

T-S-T三级交换网络路径搜索算法的研究
通信新闻
描述
T-S-T三级交换网络路径搜索算法的研究
1 引 言
光纤通讯技术的飞速发展使得目前高速通讯网络性能的瓶颈集中在高速交换系统,研究、设计和制造高速交换系统对目前高速通讯网络具有极其重要的意义。而且随着电信网和计算机网络的高速发展,高速大容量的交叉连接或交换设备和芯片的性能也在大幅度的提高。同时由于现在的交换机在不停地更新换代,对新的交换算法的需求也在不断增加。
本文的研究工作旨在利用矩阵置换的思想,模拟开发一种基于T(时分)-S(空分)-T(时分)交换网络的调度算法。提出一种新的三级交换的矩阵模型,并在这种模型上设计相应的无阻塞交换算法。利用矩阵作为数学模型,可以利用矩阵的置换操作搜索交换的设置。算法设计和实现的过程中,大量的实验表明,本算法具有良好的特性,而且通过芯片级联可实现。
本算法不同于以往的基于图论的寻径调度算法,力图通过对这个算法的研究,为未来的大型综合数字交换网络奠定理论和实践基础,并为变化多端的网络环境下快速建立有保障的网络服务提供先期的技术研究。
2 T-S-T数字交换网络结构
典型的T-S-T数字交换网络可以用图1的模型描述。
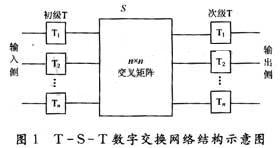
整个交换网络以S接线器为核心组织。对于一个具有N条输入复用线和N条输出复用线的交换网络而言,需要配置2N套T接线器,其中N套在输入侧,为初级T接线器,完成用户的发送时隙到交换网络内部的公共时隙的交换;N套在输出侧,称为次级T接线器,完成将交换网络内部的公共时隙上的住处传送到另一用户的接收时隙上。因此,交换网络内部提供的公共时隙的数量就决定了交换网络中能够形成的话音通路的数量。中间的S接线器主要由一个N×N的交叉接点和具有N个存储器的控制存储器组来组成,用来完成将交换网络内部运载的用户信息从一条输入侧复用线上交换到规定的一条输出复用线上。
3 T-S-T交换网络数学模型的建立
3.1 问题的描述
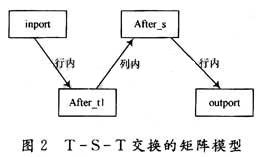
在建立T-S-T交换网络的数学模型之前,首先给出这样的数学抽象:用1个n×n的输入矩阵inport表示输入数据流,每一行代表1个T-S-T交换网络的输入链路,也就是说每一行代表l根链路HW,每一行内元素的位置代表1个时隙内各个数据帧的次序关系。由于T交换是对同一根链路的不同时隙之间进行的交换,故将其抽象为矩阵的行内置换。因此当输入矩阵inport经过一级T交换后,得到1个中间矩阵after_t1,此矩阵是inport矩阵通过每一行数据的行内变换得到。同理,由于S交换是在不同链路的相同时隙之间进行的交换,类似于对一个矩阵在其同一列内进行列内变换,称其为列内置换。这样当 after_tl又经过S交换,得到另外一个中间矩阵after_s,此矩阵是after_tl矩阵通过列内变换得到的。最后,又经过第二级的T交换,产生outport矩阵,类似地,他是after_s矩阵通过行内变换得到。于是,可以将交换算法这样描述:对于初始矩阵inport,怎样能找到一种满足 T-S-T三级交换的变换方式,最终得到1个输出矩阵outport。而且对于用户要求的任意outport(此矩阵与inport是单播关系),都可以通过算法找到其变换方式,即可以找到2个中间矩阵。
3.2 矩阵模型的建立
将T变换对应于矩阵的行内变换,而S变换对应于矩阵的列内变换,这样上面的这一段叙述就可以描述为inport矩阵经过一系列的行内变换得到after_t1矩阵,after_t1矩阵经过一系列的列内变换得到after_s矩阵,after_s矩阵又经过一系列的行内变换得到outport矩阵如图2所示。
4 交换算法的设计思想
从上面论述可以看到,本文已经将具体的路径选择问题,抽象成纯粹的数学问题。接下来,本文将从纯数学的角度来找出一种算法,从而解决这个交换问题。
4.1 问题的数学分析
观察从输入矩阵inport→中间矩阵after_t1→中间矩阵after_s→输出矩阵outport整个的变换过程,输入矩阵先后经过2次时间变换,而只经过1次空间变换。也就是说,当输入矩阵inport中的某个元素,要发生列变换时,他只有1次变换机会,此情况对于inport中的任意一个元素都是适用的。所以,时间变换只起到调整作用,因此本文要重点考察空间变换,试图从空间变换S变换中找出矩阵的特点。
不难发现,中间矩阵 after_s(n×m)(一般情况下,本文取m=n,无阻塞的交换网络)有这样的特点:每一列的n个元素,他们的行号包含从1~n的所有行号。如上面的例子可以看到这一点。这样,将after_s矩阵经过1个空间变换,向空间变换的反方向变换的时候,这n个元素就会回到在inport矩阵原来的行上,在经过1个时间变换的反变换就可以变成为输入矩阵inport。
在发现中间矩阵after_s的特点之后,就有了基本的思路。这里的算法只要能够使得outport矩阵经过1个时间变换的反变换后能够变成为满足中间矩阵after_s的特点的矩阵,那么,也就找到一种矩阵的变换方式。解决了这个交换问题。有没有一个从inport到outport的变换的问题,转换成能不能找到一个满足after_s矩阵要求的问题,此after_s矩阵只是 outport矩阵经过一个时间变换得到。
这样,对于任意输入矩阵inpott,经过矩阵的行内、列内、行内3次变换可以得到任意输出矩阵 outport,从而成功的完成了T-S-T交换。本文为了方便描述inport和T-S-T交换的核心算法,不妨将inport定义为顺序矩阵n×n,就是以行为序,从0~n×n-1,例如n=4,inport被定义为:

而outport将是inport的任意置换矩阵。在这里也不妨将outport假设为:

为了从inport矩阵变换到outport矩阵,必须找到两个中间矩阵after_t1和after_s,从而完成交换路径的接续。因此本文的目标是研究一种算法,根据输入矩阵和输出矩阵产生这两个中间矩阵,从而使处理机可以根据4个矩阵往寄存器阵列中填值,这样就可以实现T-S-T网络交换。为了以后叙述方便,3个寄存器阵列定义为:Tregister1(时分)、Sregister(空分)、Tregister2(时分)。
由于在实际的 T-S-T交换中,CPU根据各个控制寄存器中的值来完成交换。由交换的特点可知,每个控制寄存器的值是由输入序列和输出序列决定的。其中 Tregisterl的值可以由inport和after_t1决定,同理,Sregister的值由after_t1和after_s决定,Tregister2的值由after_s和outport决定。
4.2 算法思想的设计
算法设计要求:
(1)对于任意给定的输入矩阵和输出矩阵,都能够得到2个中间矩阵;
(2)由输入矩阵到第一个中间矩阵只能经过一系列行内置换;
(3)由第一个中间矩阵到第二个中间矩阵只能经过一系列列内置换;
(4)由第二个中间矩阵到输出矩阵只能经过一系列行内置换。
由行内变换和列内变换的性质可以推断出after_t1(AT)和after_s(AS)矩阵的特点如下:
AT的特点:ATij=INij'(只能在同一行上进行置换);AS的特点:AS是inport的一个置换矩阵;AS的同一列上不可能出现inport同一行上的元素。
这是由于AT同一列上不可能出现inport同一行上的元素,而AT到AS经过的是列内变换。
现在有了inport和outport,目标是通过这2个矩阵找到after_t1和after_s。从上面的设计要求和模型2个中间矩阵的特点可以看出,由inport到outport所经过的置换与由outport到inport所经过的置换是对称的,所以由outport到inpott置换所得的2个中间矩阵也是问题的解。而且inport相对于output较为确定,因此为了方便描述和算法实现,本文采用逆推法,由outport经过一系列的行内变换逆推出after_s,由after_s经过一系列的列内变换逆推出after_t1。很容易发现从after_s到after_t1只需要一个简单的排序就可以完成,因此算法的关键是由outport推导after_s。
这样本文研究的交换网络调度算法要解决的关键问题等效后分解为:将一个任意置换矩阵经过一系列的行内变换变成为同一列上不存在输入矩阵的同一行数据的置换矩阵(这是由AS的特点所决定的)。将解决这个关键问题的算法称为交换网络调度算法的核心算法。
5 关键矩阵算法的思想和步骤
5.1 高冲突值行优先排列算法
一些约定和定义:
规则:矩阵after_s同一列上不存在矩阵inport同一行上的数据。
那么对于任一给定输出矩阵outport(OP),本算法的任务是;根据“规则”将outport的每一行元素放到after_s(AS)同行的适当位置上。例如假设现在开始第i行的排列,也就是说,第0行到第i~l行的数据已经初步放置完毕(考虑到回溯,所以说“初步”),则前i行的每一列元素的初始矩阵行可以组成1个一维矩阵,一共n个一维矩阵,定义为垂直行阵v[0],v[1]。…,v[n一1];而OP的第i行的所有元素的初始矩阵行又可以组成1 个一维矩阵(元素的初始矩阵行等于该元素整除矩阵维数的商),定义为水平行阵h,数据结构如图3所示:
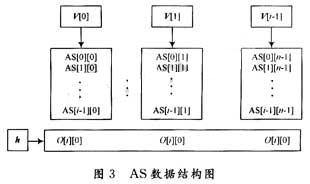
定义:垂直冲突值:vRepeat[n],其中vRepeat[i](i=0,1,2,…,n-1)等于u[i]中的元素在h中的重复次数的和。
水平冲突值:hRepeat[n],其中hRepcat[i](i=0,1,…,n-1)等于k[i]在v中的重复次数的和。
生存数(lifenum):假设vRepeat[j]等于k,也就是说,O[i]中有k个元素不能放在AS的第j列,能放在这一列的元素个数只有n-k个,定义为生存数(lifenum),将这n-k个元素下标取出形成向量,定义为生存空间(lifespace)
5.2 高冲突值行优先排列算法的实现
算法安放数据元素时,首先从vRepeat最大的那一列开始安放hRepeat最大的符合“规则”的元素,再逐次安放vRepeat中较小的且符合“规则”的列。这样,大冲突值的元素得到优先安放,重排或回溯的可能性就大大减小。
5.2.1 主流程
(1)排列第1行数据,row=0;
(2)row=row+1,如果row≥n,则停止,否则转下一步;
(3)统计冲突值,调用判回溯算法判断是否回溯,如果回溯,调用回溯算法,否则转下一步;
(4)选择vRepeat冲突值最大的列,根据“规则”安放hRepeat中最大的元素;
(5)更新vRepeat和hRepeat;
(6)判断这一行的数据是否都安放完毕,如果是,转(2),否则转(3)。
5.2.2 判断回溯算法
回溯条件:生存数为k,生存空间相同的列的个数和大于生存数k,则回溯,原因是某生存空间“不够分配”。例如,第i列和第j列(i不等于j)的生存数都为1和生存空间都为{2},这样第2个元素只能放在一个位置上,也就是说,无论如何排列都无法满足“规则”,需要回溯。
定义节点数据结构如图4所示:

判回溯的算法流程:
(1)将生存数相同的所有节点串成链表,链表的序号等于生存数;
(2)从链表序号为0向链表序号为n顺序扫描链表,统计生存空间相同的节点个数,当出现节点个数大于生存数的情况,需要回溯,否则转下一步;
(3)将本链并入下一个链表;
(4)如果所有链表都不出现生存空间相同的节点个数和大于生存数的情况,则不需要回溯。
5.2.3 回溯算法
定义经历表:在回溯过程中,各元素所“呆过”的位置序列。
回溯算法流程:
(1)确定回溯元素(冲突值最大原则);
(2)为回溯元素找一个“合法位置”;
合法条件:
规则:冲突值小于当前情况;位置不在经历表中。
(3)为其他元素找“合法位置”;
6 算法的正确性证明和复杂度分析
从前面的分析可以知道,要解决整个交换算法的关键是确定和寻找中间矩阵after_s,也就是说,在解决问题之前,必须确定问题有解。如何确定after_s一定存在,这里可以通过组合数学中的抽屉原理证明必然存在这样的矩阵,证明过程比较简单,本文在这里不做推导证明。
从前面的理论分析中知道,衡量交换算法有2个重要的指标:交换次数和比较次数。为了统计本文所研究的交换算法的性能,本文针对不同阶数矩阵的交换次数和比较次数做了系统的统计:
(1)对于每一行数据,由于统计冲突值、判回溯算法和元素的安放算法都是多项式复杂度,所以,在不存在回溯的条件下,本算法是多项式复杂度。
(2)在本算法中,“冲突”起着非常重要的作用,本身回避了许多回溯可能。即使回溯,本行可供回溯元素和非回溯元素“待”的位置个数非常有限,所以元素回溯的空间很小。
下面本文给出在不回溯的情况下,对高冲突行优先排列算法在阶数递增变化时,50次平均交换次数和比较次数统计结果如表1所示。
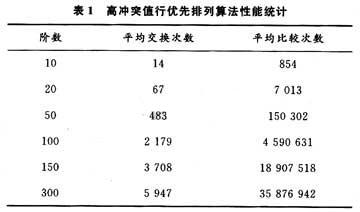
从前面对该算法的描述可知,该算法通过使每个元素“找到”尽可能适合自己的位置,从而回避了重新排列的许多可能,对于一行来说,完全避免了全排列,而且大大减小回溯概率。由于对大多数(约80%)矩阵来说,是不会出现回溯的,只有类似这样的矩阵才有可能出现回溯(也可能不回溯),即,AS的某些行,可供选择的初始行太少。所以,该算法是一个近似多项式的算法,在不回溯的情况下,是多项式算法。该算法基本上能够完成交换网络的路径接续,他有一个很大的优势就是在交换过程中交换的次数达到最小,这样也就大大提高了寻找交换路径的效率。本算法具有良好的特性,而且通过芯片级联可实现。
-
如何去设计一种关键矩阵算法?有哪些步骤?2021-05-26 1546
-
改进的二进制搜索算法原理是什么?有什么优势?2021-05-20 2006
-
基于改进和声搜索算法的深度置信网络模型2021-05-11 1786
-
Viterbi搜索算法2020-04-14 2070
-
五种运动搜索算法简介2019-07-17 1645
-
一种路径过滤性搜索算法2018-01-14 890
-
改进引力搜索算法的交换机迁移策略2017-12-03 941
-
基于PETRI网的最短路径搜索算法2017-11-07 1323
-
DS18B20-ROM编码的搜索算法2017-05-04 1874
-
急!有哪位大神会做--(2K*2K交换网络),做出必有重谢2017-03-31 2568
-
网络攻击路径的生成研究2009-08-06 756
-
一种无回溯的最长前缀匹配搜索算法2009-04-22 965
-
混合流水车间调度的变邻域禁忌搜索算法2009-04-11 840
-
基于Dijkstra的PKI交叉认证路径搜索算法2009-03-20 725
全部0条评论

快来发表一下你的评论吧 !
