

人工智能的演进需要高适应性的推理平台(WP023)
人工智能
描述
模型大小不断增长给现有架构带来了挑战
深度学习对计算能力的需求正以惊人的速度增长,其近年来的发展速度已从每年翻一番缩短到每三个月翻一番。深度神经网络(DNN)模型容量的不断提升,表明从自然语言处理到图像处理的各个领域都得到了改进——深度神经网络是诸如自动驾驶和机器人等实时应用的关键技术。例如,Facebook的研究表明,准确率与模型大小的比率呈线性增长,通过在更大的数据集进行训练,准确率甚至可以得到进一步提高。
目前在许多前沿领域,模型大小的增长速度远快于摩尔定律,用于一些应用的万亿参数模型正在考虑之中。虽然很少有生产系统会达到同样的极端情况,但在这些示例中,参数数量对性能的影响将在实际应用中产生连锁反应。模型大小的增长给实施者带来了挑战。如果不能完全依靠芯片扩展路线图,就需要其他解决方案来满足对模型容量增加部分的需求,而且成本要与部署规模相适应。这种增长要求采用定制化的架构,以最大限度地发挥每个可用晶体管的性能。
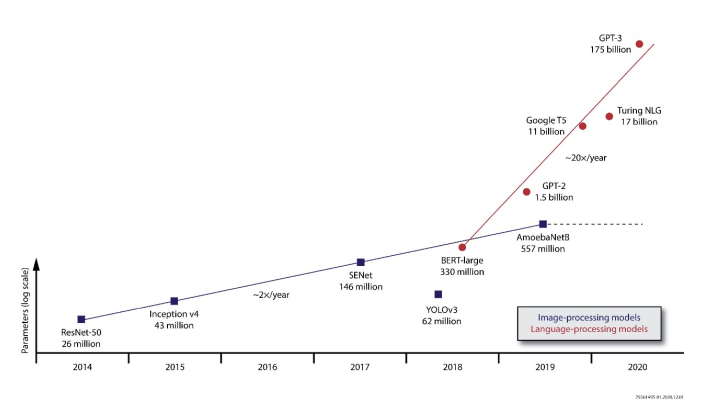
图1:模型大小的增长速度(来源:Linley Group)
Parameters (log scale):参数(对数刻度)
Image-processing models:图像处理模型
Language-processing models:语言处理模型
随着参数数量快速增长,深度学习架构也在快速演进。当深度神经网络继续广泛使用传统卷积、全连接层和池化层的组合时,市场上也出现了其它结构,诸如自然语言处理(NLP)中的自注意力网络。它们仍然需要高速矩阵和面向张量的算法,但是存储访问模式的变化可能会给图形处理器(GPU)和当前现有的加速器带来麻烦。
结构上的变化意味着诸如每秒万亿次操作(TOps)等常用指标的相关性在降低。通常情况下,处理引擎无法达到其峰值TOps分数,因为如果不改变模型的处理方式,存储和数据传输基础设施就无法提供足够的吞吐量。例如,批处理输入样本是一种常见的方法,因为它通常可以提高许多架构上可用的并行性。但是,批处理增加了响应的延迟,这在实时推理应用中通常是不可接受的。
数值灵活性是实现高吞吐量的一种途径
提高推理性能的一种途径是使计算的数值分辨率去适应各个独立层的需求,这也代表了与架构的快速演进相适应。一般来说,与训练所需的精度相比,许多深度学习模型在推理过程中可以接受明显的精度损失和增加的量化误差,而训练通常使用标准或双精度浮点算法进行。这些格式能够在非常宽的动态范围内支持高精度数值。这一特性在训练中很重要,因为训练中常见的反向传播算法需要在每次传递时对许多权重进行细微更改,以确保收敛。
通常来说,浮点运算需要大量的硬件支持才能实现高分辨率数据类型的低延迟处理,它们最初被开发用来支持高性能计算机上的科学应用,完全支持它所需的开销并不是一个主要问题。
许多推理部署都将模型转换为使用定点运算操作,这大大降低了精度。在这些情况下,对准确性的影响通常是最小的。事实上,有些层可以转换为使用极其有限的数值范围,甚至二进制或三进制数值也都是可行的选择。
然而,整数运算并不总是一种有效的解决方案。有些滤波器和数据层就需要高动态范围。为了满足这一要求,整数硬件可能需要以24位或32位字长来处理数据,这将比8位或16位的整数数据类型消耗更多的资源,这些数据类型很容易在典型的单指令多数据(SIMD)加速器中得到支持。
一种折衷方案是使用窄浮点格式,例如适合16位字长的格式。这种选择可以实现更大的并行性,但它并没有克服大多数浮点数据类型固有的性能障碍。问题在于,在每次计算后,浮点格式的两部分都需要进行调整,因为尾数的最高有效位没有显式存储。因此,指数的大小需要通过一系列的逻辑移位操作来调整,以确保隐含的前导“1”始终存在。这种规范化操作的好处是任何单个数值都只有一种表示形式,这对于用户应用程序中的软件兼容性很重要。然而,对于许多信号处理和人工智能推理常规运算来说,这是不必要的。
这些操作的大部分硬件开销都可以通过在每次计算后无需标准化尾数和调整指数来避免。这是块浮点算法所采用的方法,这种数据格式已被用于标准定点数字信号处理(DSP),以提高其在移动设备的音频处理算法、数字用户线路(DSL)调制解调器和雷达系统上的性能。
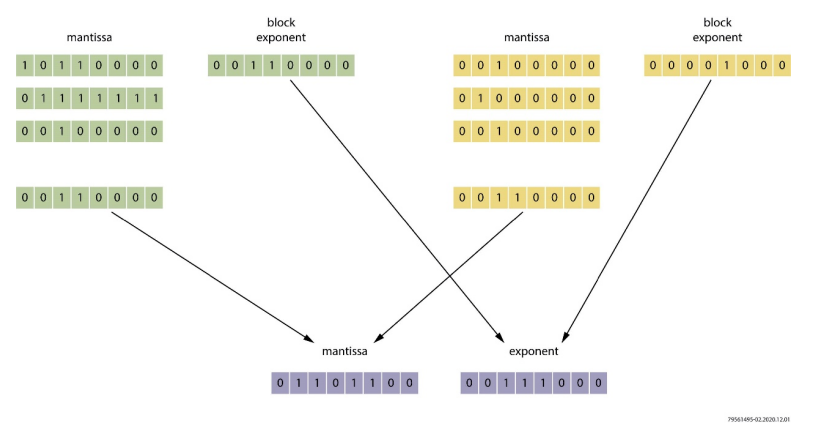
图2:块浮点计算示例
mantissa:尾数
block exponent:块指数
使用块浮点算法,无需将尾数左对齐。用于一系列计算的数据元素可以共享相同的指数,这一变化简化了执行通道的设计。对占据相似动态范围的数值进行四舍五入造成的精度损失可被降到最小。在设计时就要为每个计算块选择合适的范围。在计算块完成后,退出函数就可以对数值进行四舍五入和标准化处理,以便在需要时将它们用作常规的浮点值。
支持块浮点格式是机器学习处理器(MLP)的功能之一。Achronix的Speedster®7t FPGA器件和Speedcore™ eFPGA架构提供了这种高度灵活的算术逻辑单元。机器学习处理器针对人工智能应用所需的点积和类似矩阵运算进行了优化。相比传统浮点,这些机器学习处理器对块浮点的支持提供了实质性的改进。16位块浮点运算的吞吐量是传统的半精度浮点运算的8倍,使其与8位整数运算的速度一样快,与仅以整数形式的运算相比,有功功耗仅增加了15%。
另一种可能很重要的数据类型是TensorFloat 32(TF32)格式,与标准精度格式相比,该格式的精度有所降低,但保持了较高的动态范围。TF32也缺乏块指数处理的优化吞吐量,但对于一些应用是有用的,在这些应用中,使用TensorFlow和类似环境所创建的模型的易于移植性是很重要的。Speedster7t FPGA中机器学习处理器所具有的高度灵活性使得使用24位浮点模式来处理TF32算法成为可能。此外,机器学习处理器的高度可配置性意味着可以支持一个全新的、块浮点版本的TF32,其中四个样本共享同一个指数。机器学习处理器支持的块浮点TF32,其密度是传统TF32的两倍。

图3:机器学习处理器(MLP)的结构
Wireless:无线
AI/ML:人工智能/机器学习
Input Values:输入值
Input Layer:输入层
Hidden Layer 1:隐藏层1
Hidden Layer 2:隐藏层2
Output Layer:输出层
处理灵活性优化了算法支持
虽然机器学习处理器能够支持多种数据类型,这对于推理应用而言是至关重要的,但只有成为FPGA架构的一部分,它的强大功能才能释放出来。可轻松定义不同互连结构的能力使FPGA从大多数架构中脱颖而出。在FPGA中同时定义互连和算术逻辑的能力简化了构建一种平衡架构的过程。设计人员不仅能够为自定义数据类型构建直接支持,还可以去定义最合适的互连结构,来将数据传入和传出处理引擎。可重编程的特性进一步提供了应对人工智能快速演进的能力。通过修改FPGA的逻辑可以轻松支持自定义层中数据流的变化。
FPGA的一个主要优势是可以轻松地在优化的嵌入式计算引擎和由查找表单元实现的可编程逻辑之间切换功能。一些功能可以很好地映射到嵌入式计算引擎上,例如Speedster7t MLP。又如,较高精度的算法最好分配给机器学习处理器(MLP),因为增加的位宽会导致功能单元的大小呈指数增长,这些功能单元是用来实现诸如高速乘法之类的功能。
较低精度的整数运算通常可以有效地分配给FPGA架构中常见的查找表(LUT)。设计人员可以选择使用简单的位串行乘法器电路来实现高延迟、高并行性的逻辑阵列。或者,他们可以通过构建进位保存和超前进位的加法器等结构来为每个功能分配更多的逻辑,这些结构通常用来实现低延迟的乘法器。通过Speedster7t FPGA器件中独特的LUT配置增强了对高速算法的支持,其中LUT提供了一种实现Booth编码的高效机制,这是一种节省面积的乘法方法。
结果是,对于一个给定的位宽,实现整数乘法器所需的LUT数量可以减半。随着机器学习中的隐私和安全性等问题变得越来越重要,应对措施可能是在模型中部署同态加密形式。这些协议通常涉及非常适合于LUT实现的模式和位域操作,有助于巩固FPGA作为人工智能未来验证技术的地位。
数据传输是吞吐量的关键
为了在机器学习环境中充分利用数值自定义,周围的架构也同样重要。在越来越不规范的图形表示中,能随时在需要的地方和时间传输数据是可编程硬件的一个关键优势。但是,并非所有的FPGA架构都是一样的。
传统FPGA架构的一个问题是,它们是从早期应用演变而来的;但在早期应用中,其主要功能是实现接口和控制电路逻辑。随着时间的推移,由于这些器件为蜂窝移动通信基站制造商提供了一种从愈发昂贵的ASIC中转移出来的方法,FPGA架构结合了DSP模块来处理滤波和信道估计功能。原则上,这些DSP模块都可以处理人工智能功能。但是,这些模块最初设计主要是用于处理一维有限冲激响应(1D FIR)滤波器,这些滤波器使用一个相对简单的通道通过处理单元传输数据,一系列固定系数在该通道中被应用于连续的样本流。
传统的处理器架构对卷积层的支持相对简单,而对其他的则更为复杂。例如,全连接层需要将一层中每个神经元的输出应用到下一层的所有神经元上。其结果是,算术逻辑单元之间的数据流比传统DSP应用中的要复杂得多,并且在吞吐量较高的情况下,会给互连带来更大的压力。
尽管诸如DSP内核之类的处理引擎可以在每个周期中生成一个结果,但FPGA内部的布线限制可能导致无法足够快速地将数据传递给它。通常,对于专为许多传统FPGA设计的、通信系统中常见的1D FIR滤波器来说,拥塞不是问题。每个滤波阶段所产生的结果都可以轻松地传递到下一个阶段。但是,张量操作所需的更高的互连以及机器学习应用较低的数据局部性,使得互连对于任何实现而言都更加重要。
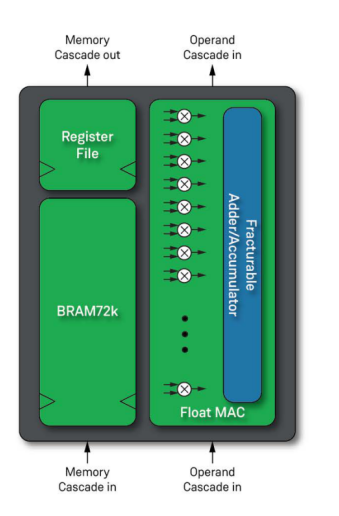
图4:滤波器和人工智能数据流
Memory Cascade Out:存储级联输出
Operand Cascade in:操作数级联
Register File:寄存器文件
Fracturable:可分割
Adder/Accumulator:加法器/累加器
Memory Cascade in:存储级联
机器学习中的数据局部性问题需要注意多层级的互连设计。由于在最有效的模型中参数数量庞大,片外数据存储通常是必需的。关键要求是可以在需要时以低延迟传输数据的机制,并使用靠近处理引擎的高效便笺式存储器,以最有效地利用预取以及其他使用可预测访问模式的策略,来确保数据在合适的时间可用。
在Speedster7t架构中,有以下三项用于数据传输的创新:
·优化的存储层次结构
·高效的本地布线技术
·一个用于片内和片外数据传输的高速二维片上网络(2D NoC)
传统的FPGA通常具有分布在整个逻辑架构上的片上RAM块,这些RAM块被放置在距离处理引擎有一定距离的地方。对于典型的FPGA设计来说,这种选择是一种有效的架构,但在人工智能环境中,它带来了额外的和不必要的布线开销。在Speedster7t架构中,每个机器学习处理器(MLP)都与一个72kb的双端口块RAM(BRAM72k)和一个较小的2kb的双端口逻辑RAM(LRAM2k)相关联,其中LRAM2k可以作为一个紧密耦合的寄存器文件。
可以通过FPGA布线资源分别访问机器学习处理器(MLP)及其相关联的存储器。但是,如果一个存储器正在驱动关联的MLP,则它可以使用直接连接,从而卸载FPGA布线资源并提供高带宽连接。
在人工智能应用中,BRAM可以作为一个存储器,用于存储那些预计不会在每个周期中发生变化的值,诸如神经元权重和激活值。LRAM更适合存储只有短期数据局部性的临时值,诸如输入样本的短通道以及用于张量收缩和池化活动的累积值。
该架构考虑到需要能够将大型复杂的层划分为可并行操作的段,并为每个段提供临时数据值。BRAM和LRAM都具有级联连接功能,可轻松支持机器学习加速器中常用的脉动阵列的构建。

图5:具有存储和级联连接功能的MLP
MLP可以从逻辑阵列、共享数据的级联路径以及关联的BRAM72k和LRAM2k逐周期驱动。这种安排能够构建复杂的调度机制和数据处理通道,使MLP持续得到数据支持,同时支持神经元之间尽可能广泛的连接模式。为MLP持续提供数据是提高有效TOps算力的关键。
MLP的输出具有同样的灵活性,能够创建脉动阵列和更复杂的布线拓扑,从而为深度学习模型中可能需要的每种类型的层提供优化的架构。

图6:具有端点和I/O块的NoC
Multiplier / multiplicand fractions after converting inputs to have the same exponent:将输入转换为具有相同指数后的乘数/被乘数分数
Multiplier block exponent:乘数块指数
Multiplicand block exponent:被乘数块指数
Integer Multiply / Add Tree:整数乘法/加法树:
Convert to Floating Point:转换为浮点
Floating Point Accumulation:浮点累加
Round to desired precision:四舍五入到所需精度
Speedster7t架构中的2D NoC提供了从逻辑阵列的可编程逻辑到位于I/O环中的高速接口子系统的高带宽连接,用于连接到片外资源。它们包括用于高速存储访问的GDDR6和诸如PCIe Gen5和400G以太网等片内互连协议。这种结构支持构建高度并行化的架构,以及基于中央FPGA的高度数据优化的加速器。
通过将高密度数据包路由到分布在整个逻辑阵列上的数百个接入点,2D NoC使得大幅增加FPGA上的可用带宽成为可能。传统的FPGA必须使用数千个单独编程的布线路径来实现相同的吞吐量,而这样做会大量吃掉本地的互连资源。通过网络接入点将千兆数据传输到本地区域,2D NoC缓解了布线问题,同时支持轻松而快速地将数据传入和传出MLP和基于LUT的定制化处理器。
相关的资源节省是相当可观的——一个采用传统FPGA软逻辑实现的2D NoC具有64个NoC接入点(NAP),每个接入点提供一个运行频率为400MHz的128位接口,将消耗390kLUT。相比之下,Speedster 7t1500器件中的硬2D NoC具有80个NAP,不消耗任何FPGA软逻辑,并且提供了更高的带宽。
使用2D NoC还有其他的一些优势。由于相邻区域之间互连拥塞程度较低,因此逻辑设计更易于布局。因为无需从相邻区域分配资源来实现高带宽路径的控制逻辑,因此设计也更加有规律。另一个好处是极大地简化了局部性重新配置——NAP支持单个区域成为有效的独立单元,这些单元可以根据应用的需要进行交换导入和导出。这种可重配置的方法反过来又支持需要在特定时间使用的不同模型,或者支持片上微调或定期对模型进行再训练这样的架构。
结论
随着模型增大和结构上变得更加复杂,FPGA正成为一种越来越具吸引力的基础器件来构建高效、低延迟AI推理解决方案,而这要归功于其对多种数值数据类型和数据导向功能的支持。但是,仅仅将传统的FPGA应用于机器学习中是远远不够的。机器学习以数据为中心的特性需要一种平衡的架构,以确保性能不受人为限制。考虑到机器学习的特点,以及不仅是现在,而且在其未来的开发需求,Achronix Speedster7t FPGA为AI推理提供了理想的基础器件。
- 相关推荐
- 热点推荐
- 人工智能
-
FPGA在人工智能中的应用有哪些?2024-07-29 8287
-
嵌入式和人工智能究竟是什么关系?2024-11-14 4002
-
数据对人工智能发展的重要性2017-10-09 5658
-
【下载】《人工智能标准化白皮书(2018版)》2018-02-02 24033
-
基于人工智能的创新教学云平台建设2018-04-16 3846
-
人工智能医生未来或上线,人工智能医疗市场规模持续增长2019-02-24 5881
-
人工智能上路需要知道什么常识2019-05-13 4153
-
人工智能:超越炒作2019-05-29 5030
-
深度学习推理和计算-通用AI核心2020-11-01 3616
-
物联网人工智能是什么?2021-09-09 5344
-
人工智能对汽车芯片设计的影响是什么2021-12-17 2212
-
AI人工智能计算棒RK1808 Al Compute Stick介绍2022-08-15 2647
-
《通用人工智能:初心与未来》-试读报告2023-09-18 1276
-
如何判定MES系统平台的适应性开发能力2018-11-20 1116
-
人工智能的演进需要高适应性的推理平台2022-08-03 1258
全部0条评论

快来发表一下你的评论吧 !
