

你真的了解Zynq的学习吗?
描述
一、简介部分
Zynq是由两个主要部分组成的:一个是由双核 ARM CortexA9 构成的处理系统 (PS),另一个是等价于一片 FPGA 的可编程逻辑 (PL)。它还具有集成的存储器、各种外设和高速通信接口。这个架构实现了工业标准的 AXI 接口,在芯片的两个部分之间实现了高带宽、低延迟的连接。
PL 部分用来实现高速逻辑、算术和数据流子系统是很理想的,而 PS 支持软件程序或操作系统,具有固定的架构,承载了处理器和系统存储区。这就意味着任何被设计的系统的整个功能可以恰当地在硬件和软件之间做出划分。
PL 和 PS 之间的链接采用了工业标准的高级可扩展接口(Advanced eXtensible Interface,AXI)连接方式。这两部分可以单独使用,也可以合起来用,而且实际上供电电路被设计成独立给每个部分供电,这样 PS 或 PL 部分不被使用的话就可以被断电。
二、处理器系统部分(PS)
作为处理器系统的基础,所有的芯片都包含了一颗双核 ARM Cortex-A9 处理器。这是一颗“ 硬 ”处理器 —— 它是芯片上专用而且优化过的硅片元件。Xilinx 的MicroBlaze这样的“软” 处理器,是由可编程逻辑部分的单元组合而成的。
也就是说,一个软处理器的实现和部署在 FPGA 的逻辑结构里的任何其他 IP 核是等价的。一般来说,软处理器的优势是处理器实例的数量和精确实现是灵活的。从另一方面来说,硬处理器可以获得相对较高的性能,Zynq 的 ARM 处理器正是如此。
Zynq 的处理器系统里并非只有 ARM 处理器,还有一组相关的处理资源,形成了一个应用处理器单元 (Application Processing Unit,APU) ,另外还有扩展外设接口、cache 存储器、存储器接口、互联接口和时钟发生电路 。下图是 PS 部分架构框图,其中高亮的部分就是 APU。
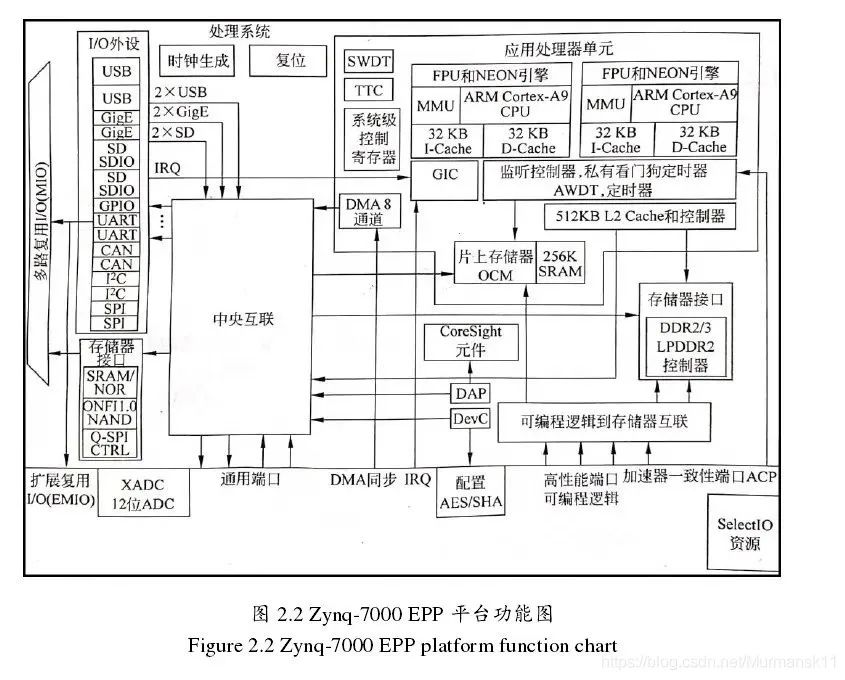
2.1 应用处理单元(APU)
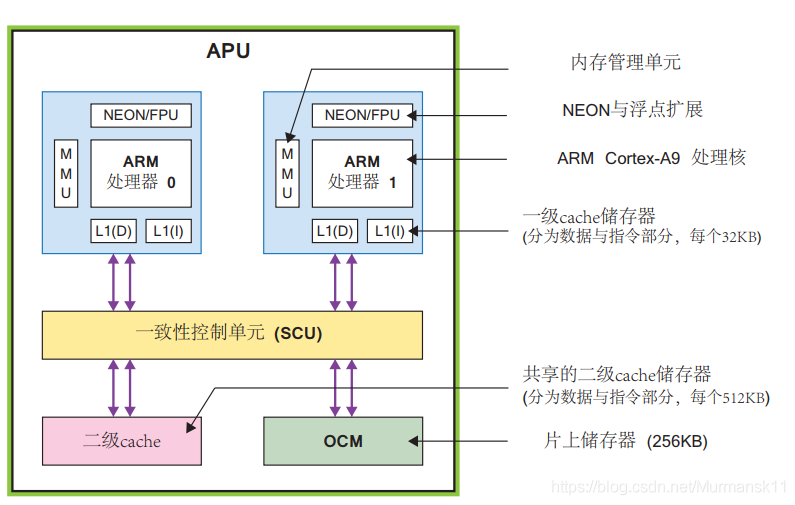
APU 主要是由两个 ARM 处理核组成的:最高工作频率1GHz;
一个 NEONTM 媒体处理引擎(Media Processing Engine,MPE)和浮点单元 (Floating Point Unit,FPU);
一个内存管理单元 (MemoryManagement Unit,MMU);在虚拟地址和物理地址之间做翻译;
一个一级 cache 存储器(分为指令和数据两个部分)APU 里还有一个二级 cache 存储器;高速缓冲,在CPU与内存储器之间;
片上存储器 (On Chip Memory,OCM);
一致性控制单元 (Snoop Control Unit,SCU);在ARM和二级cache,OCM之间形成桥连接;
2.2 处理器系统外部接口
Zynq PS 实现了众多接口,既有 PS 和 PL 之间的,也有 PS 和外部部件之间的。
(1)PS和外部接口之间的通信
PS 和外部接口之间的通信主要是通过复用的输入 / 输出( Multiplexed Input/Output,MIO)实现的,它提供了可以做灵活配置的 54 个引脚,这表明外部设备和引脚之间的映射是可以按需定义的。
三、可编程逻辑部分(PL)
Zynq 架构的第二个主要部分是可编程逻辑。这是基于 Artix-7 和 Kintex-7的 FPGA 组件的。
3.1 逻辑部分
PL 主要是由通用 FPGA 逻辑部分组成的,这个 FPGA 是由逻辑片(slice)和可配置逻辑块 (Configurable Logic Block,CLB)组成的,另外还有用于接口的输入/输出块 (Input/ Output Block,IOB)
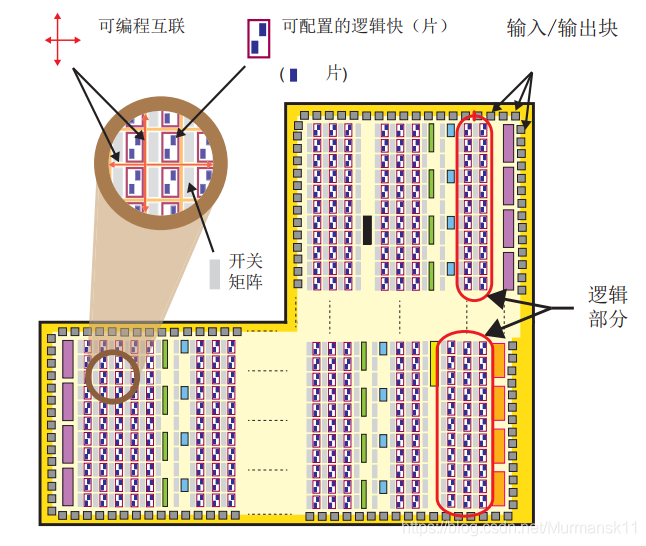
• 可配置逻辑块 (CLB) — CLB 是逻辑单元的小规模、普通编组,在 PL 中排列为一个二维阵列,通过可编程互联连接到其他类似的资源。每个 CLB 里包含两个逻辑片(slicem或slicel),并且紧邻一个开关矩阵。
• 片 (Slice) — CLB 里的一个子单元,里面有实现组合和时序逻辑电路的资源。Zynq 的片是由 4 个查找表、8 个触发器和其他一些逻辑所组成的。
• 查找表 (Lookup Table,LUT) — 一个灵活的资源,可以实现: 1.至多 6个输入的逻辑函数;2.一小片只读存储器 (ROM);3.一小片随机访问存储器 (RAM);4.一个移位寄存器。LUT 可以按需组合起来形成更大的逻辑函数、存储器或移位寄存器。
• 触发器(Flip-flop,FF) — 一个实现 1 位寄存的时序电路,带有复位功能。FF 的一种用处是实现锁存。
• 开关矩阵 (Switch Matrix) — 每个 CLB 旁都有一个开关矩阵,实现灵活的布线功能来1.连接 CLB 内的单元;2.把一个 CLB 与 PL 内的其他资源连接起来。
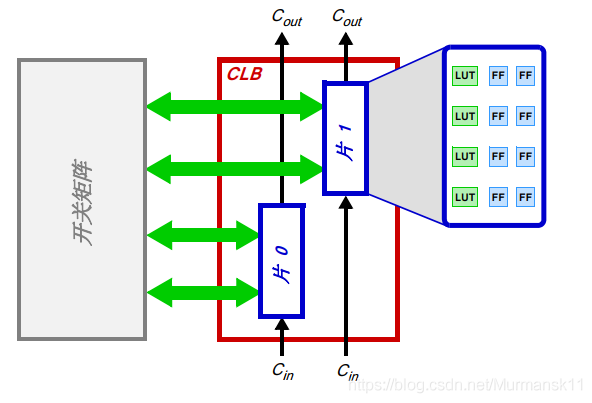
• 进位逻辑 (Carry Logic) — 算术电路需要在相邻的片之间传递信号,这就是通过进位逻辑来实现的。进位逻辑把布线和复用器组成链条来连接一个垂直列上的片。
• 输入 / 输出块 (Input/Output Blocks,IOB) — IOB 实现了 PL 逻辑资源之间的对接,并且提供物理设备 “ 焊盘 ” 来连接外部电路。每个 IOB 可以处理一位的输入或输出信号。IOB 通常位于芯片的周边。
尽管逻辑部分的内部结构知识对于设计者是有用的,但是大多数情况下并不需要专门地指定这些资源 ——Xilinx 工具会自动根据设计来安排所需的 LUT、 FF、IOB 等,然后做好相应的映射。但我还是觉得对底层的电路结构有一个清楚的认识,对以后的学习会有很大的帮助。
3.2 特殊资源:DSP48E1和块RAM
除了通用的部分,还有两个特殊用途的部件:满足密集存储需要的块 RAM 和用于高速算术的 DSP48E1 片。这两个资源都按列排列集成在逻辑阵列中,嵌入在逻辑部分中,而且往往彼此靠近 (因为密集计算和在内存中存储数据往往是紧密联系的运算)。
每个块 RAM 可以存储最多 36KB 的信息,并且可以被配置为一个 36KB 的 RAM 或两个独立的 18KB RAM。默认的字宽是 18 位,这样的配置下每个 RAM 含有 2048 个存储单元2Kx18位。RAM 还可以被 “ 重塑 ” 来包含更多更小的单元(比如 4096 个单元 x9 位,或 8192x位),或是另外做成更少更长的单元(如 1024 单元 x36 位,512x72 位) 。把两个或多个块 RAM 组合起来可以形成更大的存储容量。它们可实现 RAM、ROM 和先入先出 (First In First Out,FIFO)缓冲器,同时还支持纠错编码 (Error Correction Coding,ECC)块 RAM 往往还能用芯片所支持的最高时钟频率来工作。
分布式 RAM (Distributed RAM) ,这是用逻辑部分里的 LUT 来搭建的。用分布式 RAM 实现小存储器往往是有优势的,既是因为资源利用率,也是因为这样的布局更灵活 (分布式存储可以靠近与之相互作用的部件,这样也就能有更快的时序性能)。
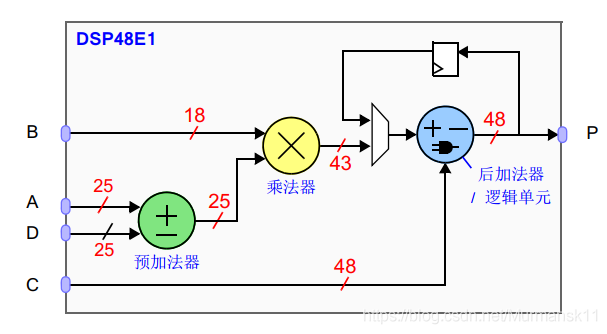
(2)DSP48E1
逻辑部分里的 LUT 可以用来实现任意长度的算术运算,但是最合适的是做短字长的算术运算 (长字长的算术电路会在逻辑片中占据较大的空间,这样的布局和布线因素会使得时钟频率是次优的)。
DSP48E1是专门用于实现对长字长信号的高速算术运算的逻辑片。这些都是专用的硅片资源,并且在逻辑单元内主要包含了预加法器/减法器乘法器和后加法器/减法器。
四、处理器系统与可编程逻辑的接口
Zynq 的表现不仅仅依赖于它的两个组成部分 PS 和 PL 的特性,还在于能把两者协同起来形成完整、集成的系统的能力。这其中起关键作用的,是一组高度定制的 AXI 互联和接口用来在两个部分之间形成桥梁。
4.1 AXI标准
AXI 表示的是高级可扩展接口 (Advanced eXtensible Interface)AXI 总线可以灵活使用,而且一般情况下是用来在一个嵌入式系统中连接处理器和其他 IP 核的。实际上有三类 AXI4,每一类代表了一种不同的总线协议,下面会有总结。对于一个特定的连接选择哪个 AXI 总线协议是基于那个连接所需的特性的。
• AXI4 — 用于存储映射链接,它支持最高的性能:通过一簇高达 256 个数据字 (或 “ 数据拍 (data beats)”)的数据传输来给定一个地址。
• AXI4-Lite — 一种简化了的链接,只支持每次连接传输一个数据(非批量) 。AXI4-Lite也是存储映射的:这种协议下每次传输一个地址和单个数据。
• AXI4-Stream — 用于高速流数据,支持批量传输无限大小的数据。没有地址机制,这种总线类型最适合源和目的地之间的直接数据流 (非存储器映射)
4.2 AXI互联接口
在 PS 和 PL 之间的主要连接是通过一组 9 个 AXI 接口,每个接口有多个通道组成。这些形成了 PS 内部的互联以及与 PL 的连接。
• 互联(Interconnect) — 互联实际上是一个开关,管理并直接传递所连接的AXI 接口之间的通信。在 PS 内有几个互联, 其中有些还直接连接到 PL ,而另一些是只用于内部连接的。这些互联之间的连接也是用 AXI 接口所构成的。
• 接口 (Interface) — 用于在系统内的主机和从机之间传递数据、地址和握手信号的点对点连接。
• 通用 AXI(General Purpose AXI) — 一条 32 位数据总线,适合 PL 和 PS 之间的中低速通信。接口是透传的不带缓冲。总共有四个通用接口:两个 PS 做主机,另两个 PL 做主机。在PS-PL Configuration中的GP Master/Slave AXI Interface中可以启用该接口
• 加速器一致性端口(Accelerator Coherency Port) — 在 PL 和 APU 内的 SCU之间的单个异步连接,总线宽度为 64 位。这个端口用来实现 APU cache 和 PL的单元之间的一致性。PL 是做主机的。ACP接口允许对PL主机进行低延迟访问,带有可选的coherency和L1、L2缓存。从系统角度来看,ACP接口具有与APU CPU类似的连通性,因此ACP可以直接在APU块争取资源。在PS-PL Configuration中的ACP Slave AXI Interface中可以启用该接口
• 高性能端口(High Performance Ports) — 四个高性能 AXI 接口,带有 FIFO缓冲来提供 “ 批量 ” 读写操作,并支持 PL 和 PS 中的存储器单元的高速率通信。数据宽度是 32 或 64 位,在所有四个接口中 PL 都是做主机的。4个AXI_HP接口为PL总线主程序提供了到DDR和OCM内存的高带宽数据通道,每个接口有两个用于读写通信的FIFO缓冲区。内存互连的PL将高速AXI_HP端口布线到两个DDR内存端口或OCM。AXI_HP接口也可以用作AXI_FIFO接口,利用其缓冲能力。简而言之,这种接口为PL主机和PS内存(DDR或OCM)之间提供了一种高吞吐量数据通道。在PS-PL Configuration中的HP Slave AXI Interface中可以启用这些接口。
本文转自:
https://blog.csdn.net/Murmansk11?type=blog
编辑:jq
-
学习单片机真的有必要学习汇编2013-08-18 4110
-
电房门控开关,你真的了解吗?!2015-04-12 3678
-
频率和时序,你是否真的了解呢?2021-06-18 1654
-
你真的了解快充吗?2021-07-26 2048
-
ZYNQ的学习笔记分享2022-02-08 1168
-
看过那么多文章,你真的了解ZigBee吗?2016-03-07 16136
-
你真的了解轮毂电机么?2017-04-17 1378
-
深度学习是什么?了解深度学习难吗?让你快速了解深度学习的视频讲解2018-08-23 1463
-
Zynq-7000 All Programmable SoC电源管理技术的了解2018-11-22 4655
-
你真的了解边缘设备吗?学习边缘计算技能需求2020-10-24 6816
-
ZYNQ学习笔记_ZYNQ简介和Hello World2021-12-22 1624
-
【Linux+C语言】你真的了解system接口的调用吗?2022-09-12 5942
-
8类双绞线你真的了解吗2022-12-15 2865
-
光纤面板你真的了解吗-科兰2023-06-07 2421
-
RFID和NFC之间的那些事儿,你真的了解吗?2023-12-15 3827
全部0条评论

快来发表一下你的评论吧 !
