

Transformer的复杂度和高效设计及Transformer的应用
描述
来自:AI部落联盟
前言
这次我们总结一下ACL2021中的Transformers,看看2021年了,NLPer在如何使用、应用、改进、分析Transformers,希望可以对大家产生idea有帮助。
本文涉及25篇Transformer相关的文章,对原文感兴趣的读者可以关注公众号回复: ACL2021Transformers,下载本文所涉及的所有文章~本文主要内容:
前言
ACL 2021中的25个Transformers模型
总结
ACL 2021中的25个Transformers模型
NLP中的层次结构Hi-Transformer: Hierarchical Interactive Transformer for Efficient and Effective Long Document Modeling
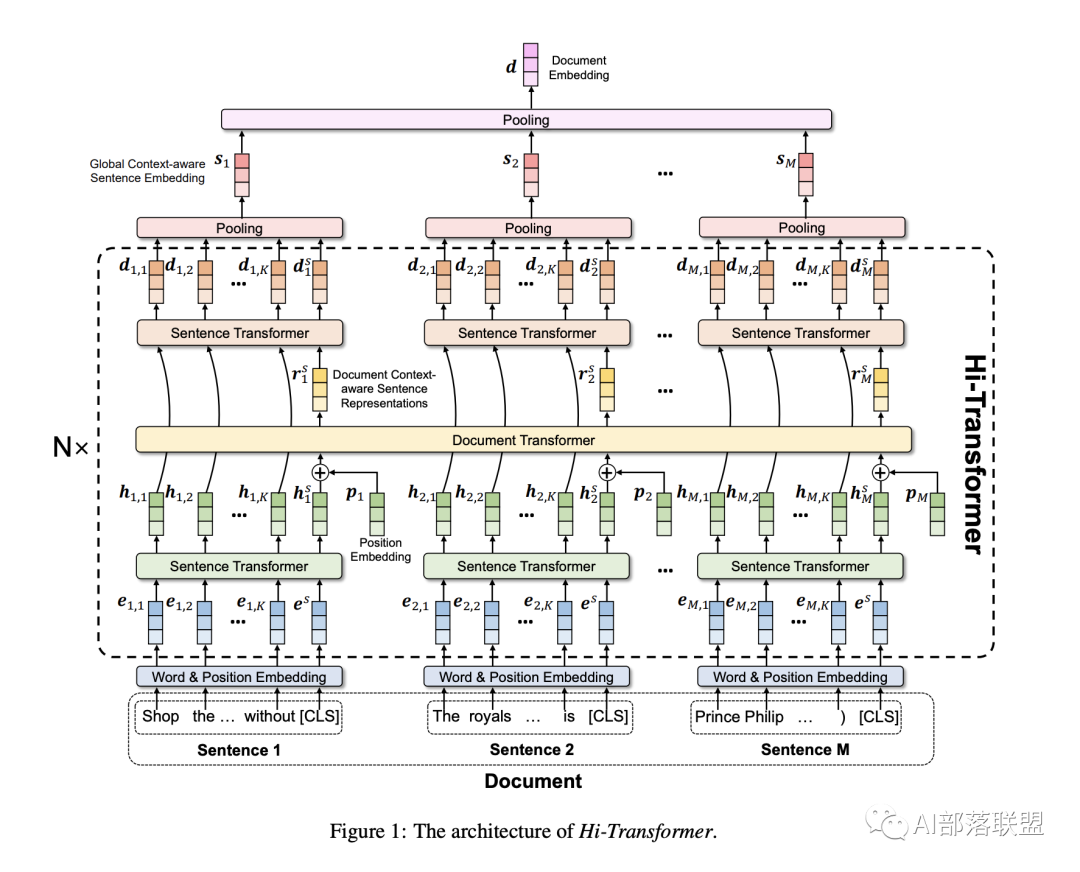
高效和长文本transformer模型设计,短文。如上图所示,这篇文章主要提出一种解决长文本任务的transformer模型:首先分别encoder sentence表示,然后再encod document表示,最后再重新encde sentence表示,总体上比较简单的local+global设计。
R2D2: Recursive Transformer based on Differentiable Tree for Interpretable Hierarchical Language Modeling
将Transformer和语言文字层次结构相结合的一篇文章。本文基于可差分CKY树,提出一种recursive Transformer模型,用于捕获语言中的层次结构(words, Phrases, sentences),与目前直接堆叠Transformer Layer的模型进行对比(例如BERT,Albert)除了可以学好表示,还能学到tree结构,与之前基于CKY的parser模型,Tree-LSTM模型比较相似。为了能让recursive Transformer进行快速、大规模训练,文章也相应提出了优化算法。Recursive Transformer语言模型实验是基于WikiText-2做的,效果还可以。为了凸显该模型的tree 结构性,文章进一步做了无监督Constituency Parse,显示了该模型结构在学习语言层次结构上的能力。
Transformer复杂度和高效设计IrEne: Interpretable Energy Prediction for Transformers
本文预测Transformer运行所消耗的能量,很有趣。首先,这篇文章将Transformer模型结构按照Tree进行拆解:整个模型是root节点(例如BERT),root节点下逐步拆分出子模块(比如BertSelf Attention),最终子模块由最基本的ML单元组成(例如全连接Dense网络),最终自底向上,先预测单个ML单元的能量消耗,再汇总计算出整体模型的能量消耗。为了验证该方法的有效性,该文还创建了一个数据集来评测Transformer-based模型的能量消耗。IrEne的代码在:https://github.com/StonyBrookNLP/irene
Optimizing Deeper Transformers on Small Datasets
小数据集+更深更大的模型,有点反常识的感觉,不过也很有趣。总体上,这篇文章通过合适的模型初始化方式和优化算法,在很小很难的Text-to-SQL任务上取得了不错的结果,这篇文章的核心是Data-dependent Transformer Fixed-update,那这个DT-Fixup怎么做的呢?比如使用的模型是roberta,在roberta上面再堆叠个几层随机Transformer:
对于模型中非预训练模型初始化的部分,使用Xavier initialization进行初始化。
对于模型中非预训练模型初始化的部分,将学习率的warm-up和所有的layer normalization去掉。
对所有的样本进行一遍前向传播获得输入的一个估计:,是roberta输出的表示。
根据得到的,在新叠加的每层Transformer上,对attention和权重矩阵进行设计好的缩放。
文章理论推导较多,建议感兴趣的同学下载文章后阅读原文进行学习。
READONCE Transformers: Reusable Representations of Text for Transformers
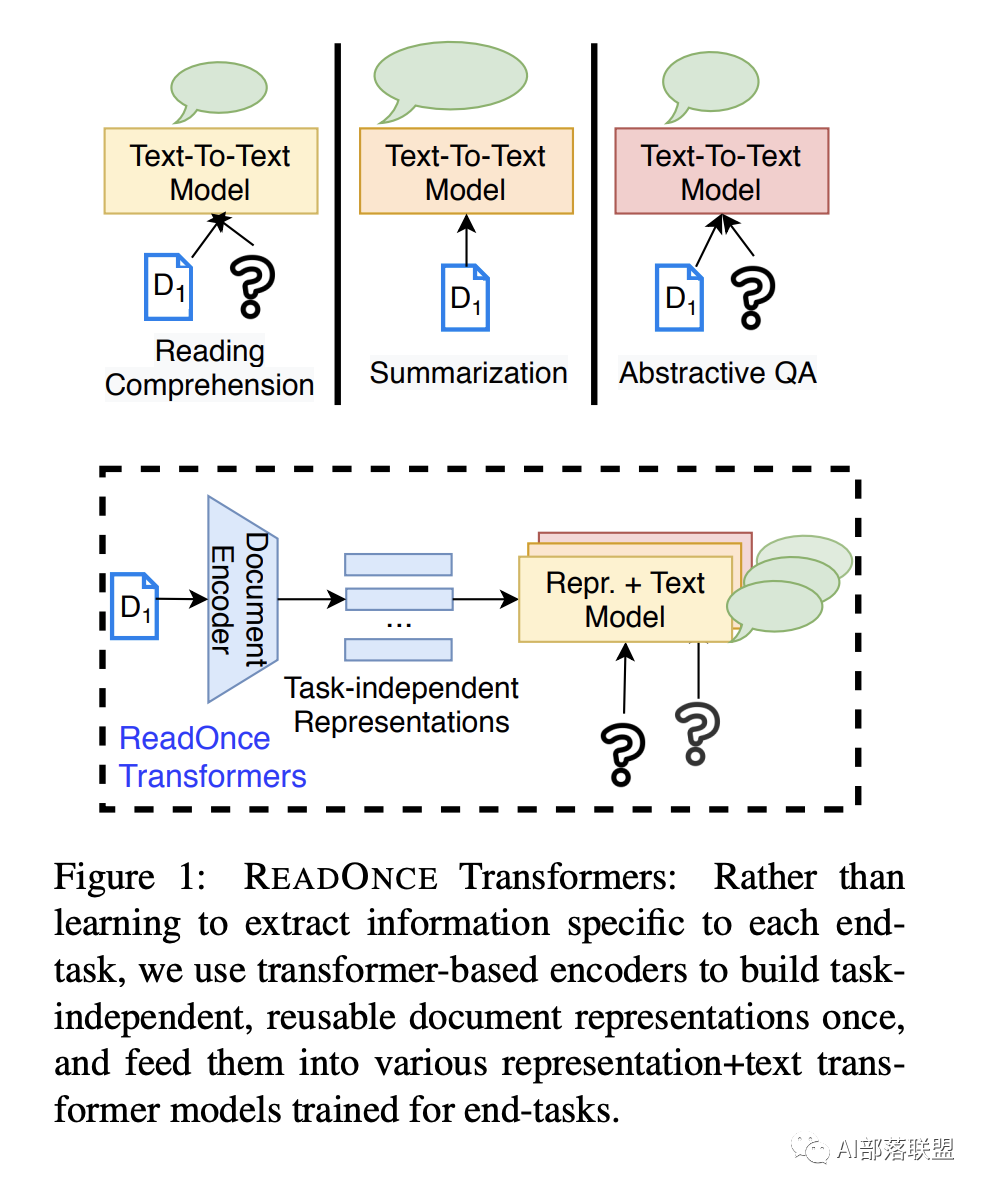
Transformer推理提速。文章的思路是:无论是问答任务,摘要生成任务还是其他任务里的不同样本可能会多次涉及到同一个wiki段落,这个时候不用每次都重新encode这个wiki段落,可以只encode这个段落一次然后re-use。文章思路和另一个SIGIR 2020的很像:DC-BERT: Decoupling Question and Document for Efficient Contextual Encoding
Parameter-efficient Multi-task Fine-tuning for Transformers via Shared Hypernetworks
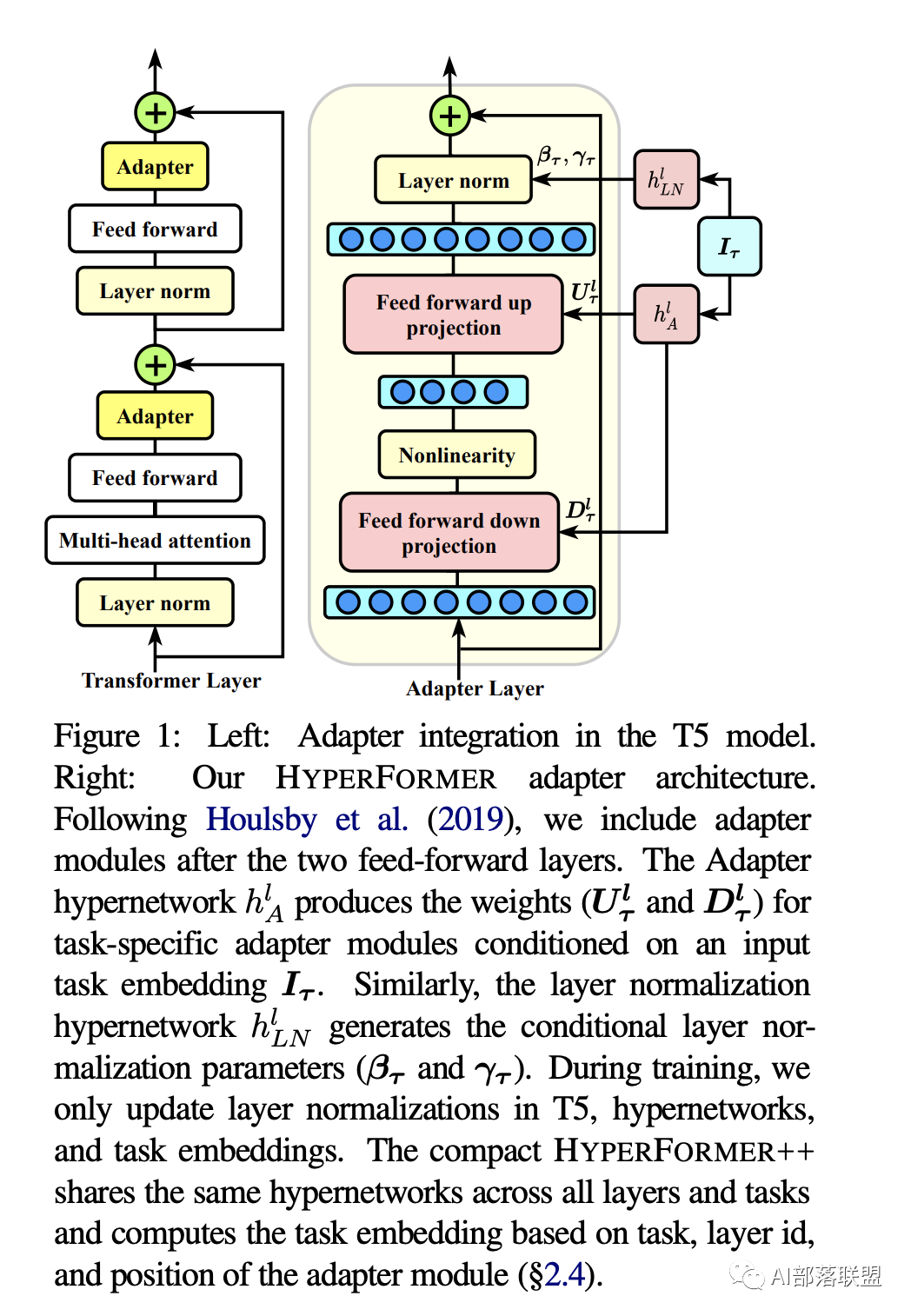
parameter-efficient相关的一篇文章,通过多任务学习和特定的模型参数共享来达到更好的迁移学习效果。总体上模型是make sense的。如上图所示,该论文基于adapter类似的结构设计来帮助下游任务finetune,但adapter处的设计与之前的研究不同的是:给予task id, adapter位置,layer id动态计算所有layer的adapter参数。代码开源在:https://github.com/rabeehk/hyperformer
Length-Adaptive Transformer: Train Once with Length Drop, Use Anytime with Search
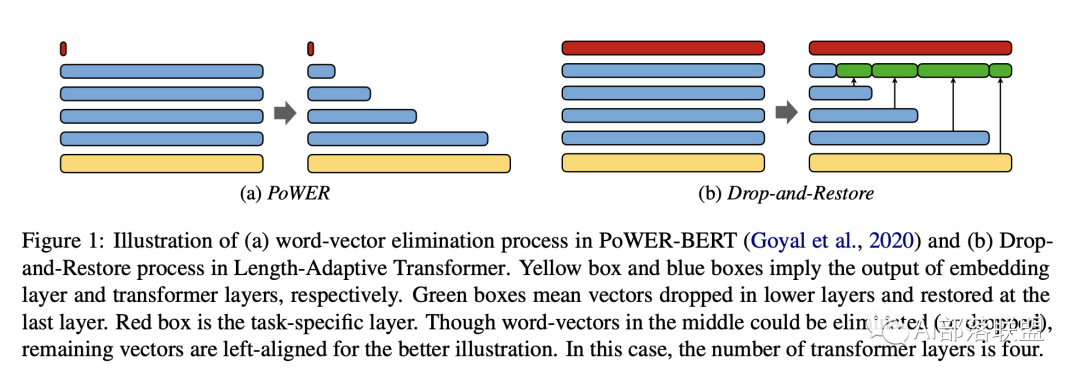
高效Transformer设计。文章的主要亮点是:1. transformer中间层的长度自适应,可以减少参数量。2. 减少的参数所对应的token表示可以被restore,因此可以用来做抽取式QA任务。文章在文本分类和QA任务上进行了验证。
H-Transformer-1D: Fast One-Dimensional Hierarchical Attention for Sequences
高效transformer设计。文章借鉴数值分析领域的:Hierarchical Matrix和Multigrid method,提出了一种hierarchical attention结构,该结构是线性时间复杂度和空间复杂度,并进一步优化到只使用dense layer运算进行实现。
Transformer分析和可解释性Personalized Transformer for Explainable Recommendation
推荐、可解释性、NLP相结合的一篇文章。该论文提出了PETER模型(如上图所示),将user, item和item feature,item的explanation当作模型输入,对user,item进行表示学习,同时也学习item特征向量表示和explanation文字的表示,输出又3个任务,Rating prediction是推荐任务,context Prediction是用item的输出表示预测item的生成item的explanation(和doc2vec算法类似),Explanation Generation就是正常的生成任务。
总体上user、item着两个输入和对应的表示能让模型学到Personalized和recommendation的知识,Explanation预测就是正常的生成任务。该模型在Yelp、Amazon,TripAdvisor数据集上做了实验,有不错的效果。
Contributions of Transformer Attention Heads in Multi- and Cross-lingual Tasks
对Transformer不同Head重要性进行分析的一篇文章。这篇文章在multi-lingual,Cross-lingual任务上,对mBERT、XLM-R这两个Transformer模型进行了分析,实验结果显示:1. 对attention head进行剪裁之后依旧可以获得与原模型相匹配的效果,甚至可以获得更好的效果。2. 根据梯度来确定哪些head可以被剪裁。3. 文章在多语言的POS和NER数据集上验证了结论和方法的正确性质。
Are Pre-trained Convolutions Better than Pre-trained Transformers?
对比CNN和Transformer的效果。该文之前已经在公众号上分享过啦,相关链接: 预训练的卷积模型比Transformer更好?
Attention Calibration for Transformer in Neural Machine Translation
翻译的时候decoder需要attention到正确的词才能获得更好的效果,但是如果有其他不重要带来了严重的干扰,那么翻译效果将会下降,来自腾讯的这篇工作展示了如何修正翻译中的attention来帮助机器翻译。
总体结构如上图所示,通过一个mask perturbation 模型来学习如何对attention进行修正,基本思路是:如果mask到了重要的词,那么翻译效果下降,如果mask掉了干扰词(也就是修正了原来的attention分数),那么翻译效果上升。
What Context Features Can Transformer Language Models Use?
Transformer需要的重要feature分析。这篇文章对transformer模型在中长文本上的效果进行对比分析发现:
1. 对于长文本而言,增加最大token数量的限制(256到768)有帮助。
2. 对于当前的模型而言,长文本的信息主要来源于content words和局部occurrence统计信息:删除一些function words和局部window内随机shuffle对模型最终影响比较小。
3. 并不是context中所有feature重要性都相同。总体上文章对:word order,sentence order,order of sections,根据token属性对token进行控制变量的删减等一些列feature进行了控制变量分析。
Reservoir Transformers
Transformer分析文章。文章显示:固定预训练模型的部分参数或者增加一些随机初始化的模块(比如加入gru,cnn等模块)可以提升transformer模型最终效果。文章在语言模型和翻译任务上进行验证。
More Identifiable yet Equally Performant Transformers for Text Classification
对Transformer模型进行可解释性设计。文章的主要贡献是:1. attention不同权重可鉴别性的理论分析。2. 设计了一种transformer变体有助于attention权重的鉴别从而提升可解释性。3. 在文本分类任务上做了分析和验证,提升可鉴别性的同时不降低原有任务的效果。
长文本处理ERNIE-DOC: A Retrospective Long-Document Modeling Transformer
针对长文本处理的Transformer优化,来自百度NLP团队。入上图所示,整个长文章的被分成了多片,该文章认为之前的Transformer模型都无法利用整个文章的信息,而提出的ERNIE-DOC用到了所有文本信息。
为了让模型能看到长文本所有信息,该文章主要有以下几个贡献:
1. 一个长文本feed给模型2次。
2. 由于目前的recurrence Transformer所能看到的最长文本受到最大层数的限制,所以提出了一个enhanced recurrence mechanism进一步扩大Transformer所能看到的文本范围。
3. 还提出了一个segment-reordering任务,主要就是将文本中的分片打乱,然后预测是否是正确的顺序。论文在语言模型任务、document-level的长文本理解任务,以及一系列中英文下游任务上进行了验证。
G-Transformer for Document-level Machine Translation
Transformer虽然在单句翻译中有不错的效果了,但多句翻译/document-level的翻译还远不够好。这篇文章发现多句翻译训练的时候容易陷入局部最优,陷入局部最优的原因是因为翻译的时候需要attention 的source words太多了。
所以这个文章做了一个比较容易理解的事情:把document level的翻译依旧看作是多个单个句子翻译,通过句子序号来提醒模型翻译到哪里了,从而缩小target到source需要attention的范围。
Transformer有趣的应用Topic-Driven and Knowledge-Aware Transformer for Dialogue Emotion Detection
结合Transformer和knowledge base,对对话系统中的Topic和情感倾向进行识别。该文主要贡献如下:1. 首次基于topic来帮助对话情感识别。2. 使用pointer network和attention机制融入commonsense knowledge。3.在解决对话情感检测任务时,设计了一个基于Transformer encoder-decoder结构的模型,来取代之前通用的recurrent attention一类的网络。
Unsupervised Out-of-Domain Detection via Pre-trained Transformers
深度学习模型的效果越来越好,但如果遇到和训练样本分布不一致的输入会怎么样?这篇文章基于BERT模型中多层Transformer所提取的feature,在inference阶段对out-of-domian的样本检测,可以有效排除和训练样本分布不一致的测试样本,基于深度学习模型对深度学习模型的输入进行检查,也是很有趣的一个方向。
MECT: Multi-Metadata Embedding based Cross-Transformer for Chinese Named Entity Recognition
融入中文字形而设计的一种Transformer,该论文显示融入了中文字形之后,在多个中文任务上取得了更好的效果。
ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information
ARBERT & MARBERT: Deep Bidirectional Transformers for Arabic
扩展Transformer模型到多种语言。文章设计和实现了两个ARabic-specific Transformer并在大量的语料和多种datasets上进行了预训练,文章还提出了一个benchmark ARLUE进行专门的多语言评测。
Glancing Transformer for Non-Autoregressive Neural Machine Translation
Transformer在翻译上的应用,主要是非自回归翻译模型方法的提出,来自字节跳动。文章提出一种非自回归的翻译模型,可以并行快速decode。感兴趣的读者可以阅读中文讲解:https://www.aminer.cn/research_report/60f0188430e4d5752f50eafd
在预训练中用上字形和拼音信息,和上一个MECT同类型的研究。
总结
本文涉及的transformer相关研究主要分以下几个类别:
NLP中的层次结构
Transformer的复杂度和高效设计
长文本处理
基于Transformer的一些有趣的应用
今天的分享就到这里啦,大家觉得不错的话,帮点赞和分享一下吧,谢谢~~~
编辑:jq
- 相关推荐
- 热点推荐
- ACL
- Transformer
- nlp
-
图解芯技术 | Transformer2026-07-01 125
-
降低Transformer复杂度O(N^2)的方法汇总2023-12-04 3170
-
BEV人工智能transformer2023-08-22 1758
-
Transformer结构及其应用详解2023-06-08 3597
-
关于Transformer的核心结构及原理2023-03-08 1895
-
基于视觉transformer的高效时空特征学习算法2022-12-12 2844
-
你了解在单GPU上就可以运行的Transformer模型吗2022-11-02 2200
-
用于语言和视觉处理的高效 Transformer能在多种语言和视觉任务中带来优异效果2021-12-28 2833
-
Inductor and Flyback Transformer Design .pdf2021-07-26 1051
-
时间复杂度是指什么2021-07-22 1935
-
我们可以使用transformer来干什么?2021-04-22 13674
-
JEM软件复杂度的增加情况2019-07-19 2132
-
ABBYY PDF Transformer+两步骤使用复杂文字语言2017-10-16 1838
-
如何更改ABBYY PDF Transformer+界面语言2017-10-11 2263
全部0条评论

快来发表一下你的评论吧 !
