

SSI技术-从概念到现实
电子说
描述
Xilinx 3D IC技术简介
跨Die约束?SLR?SSI?这些是使用UltraScale+/V7常见的概念,但是这些概念到底什么意思?有什么联系?下面我们从根本上去解释这些概念。
SSI技术-从概念到现实
SOC和NOC概念传统的SoC现在很常见,现在用的手机CPU等都是采用这种方式,常见的架构如下:
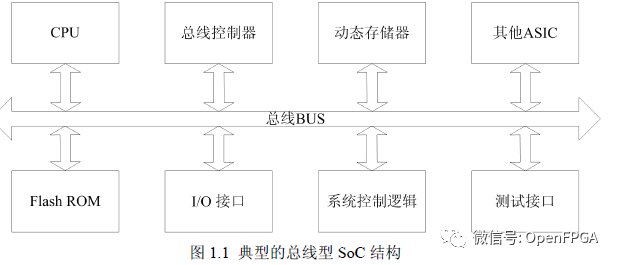
系统采用总线互连结构,多核间的通讯问题已经成为制约系统性能提升的主要瓶颈。
NOC的概念提出来很多年了,但是使用该总线的IC相对很少,但是最近几年兴起的RISC-V或许会在未来更多的应用这一总线。NoC是指在单芯片上集成大量的计算资源以及连接这些资源的片上通信网络,如图1所示。NoC包括计算和通信两个子系统,计算子系统完成广义的“计算”任务。
PE既可以是现有意义上的CPU、SoC,也可以是各种专用功能的IP核或存储器阵列、可重构硬件等;通信子系统(图中由Switch组成的子系统)负责连接PE,实现计算资源之间的高速通信。通信节点及其间的互连线所构成的网络被称为片上通信网络(On-Chip Network, OCN),它借鉴了分布式计算系统的通信方式,用路由和分组交换技术替代传统的片上总线来完成通信任务(参考:http://www.elecfans.com/d.html)。
通过上面的两个总线基础,对于Xilinx采用的3D IC概念的理解就不是很难了。
介绍参考:WP380
随着FPGA在系统设计中的地位越来越重要,设计变得越来越庞大和复杂,对逻辑容量和片上资源的要求也越来越高。到目前为止,FPGA主要依靠摩尔定律来满足这一需求,每一代新工艺都能提供近两倍的逻辑容量。然而,要跟上当今高端市场的需求,摩尔定律所能提供的还远远不够。
FPGA技术最积极的使用者渴望采用每一代FPGA中容量最高、带宽最高的器件。然而,供应商在产品生命周期的早期构建此类FPGA的挑战可能会限制其提供客户生产运行所需设备数量的能力。这是因为实现可重编程技术的电路开销对最大的FPGA的可制造性产生了负面影响。在新工艺节点的早期阶段,当缺陷密度较高时,随着模具尺寸的增大,模具成品率急剧下降。随着制造工艺的成熟,缺陷密度下降,大型模具的可制造性显著提高。
因此,虽然最大的FPGA在产品推出时供不应求,但随着时间的推移,它们的数量最终会满足最终客户的数量需求。为了应对可编程的需求,一些领先的客户向Xilinx提出挑战,要求Xilinx在产品推出后尽快用最大的fpga支持其批量生产需求。
例如,电信市场需要集成数十个串行收发器的FPGA,以提供高信号完整性。设备还需要提供广泛的互连逻辑和块RAM,用于数据处理和流量管理,同时保持当前的外形尺寸和电源。为了获得先发制人的优势,设备制造商希望尽快增加新产品的制造。
Xilinx以一种创新的方法响应了这些要求,构建了带宽和容量等于或超过最大单片FPGA芯片的FPGA芯片,具有较小芯片的制造和上市时间优势,以加快批量生产。SSI技术实现了这些优势,它使用带有微泵的无源硅插入器和通过硅通孔(TSV)将多个高度可制造的FPGA芯片片(称为超级逻辑区(SLR))组合在一个封装中。该技术还允许不同类型的芯片或硅工艺在插入器上互连。这种结构称为异构FPGA。
互连多个FPGA的挑战
SSI技术解决了先前阻碍将两个或多个FPGA的互连逻辑结合起来以创建用于实现复杂设计的更大的“虚拟FPGA”的尝试的挑战。这些挑战包括:
•可用的I/O数量不足以连接复杂的信号网络,这些信号必须在分区设计的FPGA之间传递,也不足以将FPGA连接到系统的其余部分。
•信号在FPGA之间传递的延迟限制了性能。
•使用标准设备I/O在多个FPGA之间创建逻辑连接会增加功耗。
关键挑战:有限的连通性
片上系统(SoC)设计由数百万个门电路组成,这些门电路由多条总线、复杂的时钟分配网络和大量的控制信号组成。在多个FPGA之间成功地划分SoC设计需要大量的I/O来实现跨越FPGA之间间隙的网络。由于SoC设计包括1024位宽的总线,即使针对最高可用管脚数的FPGA封装,工程师也必须使用数据缓冲和其他设计优化,这些优化对于实现高性能总线和其他关键路径所需的数千个一对一连接效率较低。
封装技术是造成这种I/O限制的关键因素之一。目前最先进的软件包提供大约1200个I/O引脚,远远低于所需的I/O总数。
在芯片级,I/O技术还存在另一个限制,因为I/O资源的扩展速度与每个新进程节点的互连逻辑资源的扩展速度不同。当与用于在FPGA的核心构建可编程逻辑资源的晶体管相比时,构成器件I/O结构的晶体管必须大得多,以提供芯片到芯片I/O标准所需的电流和电压。因此,增加芯片上标准I/o的数量对于提供用于组合多个FPGA芯片的连接来说不是一个可行的解决方案。
关键挑战:延迟过大
延迟增加是多FPGA方法的另一个挑战。对于跨多个FPGA的设计,标准设备I/O会施加管脚到管脚的延迟,从而降低整体电路性能。此外,在标准I/O上使用时域复用(TDM)通过在每个I/O上运行多个信号来增加虚拟管脚计数,这会带来更大的延迟,从而使I/O速度降低4倍到32倍或更多。这些降低的速度对于ASIC原型设计和仿真来说通常是可以接受的,但是对于最终产品应用来说通常太慢。
关键挑战:Power Penalty
TDM方法也会导致更高的功耗。当用于在多个FPGA之间的PCB线路上驱动数百个封装到封装的连接时,与在单片芯片上连接逻辑网络相比,标准设备I/O引脚的功耗损失很大。
类似地,多芯片模块(MCM)技术为在单个封装中集成多个FPGA芯片提供了潜在的形状因子缩减优势。然而,MCM方法仍然受到限制I/O计数以及不期望的延迟和功耗特性的限制。
关键挑战:高速串行连接的信号完整性
特别是在高速串行I/O连接很常见的通信应用中,信号完整性差可能成为实现设计关闭的主要瓶颈。FPGA必须提供适当的收发器信号保真度,否则必须花费无数的时间来优化I/O参数、修改PCB设计和执行通道优化以获得设计成功。对于某些要求线速率超过25Gb/s的应用程序,提供足够的信号完整性是一项非常重要的任务。
Xilinx SSI技术为了克服这些限制,Xilinx开发了一种新的方法,用于构建高容量和高性能fpga的生产量。新的解决方案通过提供更多的连接来实现多个芯片之间的高带宽连接。与多FPGA或MCM方法相比,它还具有更低的延迟和显著更低的功耗,同时能够在单个封装中集成大量的互连逻辑、收发器和片上资源。
在FPGA系列的密度范围内,中密度器件代表了“最佳点”。也就是说,与上一代器件相比,它们在芯片尺寸上提供的容量和带宽明显更大,在FPGA产品生命周期中可以比同一系列中的最大器件更早交付。因此,通过在单个器件中组合多个这样的芯片,可以匹配或超过最大的单片器件所提供的容量和带宽,但是具有较小芯片的制造和体积比优势。
Xilinx以创新的方式应用了几种成熟的技术,从而实现了这样一种解决方案。通过将TSV和微泵技术与其创新的ASMBL相结合,体系结构方面,Xilinx正在构建一种新的FPGA,它提供满足可编程需求所需的容量、性能、能力和功率特性。通过无源插入器,Xilinx SSI技术结合了多个FPGA。插入器提供数万个芯片到芯片的连接,以实现超高的互连带宽,功耗低得多,延迟为标准I/O的五分之一。
硅插入层最初是为各种芯片堆叠设计方法而开发的,它提供了模块化设计灵活性和高性能集成,适用于广泛的应用。硅插入器作为基于硅制造工艺(例如,65 nm或45 nm工艺)的互连载体,在该工艺上多个芯片并排设置并互连。SSI技术避免了由于将多个FPGA芯片堆叠在彼此或MCM上而导致的功耗和可靠性问题。
与有机或陶瓷基板相比,在mcm中,硅插入层提供了更精细的互连几何结构(约20倍密集的线间距)以提供设备级互连层次结构,支持10000多个管芯到管芯的连接。
用微泵制作用于叠层硅集成的FPGA芯片片Xilinx SSI技术的基础是公司专有的ASBL体系结构,一种模块化结构,包括以实现可配置逻辑块(CLB)、块RAM、DSP片、SelectIO等关键功能的瓷砖形式的Xilinx FPGA构建块。SelectIO和串行收发器。
这些资源被组织成列,然后组合起来创建一个FPGA。通过改变柱的高度和排列,可以创建各种各样的设备来满足不同的市场需求(图2)。FPGA包含用于生成时钟信号和用位流数据编程SRAM单元的附加块,位流数据配置设备以实现最终用户期望的功能。
从基本的ASMBL体系结构构造开始,Xilinx引入了三个关键的修改,它们支持堆叠硅集成。首先,每个芯片片接收自己的时钟和配置电路。然后对布线结构进行了修改,使其能够绕过传统的并行和串行I/O电路,通过芯片表面的钝化直接连接到FPGA逻辑阵列中的布线资源。
最后,每个单反相机都要经过额外的加工步骤来制造微泵,将芯片连接到硅衬底上。正是这一创新使得连接的数量大大增加,延迟大大降低,功耗也大大低于使用传统I/O(每瓦特的SLR到SLR连接带宽是标准I/O的100倍)。
带TSV的硅插入器无源硅插入器将多个FPGA SLR互连在一起。它是建立在一个低风险,高产量的65nm工艺,并提供四层金属化建设数以万计的记录道,连接多个FPGA芯片的逻辑区域。
组装好的芯片组的“X射线视图”的概念。它包含一个由四个FPGA单反并排安装在无源硅插入器上的堆栈(底视图)。插入器被显示为透明的,以便能够看到由硅插入器上的记录道连接的FPGA SLR(不按比例)。
TSV与可控折叠芯片连接(C4)焊点相结合,使Xilinx能够使用倒装芯片组装技术将FPGA/插入器堆栈安装在高性能封装基板上(见图1)。粗间距TSV提供了封装和FPGA之间的连接,用于并行和串行I/O、电源/接地、时钟、配置信号等。
这项SSI技术包括许多正在申请专利,通过10000多个设备规模的连接,提供每秒数TB的芯片间带宽,足以满足最复杂的多模设计。Xilinx正在使用这项新技术来支持Virtex-7 fpga家族的几个成员。
异种模具的SSI技术除了在硅插入器上集成同质单反外,SSI技术还可以集成不同类型的芯片。在图6中,Virtex-7 H870T FPGA通过硅插入器将三个SLR以及单独的28G收发电路连接在一起。由于SLR和28Gb/s收发器电路代表不同的硅工艺和功能,Virtex-7HT FPGA是世界上第一个异构体系结构,它是由异构芯片并排放置组成的FPGA,可以作为一个集成设备运行。
将数字FPGA与收发器物理分离的关键好处之一是噪声隔离。这确保了尽可能低的抖动和噪声,以简化设计关闭和降低电路板成本。
将28G收发器与SLR分离是异构体系结构如何为特定应用实现最佳结果的一个示例。因为收发器是复杂的模拟电路,在单片设备上实现它们需要更复杂的设计方法。作为一个单独的片,28G电路是为最大可能的容量和最佳可能的性能和功率,而不损害数字逻辑的功能。
异构体系结构的另一个好处是能够为传统的FPGA资源提供不同比率的收发器。Virtex-7 HT FPGA具有多达16个28G收发器,实现了前所未有的集成,处于高带宽设计的前沿。
Virtex-7系列表1所示的支持SSI的设备提供了前所未有的FPGA功能。这些设备提供多达:2000000个逻辑单元;68 Mb块RAM;5335gmacs的DSP性能;1200个SelectIO引脚,支持1.6Gb/s LVDS并行接口;2784Gb/s聚合双向带宽。
表1:Virtex-7 FPGA
FPGAsPart Numbers
Virtex-7 TXC7V585T、XC7V2000T
Virtex-7 XTXC7VX330T、XC7VX415T、XC7VX485T、XC7VX550T、XC7VX690T、XC7VX1140T
Virtex-7 HTXC7VH580T、XC7VH870T
基于SSI技术的FPGA设计利用SSI技术,设计人员创建和管理单个设计项目。这是一个非常重要的优势,因为跨多个FPGA划分大型设计会带来许多复杂的设计挑战,这些挑战不适用于单片实现。
单片FPGA设计流程中的典型步骤包括:
•创建高级描述
•综合成与硬件资源匹配的RTL描述
•执行物理位置和路线
•估计时间并调整时间结束的设计
•生成bit流以编程FPGA
当使用多个FPGA时,设计人员(或设计团队)必须在整个FPGA中划分网络表。使用多个网表意味着打开和管理多个项目,每个项目都有自己的设计文件、IP库、约束文件、打包信息等。
多个FPGA设计的时序关闭也可能是非常具有挑战性的。
计算和调整通过板到其他FPGA的传播延迟带来了新的复杂问题。同样地,在多个FPGA中通过多个部分网表调试设计可能是极其复杂和困难的。
相比之下,SSI技术路由对用户是透明的。用户使用一个标准的合成和定时闭包流执行单个设计的启动和调试。为了加速集成和实现这种容量的设备(超过200万个逻辑单元),Xilinx引入了Vivado 设计套件-一个开发环境,旨在支持当前和未来的高容量设备。
应用采用SSI技术的Xilinx-Virtex-7型FPGA突破了单片FPGA的局限性,在一些最苛刻的应用中扩展了其价值。例如,Virtex-7系列是下一代电信和网络系统的理想选择,在下一代电信和网络系统中,数十个串行收发器被用来实现灵活的,
单个FPGA解决方案。这些设备也非常适合在ASIC原型中使用,可以作为预生产和/或初始生产ASIC的替代品。Virtex-7系列还为科学、石油和天然气、金融、航空航天和国防以及生命科学应用提供灵活、可扩展、定制的高性能计算解决方案。
FPGA架构中固有的并行性非常适合于高吞吐量处理和软件加速。对多种高速并行和串行连接标准的支持使计算和通信系统得以融合。在航空航天和国防领域,采用SSI技术的FPGA提供的高收发信机数量和数千个DSP处理元件使先进的雷达实现成为可能。
SSI技术-从概念到现实Xilinx在创建SSI技术时采用的开发策略始于广泛的建模和随后创建的一系列测试设备或测试车辆,用于设计支持、可制造性和可靠性验证。
这些测试车辆和应力模拟模型显示了叠层硅技术的另一个优势。与单片解决方案相比,硅插入器起到了缓冲作用,降低了低K介电应力,提高了C4凸点可靠性。
对芯片堆热影响的大量模拟和研究表明,采用SSI技术的器件的热性能与单片器件相当。
经过近六年的广泛研究和开发,Xilinx于2011年9月推出了世界上容量最高的FPGA,Virtex-7 2000T器件,该器件采用SSI技术。2012年5月,Xilinx发布了世界上第一款异构设备Virtex-7 H580T,该设备采用28G收发器,针对Nx100G有线通信应用(见Xilinx新闻稿:http://press.xilinx.com/phoenix.zhtml?c=212763&p=RssLanding&cat=news&id=17 00586)。
跨SLR处理跨SLR的长线数量是有限的,需要从一个SLR的特殊的地方有入口,需要先打拍从逻辑的FF在SLR内部走线到SLR的入口附近的FF,然后过这个长线到接收FF,然后再走线到真实的接收逻辑(群内大佬指点)。
所以跨SLR处理需要一个专门的寄存器打拍,每个SLR之间有一个专门用来跨die用的寄存器。
总结作为唯一一家将SSI技术应用于超大容量和收发带宽FPGA的FPGA制造商,Xilinx在系统级集成领域取得了重大突破。SSI技术使Xilinx能够提供最高的逻辑密度、带宽和片上资源,并在每个进程节点以最快的速度实现批量生产。
使用SSI技术实现的FPGA进行设计要比另一种设计简单得多。灵活的工具流支持设计闭包自动化,同时允许用户交互以实现更高的性能。
Xilinx目前正在运送世界上容量最高的FPGA-Virtex-7 2000T设备,以及世界上第一个异构FPGA-Virtex-7 H580T,两者均采用SSI技术。有关更多信息,请访问www.xilinx.com/virtex7。
参考资料https://www.xilinx.com/products/silicon-devices/3dic.html
https://www.xilinx.com/publications/white-papers/3d-ic-in-3d-fpgas.pdf
对于IC工艺上一些概念深入不多,如有问题,欢迎指正。
编辑:jq
-
源网荷储:从概念到实践的全面解析2025-11-21 1914
-
功率芯片PCB嵌埋式封装“从概念到量产”,如何构建?2025-09-20 3811
-
SiC+Si混碳融合逆变器 · 从概念到系统方案落地的全景解析2025-08-15 4319
-
3D打印技术,推动手板打样从概念到成品的高效转化2024-12-26 12023
-
EMC技术:基础概念到应用的解读?2024-03-11 1898
-
SOLIDWORKS 2024:简化和加快从概念到制造的产品开发流程2024-01-25 1165
-
SSI 接口技术介绍2023-04-04 19312
-
从概念到实地应用,加速完成机器人最后“一道工序”2022-04-26 2473
-
AI技术如何从概念到现实?从产业体系到人的生活,如何利用AI的力量?2019-09-27 3073
-
SSI在音频处理中的应用2019-05-22 2608
-
从概念到底层技术,一文看懂区块链架构设计(附知识图谱)2018-09-13 1852
-
深度学习是如何从概念发展为现实的?2018-05-31 4853
-
小米MIX2怎么样?小米MIX2评测:小米MIX2从概念回归现实,果粉会不会成为米粉?2017-09-21 831
-
加速产品从概念到成型上市并不困难2015-05-21 4475
全部0条评论

快来发表一下你的评论吧 !
