

简述Python中深浅拷贝(copy)
描述
在工作中,常涉及到数据的传递,在数据传递使用过程中,可能会发生数据被修改的问题。为了防止数据被修改,就需要在传递一个副本,即使副本被修改,也不会影响原数据的使用。为了生成这个副本,就产生了拷贝。今天就说一下Python中的深浅拷贝问题。
一、深浅copy
赋值运算
l1 = [1, 2, 3, [22, 33]]l2 = l1l1.append(666)print(l1) # [1, 2, 3, [22, 33], 666]print(l2) # [1, 2, 3, [22, 33], 666]
图解:
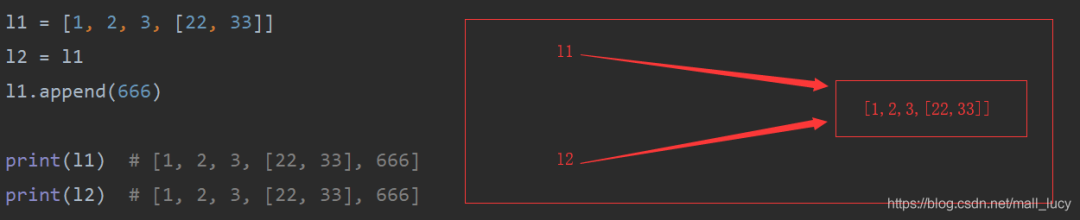
注意:l2 = l1是一个指向,是赋值,和深浅copy无关。
浅copy
其实列表是一个一个的槽位,每个槽位存储的是该对象的内存地址
#例1. 给大列表添加元素l1 = [1, 2, 3, [22, 33]]l2 = l1.copy()# 或者下面这种方式,也是浅copy# import copy# l2 = copy.copy(l1)l1.append(666)
print(l1) # [1, 2, 3, [22, 33], 666]print(l2) # [1, 2, 3, [22, 33]]
#例2. 给小列表添加元素l1 = [1, 2, 3, [22, 33]]l2 = l1.copy()l1[-1].append(666)
print(l1) # [1, 2, 3, [22, 33, 666]]print(l2) # [1, 2, 3, [22, 33, 666]]、
例3. 将l1列表中第一个元素改为6l1 = [1, 2, 3, [22, 33]]l2 = l1.copy()l1[0] = 6
print(l1) # [6, 2, 3, [22, 33]]print(l2) # [1, 2, 3, [22, 33]]
小结:
浅copy:会在内存中新开辟一个空间,存放这个copy的列表,但是列表里面的内容还是沿用之前对象的内存地址。
深copy
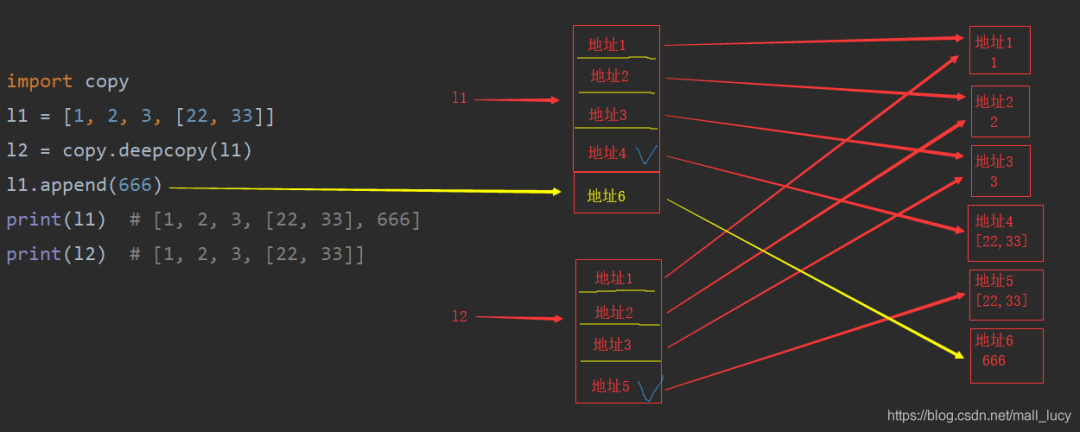
import copyl1 = [1, 2, 3, [22, 33]]l2 = copy.deepcopy(l1)l1.append(666)print(l1) # [1, 2, 3, [22, 33], 666]print(l2) # [1, 2, 3, [22, 33]]
但是python对深copy做了一个优化,将可变的数据类型在内存中重新创建一份,而不可变的数据类型则沿用之前的,所以内存中是下面这样的:
小结:
深copy:会在内存中开辟新空间,将原列表以及列表里面的可变数据类型重新创建一份,不可变数据类型则沿用之前的。
为什么Python默认的拷贝方式是浅拷贝?
时间角度:浅拷贝花费时间更少。
空间角度:浅拷贝花费内存更少。
效率角度:浅拷贝只拷贝顶层数据,一般情况下比深拷贝效率高。
总结:
不可变对象在赋值时会开辟新空间。
可变对象在赋值时,修改一个的值,另一个也会发生改变。
深、浅拷贝对不可变对象拷贝时,不开辟新空间,相当于赋值操作。
浅拷贝在拷贝时,只拷贝第一层中的引用,如果元素是可变对象,并且被修改,那么拷贝的对象也会发生变化。
深拷贝在拷贝时,会逐层进行拷贝,直到所有的引用都是不可变对象为止。
Python 有多种方式实现浅拷贝,copy模块的copy 函数 ,对象的 copy 函数 ,工厂方法,切片等。
大多数情况下,编写程序时,都是使用浅拷贝,除非有特定的需求。
浅拷贝的优点:拷贝速度快,占用空间少,拷贝效率高。
原文链接:https://blog.csdn.net/mall_lucy/article/details/104531218
文章转载:CSDN
(版权归原作者所有,侵删)
编辑:jq
- 相关推荐
- 热点推荐
- python
-
飞凌嵌入式ElfBoard ELF 1板卡-内核空间与用户空间的数据拷贝之数据拷贝介绍2025-03-19 1975
-
[分享]硬盘拷贝机部分故障排除方法2010-01-22 5934
-
system verilog 中copy函数的疑问2015-03-05 3257
-
Python面试必看的10个问题2018-02-28 4285
-
linux的copy命令操作2019-07-26 3115
-
python深浅拷贝是什么?2020-11-04 1309
-
c中几个copy函数的使用细节2017-11-29 4604
-
93C46串行E2ROOM拷贝器,93C46 Copy device2018-09-20 2564
-
Python如何防止数据被修改Python中的深拷贝与浅拷贝的问题说明2019-03-30 3861
-
实例介绍Python中深浅拷贝2020-12-16 1812
-
C++之拷贝构造函数的浅copy及深copy2020-12-24 1527
-
深度解读Linux的3种“拷贝”命令2021-05-28 4200
-
SystemVerilog中的Deep Copy概念2022-11-22 859
-
C++面向对象编程中的深拷贝和浅拷贝2023-03-30 1574
-
Python中浅拷贝与深拷贝的操作2023-11-02 1047
全部0条评论

快来发表一下你的评论吧 !
