

对DDR3/4控制器进行探讨
描述
参考资料
《pg150-ultrascale-memory-ip》
以该手册的脉络为主线,对DDR3/4控制器进行探讨。
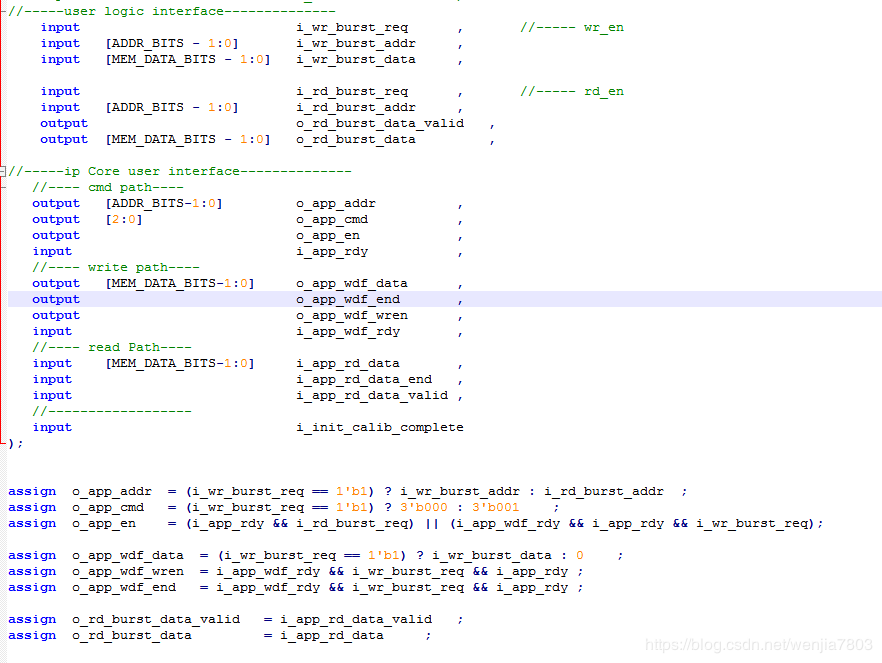
1.IP核结构
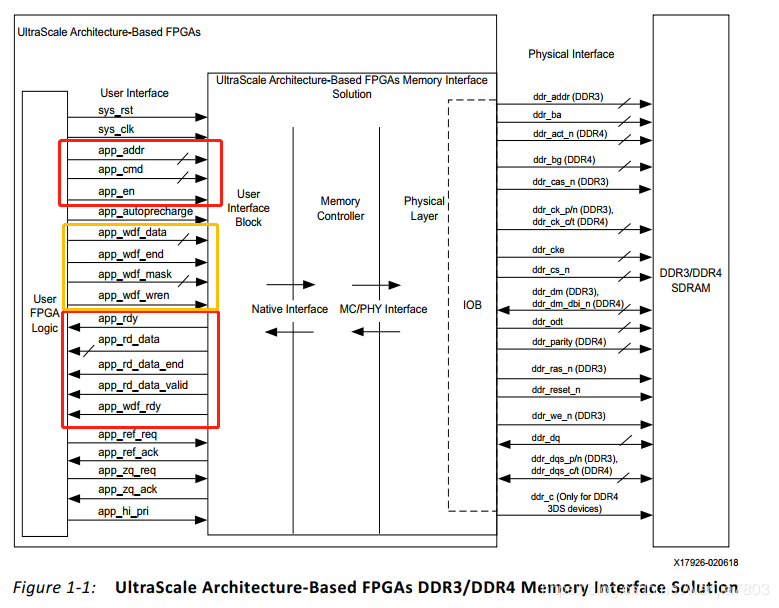
根据官方提供的资料,IP核主要划分为三个部分,分别是用户接口,内存控制器以及物理层接口。对于用户来说,我们需要研究清楚的是用户接口部分内容,其余两部分只需了解即可,这里就不展开论述。
读写效率
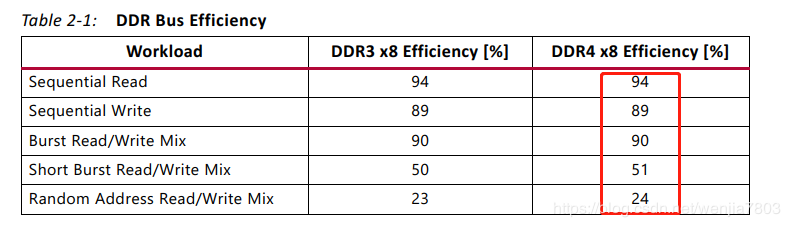
X8是表示,该内存颗粒的数据总线为8bit。常见的还有x4/x16。
2.读写时序userinterface操作
整个DDR的IP核应用,主要都是围绕这以下几个路径进行,开发者直接打交道的是IP_core的userinterface。其他物理底层的内容,由IP自行完成。主要指令路径包括:Command Path、write_Path、read_Path以及维护指令(Maintenance Commands)。
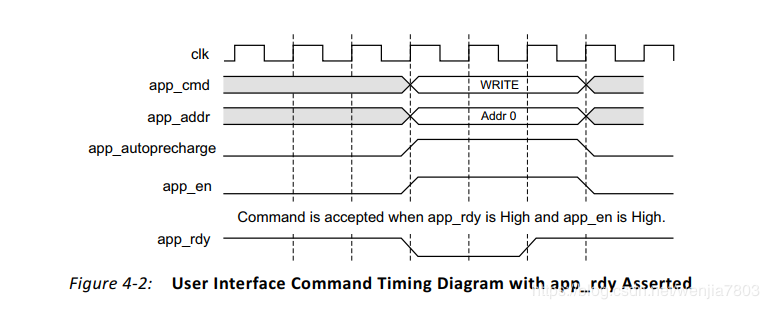
Command Path
顾名思义,就是读写操作指令写入的路径。当app_rdy与app_en都有效的时候,新的指令才能写入命令FIFO里,并被执行。
Write Path
数据内容写入IP核的路径。
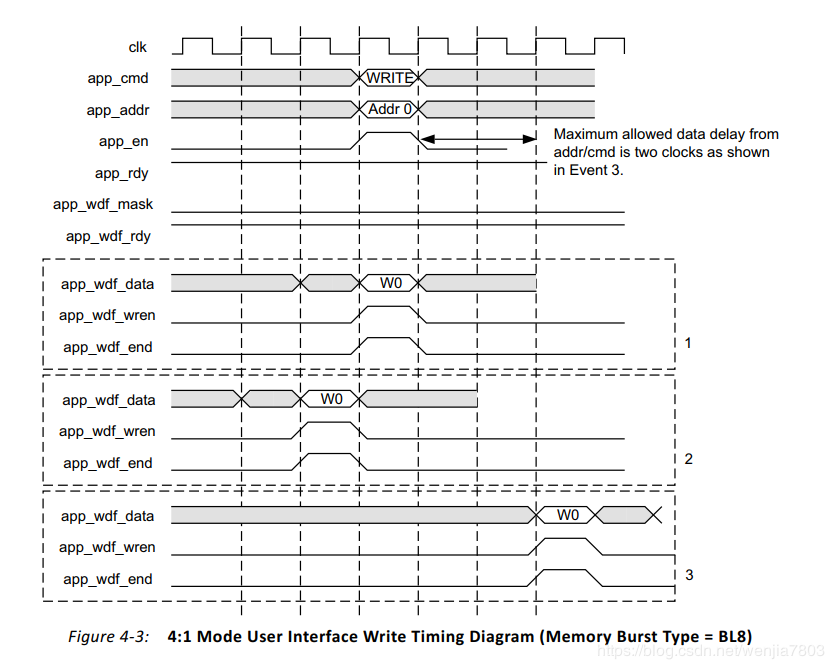
从上述的时序图看来,与写入路径相关的信号有app_adf_data、app_wdf_wren以及app_wdf_end。虽然说,写入的数据路径与指令路径可以不对齐,但实际应用过程中,建议还是对齐操作,要不然容易出问题(后续调试测试的内容有提到)。
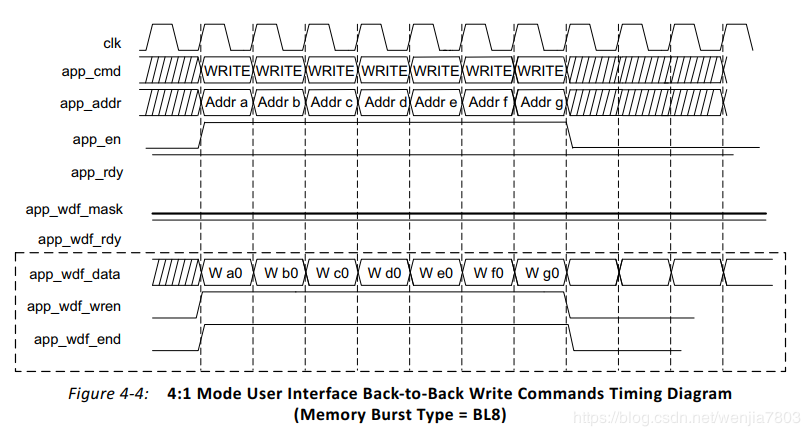
pp_wdf_end为高,表示该数据这次写入请求的最后一个数。以上图为例,4:1mode是指用户接口时钟与物理层驱动DDR的时钟之比为1:4。比如用户接口的数据总线为64bit,物理层驱动DDR芯片位宽为8bit ,BL=8, 在4:1mode下,那么正好一个用户clk可以执行完一次突发传输(DDR是在时钟上升沿和下降沿都传输数据)。所以在执行传输的过程中,app_wdf_end为高。
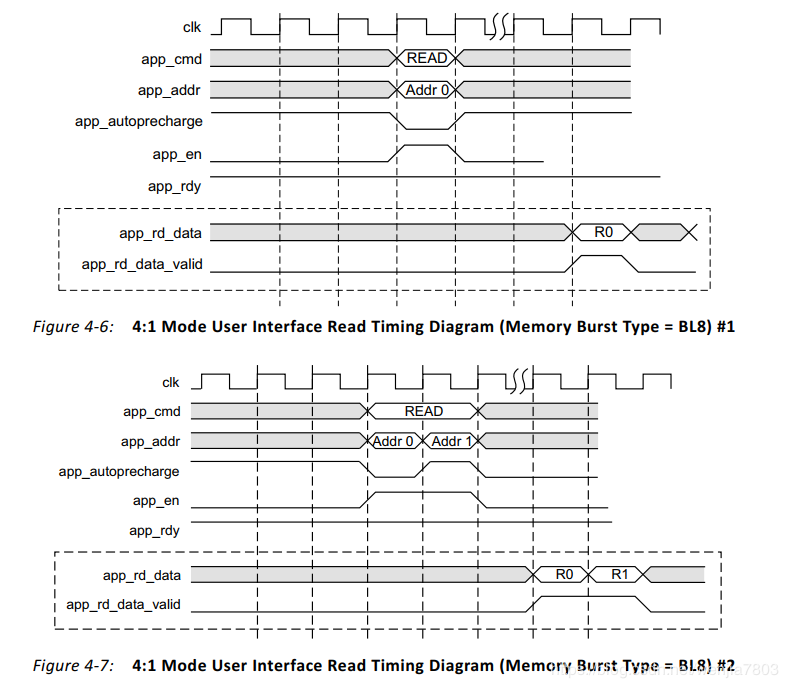
Read Path
数据从IP核中读出来的路径。
Maintenance Commands(维护指令)
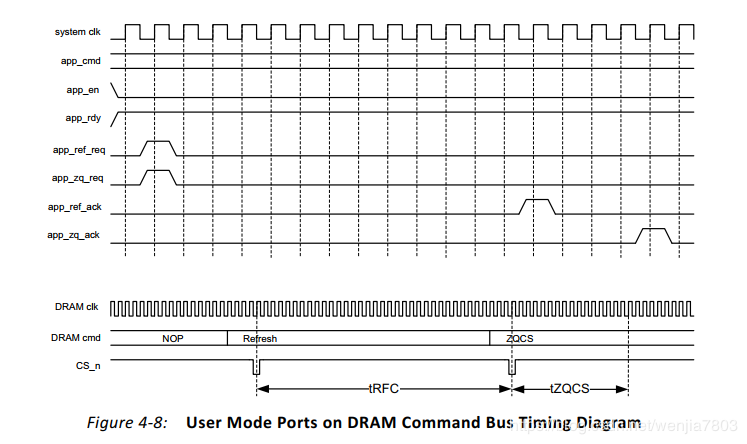
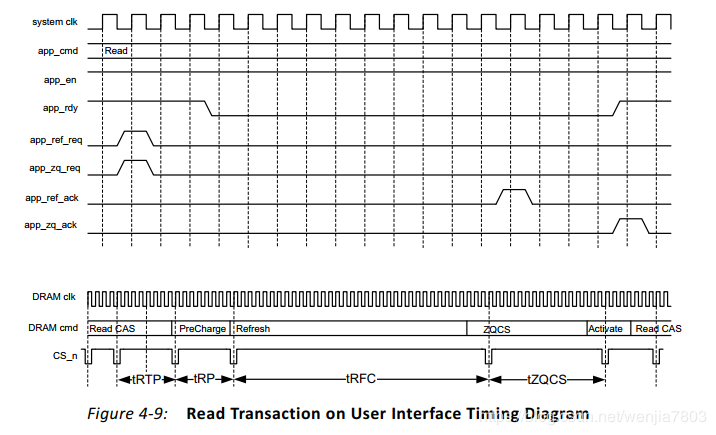
这里可以解析为什么读写效率不能够达到百分百,由于ddr需要刷新等导致。其中启动刷新有两种模式,一种是自动刷新,即IP核自己产生满足时序的刷新请求,另外一种是通过选中“启用用户刷新和ZQCS输入”选项来启用用户模式。在此模式下,当init_calib_complete有效之后,由用户负责发出Refresh和ZQCS命令以满足DRAM组件规范所要求的速率。ZQCS是用于ZQ 校准,这个与ODT相关。
扩展一下:
ODT(On-Die Termination),是从DDR2 SDRAM时代开始新增的功能。其允许用户通过读写MR1寄存器,来控制DDR3 SDRAM中内部的终端电阻的连接或者断开。
为什么要用ODT?一个DDR通道,通常会挂接多个Rank,这些Rank的数据线、地址线等等都是共用;数据信号也就依次传递到每个Rank,到达线路末端的时候,波形会有反射,从而影响到原始信号;因此需要加上终端电阻,吸收余波。之前的DDR,终端电阻做在板子上,但是因为种种原因,效果不是太好,到了DDR2,把终端电阻做到了DDR颗粒内部,也就称为On Die Termination,Die上的终端电阻,Die是硅片的意思,这里也就是DDR颗粒。
所以,使用ODT的目的很简单,是为了让DQS、RDQS、DQ和DM信号在终结电阻处消耗完,防止这些信号在电路上形成反射,进而增强信号完整性。
3.对IP核进行二次封装
建议对IP核的User_interface再封装一层,对外只需预留例如wr_en/wr_data以及rd_en/rd_data等信号,类似于读写FIFO的端口,提高模块的后期复用。
4.调试与测试记录
手册梳理得差不多了,写个简单的程序仿真测试。期间碰到了些问题,分享出来记录一下。
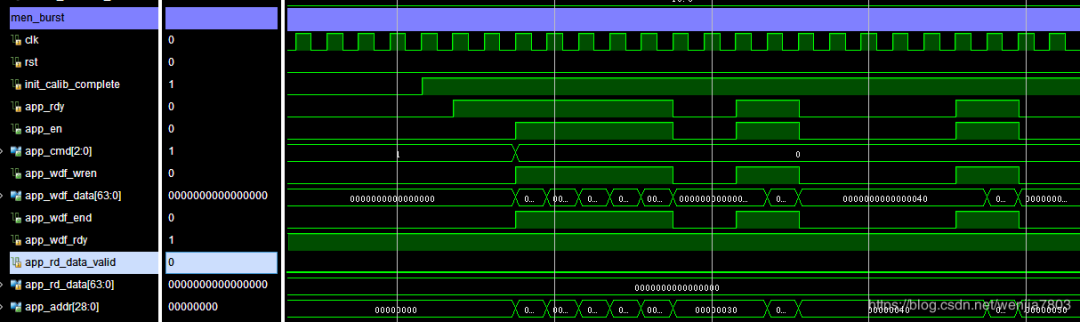
cmd_path与write_path没对齐。
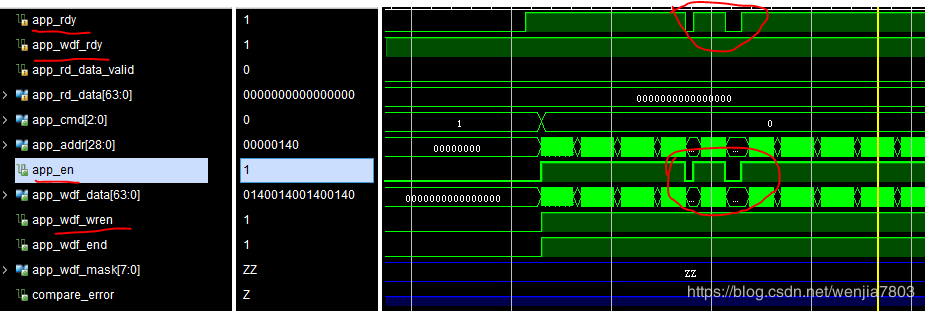
图中所示,app_rdy为低,但是wdf_wren仍然为高,短期的话应该没有什么问题,但是如果持续一段时间,必然会导致IP核中fifo被写满,导致异常。
解决办法:
令指令与数据路径命令对齐。在写入的时候,当app_rdy与app_wdf_rdy都有效的时候,才触发相应的动作。
数据没有写入,导致回读出来的数据不对。
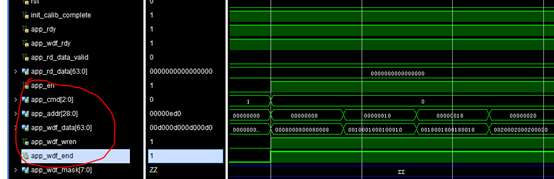
从时序上来看,写入没有问题。但是我当初忽略了app_wdf_mask,这个没有赋值(正常应该赋0),导致仿真的时候,该信号一致显示高阻态。然后发现ddr4_dm_dbi_n(双向信号)信号异常。
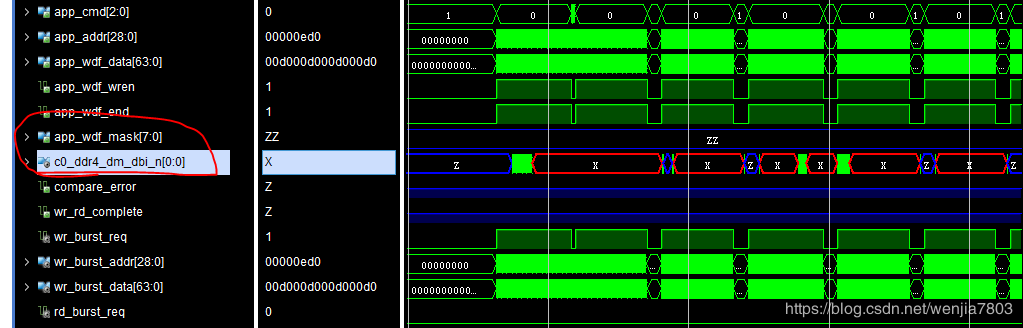
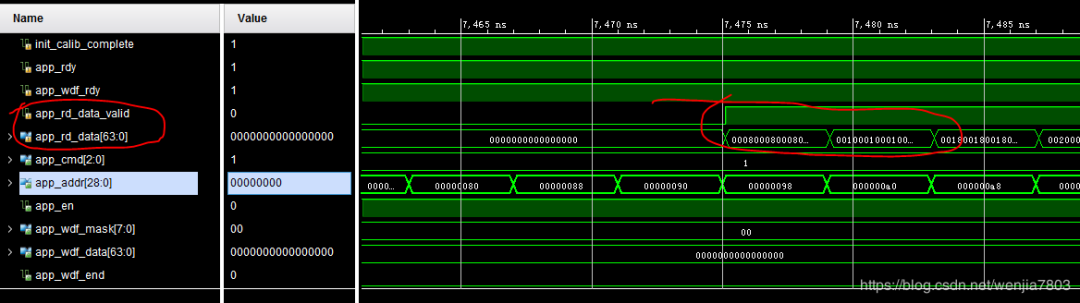
读出来的数据一直是0.
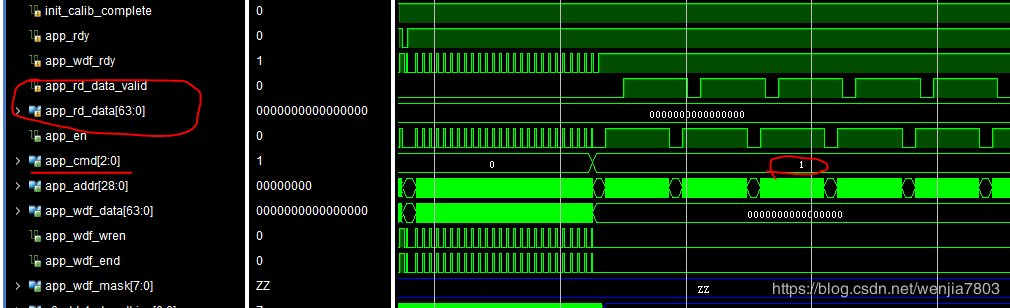
修改过来后,问题解决。
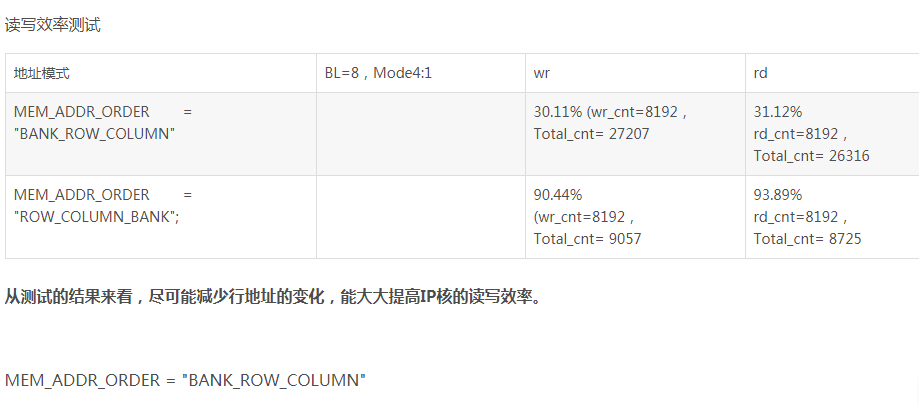
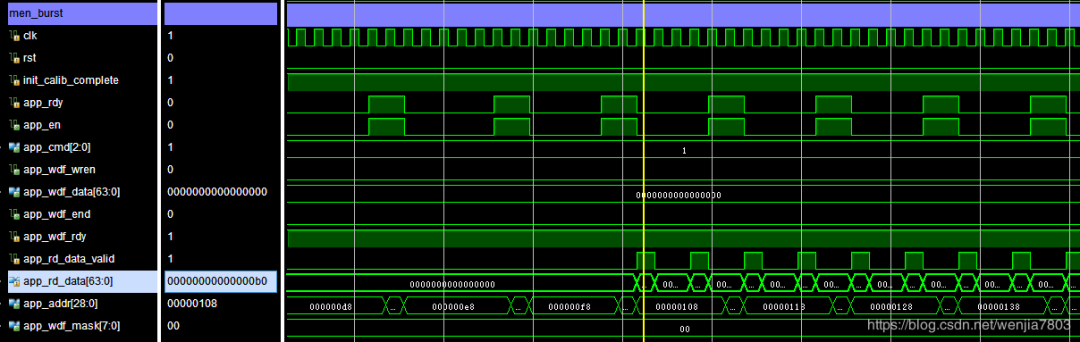
读写效率测试
Wr:
Rd:
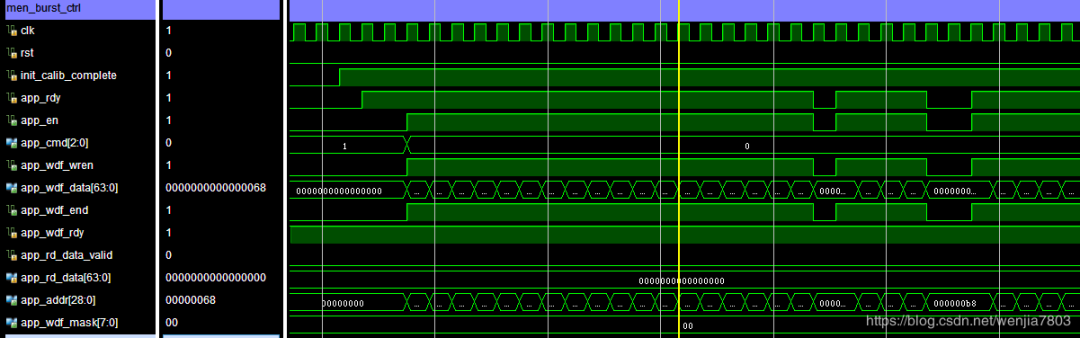
MEM_ADDR_ORDER = "ROW_COLUMN_BANK";
Wr:
Rd:
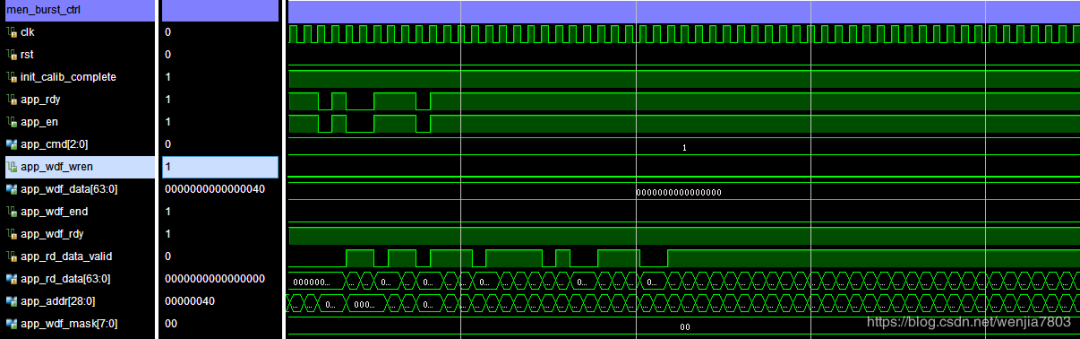
仔细的话,可以观察clk与app_rdy之间的关系,不难发现为什么两者的读写效率会相差这么大。不同的地址排列,在每次读写过程中,IP的效率有很大的关系,这个与DDR的实现机制有关。详细情况在PG150里有相关说明。
编辑:jq
-
如何提高DDR3的效率2015-08-27 9488
-
求verilog HDL编写的DDR3控制器2015-11-16 7381
-
基于FPGA的DDR3 SDRAM控制器的设计与优化2018-08-02 5136
-
DDR3存储器接口控制器IP助力数据处理应用2019-05-24 2360
-
如何用中档FPGA实现高速DDR3存储器控制器?2019-08-09 3403
-
基于Stratix III的DDR3 SDRAM控制器设计2010-07-30 888
-
基于协议控制器的DDR3访存控制器的设计及优化2017-01-07 1240
-
ddr4和ddr3内存的区别,可以通用吗2017-11-08 32706
-
基于FPGA的DDR3 SDRAM控制器用户接口设计2017-11-17 4242
-
一文探讨DDR3内存的具体特性和功能2021-02-09 15193
-
【紫光同创国产FPGA教程】【第十章】DDR3读写测试实验2021-02-05 11576
-
基于FPGA的DDR3读写测试2023-09-01 3884
-
DDR4和DDR3内存都有哪些区别?2023-10-30 15194
-
完整的DDR、DDR2和DDR3内存电源解决方案同步降压控制器数据表2024-03-13 600
-
全套DDR、DDR2、DDR3、DDR3L、LPDDR3 和 DDR4 电源解决方案同步降压控制器数据表2024-04-09 856
全部0条评论

快来发表一下你的评论吧 !
