

C语言排序中快速排序的技巧
描述
快速排序是由东尼·霍尔所发展的一种排序算法。在平均状况下,排序 n 个项目要Ο(n log n)次比较。在最坏状况下则需要Ο(n2)次比较,但这种状况并不常见。事实上,快速排序通常明显比其他Ο(n log n) 算法更快,因为它的内部循环(inner loop)可以在大部分的架构上很有效率地被实现出来。
算法步骤:
1 从数列中挑出一个元素,称为 “基准”(pivot)。
2 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
3 递归(recursive)的把小于基准值元素的子数列和大于基准值元素的子数列排序。
递归的最底部情形,是数列的大小是零或一,也就是永远都已经被排序好了。虽然一直递归下去,但是这个算法总会退出,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。
C代码的实现如下:

下面开始单步分析,这里用一个数组的数据来分析

首先将0作为比较的基准,由于右边所有的数据都比0大,所以数据不做 移动。接下来将8作为比较基准,从最右边开始和8比较。此时6比8小,将6移动到8前面,其他数据依次后移。

接着在将2和8比较,2比8小,继续将2移动到8前面,其他的数据依次后移。

这样将8小的数据移动到8的前面,比8大的数据在8后面保持不变。移动完成后如下:

接下来比较的基准变为数字6,将比6小的数据移动到6前面。从最右边开始查找,找到1比6小,将1移动到6前面。

然后继续依次寻找比6小的数字,移动到6的前面,移动完成后如下:

然后比较的基准变为数字5,从最右边开始寻找比5小的数移动到5前面。查找到的数据为2。

依次查找其他比5小的数据,移动完成后如下:
到这里可以看到数据排序已经完成了。整体运行流程如下:
下面测试一下最坏情况下的排序情况
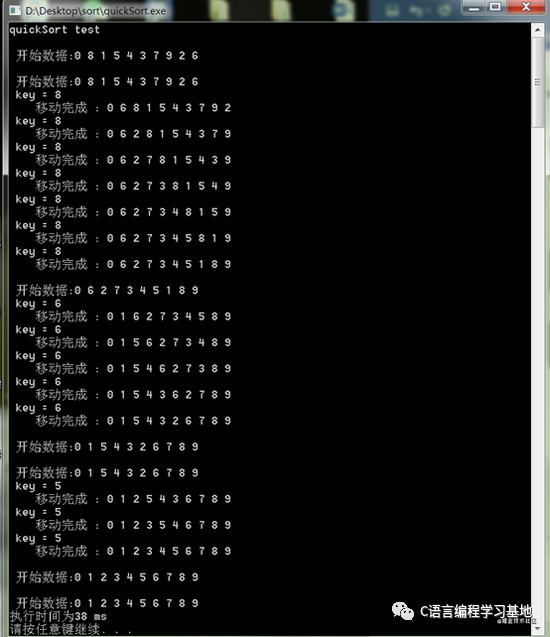
可以看到最坏情况下排序的次数并没有增多,反而感觉还减少了。在看一下最好情况下的排序情况:
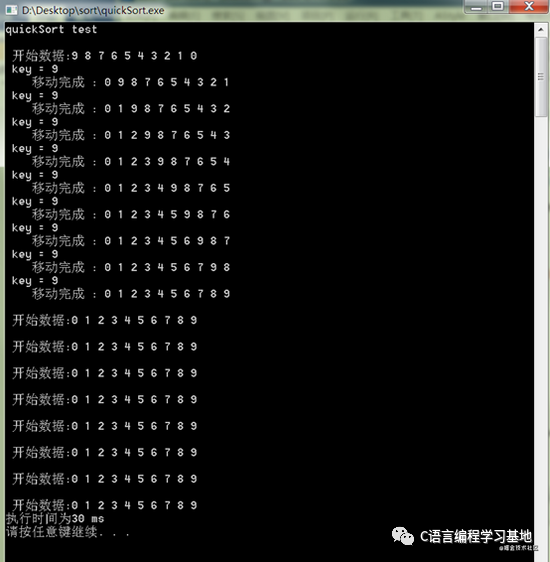
最好情况下数据也要进行比较9次。
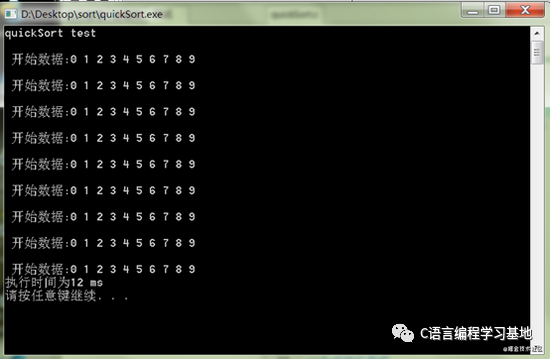
下来随机生成一个包含10000个数字的数组,测试下执行时间。
可以看到对10000个数字排序需要的时间为120ms。

另外,对现在我们的大多数朋友来说还是学编程技术最重要!栽一棵树最好的时间是十年前,其次是现在。对于准备学习编程的小伙伴,如果你想更好的提升你的编程核心能力(内功)不妨从现在开始!
编辑:jq
- 相关推荐
- 热点推荐
- C语言
-
希尔排序的基本思想2022-08-08 1891
-
C语言冒泡排序工程代码汇总2021-08-30 1021
-
几种c语言程序的排序包括应用程序等资料免费下载2018-09-29 1073
-
C语言实现简单的基数排序2018-02-05 1984
-
基于C语言二分查找排序源代码2018-01-04 712
-
C语言教程之几种排序算法2017-11-16 2091
-
C++语言实现火车排序功能2017-01-05 762
-
C语言教程之对数组进行升序和降序排序2016-04-25 904
-
C语言教程之归并排序2016-04-22 445
-
基于C语言的几种排序算法的分析2013-09-18 850
-
C语言冒泡、插入法、选择排序算法分析2013-09-06 662
全部0条评论

快来发表一下你的评论吧 !
