

如何用FPGA并行高速运算实现实时的引导滤波算法
电子说
描述
前面一篇文章中,已经详细的分析了引导滤波的理论,公式的推导,以及和双边滤波的对比分析,即在边缘的处理上双边滤波会引起人为的黑/白边。我们已经知道何博士引导滤波的优秀之处,那么本篇文章,我带你推演,如何用FPGA并行高速运算,最小的代码实现实时的引导滤波算法。
首先,给出上篇中最后的matlab 引导滤波的代码,如下所示。
其中框框中为主要的计算过程,下一图为计算a/b的最后的公式(引导图=本身)。
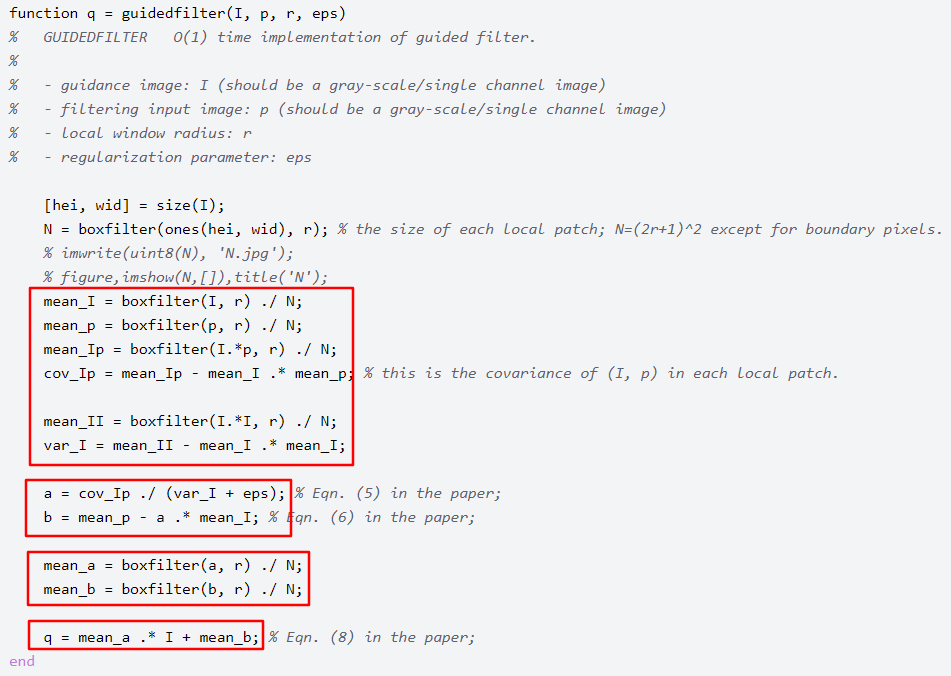
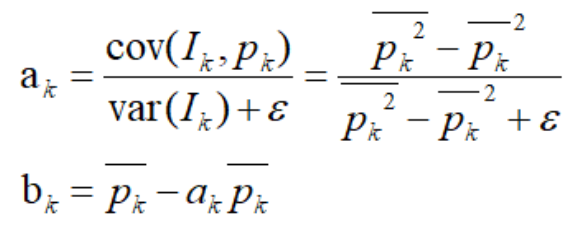
双边滤波由于其只是在空间距离及像素相似度上进行权重计算,加权滤波,相对算法不是特别复杂,FPGA也易于实现(某司的USB工业相机2D滤波就是双边滤波),但是确实效果上不如引导滤波,那么引导滤波FPGA计算真有那么难吗?为此我翻阅了一些资料,也从头到尾推到计算了一遍,略有所成,出来和大家分享下。
在Matlab/C的加速中,引导滤波采用了盒式滤波的方式去加速,将运算复杂度从O(MN)的降低到了O(4),其方法就是先计算当前像素到原点像素组成的矩形区域的和/平方和等,对于线程的Matlab/C而言确实有很大的加速作用,相关的文章可以参考如下,对于软件加速而言还是很不错:
https://www.cnblogs.com/lwl2015/p/4460711.html
于是网上就有了一篇所谓的采用FPGA进行引导滤波加速的专利,链接如下:
https://www.doc88.com/p-4377429794731.html?r=1
另附上架构实现图,但我估计这几个小朋友还没有想明白boxfilter是怎么回事,生搬硬套软件boxfilter加速的思维嘛???
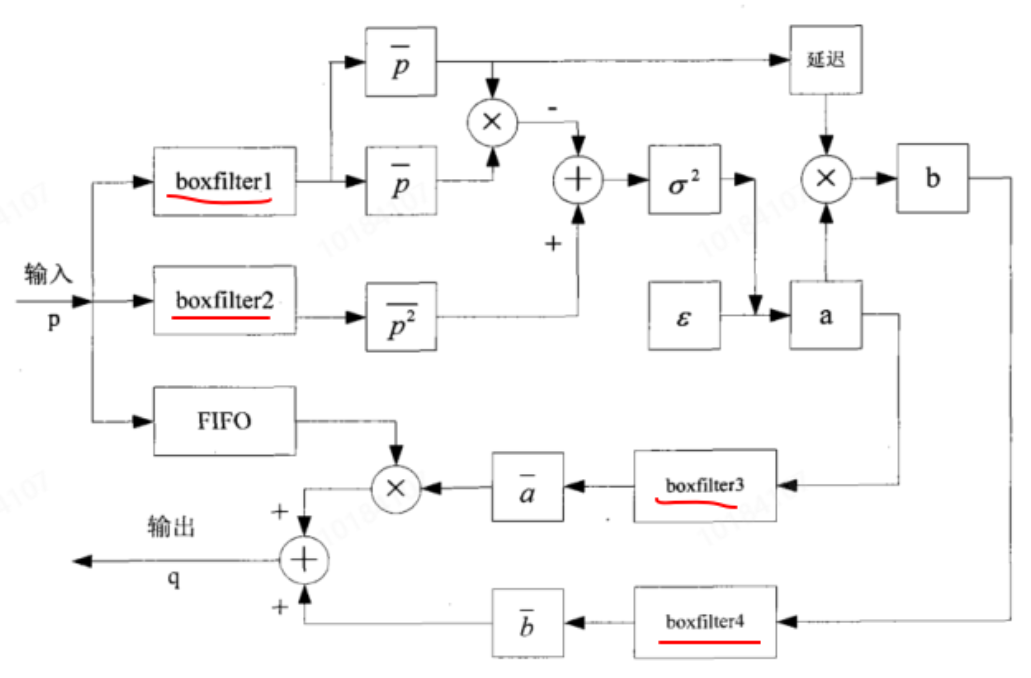
图中,计算均值,平方均值,a的均值,b的均值采用了4个boxfilter,也就是说如果输入1280*720的图像,那就需要缓存4个那么大地址空间的区域来存储中间变量,这显然是不适合FPGA加速运算的啊。FPGA的意义在于高速并行技术,尽可能的避免冲入进入缓存,而是以Pipeline的方式流水线完成运算,实现真正低延时+实时处理的目标。
所以为什么不能流水线完成所有的计算操作呢?
不服来战,没有啥难度的……下面开始我的表演。
【第一步】
以3*3的滤波为例(这里的引导图都是原图),按行从传感器或者DDR中读取原图,采用移位寄存后得到3*3的矩阵行,如下所示:
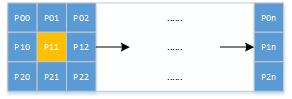
如上图中,以P00-P22为例,这9个像素,我们可以通过计算得均值,以及平方的均值,紧接着继续计算得到a与吧,详见下图,其中相关的参数定义如下:
P原始图像像素集
Pm以当前像素为中心的3*3像素的均值
PPm以当前像素为中心的3*3像素平方的均值
sum1以当前像素为中心的3*3像素的和
sum1以当前像素为中心的3*3像素平方的和
a以当前像素为中心计算的参数a
b以当前像素为中心计算的参数b
am以当前像素为中心的3*3像素的a均值
bm以当前像素为中心的3*3像素的b均值
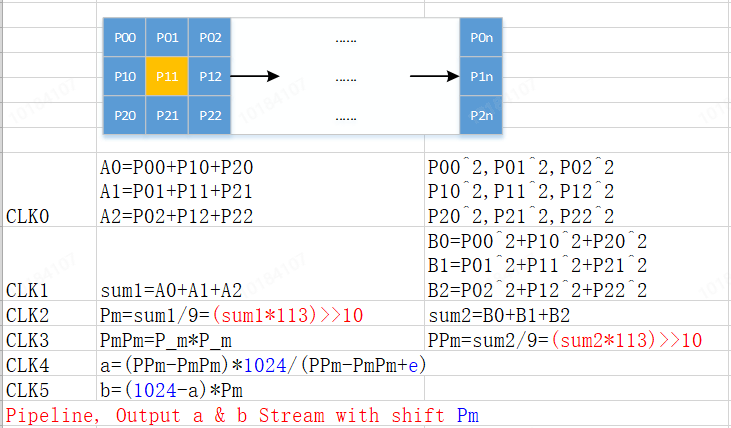
从上图可知,通过三行组成的矩阵,以流水线方式,最快用了6个时钟得到了参数a与b;
由于全图流水线运行,因此从第6个时钟开始,将持续的输出每一个像素对应的a与b,等同于我们通过这一阶段的实现方式,得到了参数a/b阵列。
另外,上图中可知,除以9的运算我已经默默转换为乘法与移位,clk4中将涉及到的小数点,已经提前扩大了1024倍,同等的b中也做了变更(红/蓝色字体),这就是FPGA定点化的加速的方式。
再者,由于最后的计算还需要P的参与,因此上述步骤中,需要将输入的原始图像进行移位延时,最终能和后续am/bm对齐。
【第二步】
接下来,进一步计算am与bm,这个就简单的多了,类似第一步,直接缓存3行得到3*3的矩阵行,通过加权后得到am与bm。这个过程中am与bm的计算可以完全并行,每个am/bm的计算耗时3个时钟。
详见下图计算流:

【第三步】
此时我们已经同时得到了am,bm,以及通过移位delay后和am/bm对齐的P,那么直接套用公式,我们就可以计算出每一个像素滤波后的值:
即输出Q=(am*P+bm)》》10
这里还需要右移10bit,是因为前面第一步中,由于涉及到了小数,我们提前进行了1024倍的扩大,来减少计算误差的损失。
至此,流水线操作,没有使用boxfilter,没有将数据回写入DDR,我们采用了若干行line buffer的形式,完成了实时引导滤波的FPGA加速实现。
整体流程再梳理一下,相关的依赖以及流水方式,如下图所示,应该可以看的更明白。其中绿色为第一步计,灰色为第二步计算,红色为最后一步计算。
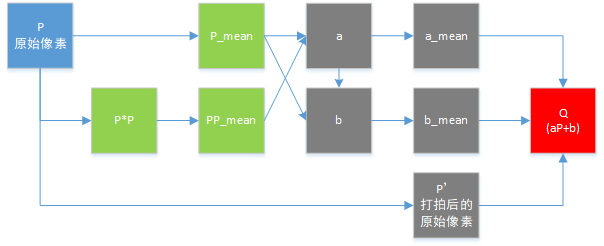
所以,这就是FPGA并行加速运算的价值与意义,按照我的实现方式,可以用最小的代码实现实时的引导滤波,甚至连低端的EP4CE6E都不是问题。
同样一个算法,可以有n种实现方式,你甚至可以把算法挪到MPSOC的PS中执行,然后忍受龟速的同时你可能还会抱怨FPGA跑的慢,CPU性能不足之类的,但是永远不要忘记,架构的意义。正如软件的优化,其实很多时候,并不是算法本身不行,而是你对系统底层,对计算优化的能力不行。
为什么我喜欢用FPGA加速,因为每一个门级电路,以何种并行度何种方式进行计算,一切都可以在我的掌控之中。
所以当年我说过一句话:掌握了FPGA,你便掌握了整个世界。
至此,从均值滤波到中值滤波、高斯滤波、双边滤波、引导滤波这些通用的2D降噪算法,我都已经通过公众号/知识星球/博客的方式,从原理到FPGA加速实现阐述明白。
如果在这之间有任何疑问,或者我有什么不到之处的,欢迎以各种方式来跟我讨论(伸手党麻烦出门右转)。
谢谢大家!
编辑:jq
-
如何用FPGA并行高速运算实现实时的引导滤波算法?2023-07-03 3677
-
采用软件算法实现数字滤波2022-01-18 1654
-
如何用单片机实现数字滤波算法2022-01-07 1497
-
在FPGA体系结构能够实现的并行运算2021-12-15 6615
-
如何使用FPGA实现图像的中值滤波算法2021-04-01 1431
-
如何使用FPGA实现实现高速并行FIR滤波器2021-01-28 1235
-
高速并行成型滤波器的FPGA实现方法2018-02-23 1245
-
基于FPGA的实时图像中值滤波算法及实现_蒋涛2017-03-19 1605
-
fpga实现滤波器2012-08-12 2730
-
基于FPGA的高速实时图像采集和自适应阈值算法2012-08-11 4254
-
基于FPGA的AES加密算法的高速实现2010-01-25 862
-
基于FPGA的超高速FFT硬件实现2009-06-14 8038
-
如何用用FPGA实现FIR滤波器2009-03-30 5008
全部0条评论

快来发表一下你的评论吧 !
