

“AI+语音/图像”智能技术线上论坛圆满成功
描述
7月15日,由全球知名电子科技媒体<电子发烧友>主办的“AI+语音/图像”智能技术线上论坛圆满举行,本次论坛邀请到来自知存科技、莱迪思、声扬科技、清微智能、希尔贝壳等企业的专家和领导进行精彩的技术分享。
在电子行业内卷严重的时候,人工智能是为数不多还在快速增长的行业之一。电子发烧友总经理张迎辉表示,以前人们对于人工智能的技术定义,是非常高大上,非常前沿的,经过三年的AI技术落地,不少朋友将人工智能技术的定义,改成了减少人力工作的智能技术。
知存科技:存算一体芯片的发展、挑战和未来
本次论坛,知存科技CEO王绍迪带来的主题是《存算一体芯片的发展、挑战和未来》,知存科技成立于2017年,并且公司团队早在2012年就开始存算一体技术研发,2018年完成国内首个存算一体芯片流片,2020年发布首个存算一体芯片产品WTM1001,2021年WTM1001量产,并发布第二代产品WTM2101。
据王绍迪介绍,近十年来摩尔定律开始放缓,而存储器在更早的时候摩尔定律就接近终结,比如DRAM工艺现在进行到10-20nm之间,一般在15-17nm工艺,Flash一般是20-40nm之间的工艺流程,存储器的工艺实际上比逻辑芯片更老,这导致存储器的速度在过去10-20年里都很难提升。
这就造成了存储墙瓶颈,一是数据搬运慢,存储容量越来越大,存储器带宽速度没有增加,CPU速度越来越快,核数从双核、四核、八核,到几千核、上万核,这导致每个核能使用的存储器资源越来越少,数据量大,做运算的时候,大部分时间都消耗在数据搬运上,运算速度受到存储带宽的影响,无法进一步提升。

二是搬运能耗大,据王绍迪介绍,在28nm工艺下,32bit数加法功耗基本是0.1/0.9pJ,乘法是3.1/3.7pJ,当把64bit数从8KB SRAM中取出,消耗功耗10pJ,从1MB SRAM中拿出,消耗功耗100pJ,说明存储器越大,从中取出一个数需要的功耗也越大,如果从芯片外部DRAM中取出来,需要消耗2000pJ,搬运功耗是运算功耗的几百倍。
现在大部分芯片都采用冯诺依曼架构,上述存储墙瓶瓶颈与此有关,为了解决这些问题,出现了3D Xpoint、3D封装等方案,用于减少搬运耗时和功耗大的问题,不过这些还都是采用冯诺依曼架构,存算一体与这些方法有所不同,存算一体可以理解成用存储器去做运算,存算一体芯片也像是计算芯片。
存储一体的应用场景广泛,包括可穿戴、智能IPC、移动终端、AR/VR、智能驾驶、数据中心等,不同应用场景,对存算一体芯片的算法和算力的要求也不一样。
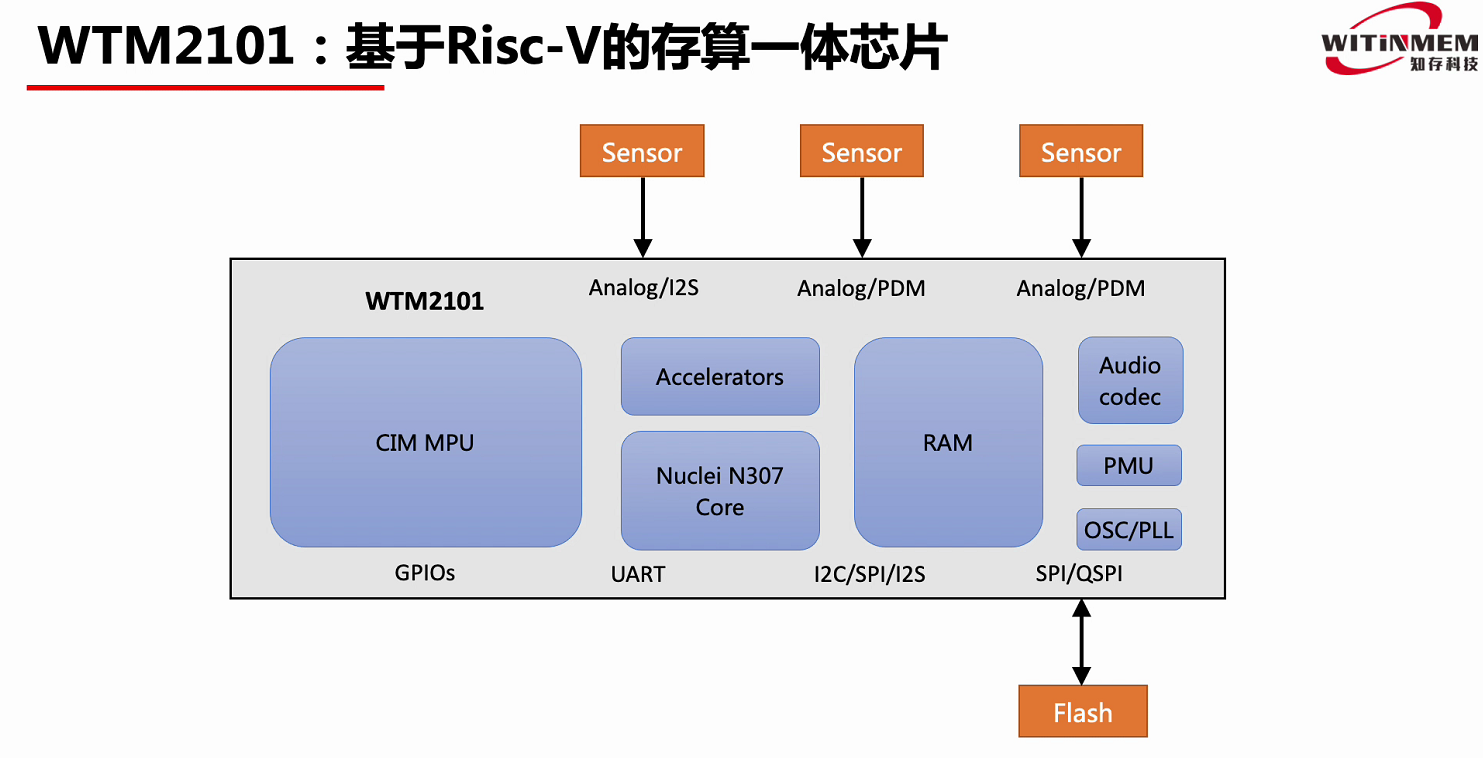
知存科技第二代产品WTM2101,是一款基于RISC-V的存算一体芯片,该芯片包括存算一体MPU,用于实现深度学习算法,RISC-VCore,加速单元,RAM,以及Audio codec,可以处理外面麦克风采集来的数据,这颗存算一体芯片可以用来做一些算法级的应用,比如语音识别、语音增强、血压/血糖、心电算法等。
莱迪思:CrossLink-NX FPGA助力网络边缘AI
莱迪思亚太区资深市场开拓经理林国松分享了《使用超低功耗FPGA在网络边缘实现毫瓦级人工智能》的主题演讲。
2020年莱迪思营收达到4.08亿美元,过去四年的出货量超过10亿片。主要聚焦在通信计算(39%)、工业和汽车(37%)、消费电子和其他(24%)。莱迪思FPGA的产品定位在小尺寸、低功耗、安全、可靠设计和易于使用。
ABI Research数据显示,截至2024年,设备端AI推理功能预计将覆盖60%的设备。
网络边缘应用的性能要求,包括1-500GOPS,功耗要求低于50mW,0.5-5TOPS算力的,功耗要求低于5W,大于10TOPS的,功耗要求低于50W。
莱迪思sensAI推出一系列FPGA产品,例如比较新的CrossLink-NX,还有IP CORE,开发软件等。

下图右侧是莱迪思的FPGA,左侧显示有训练模型,通过莱迪思开发的神经网络编译器转化成量化的权重和指令。此外,通过FPGA设计使用人工智能训练后的量化权重和指令,达到AI功能的实现。
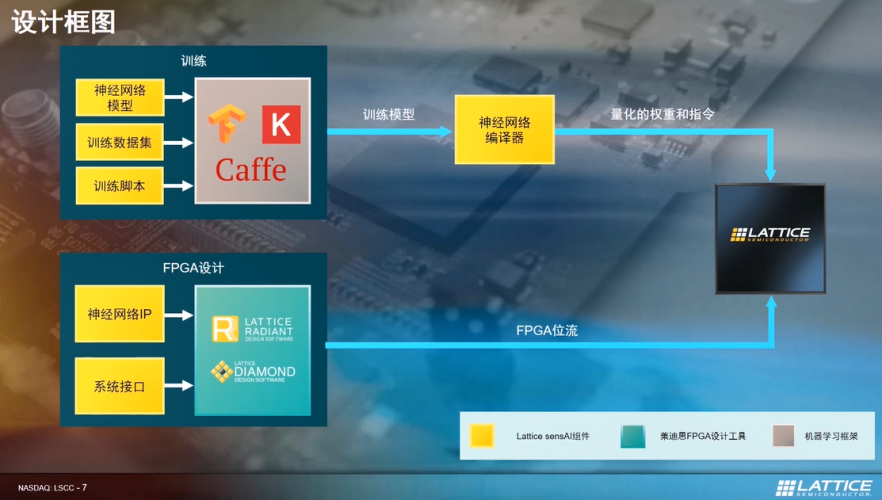
最近,莱迪思推出全新的sensAI Studio。方便客户更快的配置训练环境,令客户专注于开发AI功能。sensAI Studio能够快速搭建训练的网络,优化开发流程。
莱迪思通过软件优化的设计方法,目前可支持到Tensorflow Lite,在标准环境训练完成后通过编译器进行转换,再植入到FPGA器件上。
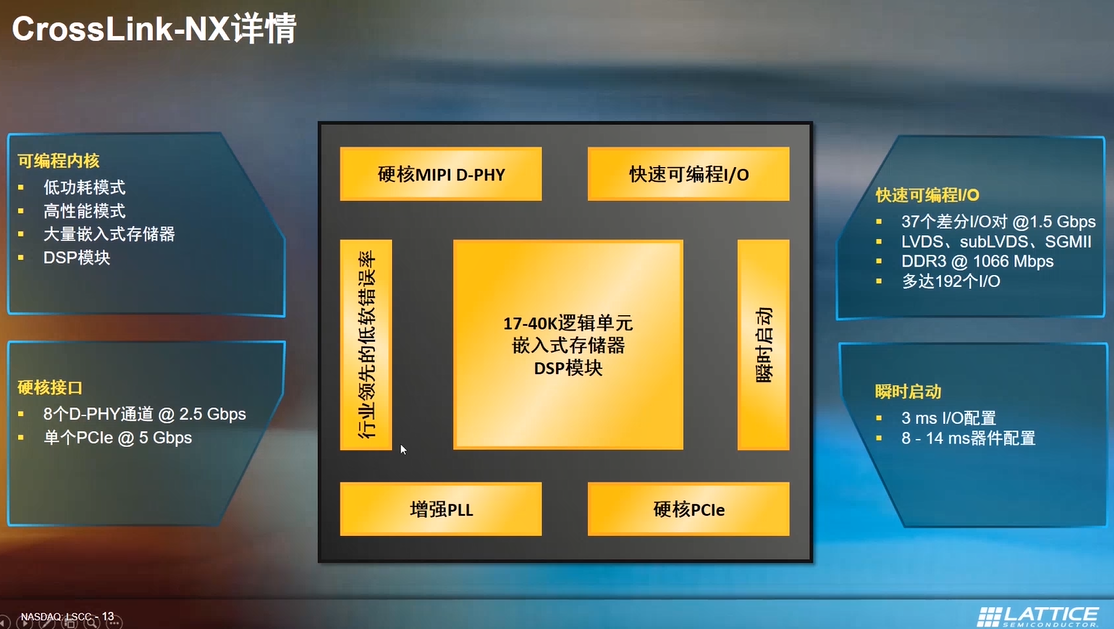
CrossLink-NX
CrossLink-NX 系列 FPGA 的设计采用了全新的Lattice Nexus技术平台,结合了28 nm FD-SOI 制造工艺与 Lattice的全新 FPGA 架构,针对小尺寸、低功耗应用进行了优化。
例如,在针对图像的AI处理参考设计中,传感器的图像数据传给FPGA器件,进行神经网络加速,输出结果给MCU。
从性能上看,NX-40K提供60fps每秒速率,是上一代产品的12倍,功耗方面,与上一代相比功耗减半。这两项指标在与MCU相比也有显著的优势。
CrossLink-NX提供17-40K逻辑单元,大量嵌入式存储和DSP模块,具有瞬间启动,支持硬核PCIe等。在器件内部,由于增强了嵌入式存储器,将所有AI的计算过程在FPGA片上实现。省去外部RAM,有助于降低功耗,提升帧率和性能。
它重点应用于超低功耗人员侦测,超低功耗关键词和手热检测,多个目标的检测和计数,以及片上注册和识别物体。


莱迪思提供快速原型设计的模块化平台,包括UPduino Shield开发板,和嵌入式视觉开发套件。前者重点是超低功耗,后者是对性能要更高求的应用。此外,软件工具方面提供神经网络编译器。还提供CNN Plus加速器IP,可简化神经网络在CrossLink-NX的实现。
网络边缘AI的算法持续推陈出新,FPGA具有可拓展的性能应对各类应用案例,可以灵活应对,且具有灵活的计算资源、超低功耗和可编辑硬件等特性。莱迪思CrossLink-NX FPGA以高性能数据处理、低功耗运行且尺寸较小的特性,为客户提供网络边缘 AI/ML 推理解决方案。
声扬科技谢基有:语音交互智能分析在产业数字化的应用
声扬科技是业界领先的语音交互智能分析平台与新型知识服务提供商,为金融、公安、政府、IoT和互联网行业提供了“以用户为中心”的语音智能化解决方案。声扬科技产品VP谢基有在本次线上论坛介绍了“语音交互智能分析在产业数字化的应用”。
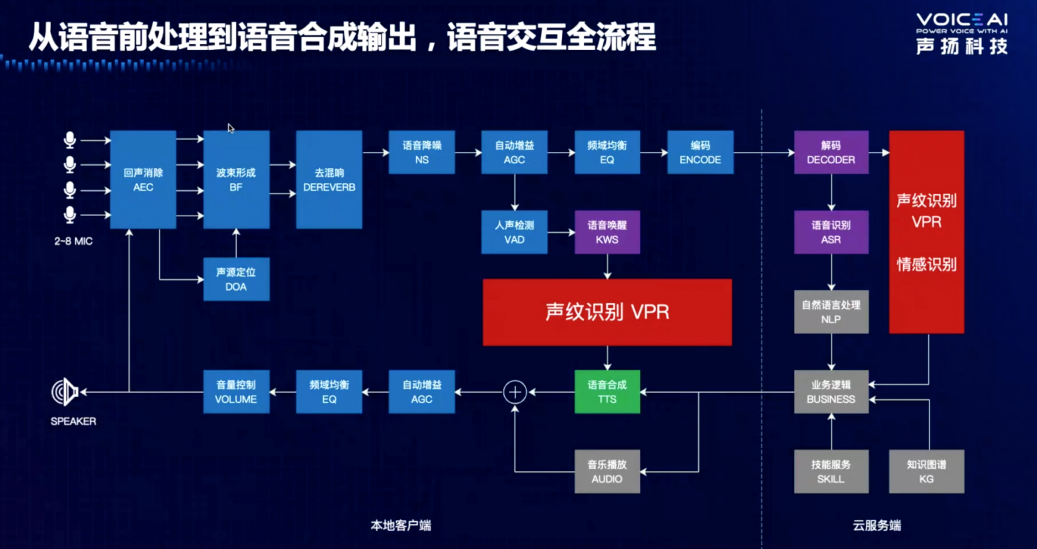
语音交互全流程 / 声扬科技
AI语音分析已经在诸多汽车场景中的得到了应用,比如车内降噪和身份核验等。然而复杂的车内声音空间,对前端语音处理来说是一项巨大的挑战。车内存在多声道、音量大和非线性失真大的问题,噪声的存在同样不可忽视,比如风噪、地面胎噪、空调出风口噪声、引擎噪声和振动噪声等。
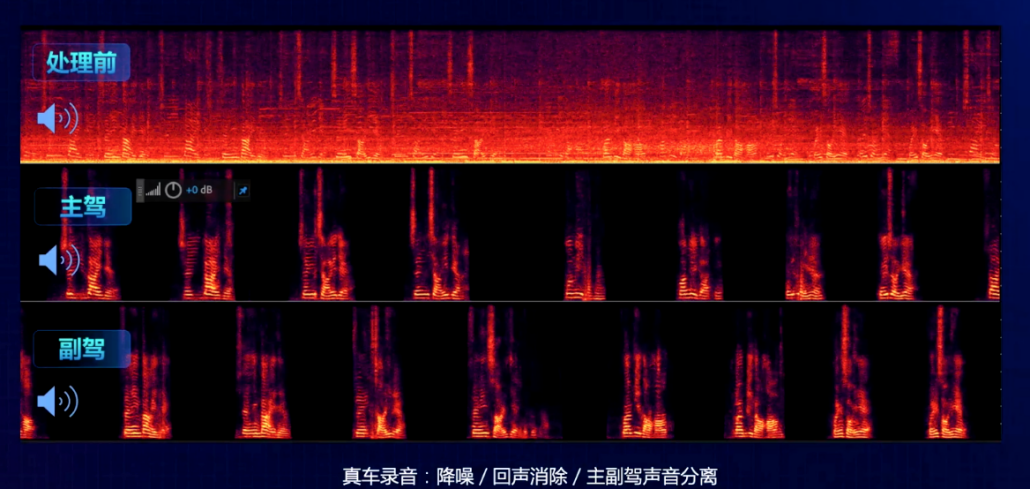
车内声音处理 / 声扬科技
声扬科技的车载前端双音区拾音车规芯片解决了这些挑战,为车内语音交互系统提供了双音区拾音、人声分离和超强降噪功能。声扬科技还为客户提供智能车载操作系统,通过声纹识别来确认车主身份,从硬件与系统上大幅提升人车语音交互体验。
在数字金融的运用上,智能语音可以助力产业数字化转型升级,用于金融风控反欺诈、APP声纹登录、声纹开卡等操作和管理。声扬科技也是中国工商银行总行声纹识别项目的唯一供应商,FinVoice智能语音认证系统已在多场景上线,用户量达4.16亿。
声扬科技拥有全栈语音技术储备,基于深度神经网络、机器学习、深度学习等人工智能前言理论打造了多项自主可控的原创计算机听觉技术,覆盖了前端声学信号采集、语音信号处理、后端特征提取识别等全流程,构建了以声纹识别为特色的1+N智能语音算法体系。在智能语音技术上,声扬科技具备自动防录音攻击、超短语音验证、跨信道等优势,而且系统资源占用低,支持高并发和海量千万级数据库检索。
北京清微智能于义:可重构计算芯片高效解决两大AI场景中的痛点问题
7月15日,在电子发烧友主办的AI线上技术峰会上,来自北京清微智能科技有限公司的首席架构师于义带来了精彩演讲。
“AIoT产业是多种技术融合,赋能各行业的产业,整体市场潜在空间超过十万亿,智能时代的支撑就是计算力,计算力的不断提升催生新的需求和产品。”于义表示,“智能化主要体现在感知智能化、分析智能化和控制智能化,具体表现在智慧城市、智能制造、智能家居、智能驾驶、智能零售等场景需要强大计算力。”
AIoT产业对于芯片的要求体现在四点:高算力、高能效、灵活性、安全性。比如视频跟踪需要高算力,来支持智能识别的应用;高能效意味着芯片在有限的能量下完成更多的智能任务,灵活性主要聚焦万物智能,芯片应用多种多样,具备灵活性适配各种算法、各种应用;安全性,表现为数据安全,智能时代的安全性要求用户数据安全被访问、被处理。

传统的计算架构无法满足AIoT计算需求,可重构智能芯片是基于可重构数据流/控制流计算架构的AI芯片类型,具有按需即时重构、高能效、低功耗、通用性特点,被《国际半导体技术路线图》评为最具前景的未来计算架构,美国电子复兴计划(ERI)将可重构计算技术列为未来美国在电子行业一直保持领导地位的核心关键技术,是后摩尔时代的颠覆性技术之一,也是各国争相抢占的科技制高点。
清微智能成立于2018年7月,公司核心创业团队来自清华大学微电子所,可重构计算技术已经在清华大学经历了10年的探索,公司在2016年到2018年连续推出了Think Series系列芯片,性能和水平处于业界领先。清微智能是可重构计算芯片领导企业,核心技术指标领跑全球,在产品应用上,也是第一个将可重构芯片真正商用落地的企业。于义表示,清微智能的核心可重构技术包括:四元编程重构计算模式、低功耗设计、融合存内计算的可重构架构、异步电路驱动可重构技术。
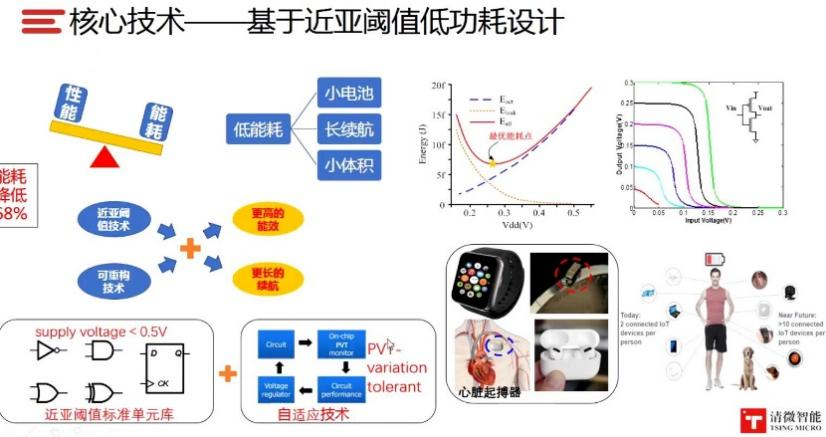
于义介绍说,2018年10月,清微智能进行了Pre-A轮融资,2019年6月量产了超低功耗的智能语音Soc芯片TX210。2020年10月,清微智能量产了全球首款多模态智能计算芯片TX510芯片,这款芯片在智能安防、金融支付、航空航天等领域交付客户。2021年4月,清微智能量产了全球首款集成独立NPU的蓝牙Soc芯片TX231,已应用于多款TWS耳机、平板、手环;2021年11月,清微智能即将量产图像芯片TX511,采用分布式可重构处理核心,芯片性能将有数十倍提升,12月份还会推出更高端的810系列。公司与TSMC、平头哥有深度合作。
希尔贝壳:算法+数据的开源如何实践与语音模型评测方案
北京希尔贝壳科技有限公司 CEO卜辉带来《算法+数据的开源如何实践与语音模型评测方案》主题演讲。随着AI技术的成熟与应用迭代,中国智能语音市场将保持约25%的增长速度,预计到2023年,智能语音产业规模将超600亿。
语音技术大致分为语音识别技术(ASR)、语音合成技术(TTS)、声纹识别技术(VPR)。随着技术的不断迭代,语音技术已经应用到移动设备、汽车、家居、金融等各个场景中,卜辉强调,语音识别技术的应用核心是算力、算法的支持。
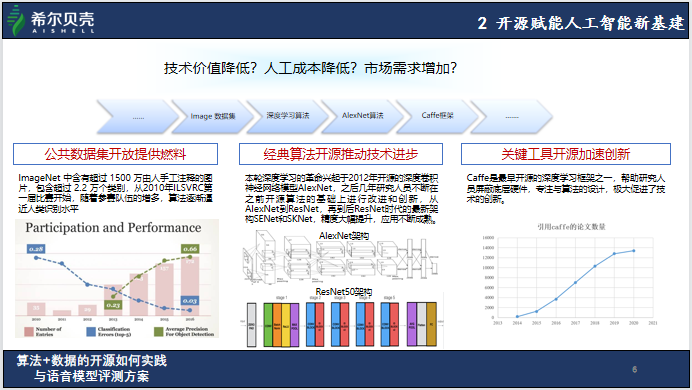
随着开源力量的崛起,市场的需求也越来越多。语音技术的开源主要是集中在海外的早期开源软件系统及算法,但国内的AI开发环境优于国外,例如目前全球最大的语音技术开发社区Kaldi在国内拥有很多开发者。
希尔贝壳自成立之初聚焦于场景数据服务,建立了开源数据项目。在疫情的影响下,越来越多的企业采用会议办公模式。卜辉认为,在会议场景下,对于说话人的跟踪、特点对象的内容转写、噪声等等,还有很多技术的点需要研究。为此,希尔贝壳发布了多通道中文会议语音数据库AISHELL-4。
卜辉介绍,AISHELL-4是一个通过麦克风阵列实录的八通道中文普通话会议场景语音数据集,包含211场会议,每场会议4至8人,数据集共120小时左右。同时提供了准确的音字转写文本及时间戳信息,方便研究者进行诸如前端处理、语音识别、说话人分割等单独任务,并可以进行联合优化。
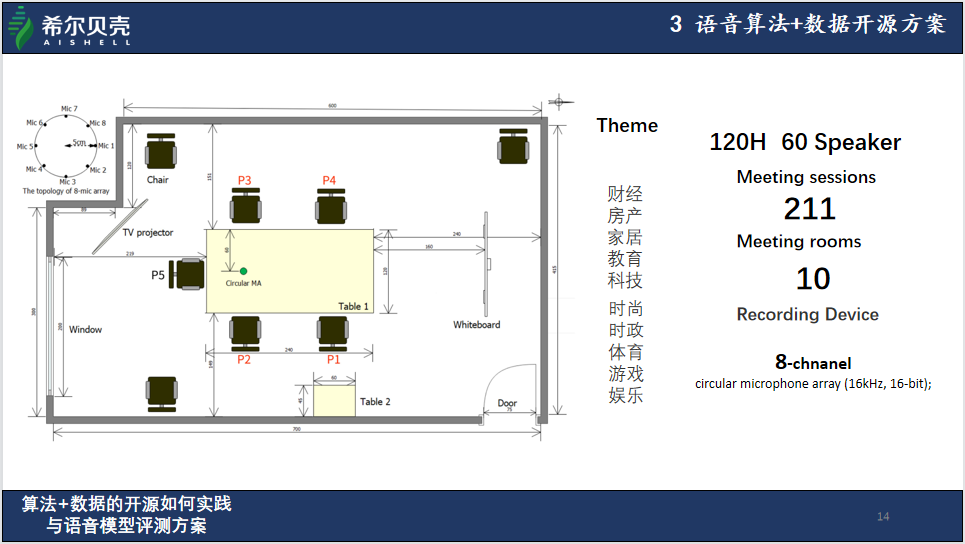
语音识别的准确率是通过数据集的评估可以体现具体的性能指标。卜辉图提到,面向场景语音识别模型的评测数据集评估规范建设可以推动智能语音技术的规范化。
希尔贝壳认为,随着整体AI算法环境的提升,语音识别技术不再是单项落地,听觉、视觉、自然语言处理结合将成为趋势,面向场景ASR模型的测试评估数据集也将重要的评估方式。未来,希尔贝壳将研发建设不完善的语言数据,同时结合图像、感知等的数据来形成多模态智能语音数据。
完整论坛视频回放,请点击:https://webinar.elecfans.com/replay/656.html

-
IntoRobot创意工作坊走进柴火创客空间取得圆满成功2016-06-12 0
-
阿里巴巴发布智能运维故障管理AI+生态计划2018-06-14 0
-
麦克风 | AI+医疗,站上了新一轮的风口?2018-08-13 0
-
横河电机计测技术解决方案研讨会圆满成功2009-08-24 638
-
2012新能源、工业与嵌入式应用方案展暨开发者论坛圆满落幕2012-08-23 461
-
我国通航低空空管服务与保障系统飞行验证圆满成功2018-09-07 3031
-
2019智能终端的AI+技术峰会圆满落幕2018-12-21 2854
-
百度成功用AI技术为输入法赋能,实现AI+输入法2020-12-25 2255
-
神舟十二号载人飞行任务圆满成功2021-09-17 3878
-
神舟十三号载人飞行任务取得圆满成功2022-04-18 1584
-
莱森光学参加第六届全国激光光谱技术学术论坛取得圆满成功2023-05-15 963
-
携手创新,前途光明——虹科2021线上年会圆满成功!2021-09-09 713
-
热烈祝贺“AI+智能传感器专委会”成立大会暨粤港澳大湾区AI+智能传感器产业研讨会圆满成功!2022-10-19 1441
-
粤港澳大湾区AI+智能传感器科技创新研讨会成功举办2024-05-14 1123
-
2024软通动力AI+数字孪生创新发展论坛圆满落幕2024-12-24 232
全部0条评论

快来发表一下你的评论吧 !
