

百万量级数据不要怕,一招教你精准锁定
今日头条
描述
在做数据分析时你有没有遇到这些问题:
数据量大,怎么也找不到特定日期的文件
老板要看某年某月的销售数据,你要从百万量级数据中一条条寻找
……
要是使用永洪BI,会不会有一种方法,让我们在百万量级的数据中,一眼锁定要找的那一条?有的,那便是文件过滤。
首先,我们来说一下什么是meta,什么是文件过滤。
01 什么是meta
meta是集市文件上打的标签,可以大致理解为这个集市文件的属性。
比如,某个集市数据,我们是按天入的,每天生成的集市文件是前一天的数据,给这个集市文件添加了一个属性(属性名:date,属性值:昨天的日期),这个就叫做meta。
这个举个常见例子,有某个部门的销售数据,每天的销售数据存储在一个excel中,这个excel的文件名上带上这天的日期。集市文件的meta就相当于excel文件的文件名上的日期。
02 什么是文件过滤
先说说文件,这里的“文件”,指的是增量任务生成的集市文件,这个文件是存储在m节点,安装目录/Yonghong/cloud下,也就是存储在m节点磁盘上的。
文件过滤,接着上面excel的比喻讲,大致就是每天的销售数据,存储在一个excel文件中,这个excel的文件名还带上了这天的日期。
要查询某天的销售数据就很快了,根据日期直接定位到要查询的这天,快速准确找到这天的数据,不需要所有的excel数据都打开去查一下。
回到文件过滤也是类似的效果,给每个集市文件打上了meta,meta的值是每个集市文件对应的数据的日期,那么要查询某天,或者某段时间的数据,就可以快速定位并查询,不需要所有的集市文件都查一遍,然后去找到想要的日期的数据。
说到这里是不是有个大概的概念,接下来说说为什么要什么文件过滤。
03 为什么做文件过滤
举个例子,某个部门的销售数据,每天大概有100万左右,一年大概就是3亿+。如果存储在excel中,一个excel文件假设存储的是100万左右,那么1年就有365个excel。
如果不把每天的数据存储在同一个excel,且文件名上标上每天的日期,那么当要查某天,或者某段时间的数据,是不是一个很大的工作量,需要把这365个excel都打开查一遍。
对应到产品的集市中也是一样,一个集市文件最大存储的行数大概100万行,如果这些数据都是按天增量的,且在集市文件生成的时候就给这些文件打上了meta。
meta值是数据对应的日期,那么当查询某一天的数据的时候,就可根据meta的值进行过滤,只查meta值为这天的这一个集市文件,那么计算量就是100万。
再来看一下如果不使用文件过滤,就需要把这365个集市文件都查询一遍,最终再过滤出这一天的数据,计算量是3亿+。
使用文件过滤是为了减少实际计算量,减少计算量后计算需要的时间也可以大幅减少,那么报表打开也就更快了。
下面做个比较,可以看到使用文件过滤与否,查询相同的时间的数据,实际的后台计算量和计算时间的巨大差别。
| 场景 | 是否使用文件过滤 | 计算文件个数 | 计算数据量 | 假设一个集市文件(100万)计算时长 | 计算需要时间 |
| 某部门销售数据每天100万,1年365百万,默认查询昨天的数据 | 是 | 1 | 1百万 | 100ms | 100ms |
| 否 | 365 | 365百万 | 365000ms=36s | ||
| 某部门销售数据每天100万,1年365百万,默认查询上个月的数据 | 是 | 30 | 30百万 | 100ms | 3000ms=3s |
| 是 | 365 | 365百万 | 365000ms=36s | ||
| 备注:这里的计算时间是按照m节点的计算能力为1计算,实际情况不止1,但是实际也不会只有一个组件,每个组件都会有这样一个集市查询 | |||||
前面已经了解了,文件过滤是什么以及为什么要用文件过滤,接下来就是文件过滤怎么用?
文件过滤的使用前提:数据已经通过增量的方式入到集市中,且在入的时候已经按照日期打好meta。
首先来看一下咱们增量且已经打好meta的集市数据。
|
集市文件夹:咖啡销售数据 下的集市文件 |
数据对应月份 | meta名 | meta值 |
| 2020年销售数据.6cb2f7790.0.0.zb | 2020-01 | _Date_Range_ | 2020-01 |
| 2020年销售数据.6cb2f7790.1.0.zb | 2020-02 | 2020-02 | |
| 2020年销售数据.6cb2f7790.2.0.zb | 2020-03 | 2020-03 | |
| 2020年销售数据.6cb2f7790.3.0.zb | 2020-04 | 2020-04 | |
| 2020年销售数据.6cb2f7790.4.0.zb | 2020-05 | 2020-05 | |
| 2020年销售数据.6cb2f7790.5.0.zb | 2020-06 | 2020-06 | |
| 2020年销售数据.6cb2f7790.6.0.zb | 2020-07 | 2020-07 | |
| 2020年销售数据.6cb2f7790.7.0.zb | 2020-08 | 2020-08 | |
| 2020年销售数据.6cb2f7790.8.0.zb | 2020-09 | 2020-09 | |
| 2020年销售数据.6cb2f7790.9.0.zb | 2020-10 | 2020-10 | |
| 2020年销售数据.6cb2f7790.10.0.zb | 2020-11 | 2020-11 | |
| 2020年销售数据.6cb2f7790.11.0.zb | 2020-12 | 2020-12 | |
|
2020年销售数据 是增量的时候设置的文件名 6cb2f7790 是随机码 0.0-11.0 是集市文件编号 .zb 是集市文件后缀 |
|||
使用步骤:
1、在“创建数据集”模块,新建数据集市数据集,选择增量任务中设置的文件夹名称,就得到一个数据集市数据集。
2、在数据集市数据集添加文件过滤,比如查询某一天的数据,对应的文件过滤如下:
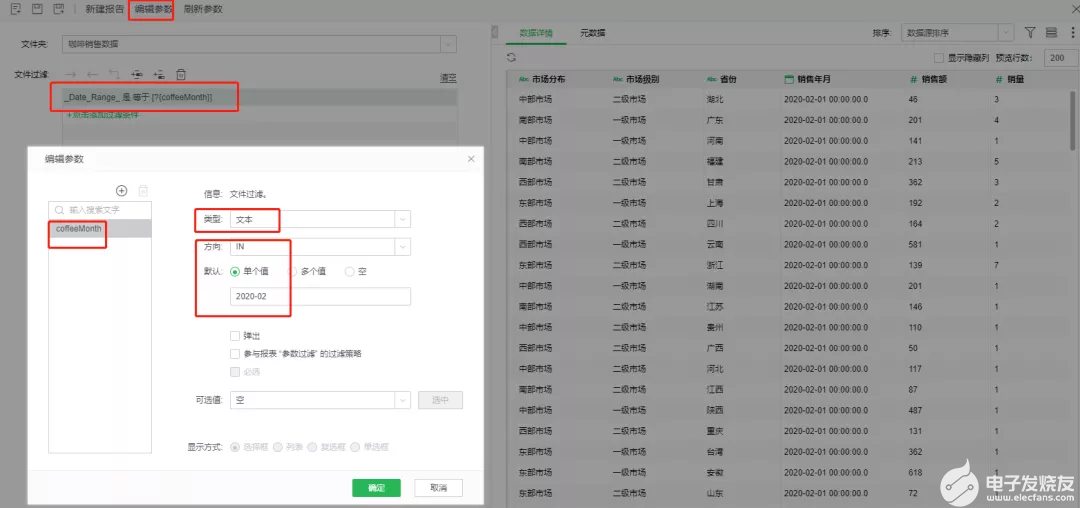
3、使用这个数据集市数据集制作报告,并将步骤2中定义的参数coffeeMonth的值,在报告中传递到数据集使用。
注意:参数的数据类型和格式一定要跟meta的数据类型和格式一致,如果不一致需要脚本处理。
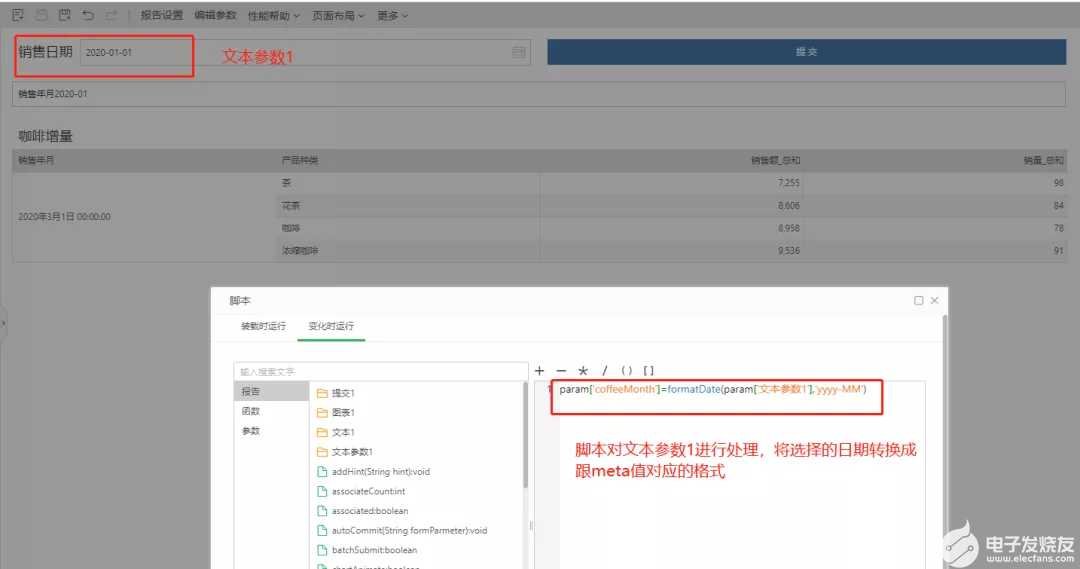
4、保存报告并查看效果,在报告中筛选选择某个月,实际底层查询的集市文件只查询这个月对应,而不是集市文件。
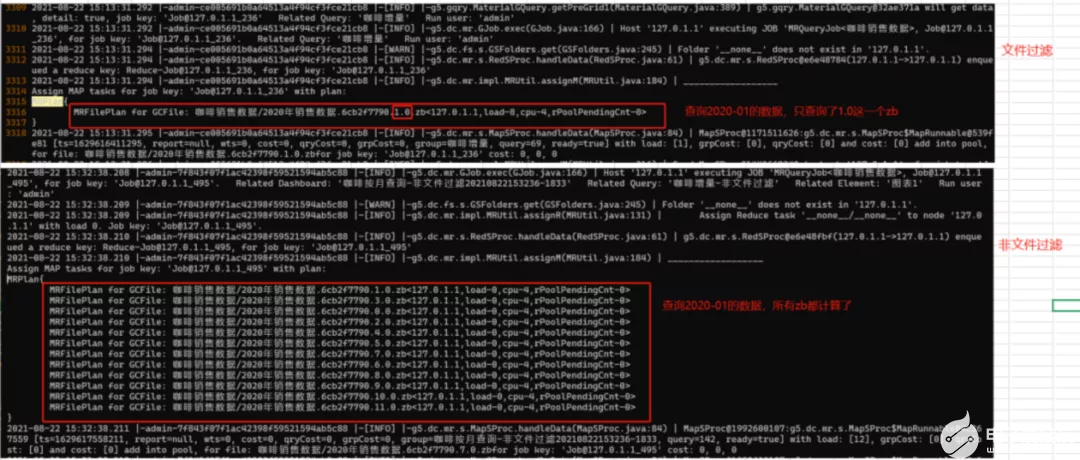
查询效果见下图,底层实际计算情况见截图(查询2020-01月的数据,使用文件过滤和不使用文件过滤的对比)。
什么时候适合用文件过滤?
集市查询数据量大的时候;查询的时候咱们只查询部分数据,而不是全量数据;希望提升查询性能;能够有用于增量同步的字段,比如日期,或者有经常筛选的字段用于打meta后的文件过滤。
举个例子,一个查询包含的数据量很大,时间跨度比较大(比如有3年的数据),每次查询的范围不是太大(比如每次查询大概3个月的数据,查询范围不定),这种就比较适合用文件过滤,将每次实际计算的计算量从3年缩减到三个月。
真正实现前台筛选多长时间范围,后台计算的就是多长时间的数据,而不是这个查询所有的数据计算完成再来筛选时间范围。
最后总结一下,集市查询,相对直连的情况一般对于报告的查询速度,是有显著的优化的,但是一个查询的总数据量很大的时候,实际查询的并不是全部时间段的情况下,用文件过滤能进一步优化查询性能。
fqj
-
教你一招如何分辨PCB板层数2021-04-23 4411
-
教你一招如何去实现傅立叶变换算法?2021-04-30 2018
-
教你一招怎样去选择合适的CPLD2021-05-06 1853
-
教你一招分分钟实现频谱仪带宽的正确设置2021-05-07 3250
-
教你一招定时器中断该怎么办?2021-05-14 2153
-
教你一招如何通过手机的芯片来判断手机的价格?2021-05-24 2990
-
教你一招如何去选择射频滤波器?2021-05-28 2184
-
教你一招RK31885.1蓝牙MAC怎样才能从模组中获取MAC地址2022-02-18 1612
-
笔记本硬盘保养15招(一招都马虎不得)2010-01-21 1171
-
巧解任何电脑的开机密码(小小一招就搞定)2010-02-25 905
-
教你一招辨别真假OLED屏2017-09-25 18083
-
一招让手机屏立马干净2019-08-27 8294
-
轻量级数据库有哪些2023-08-28 7379
-
5G NR生成与解调很难?教你一招轻松解决2023-09-09 2092
-
哪些晶体、谐振器和振荡器可旋转180°使用?一招儿教你快速识别2023-12-05 914
全部0条评论

快来发表一下你的评论吧 !
