

Spark SQL的概念及查询方式
描述
一、Spark SQL的概念理解
Spark SQL是spark套件中一个模板,它将数据的计算任务通过SQL的形式转换成了RDD的计算,类似于Hive通过SQL的形式将数据的计算任务转换成了MapReduce。
Spark SQL的特点:
和Spark Core的无缝集成,可以在写整个RDD应用的时候,配置Spark SQL来完成逻辑实现。
统一的数据访问方式,Spark SQL提供标准化的SQL查询。
Hive的继承,Spark SQL通过内嵌的hive或者连接外部已经部署好的hive案例,实现了对hive语法的继承和操作。
标准化的连接方式,Spark SQL可以通过启动thrift Server来支持JDBC、ODBC的访问,将自己作为一个BI Server使用
Spark SQL数据抽象:
RDD(Spark1.0)-》DataFrame(Spark1.3)-》DataSet(Spark1.6)
Spark SQL提供了DataFrame和DataSet的数据抽象
DataFrame就是RDD+Schema,可以认为是一张二维表格,劣势在于编译器不进行表格中的字段的类型检查,在运行期进行检查
DataSet是Spark最新的数据抽象,Spark的发展会逐步将DataSet作为主要的数据抽象,弱化RDD和DataFrame.DataSet包含了DataFrame所有的优化机制。除此之外提供了以样例类为Schema模型的强类型
DataFrame=DataSet[Row]
DataFrame和DataSet都有可控的内存管理机制,所有数据都保存在非堆上,都使用了catalyst进行SQL的优化。
Spark SQL客户端查询:
可以通过Spark-shell来操作Spark SQL,spark作为SparkSession的变量名,sc作为SparkContext的变量名
可以通过Spark提供的方法读取json文件,将json文件转换成DataFrame
可以通过DataFrame提供的API来操作DataFrame里面的数据。
可以通过将DataFrame注册成为一个临时表的方式,来通过Spark.sql方法运行标准的SQL语句来查询。
二、Spark SQL查询方式
DataFrame查询方式
DataFrame支持两种查询方式:一种是DSL风格,另外一种是SQL风格
(1)、DSL风格:
需要引入import spark.implicit. _ 这个隐式转换,可以将DataFrame隐式转换成RDD
(2)、SQL风格:
a、需要将DataFrame注册成一张表格,如果通过CreateTempView这种方式来创建,那么该表格Session有效,如果通过CreateGlobalTempView来创建,那么该表格跨Session有效,但是SQL语句访问该表格的时候需要加上前缀global_temp
b、需要通过sparkSession.sql方法来运行你的SQL语句
DataSet查询方式
定义一个DataSet,先定义一个Case类
三、DataFrame、Dataset和RDD互操作
RDD-》DataFrame
普通方式:例如rdd.map(para(para(0).trim(),para(1).trim().toInt)).toDF(“name”,“age”)
通过反射来设置schema,例如:
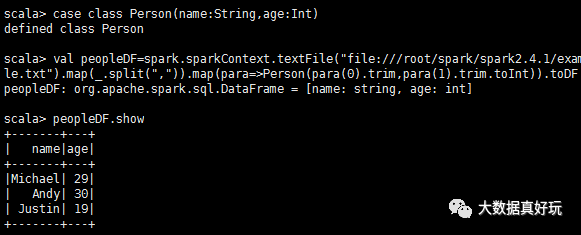
#通过反射设置schema,数据集是spark自带的people.txt,路径在下面的代码中case class Person(name:String,age:Int)
val peopleDF=spark.sparkContext.textFile(“file:///root/spark/spark2.4.1/examples/src/main/resources/people.txt”).map(_.split(“,”)).map(para=》Person(para(0).trim,para(1).trim.toInt)).toDF
peopleDF.show
#注册成一张临时表
peopleDF.createOrReplaceTempView(“persons”)
val teen=spark.sql(“select name,age from persons where age between 13 and 29”)
teen.show
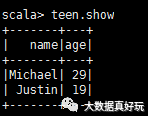
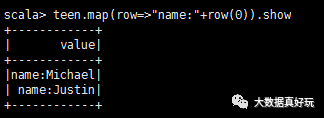
这时teen是一张表,每一行是一个row对象,如果需要访问Row对象中的每一个元素,可以通过下标 row(0);你也可以通过列名 row.getAs[String](“name”)
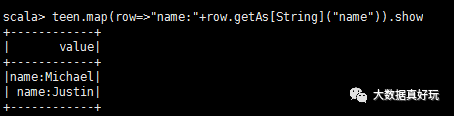
也可以使用getAs方法:
3、通过编程的方式来设置schema,适用于编译器不能确定列的情况
val peopleRDD=spark.sparkContext.textFile(“file:///root/spark/spark2.4.1/examples/src/main/resources/people.txt”)
val schemaString=“name age”
val filed=schemaString.split(“ ”).map(filename=》 org.apache.spark.sql.types.StructField(filename,org.apache.spark.sql.types.StringType,nullable = true))
val schema=org.apache.spark.sql.types.StructType(filed)
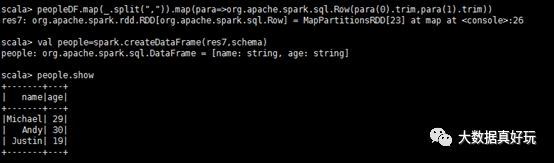
peopleRDD.map(_.split(“,”)).map(para=》org.apache.spark.sql.Row(para(0).trim,para(1).trim))
val peopleDF=spark.createDataFrame(res6,schema)
peopleDF.show


DataFrame-》RDD
dataFrame.rdd
RDD-》DataSet
rdd.map(para=》 Person(para(0).trim(),para(1).trim().toInt)).toDS
DataSet-》DataSet
dataSet.rdd
DataFrame -》 DataSet
dataFrame.to[Person]
DataSet -》 DataFrame
dataSet.toDF
四、用户自定义函数
用户自定义UDF函数
通过spark.udf功能用户可以自定义函数
自定义udf函数:
通过spark.udf.register(name,func)来注册一个UDF函数,name是UDF调用时的标识符,fun是一个函数,用于处理字段。
需要将一个DF或者DS注册为一个临时表
通过spark.sql去运行一个SQL语句,在SQL语句中可以通过name(列名)方式来应用UDF函数
用户自定义聚合函数
1. 弱类型用户自定义聚合函数
新建一个Class 继承UserDefinedAggregateFunction ,然后复写方法:
//聚合函数需要输入参数的数据类型
override def inputSchema: StructType = ???
//可以理解为保存聚合函数业务逻辑数据的一个数据结构
override def bufferSchema: StructType = ???
// 返回值的数据类型
override def dataType: DataType = ???
// 对于相同的输入一直有相同的输出
override def deterministic: Boolean = true
//用于初始化你的数据结构
override def initialize(buffer: MutableAggregationBuffer): Unit = ???
//用于同分区内Row对聚合函数的更新操作
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = ???
//用于不同分区对聚合结果的聚合。
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = ???
//计算最终结果
override def evaluate(buffer: Row): Any = ???
你需要通过spark.udf.resigter去注册你的UDAF函数。
需要通过spark.sql去运行你的SQL语句,可以通过 select UDAF(列名) 来应用你的用户自定义聚合函数。
2、强类型用户自定义聚合函数
新建一个class,继承Aggregator[Employee, Average, Double],其中Employee是在应用聚合函数的时候传入的对象,Average是聚合函数在运行的时候内部需要的数据结构,Double是聚合函数最终需要输出的类型。这些可以根据自己的业务需求去调整。复写相对应的方法:
//用于定义一个聚合函数内部需要的数据结构
override def zero: Average = ???
//针对每个分区内部每一个输入来更新你的数据结构
override def reduce(b: Average, a: Employee): Average = ???
//用于对于不同分区的结构进行聚合
override def merge(b1: Average, b2: Average): Average = ???
//计算输出
override def finish(reduction: Average): Double = ???
//用于数据结构他的转换
override def bufferEncoder: Encoder[Average] = ???
//用于最终结果的转换
override def outputEncoder: Encoder[Double] = ???
新建一个UDAF实例,通过DF或者DS的DSL风格语法去应用。
五、Spark SQL和Hive的继承
1、内置Hive
Spark内置有Hive,Spark2.1.1 内置的Hive是1.2.1。
需要将core-site.xml和hdfs-site.xml 拷贝到spark的conf目录下。如果Spark路径下发现metastore_db,需要删除【仅第一次启动的时候】。
在你第一次启动创建metastore的时候,你需要指定spark.sql.warehouse.dir这个参数, 比如:bin/spark-shell --conf spark.sql.warehouse.dir=hdfs://master01:9000/spark_warehouse
注意,如果你在load数据的时候,需要将数据放到HDFS上。
2、外部Hive(这里主要使用这个方法)
需要将hive-site.xml 拷贝到spark的conf目录下。
如果hive的metestore使用的是mysql数据库,那么需要将mysql的jdbc驱动包放到spark的jars目录下。
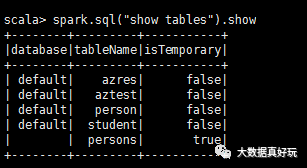
可以通过spark-sql或者spark-shell来进行sql的查询。完成和hive的连接。

这就是hive里面的表
六、Spark SQL的数据源
1、输入
对于Spark SQL的输入需要使用sparkSession.read方法
通用模式 sparkSession.read.format(“json”).load(“path”) 支持类型:parquet、json、text、csv、orc、jdbc
专业模式 sparkSession.read.json、 csv 直接指定类型。
2、输出
对于Spark SQL的输出需要使用 sparkSession.write方法
通用模式 dataFrame.write.format(“json”).save(“path”) 支持类型:parquet、json、text、csv、orc
专业模式 dataFrame.write.csv(“path”) 直接指定类型
如果你使用通用模式,spark默认parquet是默认格式、sparkSession.read.load 加载的默认是parquet格式dataFrame.write.save也是默认保存成parquet格式。
如果需要保存成一个text文件,那么需要dataFrame里面只有一列(只需要一列即可)。
七、Spark SQL实战
1、数据说明
这里有三个数据集,合起来大概有几十万条数据,是关于货品交易的数据集。

2、任务
这里有三个需求:
计算所有订单中每年的销售单数、销售总额
计算所有订单每年最大金额订单的销售额
计算所有订单中每年最畅销货品
3、步骤
1. 加载数据
tbStock.txt
#代码case class tbStock(ordernumber:String,locationid:String,dateid:String) extends Serializable
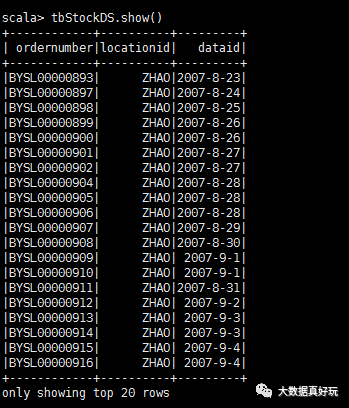
val tbStockRdd=spark.sparkContext.textFile(“file:///root/dataset/tbStock.txt”)
val tbStockDS=tbStockRdd.map(_.split(“,”)).map(attr=》tbStock(attr(0),attr(1),attr(2))).toDS
tbStockDS.show()



tbStockDetail.txt
case class tbStockDetail(ordernumber:String,rownum:Int,itemid:String,number:Int,price:Double,amount:Double) extends Serializable
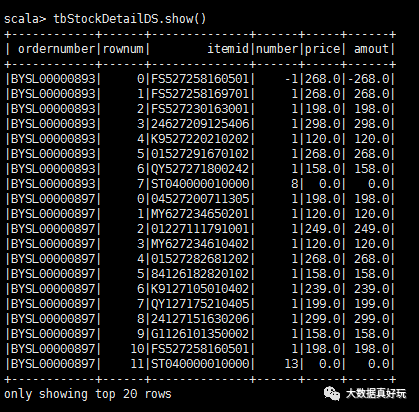
val tbStockDetailRdd=spark.sparkContext.textFile(“file:///root/dataset/tbStockDetail.txt”)
val tbStockDetailDS=tbStockDetailRdd.map(_.split(“,”)).map(attr=》tbStockDetail(attr(0),attr(1).trim().toInt,attr(2),attr(3).trim().toInt,attr(4).trim().toDouble,attr(5).trim().toDouble)).toDS
tbStockDetailDS.show()



tbDate.txt
case class tbDate(dateid:String,years:Int,theyear:Int,month:Int,day:Int,weekday:Int,week:Int,quarter:Int,period:Int,halfmonth:Int) extends Serializable
val tbDateRdd=spark.sparkContext.textFile(“file:///root/dataset/tbDate.txt”)
val tbDateDS=tbDateRdd.map(_.split(“,”)).map(attr=》tbDate(attr(0),attr(1).trim().toInt,attr(2).trim().toInt,attr(3).trim().toInt,attr(4).trim().toInt,attr(5).trim().toInt,attr(6).trim().toInt,attr(7).trim().toInt,attr(8).trim().toInt,attr(9).trim().toInt)).toDS
tbDateDS.show()



2. 注册表
tbStockDS.createOrReplaceTempView(“tbStock”)
tbDateDS.createOrReplaceTempView(“tbDate”)
tbStockDetailDS.createOrReplaceTempView(“tbStockDetail”)

3. 解析表
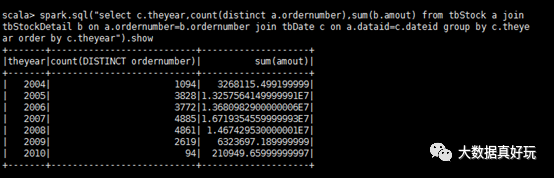
计算所有订单中每年的销售单数、销售总额
#sql语句
select c.theyear,count(distinct a.ordernumber),sum(b.amount)
from tbStock a
join tbStockDetail b on a.ordernumber=b.ordernumber
join tbDate c on a.dateid=c.dateid
group by c.theyear
order by c.theyear
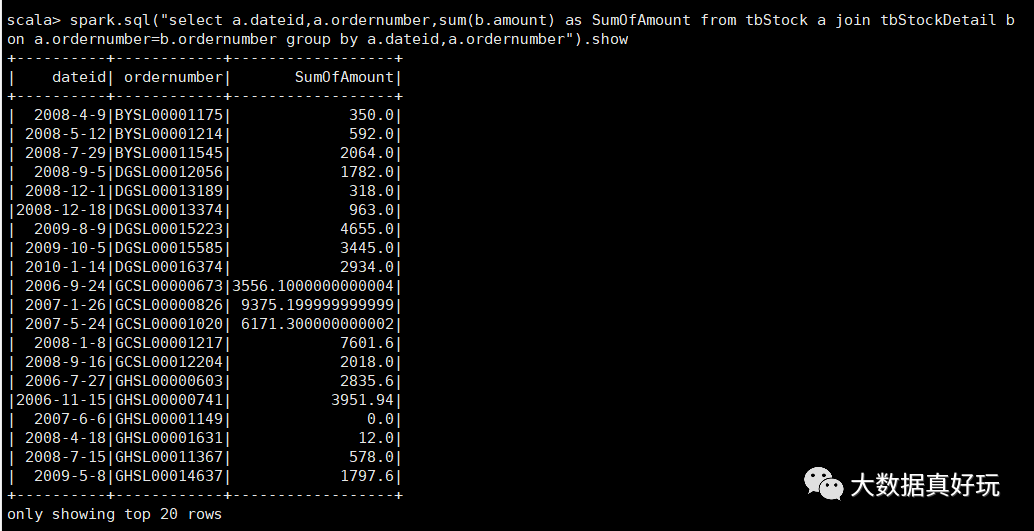
计算所有订单每年最大金额订单的销售额
a、先统计每年每个订单的销售额
select a.dateid,a.ordernumber,sum(b.amount) as SumOfAmount
from tbStock a
join tbStockDetail b on a.ordernumber=b.ordernumber
group by a.dateid,a.ordernumber
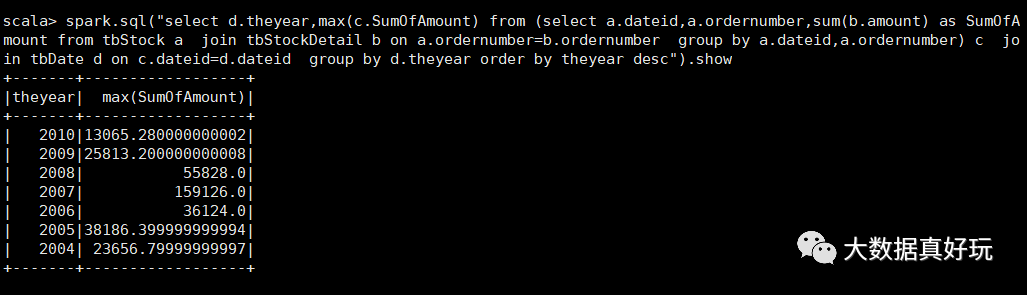
b、计算最大金额订单的销售额
select d.theyear,c.SumOfAmount as SumOfAmount
from
(select a.dateid,a.ordernumber,sum(b.amount) as SumOfAmount
from tbStock a
join tbStockDetail b on a.ordernumber=b.ordernumber
group by a.dateid,a.ordernumber) c
join tbDate d on c.dateid=d.dateid
group by d.theyear
order by theyear desc
计算所有订单中每年最畅销货品
a、求出每年每个货品的销售额
select c.theyear,b.itemid,sum(b.amount) as SumOfAmount
from tbStock a
join tbStockDetail b on a.ordernumber=b.ordernumber
join tbDate c on a.dateid=c.dateid
group by c.theyear,b.itemid
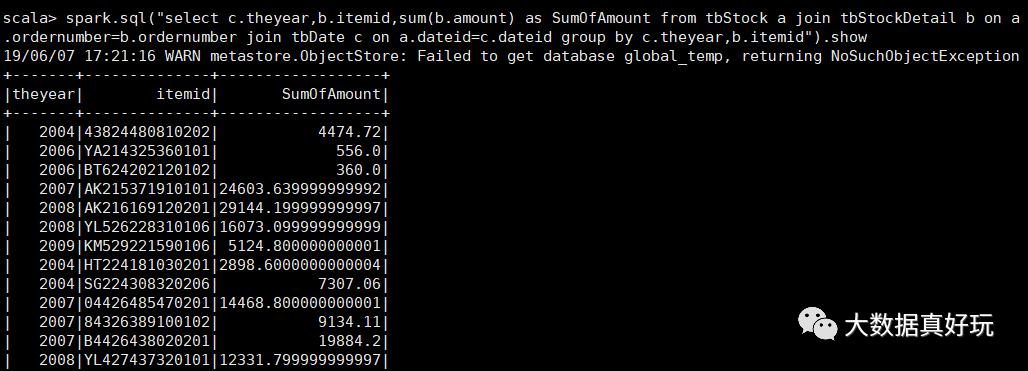
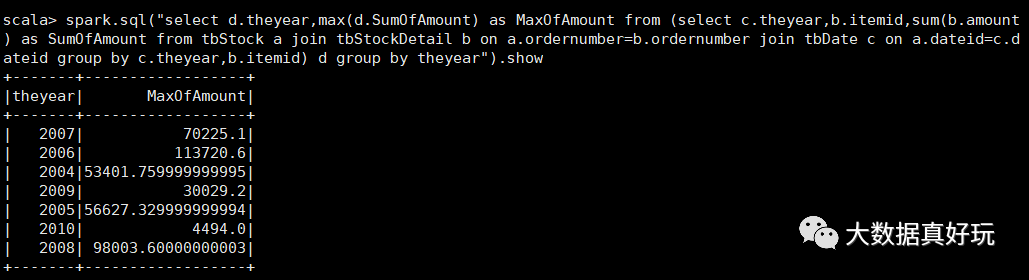
b、在a的基础上,统计每年单个货品的最大金额
select d.theyear,max(d.SumOfAmount) as MaxOfAmount
from
(select c.theyear,b.itemid,sum(b.amount) as SumOfAmount
from tbStock a
join tbStockDetail b on a.ordernumber=b.ordernumber
join tbDate c on a.dateid=c.dateid
group by c.theyear,b.itemid) d
group by theyear
c、用最大销售额和统计好的每个货品的销售额join,以及用年join,集合得到最畅销货品那一行信息
select distinct e.theyear,e.itemid,f.maxofamount
from
(select c.theyear,b.itemid,sum(b.amount) as sumofamount
from tbStock a
join tbStockDetail b on a.ordernumber=b.ordernumber
join tbDate c on a.dateid=c.dateid
group by c.theyear,b.itemid) e
join
(select d.theyear,max(d.sumofamount) as maxofamount
from
(select c.theyear,b.itemid,sum(b.amount) as sumofamount
from tbStock a
join tbStockDetail b on a.ordernumber=b.ordernumber
join tbDate c on a.dateid=c.dateid
group by c.theyear,b.itemid) d
group by d.theyear) f on e.theyear=f.theyear
and e.sumofamount=f.maxofamount order by e.theyear

编辑:jq
-
谐波的概念及应用2024-10-18 3073
-
S参数的概念及应用2024-08-12 700
-
Spark基于DPU Snappy压缩算法的异构加速方案2024-03-26 1815
-
基于DPU和HADOS-RACE加速Spark 3.x2024-03-25 2315
-
SQL改写消除相关子查询实践2023-12-27 1524
-
oracle执行sql查询语句的步骤是什么2023-12-06 2182
-
一文终结SQL子查询优化2023-04-28 1711
-
嵌入式系统的概念及特点2021-12-22 1773
-
SQL子查询优化是怎么回事2021-02-01 3008
-
源码Spark SQL的分区特性2020-04-28 1777
-
SQL构造查询的方式详细概述2020-04-12 3128
-
Spark SQL的工作原理和性能优化2019-06-12 1178
-
Spark SQL讲解2018-04-17 836
-
基于KingView的SQL数据查询设计_杨洋2017-01-17 965
全部0条评论

快来发表一下你的评论吧 !
