

让C++代码更加高效的几个小技巧
电子说
描述
今天和大家介绍一下能让C++代码更加高效的几个小技巧,话不多说,以下为本文目录:
参数传递方式:值传递还是引用传递
函数返回方式:按值返回还是按引用返回
使用移动语义
避免创建临时对象
了解返回值优化
考虑预分配内存
考虑内联
迭代 vs 递归
选择高效的算法
利用缓存
profiling
other碎碎念
以下为正文:
值传递还是引用传递:
一般情况下使用const的引用参数。对于函数本身会拷贝的参数,最好使用值传递,但只有当参数的类型支持移动语义时才这样。
在某些情况下,值传递并移动实际上是向函数传递参数的最佳方式(注意看后面的tips),例如:
class A { public: A(const std::string &str) { str_ = str; }
private: std::string str_;};
可以考虑改为这种形式:
class A { public: A(std::string str) { str_ = std::move(str); }
private: std::string str_;};
因为无论如何都会对它们进行拷贝。
tips:看有些资料说后者值传递是更好的参数传递方式,貌似有些道理,但是我没找到非常合理的理由,有知道的读者可以在评论区留言。
按值返回还是按引用返回:
可以通过从函数中按引用方式返回对象,以避免对象发生不必要的复制。但有时不可能通过引用返回对象,例如编写重载的operator+和其他类似运算符时。
永远都不要返回指向局部对象的引用或指针,局部对象会在函数退出时被销毁。
但是,按值返回对象通常没啥大问题。因为一般情况下他们会触发返回值优化或移动语义,即不会有多余的拷贝动作。
使用移动语义:
尽量确保对象拥有移动构造函数和移动赋值运算符。对象有了移动语义后,许多操作都会更加高效,特别是与标准库和算法相结合时。
避免创建临时对象:
没有必要的临时对象能避免就避免。一般来说,应该避免迫使编译器构造临时对象的情况。尽管有时这是不可避免的,但是至少应该意识到这项“特性”的存在,这样才不会为实际性能和分析结果而感到惊讶。编译器还会使用移动语义使临时对象的效率更高。这是要在类中添加移动语义的另一个原因。
《More Effective C++》第19条款中介绍过:所谓的临时对象并不是程序员创建的用于存储临时值的对象,而是指编译器层面上的临时对象:这种临时对象不是由程序员创建,而是由编译器为了实现某些功能(例如函数返回,类型转换等)而创建。
比如下面的代码就会有临时对象的产生:
void Func(const std::string& s);char arr[]=“hello”;Func(aar); // here
返回值优化
通过值返回对象的函数可能导致创建一个临时对象。看下面的代码:
Person createPerson(){ Person newP { “Marc”, “Gregoire”, 42 }; return newP;}
假如像这样调用这个函数(假设Person 类已经实现了operator《《运算符):
cout 《《 createPerson();
即便这个调用没有将createPerson()的结果保存在任何地方,也必须将结果保存在某个地方,才能传递给operator《《。为此编译器创建一个临时变量,来保存createPerson()返回的Person 对象。
即使这个函数的结果没有在任何地方使用,编译器也仍然可能会生成创建临时对象的代码:
createPerson();
编译器可能生成代码来创建一个临时对象来保存返回值,即使这个返回值没有使用也是如此。
不过吧,编译器会在大多数情况下优化掉临时变量,以避免复制和移动。
关于返回值优化我之前有篇文章介绍过,感兴趣的可以看看这个:《左值引用、右值引用、移动语义、完美转发,你知道的不知道的都在这里》
预分配内存:
比如标准化容器中的reserve,需要频繁创建内存的地方可以考虑预分配一块内存出来,避免频繁的创建内存。
内联函数:
短函数可以使用内联消除函数开销。
迭代 vs 递归:
这里我更倾向于选择迭代方式,而不是递归。递归占用大量栈内存,且可能会产生很多不必要的临时对象构建。
选择效率更高的算法:
学计算机的估计没有不知道算法的吧,学算法估计没有人不知道如何计算时间复杂度和空间复杂度吧,在平时开发过程中遇到算法问题时我们可尽量选择效率更高的算法,比如O(N)和O(N2)的算法,我们肯定要选择O(N)的呀,这里可以了解下C++的,这里引入了很多高效的算法供我们使用。
尽可能多的使用缓存:
将某些数据保存下来供下次使用,避免再次获取或重新计算它们。如果任务或计算特别慢,应该保证不执行那些没有必要的任务或者重复计算。
网络通信:如果频繁发起相同的网络请求,可考虑将第一次的网络请求结果保存在内存中,或文件中?
磁盘访问:如果频繁访问一个文件,可考虑将这个文件的内容保存在内存中。
数学计算:某些很耗时很复杂的运算,可考虑只执行这种计算一次,然后共享结果。
对象分配:如果需要大量频繁创建和销毁短期对象,可考虑使用对象池。
线程创建:如果需要大量频繁创建和销毁线程,可考虑使用线程池。
做客户端开发的朋友应该都听说多级缓存的概念,就是这个原理。
profiling:
那到底什么样的代码才算是高质量代码呢?
对此我整理了一份脑图:
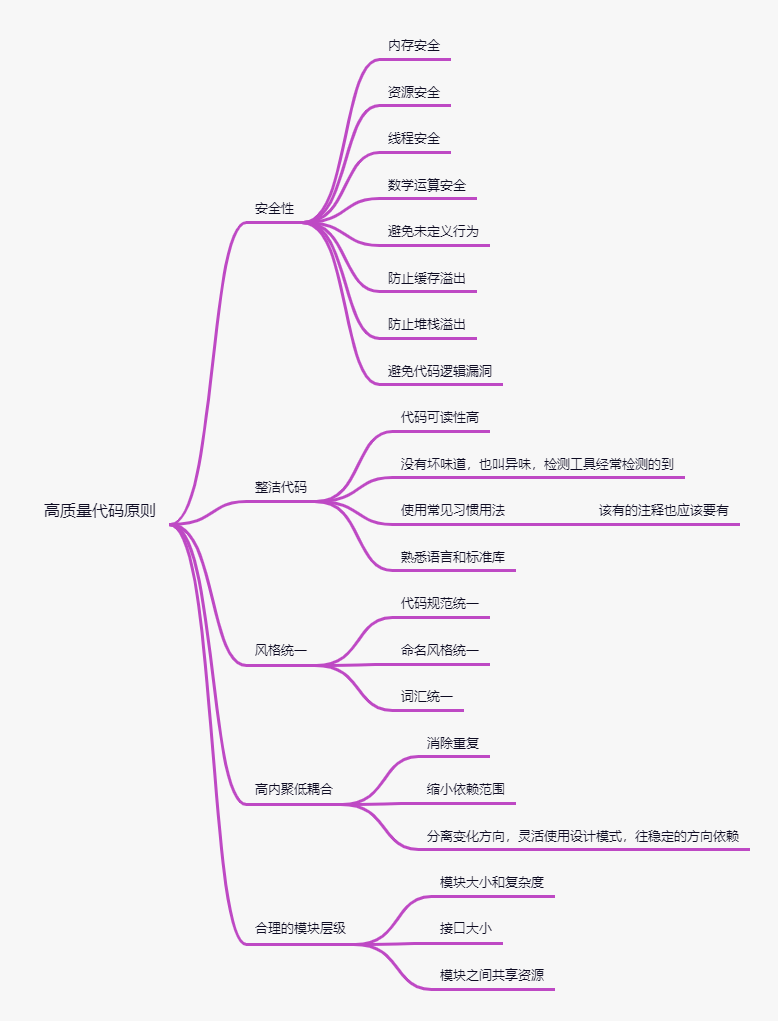
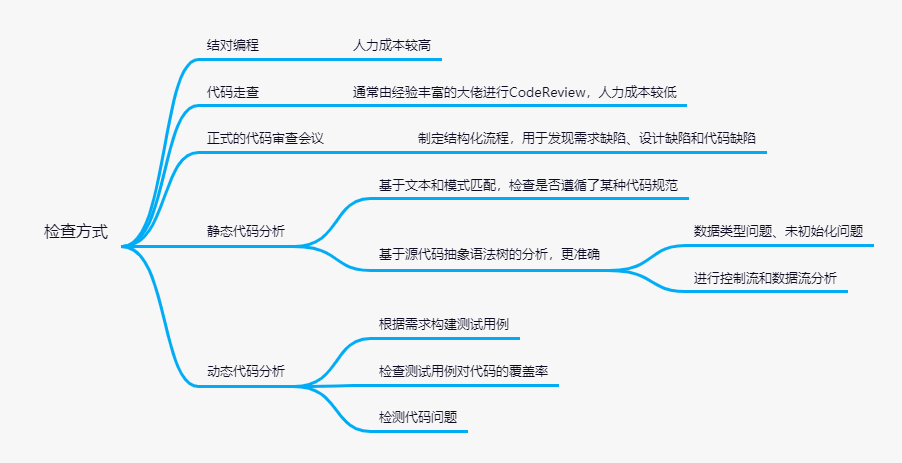
如何能够提升代码质量呢,除了我们自身过硬的编码能力,还需要制定代码检查流程,一般代码检查有以下几种方式:
代码检查要检查的问题有:
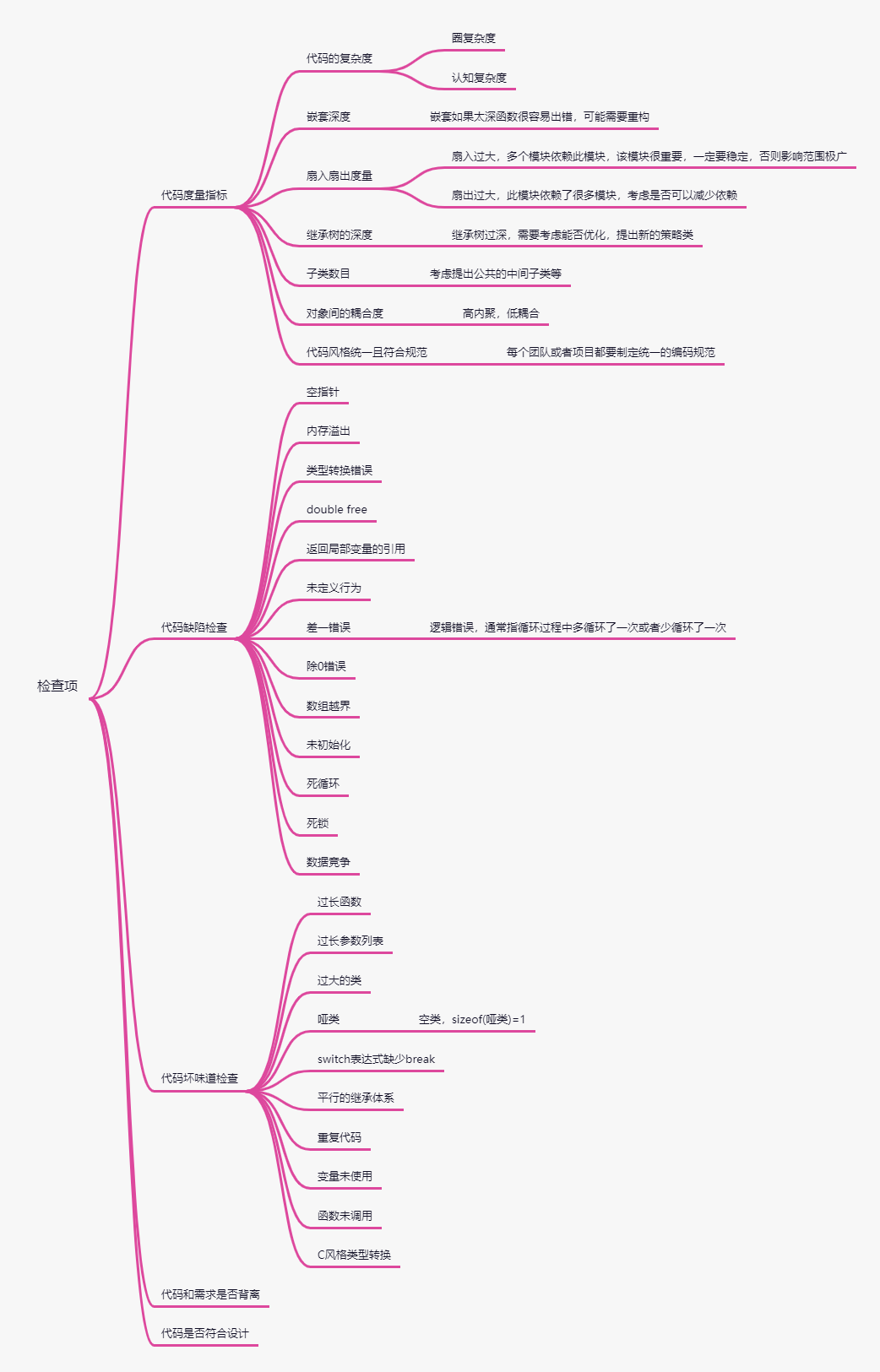
脑图中有一些代码度量指标,它用于量化代码质量:
如果代码的圈复杂度或认知复杂度过大,可能函数本身实现的过于复杂,或可能因为架构设计过于复杂,导致函数过于复杂。
如果函数嵌套过深,说明函数很可能出错,需要仔细进⾏⼈⼯评审,并且函数可能需要重构。
如果模块的扇入过大,说明模块可能是公共模块,需要⼈⼯评审接⼝是否是稳定的,或模块承担过多职责,可以考虑遵循单⼀职责,分解模块的职责。
如果模块的扇出过大,说明该模块依赖多个模块,可以考虑把被依赖的多个模块合并为⼀个模块,重构依赖的接⼝。
如果类的继承树过深,考虑在继承树的深度上是否有新的变化⽅向,考虑提出新的策略类,或其他设计模式来优化继承树。
如果子类过多,检查⼦类的实现中共同的地⽅,先考虑提出公共的中间⼦类,检查是否可以通过桥接模式、装饰模式、组合模式等结构型模式重构代码。
上面脑图所说的需要检查的各种问题中,代码和需求背离问题与代码是否符合设计问题需要人工评审,成本较高,其它问题可以通过工具来检测。
检测工具主要分为静态代码分析工具和动态代码检测工具。
静态代码分析工具主要用于静态代码分析,关于静态代码分析,它能够根据规则帮助检查代码缺陷,然而,对于检查规则能够覆盖的代码,工具能够工作的挺好,但对于规则没有覆盖的代码,它却无能为力,而且可能存在误报问题。
静态代码分析是保证代码质量的重要手段,据说软件开发中大概30%-70%的代码逻辑设计和编码缺陷都可以通过静态代码分析来发现和修复。它会扫描程序代码,找出代码中隐藏的错误,如参数不匹配、有歧义的嵌套语句、错误的递归、非法计算、空指针问题、越界问题、未初始化问题、内存泄漏问题等。
静态代码分析工具的优势有:
自动执行静态代码分析,快速定位代码隐藏错误和缺陷
帮助代码设计人员更专注于分析和解决代码设计缺陷
减少在代码人工检查上花费的时间,提高软件可靠性并节省开发成本
举例如下:
代码规范检查:由于拷贝粘贴造成两个分支的代码完全相同
void func(int in, int &out) { if (in 》 1) out++; else out++; out++;}
代码缺陷检查:没有用的RAII
void func() { std::lock_guard《std::mutex》(lk); // 临时对象,语句结束后执行析构,误用的加锁 。..}
下面是一些常见的静态代码分析工具:
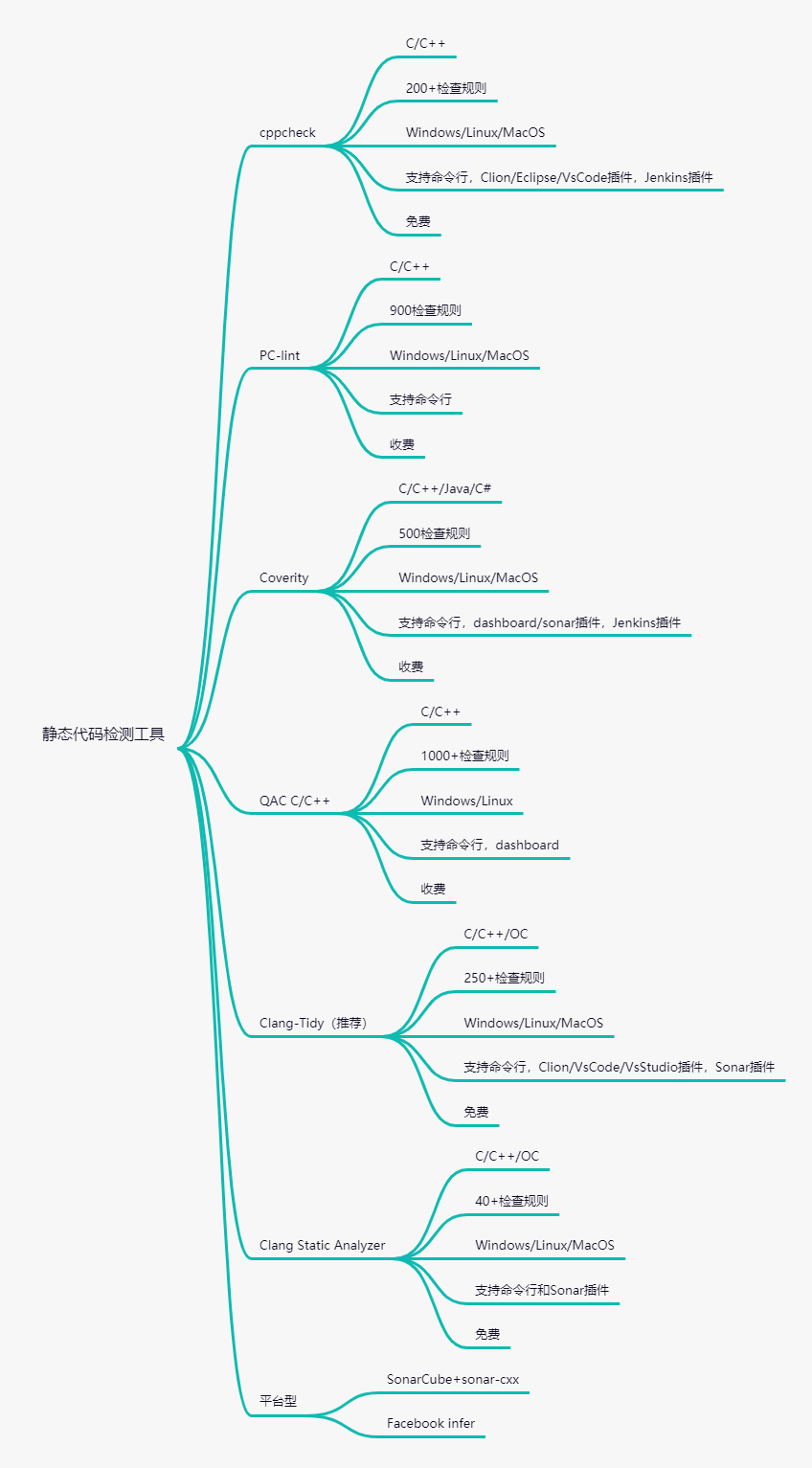
这里推荐一个常用的代码质量管理平台SonarCube,SonarQube是一个管理代码质量的平台(社区版免费),用于管理代码的质量,它会从多个角度维护检测代码质量,通过插件形式支持多种语言的代码质量管理和检测。它可以安装sonar-cxx插件,内置了一系列C/C++代码检查工具,还可以应用在CI/CD流程中,和Jenkins打通,可以在提交代码后检查代码是否有坏味道,不符合规范的代码就拒绝被合入master。
还有一个很好用的静态代码检测工具是Facebook的infer,它最大的优势是可以静态检测代码内隐藏的内存泄漏问题,而且免费支持Android、C、OC语言。
静态代码分析工具可以在运行前帮助我们检测缺陷,只有30%-70%,但不是所有缺陷,很多缺陷需要在运行时才会被发现。
其实我们还可以使用一些动态分析工具,通过动态分析工具可以准确定位问题,而且误报率低,但这与测试用例强绑定,查找缺陷的比例与测试用例的覆盖率有关,覆盖率对于衡量代码质量有很大意义。
代码覆盖率的意义:
● 帮助我们找到未覆盖部分的代码,分析测试用例设计的是否充分,之后视情况决定是否可以补充测试用例。
● 检测出代码的坏味道,提示我们修改代码,理清代码逻辑关系,提升代码质量。
● 代码覆盖率高不能代表代码质量一定好,但代码覆盖率低,代码质量估计不会高到哪去,可以作为我们衡量代码质量的重要手段之一。
● 对于没有覆盖到的错误,动态分析工具也无能为力。在实际工作中,我们可以动静结合,多种检查手段全都用上,可以更有效的提升代码质量。
动态分析工具可以在程序运行时发现代码的缺陷,例如内存问题、数据竞争、未定义行为等。
常用工具有GCC&Clang的Santizer系列:
● Asan-Address Sanitizer:缓存区溢出,内存泄漏
● Tsan-Thread Sanitizer:并发问题
● Msan-Memory Sanitizer:未初始化内存
● Ubsan-Undefined Behavior Sanitizer:未定义行为
● 编译选项添加fsanitize=address/memory/thread/undefined
还有Valgrind工具:
● memchek:内存问题,包括Asan和Msan
● helgrind:线程和并发问题
● cachegrind、callgrind、massif:帮助进行性能优化
使用各种工具与单元测试、功能测试、系统测试结合,提高覆盖率,可以帮助我们发现更多缺陷。
前面的多数都是代码分析工具,下面介绍一些性能分析工具,关于性能分析工具Brendan Gregg大佬的网站介绍的很详细,这里贴出来一张他总结的工具图:
这张图从Linux内核的各个子系统出发,汇总了对各个子系统进行性能分析时可以选择的工具。其实还有一些好用的工具,图里没有提到,这里重点介绍一下:
gprof:gprof是GNU工具之一,编译的时候,它在每个函数的出入口加入了profiling的代码,运行时统计程序在用户态的执行信息,可以得到每个函数的调用次数,执行时间,调用关系等信息,简单易懂。适合于查找用户级程序的性能瓶颈,然而对于很多耗时在内核态执行的程序,gprof不适合。
Oprofile:Oprofile也是一个开源的profiling工具,它使用硬件调试寄存器来统计信息,进行profiling的开销比较小,而且可以对内核进行profiling。它统计的信息非常多,可以得到cache的缺失率,memory的访存信息,分支预测错误率等等,这些信息gprof得不到,但是对于函数调用次数,它无能为力。
简单来说,gprof简单,适合于查找用户级程序的瓶颈,而Oprofile稍微有点复杂,但是得到的信息更多,更适合调试系统软件。
gperftools:Google出品,值得信赖,提供整个程序的热点分布图,找到性能瓶颈,然后可以针对性的进行性能优化,如图:
那使用什么API效率更高呢,可以看下图:
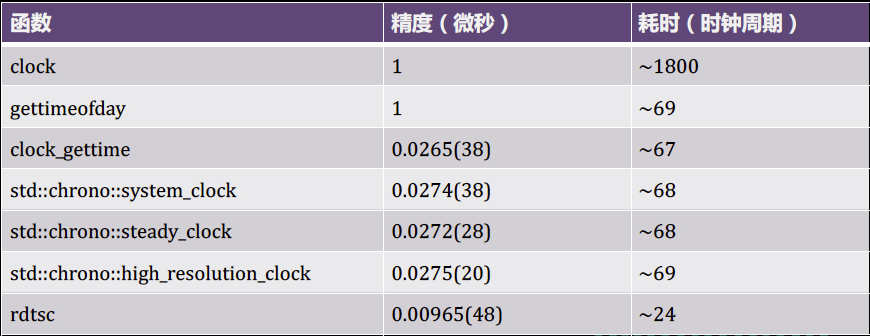
图中的rdtsc使用较繁琐而且不适用于所有平台和编译器,剩下的大家可以按需使用哈。
关于性能分析工具,程序喵整理了一份非常详细的脑图(精华全在脑图里),以性能指标分类,不同指标使用什么工具进行分析,都在图里,目录如下:
other碎碎念:
选择合适的数据结构:
选择合适的STL,想清楚什么时候用栈,什么时候用队列,什么时候用数组,什么时候用链表。
某些if-else可改为switch,效率可能更高(知道为什么吗,不知道的可以留言,人多的话考虑输出一篇文章)。
优先考虑栈内存,而不是堆内存(免得频繁的申请释放内存)。
如何函数不需要返回值,就不要设置返回值。
使用位操作,移位代替乘法除法操作。
构造函数时使用初始化方式,而不是赋值。
A::A() : a_(a) {} // better
A::A() { a_ = a;}
明确使用模板带来的益处:
如果使用模板并没有给你的开发带来任何益处,是不是可以考虑不使用它,因为调试起来真的麻烦。
函数参数的个数不要太多。
擅用emplace,有些情况下会省去一次构造的开销。
最后想说一句:
先完成再完美。不要一开始就想着写最完美的代码,很多bug都是过早过度优化导致的。一般情况下,性能较高的代码可读性都不是特别高。提早优化很可能引发很多bug。很多情况下,我们可以先完成代码,确保功能完成且正确之后,再去考虑完善。完成代码后,可以使用profiling工具,找到瓶颈所在,然后做相应优化。另外产品和测试如果没给你提性能需求,那优化它干嘛!
责任编辑:haq
-
AKI跨语言调用库神助攻C/C++代码迁移至HarmonyOS NEXT2025-01-02 239
-
Google C++编程指南2017-11-29 4894
-
DSP编程技巧之链接汇编代码与C_C++代码2017-10-18 918
-
如何在C++代码中使用C头文件2017-10-19 2997
-
二维码货运标签处理包裹更加高效、更加节省成本2018-05-14 1318
-
自动驾驶警车自动贴罚单,让交警的执法变得更加高效2018-06-11 2000
-
智慧医疗送服务上门,让医疗服务变得更加高效2020-12-28 945
-
C++ Socket网络编程大全源代码下载2021-06-21 1588
-
IAR中使用C++做开发语言,更加简单高效2021-12-03 1433
-
写好C++代码需要遵循的10个最佳实践2022-09-19 1215
-
qt用C++写的2048小游戏源代码2022-09-27 902
-
C++代码需要遵循的10个最佳实践2022-10-18 1657
-
C++之父新作带你勾勒现代C++地图2023-10-30 2102
-
Chapyter让编码更加地高效2023-11-03 1354
-
基于RFID和AI等先进技术,让医疗保健更加高效、准确2024-05-23 5122
全部0条评论

快来发表一下你的评论吧 !
