何应用提供最高系统级性能。由传统的 DSP EMIF转向串行 RapidIO 交换方法可实现强大、功能丰富的设计,从而扩展至多个DSP密度。串行 RapidIO 交换器的成本不到 FPGA EMIF6? 交换器成本的一半,此外,前者所需的开发资源远比后者少。
若使用硬件终止串行 RapidIO 端点,将极大地降低 DSP 软件支持。最后,通过 DSP 群集 MIPS 的累积节省可提高整体系统性能及价值。
- 相关推荐
- 热点推荐
- 交换器
-
rapidio交换芯片是什么2024-03-16 3438
-
热交换器工作原理_热交换器清洗方法2019-11-22 21265
-
板式热交换器的作用_板式热交换器的优缺点2019-11-12 13097
-
热交换器哪个牌子好_家用热交换器好用吗?2017-10-26 11853
-
全热交换器种类有哪些?全热交换器优缺点2017-10-20 12005
-
基于串行RapidIO的Buffer层设计2017-01-07 709
-
全新Serial RapidIO Gen2交换器系列2010-06-28 2120
-
热交换器使用效率提升技术手册2010-04-16 758
-
基于FPGA的串行RapidIO-PCI转接桥设计2009-04-01 502
全部0条评论

快来发表一下你的评论吧 !
