

cacheеѓєеЖЩе•љдї£з†БзЬЯзЪДжЬЙйВ£дєИйЗНи¶БеРЧ
зФµе≠Риѓі
жППињ∞
CACHEеЯЇз°А
еѓєcacheзЪДжОМжП°пЉМеѓєдЇОLinuxеЈ•з®ЛеЄИпЉИеЕґдїЦзЪДйЭЮLinuxеЈ•з®ЛеЄИдєЯдЄАж†ЈпЉЙеЖЩеЗЇйЂШжХИиГљдї£з†БпЉМдї•еПКдЉШеМЦLinuxз≥їзїЯзЪДжАІиГљжШѓиЗ≥еЕ≥йЗНи¶БзЪДгАВзЃАеНХжЭ•иѓіпЉМcacheењЂпЉМеЖЕе≠ШжЕҐпЉМз°ђзЫШжЫіжЕҐгАВеЬ®дЄАдЄ™еЕЄеЮЛзЪДзО∞дї£CPUдЄ≠жѓФиЊГжО•ињСжФєињЫзЪДеУИдљЫзїУжЮДпЉМcacheзЪДжОТеЄГе§Іж¶ВжШѓињЩж†ЈзЪДпЉЪ
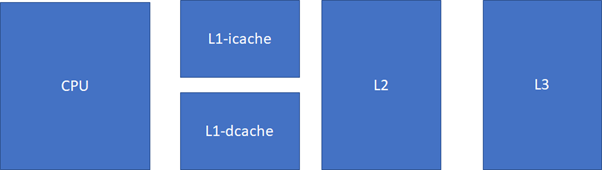
L1йАЯеЇ¶гАЛ L2йАЯеЇ¶гАЛ L3йАЯеЇ¶гАЛ RAM
L1еЃєйЗПгАК L2еЃєйЗПгАК L3еЃєйЗПгАК RAM
зО∞дї£CPUпЉМйАЪеЄЄL1 cacheзЪДжМЗдї§еТМжХ∞жНЃжШѓеИЖз¶їзЪДгАВињЩж†ЈеПѓдї•еЃЮзО∞2жЭ°йЂШйАЯеЕђиЈѓеєґи°МиЃњйЧЃпЉМCPUеПѓдї•еРМжЧґloadжМЗдї§еТМжХ∞жНЃгАВељУзДґпЉМcacheдєЯдЄНдЄАеЃЪжШѓдЄАдЄ™coreзЛђдЇЂпЉМзО∞дї£еЊИе§ЪCPUзЪДеЕЄеЮЛеИЖеЄГжШѓињЩж†ЈзЪДпЉМжѓФе¶Ве§ЪдЄ™coreеЕ±дЇЂдЄАдЄ™L3гАВжѓФе¶ВињЩеП∞зЪДLinuxйЗМйЭҐињРи°МlstopoеСљдї§пЉЪ

дЇЇдїђдєЯеЄЄеЄЄзІ∞еСЉL2cacheдЄЇMLCпЉИMiddleLevel CacheпЉЙпЉМL3cacheдЄЇLLCпЉИLast LevelCacheпЉЙгАВињЩдЇЫCacheз©ґзЂЯжЬЙе§ЪеЭЧеСҐпЉЯжИСдїђжЭ•зЬЛзЬЛIntelзЪДжХ∞жНЃпЉМеЕЈдљУйЕНзљЃпЉЪIntel i7-4770 пЉИHaswellпЉЙпЉМ 3.4 GHz пЉИTurbo BoostoffпЉЙпЉМ 22 nm. RAMпЉЪ 32 GB пЉИPC3-12800 cl11 cr2пЉЙ
иЃњйЧЃеїґињЯпЉЪ

жХ∞жНЃжЭ•жЇРпЉЪhttps://www.7-cpu.com/cpu/Haswell.html
зФ±ж≠§жИСдїђеПѓдї•зЯ•йБУпЉМжИСдїђеЇФиѓ•е∞љеПѓиГљињљж±ВcacheзЪДеСљдЄ≠зОЗйЂШпЉМдї•йБњеЕНеїґињЯпЉМжЬАе•љжШѓдљОзЇІcacheзЪДеСљдЄ≠зОЗиґКйЂШиґКе•љгАВ
CACHEзЪДзїДзїЗ
зО∞дї£зЪДcacheеЯЇжЬђжМЙзЕІињЩдЄ™ж®°еЉПжЭ•зїДзїЗпЉЪSETгАБWAYгАБTAGгАБINDEXпЉМињЩеЗ†дЄ™ж¶ВењµжШѓзРЖиІ£CacheзЪДеЕ≥йФЃгАВйЪПдЊњжЙУеЉАдЄАдЄ™жХ∞жНЃжЙЛеЖМпЉМе∞±еПѓдї•зЬЛеИ∞ињЩж†ЈзЪДе≠ЧзЬЉпЉЪ

зњїиѓСжИРдЄ≠жЦЗе∞±жШѓ4иЈѓпЉИwayпЉЙзїДпЉИsetпЉЙзЫЄиБФпЉМVIPTи°®зО∞дЄЇпЉИbehave asпЉЙPIPT --ињЩе∞ЉзОЫдїАдєИйђЉпЉЯпЉМcachelineзЪДйХњеЇ¶жШѓ64е≠ЧиКВгАВ
дЄЛйЭҐжИСдїђжЭ•жГ≥и±°дЄАдЄ™16KBе§Іе∞ПзЪДcacheпЉМеБЗиЃЊжШѓ4иЈѓзїДзЫЄиБФпЉМcachelineзЪДйХњеЇ¶жШѓ64е≠ЧиКВгАВCachelineзЪДж¶ВењµжѓФиЊГзЃАеНХпЉМcacheзЪДжХідЄ™жЫњжНҐжШѓдї•и°МдЄЇеНХдљНзЪДпЉМдЄАи°М64дЄ™е≠ЧиКВйЗМйЭҐиѓїдЇЖдїїдљХдЄАдЄ™е≠ЧиКВпЉМеЕґеЃЮжХідЄ™64е≠ЧиКВе∞±ињЫеЕ•дЇЖcacheгАВ
жѓФе¶ВдЄЛйЭҐдЄ§жЃµз®ЛеЇПпЉМеЙНиАЕзЪДиЃ°зЃЧйЗПжШѓеРОиАЕзЪД8еАНпЉЪ

дљЖжШѓеЃГзЪДжЙІи°МжЧґйЧіпЉМеИЩињЬињЬдЄНеИ∞еРОиАЕзЪД8еАНпЉЪ
16KBзЪДcacheжШѓ4wayзЪДиѓЭпЉМжѓПдЄ™setеМЕжЛђ4*64BпЉМеИЩжХідЄ™cacheеИЖдЄЇ16KB/64B/4 = 64setпЉМдєЯеН≥2зЪД6жђ°жЦєгАВељУCPUдїОcacheйЗМйЭҐиѓїжХ∞жНЃзЪДжЧґеАЩпЉМеЃГдЉЪзФ®еЬ∞еЭАдљНзЪДBIT6-BIT11жЭ•еѓїеЭАsetпЉМBIT0-BIT5жШѓcachelineеЖЕзЪДoffsetгАВ
жѓФе¶ВCPUиЃњйЧЃеЬ∞еЭА
0 000000 XXXXXX
жИЦиАЕ
1 000000 XXXXXX
жИЦиАЕ
YYYY 000000 XXXXXX
зФ±дЇОеЃГдїђзЇҐиЙ≤зЪД6дљНйГљзЫЄеРМпЉМжЙАдї•дїЦдїђеЕ®йГ®йГљдЉЪжЙЊеИ∞зђђ0дЄ™setзЪДcachelineгАВзђђ0дЄ™setйЗМйЭҐжЬЙ4дЄ™wayпЉМдєЛеРОз°ђдїґдЉЪзФ®еЬ∞еЭАзЪДйЂШдљНе¶В0пЉМ1пЉМYYYYдљЬдЄЇtagпЉМеОїж£А糥ињЩ4дЄ™wayзЪДtagжШѓеР¶дЄОеЬ∞еЭАзЪДйЂШдљНзЫЄеРМпЉМиАМдЄФcachelineжШѓеР¶жЬЙжХИпЉМе¶ВжЮЬtagеМєйЕНдЄФcachelineжЬЙжХИпЉМеИЩcacheеСљдЄ≠гАВ
жЙАдї•еЬ∞еЭАYYYYYY000000XXXXXXеЕ®йГ®йГљжШѓжЙЊзђђ0дЄ™setпЉМYYYYYY000001XXXXXXеЕ®йГ®йГљжШѓжЙЊзђђ1дЄ™setпЉМYYYYYY111111XXXXXXеЕ®йГ®йГљжШѓжЙЊзђђ63дЄ™setгАВжѓПдЄ™setдЄ≠зЪД4дЄ™wayпЉМйГљжЬЙеПѓиГљеСљдЄ≠гАВ
дЄ≠йЧізЇҐиЙ≤зЪДдљНе∞±жШѓINDEXпЉМеЙНйЭҐYYYYињЩдЇЫдљНе∞±жШѓTAGгАВеЕЈдљУзЪДеЃЮзО∞еПѓдї•жШѓзФ®иЩЪжЛЯеЬ∞еЭАжИЦиАЕзЙ©зРЖеЬ∞еЭАзЪДзЫЄеЇФдљНеБЪTAGжИЦиАЕINDEXгАВе¶ВжЮЬзФ®иЩЪжЛЯеЬ∞еЭАеБЪTAGпЉМжИСдїђеПЂVTпЉЫе¶ВжЮЬзФ®зЙ©зРЖеЬ∞еЭАеБЪTAGпЉМжИСдїђеПЂPTпЉЫе¶ВжЮЬзФ®иЩЪжЛЯеЬ∞еЭАеБЪINDEXпЉМжИСдїђеПЂVIпЉЫе¶ВжЮЬзФ®зЙ©зРЖеЬ∞еЭАеБЪTAGпЉМжИСдїђеПЂPTгАВеЈ•з®ЛдЄ≠зҐ∞еИ∞зЪДcacheеПѓиГљжЬЙињЩдєИдЇЫзїДеРИпЉЪ
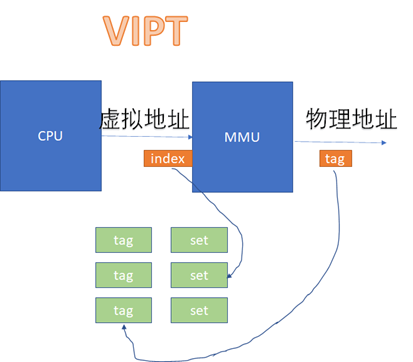
VIVTгАБVIPTгАБPIPTгАВ
VIVTзЪДз°ђдїґеЃЮзО∞еЉАйФАжЬАдљОпЉМдљЖжШѓиљѓдїґзїіжК§жИРжЬђйЂШпЉЫPIPTзЪДз°ђдїґеЃЮзО∞еЉАйФАжЬАйЂШпЉМдљЖжШѓиљѓдїґзїіжК§жИРжЬђжЬАдљОпЉЫVIPTдїЛдЇОдЇМиАЕдєЛйЧіпЉМдљЖжШѓжЬЙдЇЫз°ђдїґжШѓVIPTпЉМдљЖжШѓbehave as PIPTпЉМињЩж†ЈеѓєиљѓдїґиАМи®АпЉМзїіжК§жИРжЬђдЄОPIPTдЄАж†ЈгАВ
еЬ®VIVTзЪДжГЕеЖµдЄЛпЉМCPUеПСеЗЇзЪДиЩЪжЛЯеЬ∞еЭАпЉМдЄНйЬАи¶БзїПињЗMMUзЪДиљђеМЦпЉМзЫіжО•е∞±еПѓдї•еОїжЯ•cacheгАВ
иАМеЬ®VIPTеТМPIPTзЪДеЬЇжЩѓдЄЛпЉМйГљжґЙеПКеИ∞иЩЪжЛЯеЬ∞еЭАиљђжНҐдЄЇзЙ©зРЖеЬ∞еЭАеРОпЉМеЖНеОїжѓФеѓєcacheзЪДињЗз®ЛгАВVIPTе¶ВдЄЛпЉЪ
PIPTе¶ВдЄЛпЉЪ
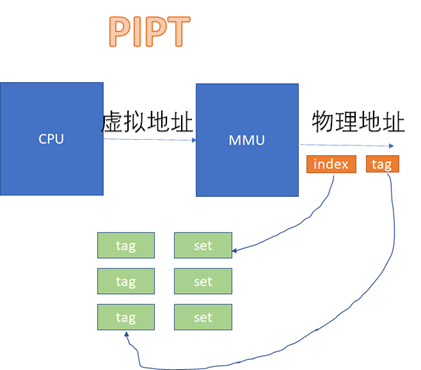
дїОеЫЊдЄКзЬЛиµЈжЭ•пЉМVIVTзЪДз°ђдїґеЃЮзО∞жХИзОЗеЊИйЂШпЉМдЄНйЬАи¶БзїПињЗMMUе∞±еПѓдї•еОїжЯ•cacheдЇЖгАВдЄНињЗпЉМеѓєиљѓдїґжЭ•иѓіпЉМињЩжШѓдЄ™зБЊйЪЊгАВеЫ†дЄЇVIVTжЬЙдЄ•йЗНзЪДж≠ІдєЙеТМеИЂеРНйЧЃйҐШгАВ
ж≠ІдєЙпЉЪдЄАдЄ™иЩЪжЛЯеЬ∞еЭАеЕИеРОжМЗеРСдЄ§дЄ™пЉИжИЦиАЕе§ЪдЄ™пЉЙзЙ©зРЖеЬ∞еЭА
еИЂеРНпЉЪдЄ§дЄ™пЉИжИЦиАЕе§ЪдЄ™пЉЙиЩЪжЛЯеЬ∞еЭАеРМжЧґжМЗеРСдЄАдЄ™зЙ©зРЖеЬ∞еЭА
ињЩйЗМжИСдїђйЗНзВєзЬЛеИЂеРНйЧЃйҐШгАВжѓФе¶В2дЄ™иЩЪжЛЯеЬ∞еЭАеѓєеЇФеРМдЄАдЄ™зЙ©зРЖеЬ∞еЭАпЉМеЯЇдЇОVIVTзЪДйАїиЊСпЉМжЧ†иЃЇжШѓINDEXињШжШѓTAGпЉМ2дЄ™иЩЪжЛЯеЬ∞еЭАйГљжШѓеПѓиГљдЄНдЄАж†ЈзЪДпЉИе∞љзЃ°дїЦдїђзЪДзЙ©зРЖеЬ∞еЭАдЄАж†ЈпЉМдљЖжШѓзЙ©зРЖеЬ∞еЭАеЬ®cacheжѓФеѓєдЄ≠еЃМеЕ®дЄНжОЇеТМпЉЙпЉМињЩж†ЈеЃГдїђеЃМеЕ®еПѓиГљеЬ®2дЄ™cachelineеРМжЧґеСљдЄ≠гАВ
зФ±дЇО2дЄ™иЩЪжЛЯеЬ∞еЭАжМЗеРС1дЄ™зЙ©зРЖеЬ∞еЭАпЉМињЩж†ЈCPUеЖЩињЗзђђдЄАдЄ™иЩЪжЛЯеЬ∞еЭАеРОпЉМеЖЩеЕ•cacheline1гАВCPUиѓїзђђ2дЄ™иЩЪжЛЯеЬ∞еЭАпЉМиѓїеИ∞зЪДжШѓињЗжЧґзЪДcacheline2пЉМињЩж†Је∞±еЗЇзО∞дЇЖдЄНдЄАиЗігАВжЙАдї•пЉМдЄЇдЇЖйБњеЕНињЩзІНжГЕеЖµпЉМиљѓдїґењЕй°їеЖЩеЃМиЩЪжЛЯеЬ∞еЭА1еРОпЉМеѓєиЩЪжЛЯеЬ∞еЭА1еѓєеЇФзЪДcacheжЙІи°МcleanпЉМеѓєиЩЪжЛЯеЬ∞еЭА2еѓєеЇФзЪДcacheжЙІи°МinvalidateгАВ
иАМPIPTеЃМеЕ®ж≤°жЬЙињЩж†ЈзЪДйЧЃйҐШпЉМеЫ†дЄЇжЧ†иЃЇе§Ъе∞СиЩЪжЛЯеЬ∞еЭАеѓєеЇФдЄАдЄ™зЙ©зРЖеЬ∞еЭАпЉМзФ±дЇОзЙ©зРЖеЬ∞еЭАдЄАж†ЈпЉМжИСдїђжШѓеЯЇдЇОзЙ©зРЖеЬ∞еЭАеОїеѓїжЙЊеТМжѓФеѓєcacheзЪДпЉМжЙАдї•дЄНеПѓиГљеЗЇзО∞ињЩзІНеИЂеРНйЧЃйҐШгАВ
йВ£дєИVIPTжЬЙж≤°жЬЙеПѓиГљеЗЇзО∞еИЂеРНеСҐпЉЯз≠Фж°ИжШѓжЬЙеПѓиГљпЉМдєЯжЬЙеПѓиГљдЄНиГљгАВе¶ВжЮЬVIжБ∞е•љеѓєдЇОPIпЉМе∞±дЄНеПѓиГљпЉМињЩдЄ™жЧґеАЩпЉМVIPTеѓєиљѓдїґиАМи®Ае∞±жШѓPIPTдЇЖпЉЪ
VI=PI
PT=PT
йВ£дєИдїАдєИжЧґеАЩVIдЉЪз≠ЙдЇОPIеСҐпЉЯињЩдЄ™жЧґеАЩжИСдїђжЭ•еЫЮењЖдЄЛиЩЪжЛЯеЬ∞еЭАеЊАзЙ©зРЖеЬ∞еЭАзЪДиљђжНҐињЗз®ЛпЉМеЃГжШѓдї•й°µдЄЇеНХдљНзЪДгАВеБЗиЃЊдЄАй°µжШѓ4KпЉМйВ£дєИеЬ∞еЭАзЪДдљО12дљНиЩЪжЛЯеЬ∞еЭАеТМзЙ©зРЖеЬ∞еЭАжШѓеЃМеЕ®дЄАж†ЈзЪДгАВеЫЮењЖжИСдїђеЙНйЭҐзЪДеЬ∞еЭАпЉЪ
YYYYY000000XXXXXX
еЕґдЄ≠зЇҐиЙ≤зЪД000000жШѓINDEXгАВеЬ®жИСдїђзЪДдЊЛе≠РдЄ≠пЉМзЇҐиЙ≤зЪД6дљНеТМеРОйЭҐзЪДXXXXXXпЉИcacheеЖЕйГ®еБПзІїпЉЙеК†иµЈжЭ•ж≠£е•љ12дљНпЉМжЙАдї•ињЩдЄ™000000зїПињЗиЩЪеЃЮиљђжНҐеРОпЉМеЕґеЃЮињШжШѓ000000зЪДпЉМињЩдЄ™жЧґеАЩVI=PIпЉМVIPTж≤°жЬЙеИЂеРНйЧЃйҐШгАВ
жИСдїђеОЯеЕИеБЗиЃЊзЪДcacheжШѓпЉЪ16KBе§Іе∞ПзЪДcacheпЉМеБЗиЃЊжШѓ4иЈѓзїДзЫЄиБФпЉМcachelineзЪДйХњеЇ¶жШѓ64е≠ЧиКВпЉМињЩж†ЈжИСдїђж≠£е•љйЬАи¶БзЇҐиЙ≤зЪД6дљНжЭ•дљЬдЄЇINDEXгАВдљЖжШѓе¶ВжЮЬжИСдїђжККcacheзЪДе§Іе∞ПеҐЮеК†дЄЇ32KBпЉМињЩж†ЈжИСдїђйЬАи¶Б 32KB/4/64B=128=2^7пЉМдєЯеН≥7дљНжЭ•еБЪINDEXгАВ
YYYY0000000XXXXXX
ињЩж†ЈVIе∞±еПѓиГљдЄНз≠ЙдЇОPIдЇЖпЉМеЫ†дЄЇзЇҐиЙ≤зЪДжЬАйЂШдљНиґЕињЗдЇЖ2^12зЪДиМГеЫіпЉМеЃМеЕ®еПѓиГљеЗЇзО∞е¶ВдЄЛ2дЄ™иЩЪжЛЯеЬ∞еЭАпЉМжМЗеРСеРМдЄАдЄ™зЙ©зРЖеЬ∞еЭАпЉЪ
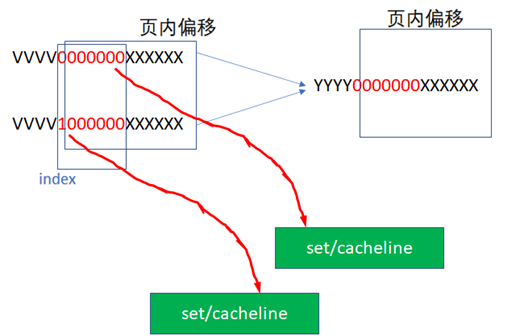
ињЩж†Је∞±еЗЇзО∞дЇЖеИЂеРНйЧЃйҐШпЉМжИСдїђеЬ®еЈ•з®ЛйЗМпЉМеПѓиГљеПѓдї•йАЪињЗдЄАдЇЫеКЮж≥ХйБњеЕНињЩзІНеИЂеРНйЧЃйҐШпЉМжѓФе¶ВиљѓдїґеЬ®еїЇзЂЛиЩЪеЃЮиљђжНҐзЪДжЧґеАЩпЉМжККиЩЪеЃЮиљђжНҐеЊА2^13иАМдЄНжШѓ2^12еѓєйљРпЉМиЃ©зЙ©зРЖеЬ∞еЭАзЪДдљО13дљНиАМдЄНжШѓдљО12дљНдЄОзЙ©зРЖеЬ∞еЭАзЫЄеРМгАВ
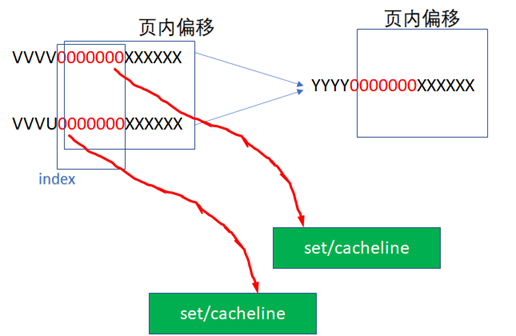
ињЩж†ЈеЉЇи°МзїХеЉАеИЂеРНйЧЃйҐШпЉМдЄЛеЫЊдЄ≠пЉМ2дЄ™иЩЪжЛЯеЬ∞еЭАжМЗеРСдЇЖеРМдЄАдЄ™зЙ©зРЖеЬ∞еЭАпЉМдљЖжШѓеЃГдїђзЪДINDEXжШѓзЫЄеРМзЪДпЉМињЩж†ЈVI=PIпЉМе∞±зїХеЉАдЇЖеИЂеРНйЧЃйҐШгАВињЩйАЪеЄЄжШѓPAGE COLOURINGжКАжЬѓдЄ≠зЪДдЄАзІНжКАеЈІгАВ
е¶ВжЮЬињЩзІНPAGE COLOURINGзЪДйЩРеИґеѓєиљѓдїґдїНзДґдЄНеПѓжО•еПЧпЉМиАМжИСдїђеПИжГ≥дЇЂеПЧVIPTзЪДINDEXдЄНйЬАи¶БзїПињЗMMUиЩЪеЃЮиљђжНҐзЪДењЂжНЈпЉЯжЬЙж≤°жЬЙдїАдєИз°ђдїґжКАжЬѓжЭ•иІ£еЖ≥VIPTеИЂеРНйЧЃйҐШеСҐпЉЯз°ЃеЃЮжШѓе≠ШеЬ®зЪДпЉМзО∞дї£CPUеЊИе§ЪйГљжШѓжККL1 CACHEеБЪжИРVIPTпЉМдљЖжШѓи°®зО∞еЬ∞пЉИbehave asпЉЙеГПPIPTгАВињЩжШѓжАОдєИеБЪеИ∞зЪДеСҐпЉЯ
ињЩи¶Бж±ВVIPTзЪДcacheпЉМз°ђдїґдЄКеЕЈе§Зalias detectionзЪДиГљеКЫгАВжѓФе¶ВпЉМз°ђдїґзЯ•йБУYYYY0000000XXXXXXжЧҐжЬЙеПѓиГљеЗЇзО∞еЬ®зђђ0000000пЉМеПИеПѓиГљеЗЇзО∞еЬ®1000000ињЩ2дЄ™setпЉМзДґеРОз°ђдїґиЗ™еК®еОїжѓФеѓєињЩ2дЄ™setйЗМйЭҐжШѓеР¶еЗЇзО∞жШ†е∞ДеИ∞зЫЄеРМзЙ©зРЖеЬ∞еЭАзЪДcachelineпЉМеєґдїОз°ђдїґдЄКиІ£еЖ≥е•љеИЂеРНеРМж≠•пЉМйВ£дєИиљѓдїґе∞±еЃМеЕ®дЄНзФ®жУНењГдЇЖгАВ
дЄЛйЭҐжИСдїђиЃ∞дљПдЄАдЄ™зЃАеНХзЪДиІДеИЩпЉЪ
еѓєдЇОVIPTпЉМе¶ВжЮЬcacheзЪДsizeйЩ§дї•WAYжХ∞пЉМе∞ПдЇОз≠ЙдЇО1дЄ™pageзЪДе§Іе∞ПпЉМеИЩ姩зДґVI=PIпЉМжЧ†еИЂеРНйЧЃйҐШпЉЫ
еѓєдЇОVIPTпЉМе¶ВжЮЬcacheзЪДsizeйЩ§дї•WAYжХ∞пЉМе§ІдЇО1дЄ™pageзЪДе§Іе∞ПпЉМеИЩ姩зДґVIвЙ†PIпЉМжЬЙеИЂеРНйЧЃйҐШпЉЫињЩдЄ™жЧґеАЩеПИеИЖжИР2зІНжГЕеЖµпЉЪ
з°ђдїґдЄНеЕЈе§Зalias detectionиГљеКЫпЉМиљѓдїґйЬАи¶БpagecolouringпЉЫ
з°ђдїґеЕЈе§Зalias detectionиГљеКЫпЉМиљѓдїґжККcacheељУжИРPIPTзФ®гАВ
жѓФе¶Вcacheе§Іе∞П64KBпЉМ4WAYпЉМPAGE SIZEжШѓ4KпЉМжШЊзДґжЬЙеИЂеРНйЧЃйҐШпЉЫињЩдЄ™жЧґеАЩпЉМе¶ВжЮЬcacheжФєдЄЇ16WAYпЉМжИЦиАЕPAGE SIZEжФєдЄЇ16KпЉМдЄНеЖНжЬЙеИЂеРНйЧЃйҐШгАВдЄЇдїАдєИпЉЯжДЯиІЙе∞Пе≠¶жХ∞е≠¶зЯ•иѓЖдєЯиГљзЃЧеЊЧжЄЕ
CACHEзЪДдЄАиЗіжАІ
CacheзЪДдЄАиЗіжАІжЬЙињЩдєИеЗ†дЄ™е±ВйЭҐ
1. дЄАдЄ™CPUзЪДicacheеТМdcacheзЪДеРМж≠•йЧЃйҐШ
2. е§ЪдЄ™CPUеРДиЗ™зЪДcacheеРМж≠•йЧЃйҐШ
3. CPUдЄОиЃЊе§ЗпЉИеЕґеЃЮдєЯеПѓиГљжШѓдЄ™еЉВжЮДе§ДзРЖеЩ®пЉМдЄНињЗеЬ®LinuxињРи°МзЪДCPUзЬЉйЗМпЉМйГљжШѓиЃЊе§ЗпЉМйГљжШѓDMAпЉЙзЪДcacheеРМж≠•йЧЃйҐШ
еЕИзЬЛдЄАдЄЛICACHEеТМDCACHEеРМж≠•йЧЃйҐШгАВзФ±дЇОз®ЛеЇПзЪДињРи°МиАМи®АпЉМжМЗдї§жµБзЪДйГљжµБињЗicacheпЉМиАМжМЗдї§дЄ≠жґЙеПКеИ∞зЪДжХ∞жНЃжµБзїПињЗdcacheгАВжЙАдї•еѓєдЇОиЗ™дњЃжФєзЪДдї£з†БпЉИSelf-Modifying CodeпЉЙиАМи®АпЉМжѓФе¶ВжИСдїђдњЃжФєдЇЖеЖЕе≠ШpињЩдЄ™дљНзљЃзЪДдї£з†БпЉИеЕЄеЮЛе§ЪиІБдЇОJIT compilerпЉЙпЉМињЩдЄ™жЧґеАЩжИСдїђжШѓйАЪињЗstoreзЪДжЦєеЉПеОїеЖЩзЪДpпЉМжЙАдї•жЦ∞зЪДжМЗдї§дЉЪињЫеЕ•dcacheгАВдљЖжШѓжИСдїђжО•дЄЛжЭ•еОїжЙІи°МpдљНзљЃзЪДжМЗдї§зЪДжЧґеАЩпЉМicacheйЗМйЭҐеПѓиГљеСљдЄ≠зЪДжШѓдњЃжФєдєЛеЙНзЪДжМЗдї§гАВ
жЙАдї•ињЩдЄ™жЧґеАЩиљѓдїґйЬАи¶БжККdcacheзЪДдЄЬи•њcleanеЗЇеОїпЉМзДґеРОиЃ©icache invalidateпЉМињЩдЄ™еЉАйФАжШЊзДґињШжШѓжѓФиЊГе§ІзЪДгАВ
дљЖжШѓпЉМжѓФе¶ВARM64зЪДN1е§ДзРЖеЩ®пЉМеЃГжФѓжМБз°ђдїґзЪДicacheеРМж≠•пЉМиѓ¶иІБжЦЗж°£пЉЪThe Arm Neoverse N1 PlatformпЉЪ Building Blocks for the Next-Gen Cloud-to-Edge Infrastructure SoC
зЙєеИЂж≥®жДПзФїзЇҐиЙ≤зЪДеЗ†и°МгАВиљѓдїґзїіжК§зЪДжИРжЬђеЃЮйЩЕеЊИйЂШпЉМињШжґЙеПКеИ∞icacheзЪДinvalidationеРСжЙАжЬЙж†ЄеєњжТ≠зЪДеК®дљЬгАВ
жО•дЄЛжЭ•зЪДдЄАдЄ™йЧЃйҐШе∞±жШѓе§ЪдЄ™ж†ЄдєЛйЧізЪДcacheеРМж≠•гАВдЄЛйЭҐжШѓдЄАдЄ™зЃАеМЦзЙИзЪДе§ДзРЖеЩ®пЉМCPU_AеТМBеЕ±дЇЂдЇЖдЄАдЄ™L3пЉМCPU_CеТМCPU_DеЕ±дЇЂдЇЖдЄАдЄ™L3гАВеЃЮйЩЕзЪДз°ђдїґжЮґжЮДзФ±дЇОжґЙеПКеИ∞NUMAпЉМдЉЪжѓФињЩдЄ™жЫіеК†е§НжЭВпЉМдљЖжШѓињЩдЄ™еЫЊеПНжШ†е±ВзЇІеЕ≥з≥їжШѓиґ≥е§ЯдЇЖгАВ
жѓФе¶ВCPU_AиѓїдЇЖдЄАдЄ™еЬ∞еЭАpзЪДеПШйЗПпЉЯCPU_BгАБCгАБDеПИиѓїпЉМйЪЊйБУBпЉМCпЉМDеПИењЕй°їдїОRAMйЗМйЭҐзїПињЗL3пЉМL2пЉМL1еЖНиѓїдЄАйБНеРЧпЉЯињЩдЄ™жШЊзДґжШѓж≤°жЬЙењЕи¶БзЪДпЉМеЬ®з°ђдїґдЄКпЉМcacheзЪДsnoopingжОІеИґеНХеЕГпЉМеПѓдї•еНПеК©зЫіжО•жККCPU_AзЪДpеЬ∞еЭАcacheжЛЈиіЭеИ∞CPU_BгАБCеТМDзЪДcacheгАВ
ињЩж†ЈA-B-C-DйГљеЊЧеИ∞дЇЖзЫЄеРМзЪДpеЬ∞еЭАзЪДж£ХиЙ≤е∞ПзРГгАВ
еБЗиЃЊCPU BињЩдЄ™жЧґеАЩпЉМжККж£ХиЙ≤е∞ПзРГеЖЩжИРзЇҐиЙ≤пЉМиАМеЕґдїЦCPUйЗМйЭҐињШжШѓж£ХиЙ≤пЉМињЩж†Је∞±дЉЪдЄНдЄАиЗідЇЖпЉЪ
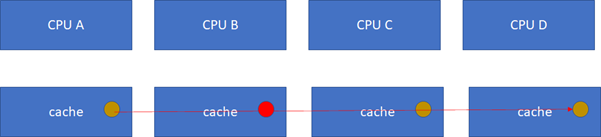
ињЩдЄ™жЧґеАЩжАОдєИеКЮпЉЯињЩйЗМйЭҐжШЊзДґйЬАи¶БдЄАдЄ™еНПиЃЃпЉМеЕЄеЮЛзЪДе§Ъж†ЄcacheеРМж≠•еНПиЃЃжЬЙMESIеТМMOESIгАВMOESIзЫЄеѓєMESIжЬЙдЇЫзїЖеЊЃзЪДеЈЃеЉВпЉМдЄНељ±еУНеѓєеЕ®е±АзЪДзРЖиІ£гАВдЄЛйЭҐжИСдїђйЗНзВєзЬЛMESIеНПиЃЃгАВ
MESIеНПиЃЃеЃЪдєЙдЇЖ4зІНзКґжАБпЉЪ
MпЉИModifiedпЉЙпЉЪ ељУеЙНcacheзЪДеЖЕеЃєжЬЙжХИпЉМжХ∞жНЃеЈ≤襀䜁жФєиАМдЄФдЄОеЖЕе≠ШдЄ≠зЪДжХ∞жНЃдЄНдЄАиЗіпЉМжХ∞жНЃеП™еЬ®ељУеЙНcacheйЗМе≠ШеЬ®пЉЫз±їдЉЉRAMйЗМйЭҐжШѓж£ХиЙ≤зРГпЉМBйЗМйЭҐжШѓзЇҐиЙ≤зРГпЉИCACHEдЄОRAMдЄНдЄАиЗіпЉЙпЉМAгАБCгАБDйГљж≤°жЬЙзРГгАВ
EпЉИExclusiveпЉЙпЉЪељУеЙНcacheзЪДеЖЕеЃєжЬЙжХИпЉМжХ∞жНЃдЄОеЖЕе≠ШдЄ≠зЪДжХ∞жНЃдЄАиЗіпЉМжХ∞жНЃеП™еЬ®ељУеЙНcacheйЗМе≠ШеЬ®пЉЫз±їдЉЉRAMйЗМйЭҐжШѓж£ХиЙ≤зРГпЉМBйЗМйЭҐжШѓж£ХиЙ≤зРГпЉИRAMеТМCACHEдЄАиЗіпЉЙпЉМAгАБCгАБDйГљж≤°жЬЙзРГгАВ
SпЉИSharedпЉЙпЉЪељУеЙНcacheзЪДеЖЕеЃєжЬЙжХИпЉМжХ∞жНЃдЄОеЖЕе≠ШдЄ≠зЪДжХ∞жНЃдЄАиЗіпЉМжХ∞жНЃеЬ®е§ЪдЄ™cacheйЗМе≠ШеЬ®гАВз±їдЉЉе¶ВдЄЛеЫЊпЉМеЬ®CPU A-B-CйЗМйЭҐcacheзЪДж£ХиЙ≤зРГйГљдЄОRAMдЄАиЗігАВ
IпЉИInvalidпЉЙпЉЪ ељУеЙНcacheжЧ†жХИгАВеЙНйЭҐдЄЙеєЕеЫЊйЗМйЭҐcacheж≤°жЬЙзРГзЪДйВ£дЇЫйГљжШѓе±ЮдЇОињЩдЄ™жГЕеЖµгАВ
зДґеРОеЃГжЬЙдЄ™зКґжАБжЬЇ
ињЩдЄ™зКґжАБжЬЇжѓФиЊГйЪЊиЃ∞пЉМж≠їиЃ∞з°ђиГМжШѓиЃ∞дЄНдљПзЪДпЉМдєЯж≤°ењЕи¶БиЃ∞пЉМеЃГиЃ≤зЪДcacheеОЯеЕИзЪДзКґжАБпЉМзїПињЗдЄАдЄ™з°ђдїґеЬ®жЬђcacheжИЦиАЕеЕґдїЦcacheзЪДиѓїеЖЩжУНдљЬеРОпЉМеРДдЄ™cacheзЪДзКґжАБдЉЪе¶ВдљХеПШињБгАВжЙАдї•пЉМз°ђдїґдЄКдЄНдїЕдїЕжШѓзЫСжОІжЬђCPUзЪДcacheиѓїеЖЩи°МдЄЇпЉМињШдЉЪзЫСжОІеЕґдїЦCPUзЪДгАВеП™йЬАи¶БиЃ∞дљПдЄАзВєпЉЪињЩдЄ™зКґжАБжЬЇжШѓдЄЇдЇЖдњЭиѓБе§Ъж†ЄдєЛйЧіcacheзЪДдЄАиЗіжАІпЉМжѓФе¶ВдЄАдЄ™еє≤еЗАзЪДжХ∞жНЃпЉМеПѓдї•еЬ®е§ЪдЄ™CPUзЪДcache shareпЉМињЩдЄ™ж≤°жЬЙдЄАиЗіжАІйЧЃйҐШпЉЫдљЖжШѓпЉМеБЗиЃЊеЕґдЄ≠дЄАдЄ™CPUеЖЩињЗдЇЖпЉМжѓФе¶ВA-B-CжЬђжЭ•жШѓињЩж†ЈпЉЪ
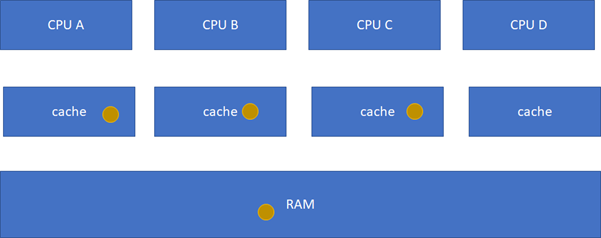
зДґеРОB襀еЖЩињЗдЇЖпЉЪ
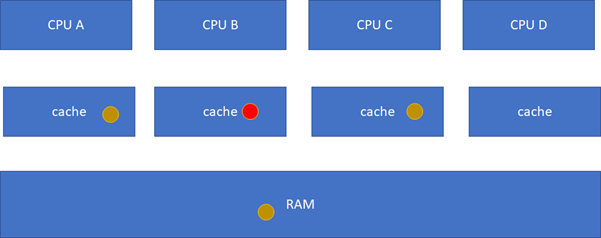
ињЩж†ЈAгАБCзЪДcacheеЃЮйЩЕжШѓињЗжЧґзЪДжХ∞жНЃпЉМињЩжШѓдЄНеЕБиЃЄзЪДгАВињЩдЄ™жЧґеАЩпЉМз°ђдїґдЉЪиЗ™еК®жККAгАБCзЪДcache invalidateжОЙпЉМдЄНйЬАи¶БиљѓдїґзЪДеє≤йҐДпЉМAгАБCеЕґеЃЮеПШеЬ∞зЫЄељУдЇОдЄНеСљдЄ≠ињЩдЄ™зРГдЇЖпЉЪ
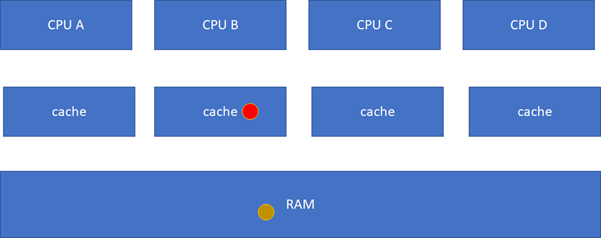
ињЩдЄ™жЧґеАЩпЉМдљ†еПѓиГљдЉЪзїІзї≠йЧЃпЉМе¶ВжЮЬCи¶БиѓїињЩдЄ™зРГеСҐпЉЯеЃГзЫЃеЙНзЪДзКґжАБеЬ®BйЗМйЭҐжШѓmodifiedзЪДпЉМиАМдЄФдЄОRAMдЄНдЄАиЗіпЉМињЩдЄ™жЧґеАЩпЉМз°ђдїґдЉЪжККзЇҐзРГcleanпЉМзДґеРОBгАБCгАБRAMеПШеЬ∞дЄАиЗіпЉМBгАБCзЪДзКґжАБйГљеПШеМЦдЄЇSпЉИSharedпЉЙпЉЪ
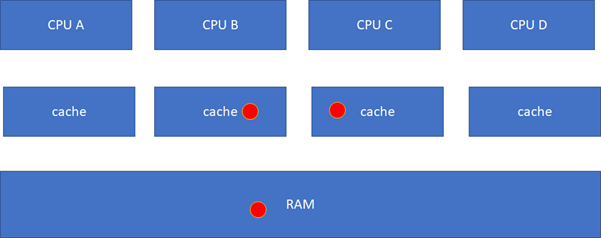
ињЩдЄАз≥їеИЧзЪДеК®дљЬиЩљзДґзФ±з°ђдїґеЃМжИРпЉМдљЖжШѓеѓєиљѓдїґиАМи®АдЄНжШѓеЕНиієзЪДпЉМеЫ†дЄЇеЃГиАЧиієдЇЖжЧґйЧігАВе¶ВжЮЬзЉЦз®ЛзЪДжЧґеАЩдЄНж≥®жДПпЉМеЉХиµЈдЇЖз°ђдїґзЪДе§ІйЗПcacheеРМж≠•и°МдЄЇпЉМеИЩз®ЛеЇПзЪДжХИзОЗеПѓиГљдЉЪжА•еЙІдЄЛйЩНгАВ
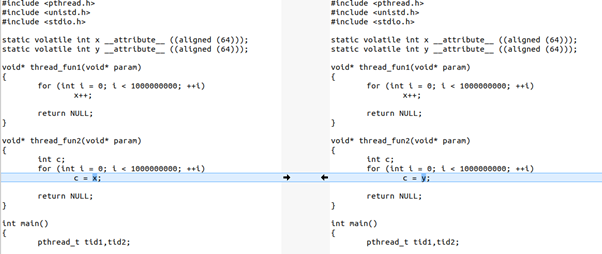
дЄЇдЇЖиЃ©е§ІеЃґзЫіиІВжДЯеПЧеИ∞ињЩдЄ™cacheеРМж≠•зЪДеЉАйФАпЉМдЄЛйЭҐжИСдїђеЖЩдЄАдЄ™з®ЛеЇПпЉМињЩдЄ™з®ЛеЇПжЬЙ2дЄ™зЇњз®ЛпЉМдЄАдЄ™еЖЩеПШйЗПпЉМдЄАдЄ™иѓїеПШйЗПпЉЪ

ињЩдЄ™з®ЛеЇПйЗМпЉМxеТМyйГљжШѓcachelineеѓєйљРзЪДпЉМињЩдЄ™з®ЛеЇПзЪДthread1зЪДеЖЩпЉМдЉЪдЄНеБЬеЬ∞дЄОthread2зЪДиѓїпЉМињЫи°МcacheеРМж≠•гАВ
еЃГзЪДжЙІи°МжЧґйЧідЄЇпЉЪ
$ time гАВ/a.out real 0m3.614suser 0m7.021ssys 0m0.004s
еЃГеЬ®2дЄ™CPUдЄКзЪДuserspaceеЕ±ињРи°МдЇЖ7.021зІТпЉМзіѓиЃ°ињЩдЄ™з®ЛеЇПдїОеЉАеІЛеИ∞зїУжЭЯзЪДеѓєеЇФзЬЯеЃЮдЄЦзХМзЪДжЧґйЧіжШѓ3.614зІТпЉИе∞±жШѓдїОеСљдї§еЉАеІЛеИ∞еСљдї§зїУжЭЯзЪДжЧґйЧіпЉЙгАВ
е¶ВжЮЬжИСдїђжККз®ЛеЇПжФєдЄАеП•иѓЭпЉМжККthread2йЗМйЭҐзЪДc = xжФєдЄЇc = yпЉМињЩж†Ј2дЄ™зЇњз®ЛеЬ®2дЄ™CPUињРи°МзЪДжЧґеАЩпЉМиѓїеЖЩзЪДжШѓдЄНеРМзЪДcachelineпЉМе∞±ж≤°жЬЙињЩдЄ™з°ђдїґзЪДcacheеРМж≠•еЉАйФАдЇЖпЉЪ
еЃГзЪДињРи°МжЧґйЧіпЉЪ
$ time гАВ/b.out real 0m1.820suser 0m3.606ssys 0m0.008s
зО∞еЬ®еП™йЬАи¶Б1.8зІТпЉМеЗ†дєОеЗПе∞ПдЇЖдЄАеНКгАВ
жДЯиІЙеЙНйЭҐйВ£дЄ™a.outпЉМеПМж†ЄзЪДеЄЃеК©зФЪиЗ≥йГљдЄНе§ІгАВе¶ВжЮЬжИСдїђжФєдЄЇеНХж†ЄиЈСеСҐпЉЯ
$ time taskset -c 0 гАВ/a.out real 0m3.299suser 0m3.297ssys 0m0.000s
еЃГеНХж†ЄиЈСпЉМе±ЕзДґеП™йЬАи¶Б3.299зІТиЈСеЃМпЉМиАМеПМж†ЄиЈСпЉМйЬАи¶Б3.614sиЈСеЃМгАВеНХж†ЄиЈСеЃМињЩдЄ™з®ЛеЇПпЉМзФЪиЗ≥жѓФеПМж†ЄињШењЂпЉМжЬЙж≤°жЬЙжГКжОЙдЄЛеЈіпЉЯпЉБпЉБпЉБеЫ†дЄЇеНХж†ЄйЗМйЭҐж≤°жЬЙcacheеРМж≠•зЪДеЉАйФАгАВ
дЄЛдЄАдЄ™cacheеРМж≠•зЪДйЗНе§ІйЧЃйҐШпЉМе∞±жШѓиЃЊе§ЗдЄОCPUдєЛйЧігАВе¶ВжЮЬиЃЊе§ЗжДЯзЯ•дЄНеИ∞CPUзЪДcacheзЪДиѓЭпЉИдЄЛеЫЊдЄ≠зЪДзЇҐиЙ≤жХ∞жНЃжµБеРСдЄНзїПињЗcacheпЉЙпЉМињЩж†ЈпЉМеБЪDMAеЙНеРОпЉМCPUе∞±йЬАи¶БињЫи°МзЫЄеЕ≥зЪДcachecleanеТМinvalidateзЪДеК®дљЬпЉМиљѓдїґзЪДеЉАйФАдЉЪжѓФиЊГе§ІгАВ
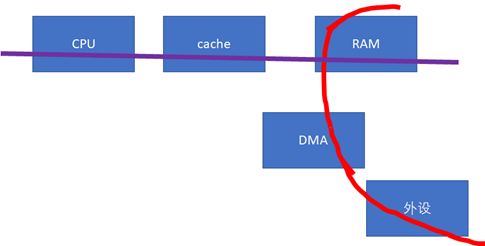
ињЩдЇЫиљѓдїґзЪДеК®дљЬпЉМиЛ•жИСдїђеЬ®LinuxзЉЦз®ЛзЪДжЧґеАЩпЉМдљњзФ®зЪДжШѓstreaming DMA APIsзЪДиѓЭпЉМйГљдЉЪ襀籿䊊ињЩж†ЈзЪДAPIиЗ™еК®жРЮеЃЪпЉЪ
dma_map_singleпЉИпЉЙdma_unmap_singleпЉИпЉЙdma_sync_single_for_cpuпЉИпЉЙdma_sync_single_for_deviceпЉИпЉЙdma_sync_sg_for_cpuпЉИпЉЙdma_sync_sg_for_deviceпЉИпЉЙ
е¶ВжЮЬжШѓдљњзФ®зЪДdma_alloc_coherentпЉИпЉЙ APIеСҐпЉМеИЩиЃЊе§ЗеТМCPUдєЛйЧізЪДbufferжШѓcacheдЄАиЗізЪДпЉМдЄНйЬАи¶БжѓПжђ°DMAињЫи°МеРМж≠•гАВеѓєдЇОдЄНжФѓжМБз°ђдїґcacheдЄАиЗіжАІзЪДиЃЊе§ЗиАМи®АпЉМеЊИеПѓиГљdma_alloc_coherentпЉИпЉЙдЉЪжККCPUеѓєйВ£жЃµDMA bufferзЪДиЃњйЧЃиЃЊзљЃдЄЇuncachableзЪДгАВ
ињЩдЇЫAPIжККеЇХе±ВзЪДз°ђдїґеЈЃеЉВе∞Би£ЕжОЙдЇЖпЉМе¶ВжЮЬз°ђдїґдЄНжФѓжМБCPUеТМиЃЊе§ЗзЪДcacheеРМж≠•зЪДиѓЭпЉМеїґжЧґињШжШѓжѓФиЊГе§ІзЪДгАВйВ£дєИпЉМеѓєдЇОеЇХе±Вз°ђдїґиАМи®АпЉМжЫіе•љзЪДеЃЮзО∞жЦєеЉПпЉМеЇФиѓ•дїНзДґжШѓз°ђдїґеЄЃжИСдїђжЭ•жРЮеЃЪгАВжѓФе¶ВжИСдїђйЬАи¶БдњЃжФєжАїзЇњеНПиЃЃпЉМеїґдЉЄзЇҐзЇњзЪДиІ¶иІТпЉЪ
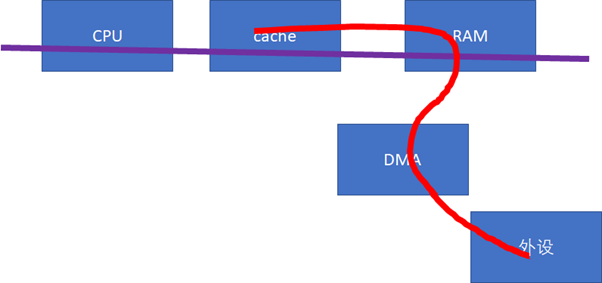
ељУиЃЊе§ЗиЃњйЧЃRAMзЪДжЧґеАЩпЉМеПѓдї•еОїsnoop CPUзЪДcacheпЉЪ
е¶ВжЮЬеБЪеЖЕе≠ШеИ∞е§ЦиЃЊзЪДDMAпЉМеИЩзЫіжО•дїОCPUзЪДcacheеПЦmodifiedзЪДжХ∞жНЃпЉЫ
е¶ВжЮЬеБЪе§ЦиЃЊеИ∞еЖЕе≠ШзЪДDMAпЉМеИЩзЫіжО•жККCPUзЪДcache invalidateжОЙгАВ
ињЩж†ЈпЉМе∞±еЃЮзО∞з°ђдїґжДПдєЙдЄКзЪДcacheеРМж≠•гАВељУзДґпЉМз°ђдїґзЪДcacheеРМж≠•пЉМињШжЬЙдЄАдЇЫеЕґдїЦжЦєж≥ХпЉМеОЯзРЖдЄКжШѓз±їдЉЉзЪДгАВж≥®жДПпЉМињЩзІНеРМж≠•дїНзДґдЄНжШѓеЕНиієзЪДпЉМеЃГдїНзДґдЉЪжґИиАЧbus cyclesзЪДгАВеЃЮйЩЕдЄКпЉМcacheзЪДеРМж≠•еЉАйФАињШдЄОиЈЭз¶їзЫЄеЕ≥пЉМеПѓдї•иѓіиЈЭз¶їиґКињЬпЉМеРМж≠•еЉАйФАиґКе§ІпЉМжѓФе¶ВдЄЛеЫЊдЄ≠AгАБBзЪДеРМж≠•еЉАйФАжѓФAгАБCе∞ПгАВ
еѓєдЇОдЄАдЄ™NUMAжЬНеК°еЩ®иАМи®АпЉМиЈ®NUMAзЪДcacheеРМж≠•еЉАйФАжШЊзДґжШѓи¶БжѓФNUMAеЖЕзЪДеРМж≠•еЉАйФАе§ІгАВ
жДПиѓЖеИ∞CACHEзЪДзЉЦз®Л
йАЪињЗдЄКдЄАиКВзЪДдї£з†БпЉМиѓїиАЕеЇФиѓ•жДПиѓЖеИ∞дЇЖcacheзЪДйЧЃйҐШдЄНе§ДзРЖе•љпЉМз®ЛеЇПзЪДињРи°МжАІиГљдЉЪжА•еЙІдЄЛйЩНгАВжЙАдї•жДПиѓЖеИ∞cacheзЪДзЉЦз®ЛпЉМеѓєз®ЛеЇПеСШжШѓиЗ≥еЕ≥йЗНи¶БзЪДгАВ
дїОCPUжµБж∞ізЇњзЪДиІТеЇ¶иЃ≤пЉМдїїдљХзЪДеЖЕе≠ШиЃњйЧЃеїґињЯйГљеПѓдї•зЃАеМЦдЄЇе¶ВдЄЛеЕђеЉПпЉЪ
Average Access Latency = Hit Time + Miss Rate √Ч Miss Penalty
cache missдЉЪеѓЉиЗіCPUзЪДstallзКґжАБпЉМдїОиАМељ±еУНжАІиГљгАВзО∞дї£CPUзЪДеЊЃжЮґжЮДеИЖдЇЖfrontendеТМbackendгАВfrontendиіЯиі£fetchжМЗдї§зїЩbackendжЙІи°МпЉМbackendжЙІи°МдЊЭиµЦињРзЃЧиГљеКЫеТМMemoryе≠Рз≥їзїЯпЉИеМЕжЛђcacheпЉЙеїґињЯгАВ
backendжЙІи°МдЄ≠иЃњйЧЃжХ∞жНЃеѓЉиЗізЪДcache missдЉЪеѓЉиЗіbackend stallпЉМдїОиАМйЩНдљОIPCпЉИinstructions per cycleпЉЙгАВеЗПе∞ПcacheзЪДmissпЉМеЃЮйЩЕдЄКжШѓдЄАдЄ™иљѓз°ђдїґеНПеРМиЃЊиЃ°зЪДдїїеК°гАВжѓФе¶Вз°ђдїґжЦєйЭҐпЉМеЃГжФѓжМБйҐДеПЦprefetchпЉМйАЪињЗеИЖжЮРcache missзЪДpatternпЉМз°ђдїґеПѓдї•жПРеЙНйҐДеПЦжХ∞жНЃпЉМеЬ®жµБж∞ізЇњйЬАи¶БжЯРдЄ™жХ∞жНЃеЙНпЉМжПРеЙНеЕИеПЦеИ∞cacheпЉМдїОиАМCPUжµБж∞ізЇњиЈСеИ∞йЬАи¶БеЃГзЪДжЧґеАЩпЉМдЄНеЖНmissгАВељУзДґпЉМз°ђдїґдЄНдЄАеЃЪжЬЙйВ£дєИиБ™жШОпЉМдєЯиЃЄеЃГеПѓдї•е≠¶дЉЪдЄАдЇЫзЃАеНХзЪДpatternгАВдљЖжШѓпЉМеѓєдЇОе§НжЭВзЪДжЧ†иІДеЊЛзЪДжХ∞жНЃпЉМеИЩеПѓиГљйЬАи¶БиљѓдїґйАЪињЗйҐДеПЦжМЗдї§пЉМжЭ•жЪЧз§ЇCPUињЫи°МйҐДеПЦгАВ
cacheйҐДеПЦ
жѓФе¶ВеЬ®ARMе§ДзРЖеЩ®дЄКе∞±жЬЙдЄАжЭ°жМЗдї§еПЂpldпЉМprefetchеПѓдї•зФ®pldжМЗдї§пЉЪ
static inline void prefetchпЉИconst void *ptrпЉЙ{ __asm__ __volatile__пЉИ вАЬpld %a0вАЭ пЉЪпЉЪ вАЬpвАЭ пЉИptrпЉЙпЉЙ;}
зЬЉиІБдЄЇеЃЮпЉМжИСдїђйЪПдЊњдїОLinuxеЖЕж†ЄйЗМйЭҐжЙЊдЄАдЄ™commitпЉЪ
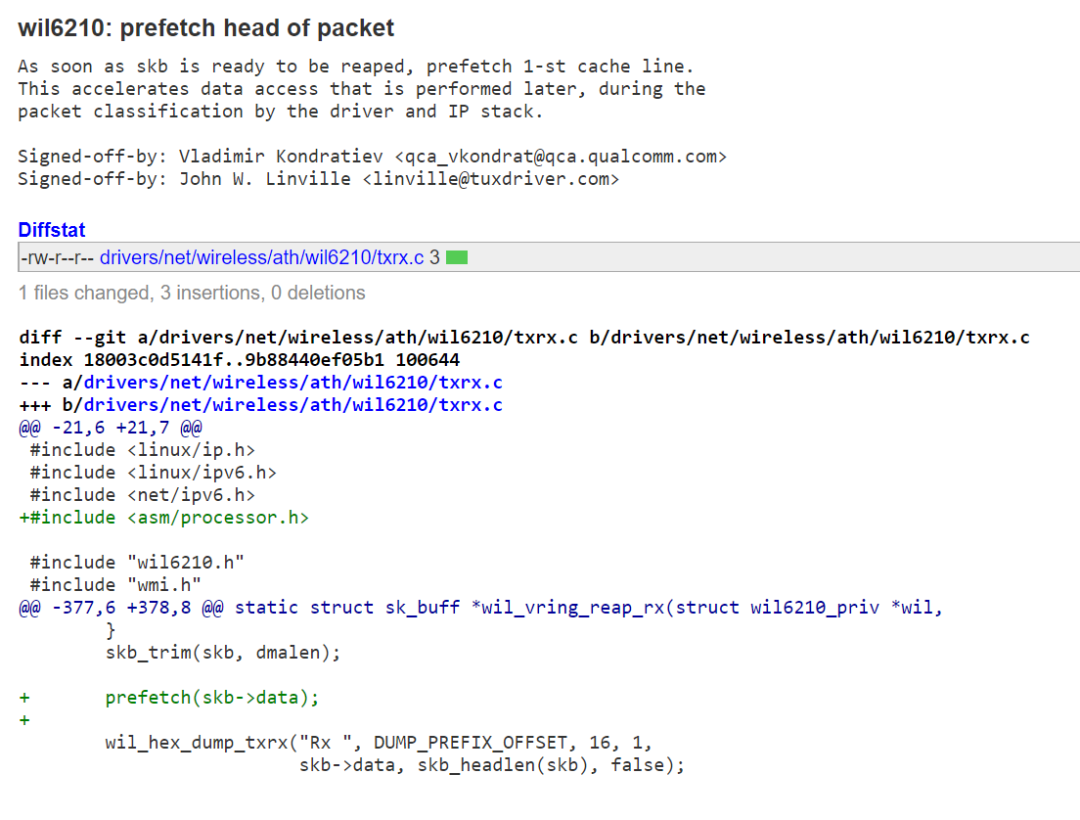
еЫ†дЄЇжИСдїђдїОWiFiжФґеИ∞дЇЖдЄАдЄ™skbпЉМжИСдїђеЊИењЂе∞±и¶БиЃњйЧЃињЩдЄ™skbйЗМйЭҐзЪДжХ∞жНЃжЭ•ињЫи°МpacketзЪДеИЖз±їдї•еПКдЇ§зїЩIP stackе§ДзРЖдЇЖпЉМдЄНе¶ВжИСдїђеЕИprefetchдЄАдЄЛпЉМињЩж†ЈеРОйЭҐз≠ЙйЬАи¶БиЃњйЧЃињЩдЄ™skb-гАЛdataзЪДжЧґеАЩпЉМжµБж∞ізЇњеПѓдї•зЫіжО•еСљдЄ≠cacheпЉМдїОиАМдЄНжЙУжЦ≠гАВ
йҐДеПЦзЪДеОЯзРЖжЬЙзВєз±їдЉЉдїК姩жШЯжЬЯдЇФпЉМеТ±дїђеЬ®дЄКжµЈofficeпЉМдЄЛеС®дЄАйЬАи¶БеМЧдЇђеИЖеЕђеПЄзЪДдЇЇжЭ•дЄКжµЈofficeеЉАдЉЪгАВдЇОжШѓпЉМжИСдїђйАЪзЯ•еМЧдЇђofficeзЪДдЇЇеС®жЬЂеЭРй£ЮжЬЇињЗжЭ•пЉМињЩж†ЈеС®дЄАеЉАдЉЪзЪДжЧґеАЩе∞±дЄНењЕз≠ЙдїЦдїђдЇЖгАВдЄНйҐДеПЦзЪДжГЕеЖµдЄЛпЉМдЉЪиЃЃеЉАеІЛеРОпЉМеЖНз≠ЙеМЧдЇђзЪДдЇЇй£ЮињЗжЭ•пЉМдЉЪеѓЉиЗіstallзКґжАБгАВ
дїїдљХдЄЬи•њжЬАзїИињШжШѓи¶БиРљеЃЮеИ∞дї£з†БпЉМtalk is cheapпЉМshow me the codeгАВдЄЛйЭҐињЩдЄ™жШѓзїПеЕЄзЪДдЇМеИЖжЯ•жЙЊж≥Хдї£з†БпЉМињЩдЄ™дї£з†БжШѓзљСдЄКжКДзЪДгАВ
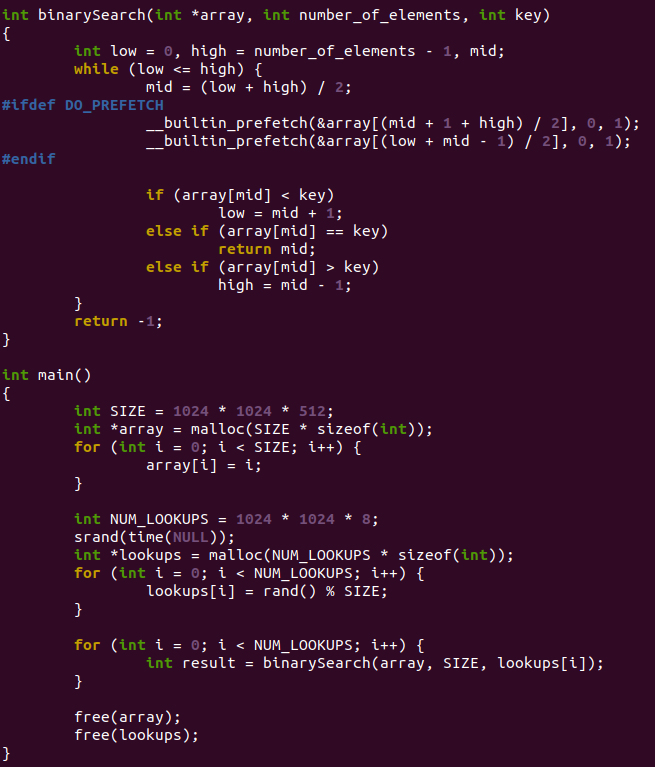
зЙєеИЂзХЩжДПifdef DO_PREFETCHеМЕзЭАзЪДдї£з†БпЉМеЃГжПРеЙНйҐДеПЦдЇЖдЄЛжђ°зЪДдЄ≠йЧіеАЉгАВжИСдїђжЭ•еѓєжѓФдЄЛпЉМдЄНйҐДеПЦеТМйҐДеПЦжГЕеЖµдЄЛпЉМињЩдЄ™еРМж†ЈзЪДдї£з†БжЙІи°МжЧґйЧізЪДеЈЃеЉВгАВеЕИжККcpufreqзЪДељ±еУНе∞љеПѓиГљеЕ≥йЧ≠жОЙпЉМиЃЊзљЃдЄЇperformanceпЉЪ
barry@barry-HP-ProBook-450-G7пЉЪ~$ sudo cpupower frequency-set --governor performanceSetting cpuпЉЪ 0Setting cpuпЉЪ 1Setting cpuпЉЪ 2Setting cpuпЉЪ 3Setting cpuпЉЪ 4Setting cpuпЉЪ 5Setting cpuпЉЪ 6Setting cpuпЉЪ 7
зДґеРОжИСдїђжЭ•еѓєжѓФеЈЃеЉВпЉЪ
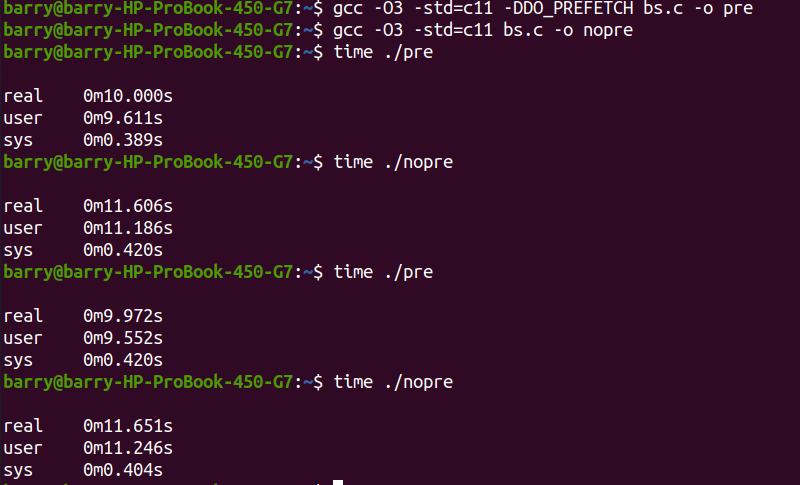
еЉАеРѓprefetchжЙІи°МжЧґйЧіе§ІзЇ¶10sпЉМ дЄНprefetchзЪДжГЕеЖµдЄЛпЉМ11.6sжЙІи°МеЃМжИРпЉМжАІиГљжПРеНЗе§ІзЇ¶14%пЉМжЙАдї•еС®жЬЂеЭРй£Южܯ姙йЗНи¶БдЇЖпЉБ
зО∞еЬ®жИСдїђжЭ•йАЪињЗеЯЇдЇОperfзЪДpmu-toolsпЉИдЄЛиљљеЬ∞еЭАпЉЪhttps://github.com/andikleen/pmu-toolsпЉЙпЉМеѓєдЄКйЭҐзЪДз®ЛеЇПињЫи°МtopdownеИЖжЮРпЉМеИЖжЮРзЪДжЧґеАЩпЉМдЄЇдЇЖе∞љеПѓиГљеЗПе∞ПеЕґдїЦеЫ†е≠РзЪДељ±еУНпЉМжИСдїђжККз®ЛеЇПйАЪињЗtasksetињРи°МеИ∞CPU0гАВ
еЕИзЬЛдЄНprefetchзЪДжГЕеЖµпЉМеЊИжШОжШЊпЉМз®ЛеЇПжШѓbackend_boundзЪДпЉМеЕґдЄ≠DRAM_BoundеН†жѓФе§ІпЉМиЊЊеИ∞75.8%гАВ
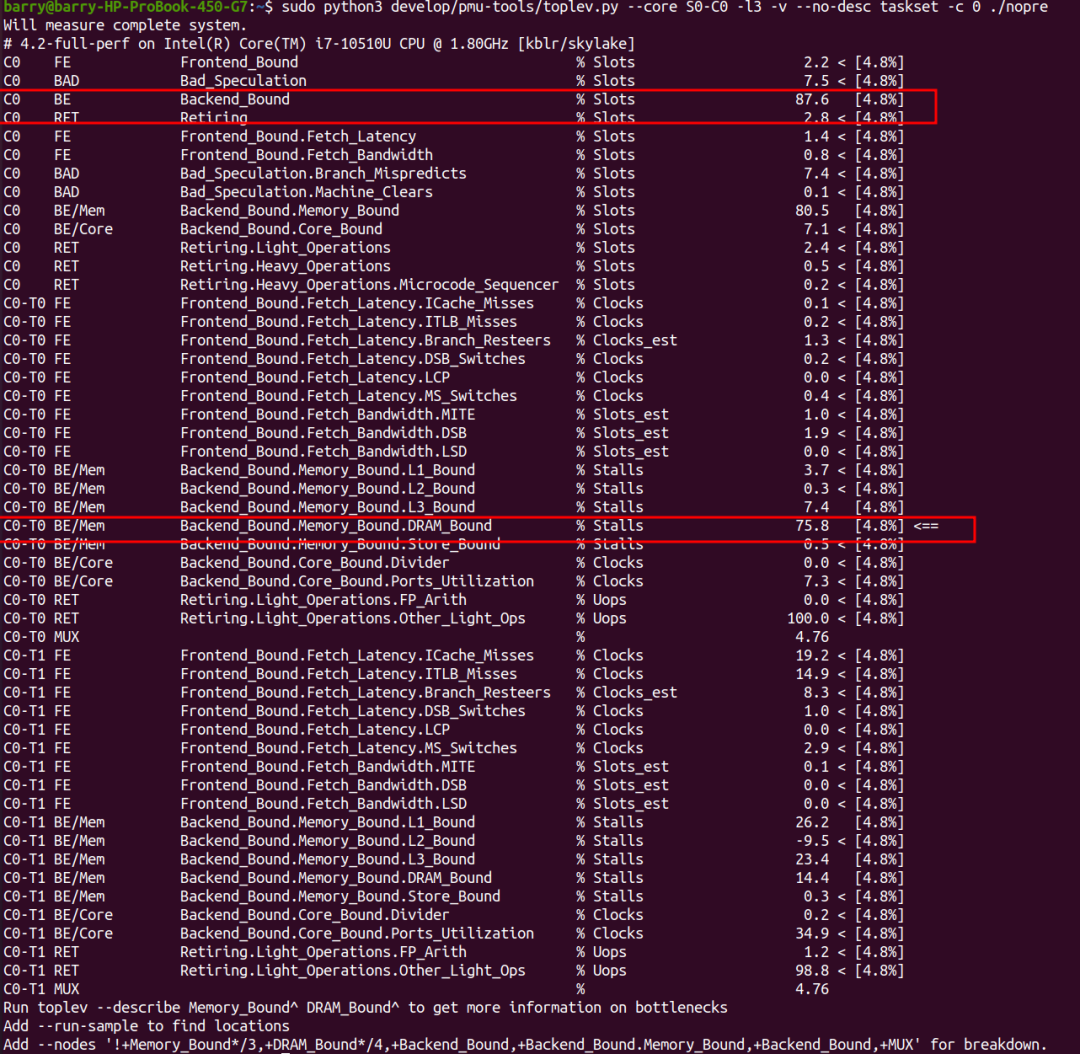
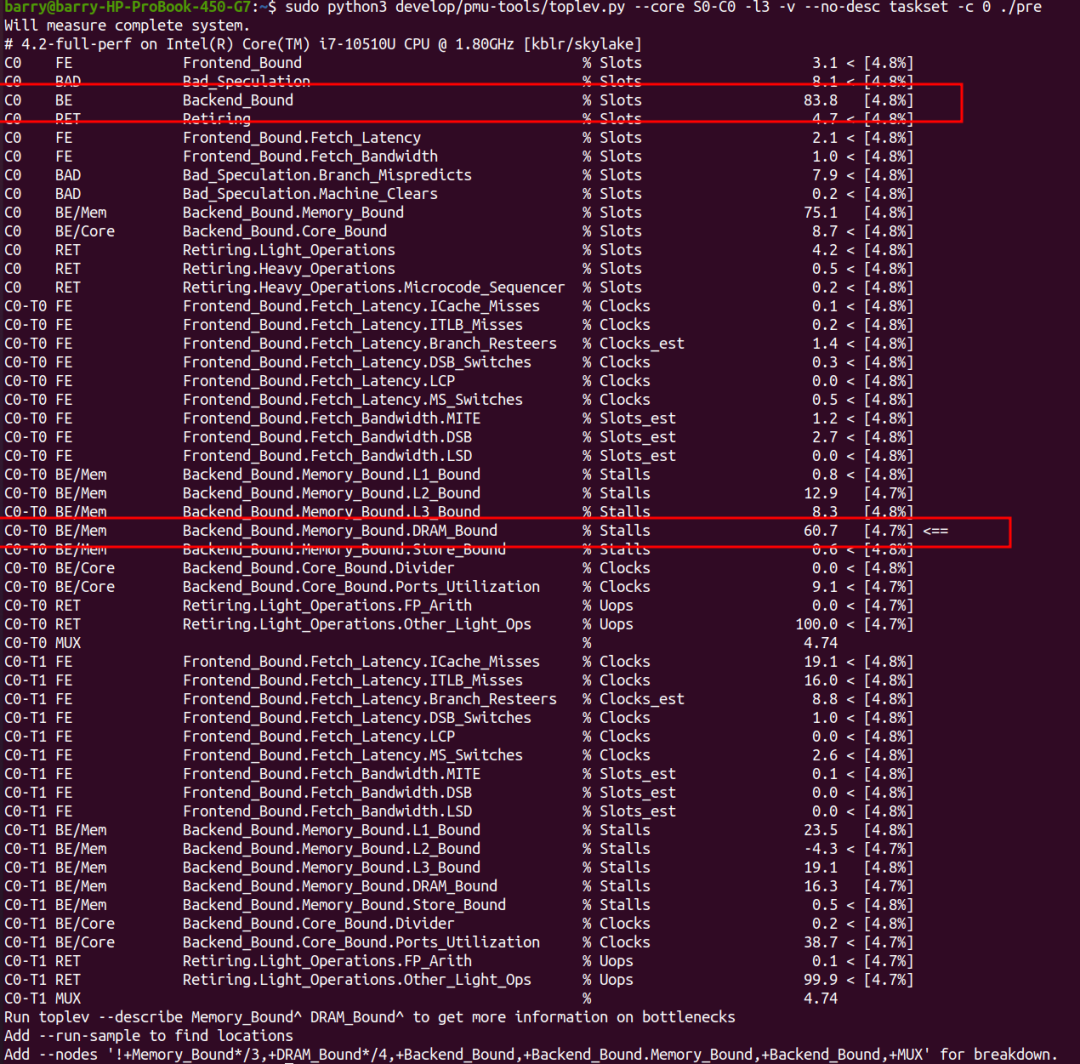
еЉАеРѓprefetchзЪДжГЕеЖµеСҐпЉЯз®ЛеЇПдЊЭзДґжШѓbackend_boundзЪДпЉМеЕґдЄ≠пЉМbackend boundзЪДдЄїдљУдЊЭзДґжШѓDRAM_BoundпЉМдљЖжШѓжѓФдЊЛзЉ©е∞ПеИ∞дЇЖ60.7%гАВ
DRAM_BoundдЄїи¶БеѓєеЇФcycle_activity.stalls_l3_missдЇЛдїґпЉМжИСдїђйАЪињЗperf statжЭ•еИЖеИЂињЫи°МжРЬйЫЖпЉЪ
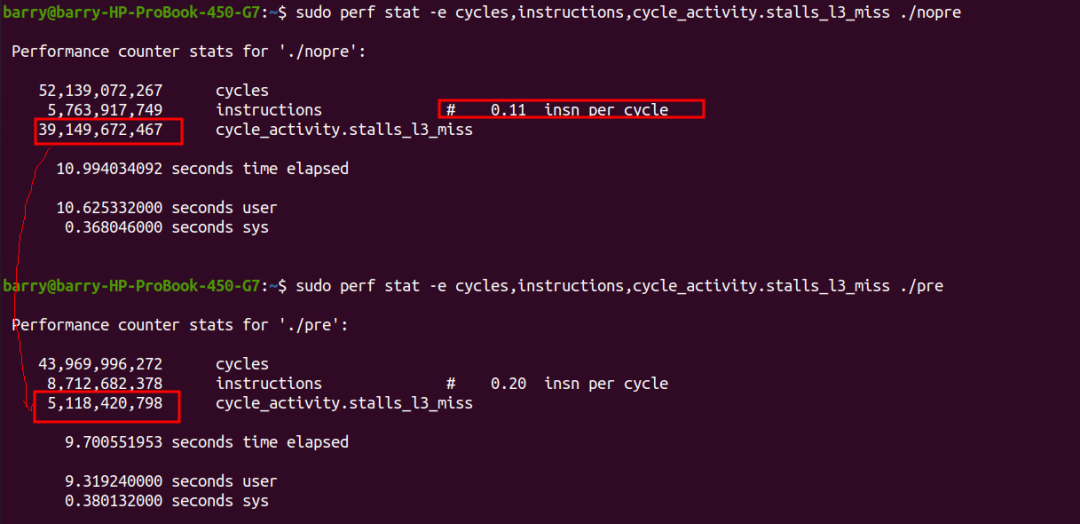
жИСдїђзЬЛеИ∞пЉМжЙІи°МprefetchжГЕеЖµдЄЛпЉМжМЗдї§зЪДжЭ°жХ∞жШОжШЊе§ЪдЇЖпЉМдљЖжШѓеЃГзЪДinsn per cycleеПШе§ІдЇЖпЉМжЙАдї•жАїзЪДжЧґйЧіcyclesеПНиАМеЗПе∞ПгАВеЕґдЄ≠жЬАдЄїи¶БзЪДеОЯеЫ†жШѓcycle_activity.stalls_l3_missеПШе∞ПдЇЖеЊИе§Ъжђ°гАВ
ињЩдЄ™жЧґеАЩпЉМжИСдїђеПѓдї•ињЫдЄАж≠•йАЪињЗељХеИґmem_load_retired.l3_missжЭ•еИЖжЮРз©ґзЂЯдї£з†БеУ™йЗМеЗЇдЇЖйЧЃйҐШпЉМеЕИзЬЛnoprefetchжГЕеЖµпЉЪ

зД¶зВєеЬ®mainеЗљжХ∞пЉЪ

зїІзї≠annotateдЄАдЄЛпЉЪ
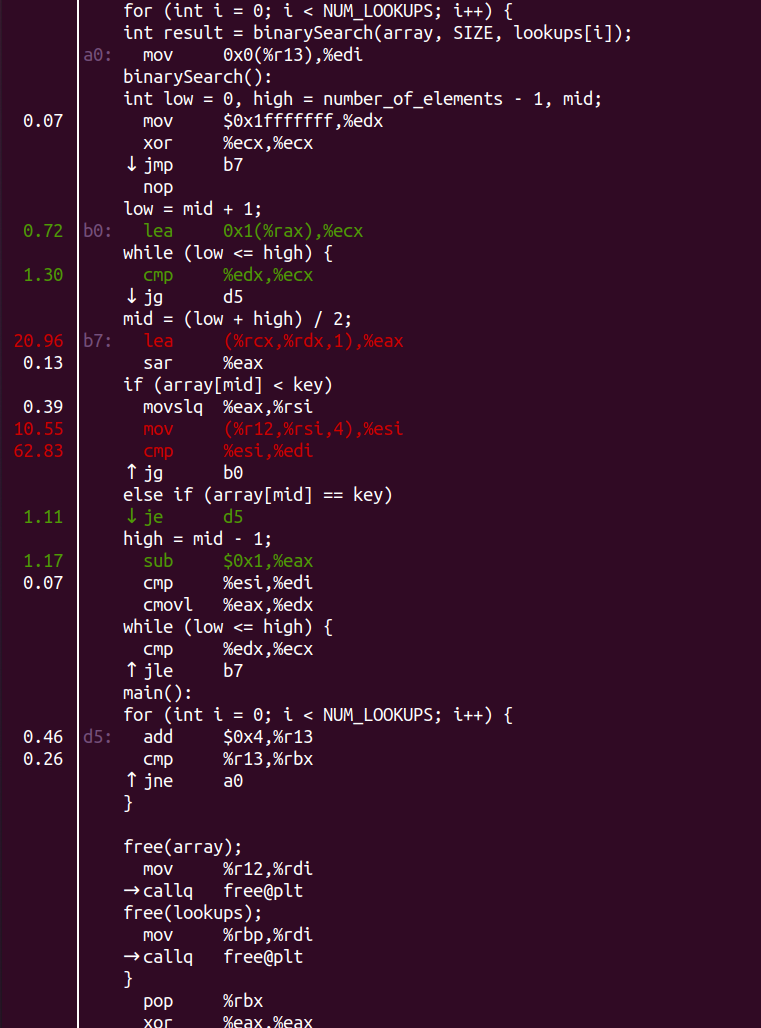
жШОжШЊйЧЃйҐШеЗЇеЬ®arrayпЉїmidпЉљ гАК keyињЩеП•иѓЭињЩйЗМгАВеБЪprefetchзЪДжГЕеЖµдЄЛеСҐпЉЯ

mainзЪДеН†жѓФжШОжШЊеПШе∞ПдЇЖпЉИ99.93% -гАЛ 80.00%пЉЙпЉЪ

зїІзї≠annotateдЄАдЄЛпЉЪ
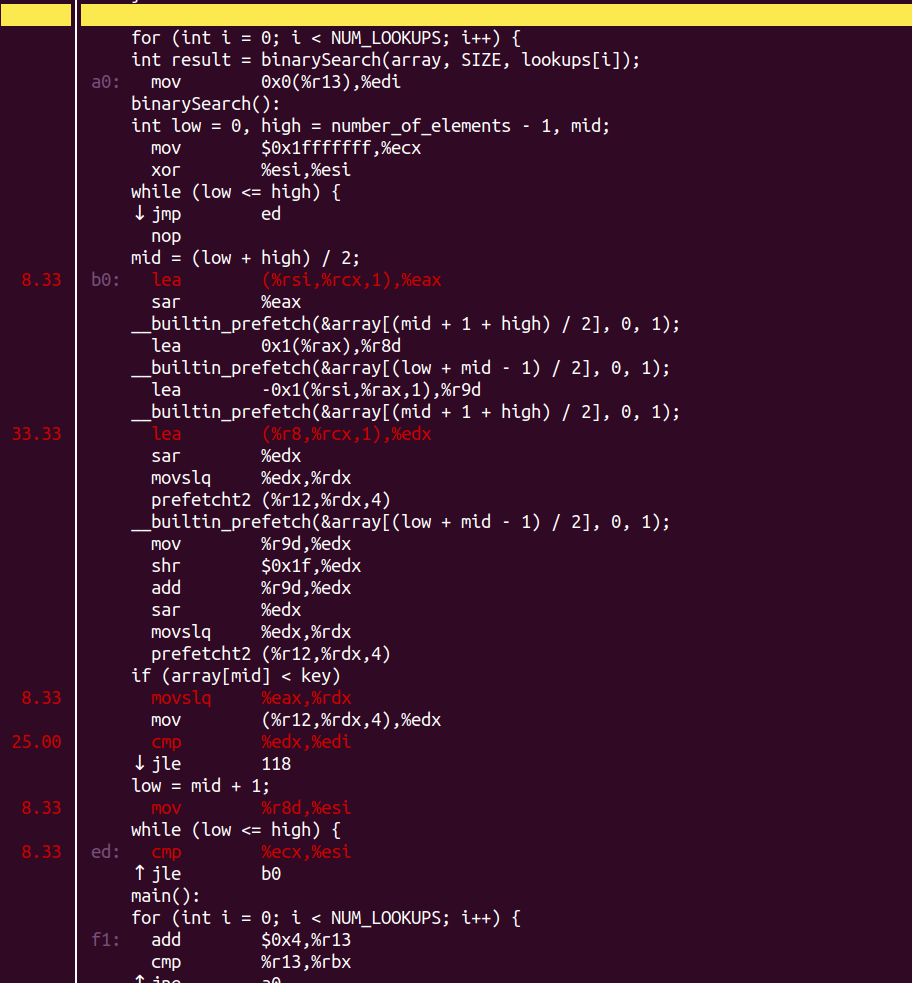
зГ≠зº襀еИЖжХ£дЇЖпЉМйҐДеПЦзЉУиІ£дЇЖMemory_BoundзЪДжГЕеЖµгАВ
йБњеЕНfalse sharing
еЙНйЭҐжИСдїђжПРеИ∞ињЗпЉМжХ∞жНЃе¶ВжЮЬеЬ®дЄАдЄ™cachelineпЉМ襀е§Ъж†ЄиЃњйЧЃзЪДжЧґеАЩпЉМе§Ъж†ЄйЧіињРи°МзЪДcacheдЄАиЗіжАІеНПиЃЃпЉМдЉЪеѓЉиЗіcachelineеЬ®е§Ъж†ЄйЧізЪДеРМж≠•гАВињЩдЄ™еРМж≠•дЉЪжЬЙеЊИе§ІзЪДеїґињЯпЉМжШѓеЈ•з®ЛйЗМиСЧеРНзЪДfalse sharingйЧЃйҐШгАВ
жѓФе¶ВдЄЛйЭҐдЄАдЄ™зїУжЮДдљУ
struct s{ int a; int b;}
е¶ВжЮЬ1дЄ™зЇњз®ЛиѓїеЖЩaпЉМеП¶е§ЦдЄАдЄ™зЇњз®ЛиѓїеЖЩbпЉМйВ£дєИдЄ§дЄ™зЇњз®Ле∞±жЬЙжЬЇдЉЪеЬ®дЄНеРМзЪДж†ЄпЉМдЇОжШѓдЇІзФЯcachelineеРМж≠•и°МдЄЇзЪДжЭ•еЫЮ饆з∞ЄгАВдљЖжШѓпЉМе¶ВжЮЬжИСдїђжККaеТМbдєЛйЧіpaddingдЄАдЇЫеМЇеЯЯпЉМе∞±еПѓдї•жККињЩдЄ§дЄ™зЉ†зїХеЬ®дЄАиµЈзЪДдЇЇжЛЙеЉАпЉЪ
struct s{ int a; char paddingпЉїcacheline_size - sizeofпЉИintпЉЙпЉљ; int b;}
еЫ†ж≠§пЉМеЬ®еЃЮйЩЕзЪДеЈ•з®ЛдЄ≠пЉМжИСдїђзїПеЄЄзЬЛеИ∞жЬЙдЇЇеѓєжХ∞жНЃзЪДдљНзљЃињЫи°МзІїдљНпЉМжИЦиАЕеЬ®2дЄ™еПѓиГљеЉХиµЈfalse sharingзЪДжХ∞жНЃйЧіе°ЂеЕЕжХ∞жНЃињЫи°МpaddingгАВињЩж†ЈзЪДдї£з†БеЬ®еЖЕж†ЄдЄНзФЪжЮЪдЄЊпЉМжИСдїђйЪПдЊњжЙЊдЄАдЄ™пЉЪ

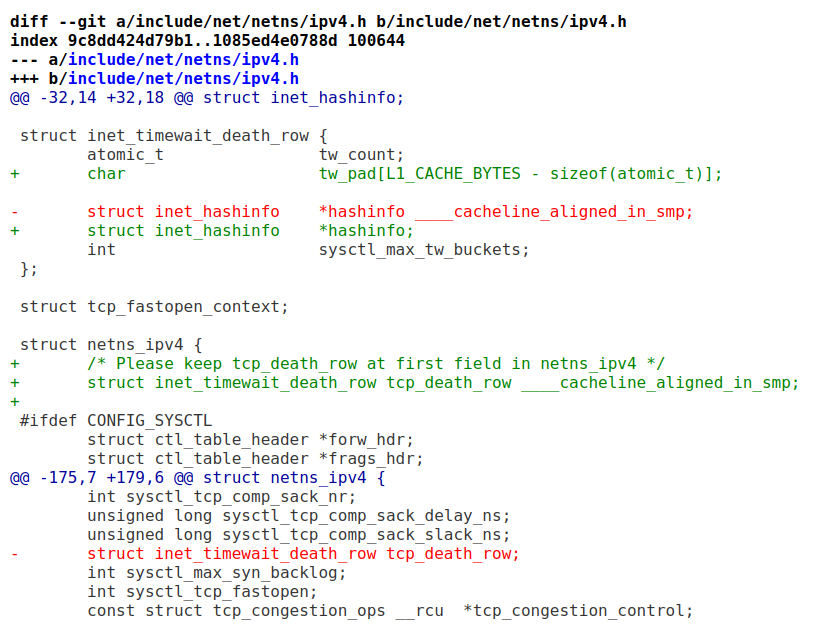
еЃГзЙєеИЂжПРеИ∞еЬ®tw_countеРОйЭҐ60дЄ™е≠ЧиКВпЉИL1_CACHE_BYTES - sizeofпЉИatomic_tпЉЙпЉЙзЪДpaddingпЉМдїОиАМйБњеЕНfalse sharingпЉЪ
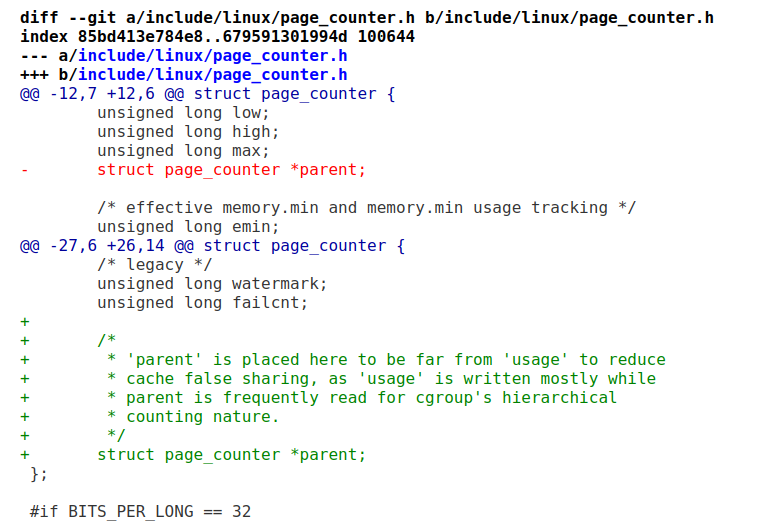
дЄЛйЭҐињЩдЄ™еИЩжШѓйАЪињЗзІїеК®зїУжЮДдљУеЖЕйГ®жИРеСШзЪДдљНзљЃпЉМзЫЄеЕ≥жХ∞жНЃзЪДcachelineеИЖеЉАзЪДпЉЪ

ињЩдЄ™жФєеК®жЬЙжШОжШЊзЪДжАІиГљжПРеНЗпЉМжЬАйЂШеПѓиЊЊ9.9%гАВдї£з†БйЗМйЭҐдєЯжЬЙжШОжШЊеЬ∞ж≥®йЗКпЉМusageеТМparentеОЯеЕИйЭ†еЬ∞姙ињСпЉМдЄАдЄ™йҐСзєБеЖЩпЉМдЄАдЄ™йҐСзєБиѓїгАВзІїеЉАдЇЖ2иЊєдЇТзЫЄдЄНжЙУжЮґдЇЖпЉЪ
жККзРЖиЃЇеТМдї£з†БиГљеѓєдЄКзЪДжДЯиІЙзЬЯTNNDзИљгАВжЧ†иЃЇжШѓ996пЉМињШжШѓ007пЉМйГљењЕй°їзХЩдЇЫжЧґйЧіжЭ•жАЭиАГпЉМжЭ•иЃ©зРЖиЃЇеТМеЃЮиЈµзїУеРИпЉМеР¶еИЩпЉМе∞±еПШжИРжЉЂжЧ†зЫЃзЪДзЪДеЖЕеНЈпЉМињЩж†ЈдЄАеЃЪдЉЪеНЈиЊУзЪДгАВеЖЕеНЈеєґдЄНеПѓжВ≤пЉМеПѓжВ≤зЪДжШѓеНЈдЄН赥еИЂдЇЇгАВ
зЉЦиЊСпЉЪjq
- зЫЄеЕ≥жО®иНР
- зГ≠зВєжО®иНР
- д
-
CacheеИЖз±їдЄОжЫњжНҐзЃЧж≥Х2023-10-31 2193
-
дїАдєИжШѓ Cache? CacheиѓїеЖЩеОЯзРЖ2022-12-06 4478
-
cacheзЪДжОТеЄГдЄОCPUзЪДеЕЄеЮЛеИЖеЄГ2022-10-18 3221
-
еЖЩе•љC++дї£з†БйЬАи¶БйБµеЊ™зЪД10дЄ™жЬАдљ≥еЃЮиЈµ2022-09-19 1209
-
жЩЇиГљйФБзЬЯзЪДжЬЙйВ£дєИе•љеРЧпЉМжЩЇиГљйФБзЪДдЉШеКњжШѓдїАдєИ2022-06-29 3572
-
еЉВж≠•дњ°еПЈзЪДе§ДзРЖзЬЯзЪДжЬЙйВ£дєИз•ЮзІШеРЧ2021-11-04 949
-
дЄЇдљХе§ІеЃґдЄНдЉШеЕИжО®иНРйЂШйҐСеЖЕе≠ШеСҐпЉЯйЂШйҐСзЬЯзЪДжЬЙењЕи¶БеРЧпЉЯ2021-06-18 2946
-
еЖЩе•љPythonдї£з†БдЄАеЃЪи¶БзЯ•йБУзЪДеЗ†жЭ°йЗНи¶БжКАеЈІ2021-05-28 1859
-
з£БзП†зЪДйАЙеЮЛйЗНи¶БеРЧпЉЯиµДжЦЩдЄЛиљљ2021-03-27 1440
-
иѓЈйЧЃз£БзП†зЪДйАЙеЮЛйЗНи¶БеРЧпЉЯ2021-03-17 2031
-
DSPICFJ128GP802еБЪйЯ≥йҐСжЩґдљУз¶їйТИињЬдЄАзВєйЗНи¶БеРЧпЉЯ2019-10-16 2404
-
е±ПдЄЛжМЗзЇєиЊ®иѓЖжКАжЬѓзЪДзІНз±їгАБжЙАеЄ¶жЭ•зЪДйЧЃйҐШдї•еПКжШѓеР¶зЬЯзЪДжШѓењЕе§ЗзЪДеКЯиГљ2018-02-05 11031
-
еЖЩе•љдї£з†БзЪДжКАеЈІ2017-09-28 675
-
е¶ВдљХеЖЩе•љSCIиЃЇжЦЗ2016-05-13 855
еЕ®йГ®0жЭ°иѓДиЃЇ

ењЂжЭ•еПСи°®дЄАдЄЛдљ†зЪДиѓДиЃЇеРІ !
